音视频基础+ffmpeg原理(视频编码)
H264:
H264压缩比
条件:1、YUV格式YUV420 2、分辨率:640x480 3、帧率15
源码流:640x480x1.5x15,建议码流:500kpbs, 结果:约1/100
码流参考值:https://docs.agora.io/cn
GOP:
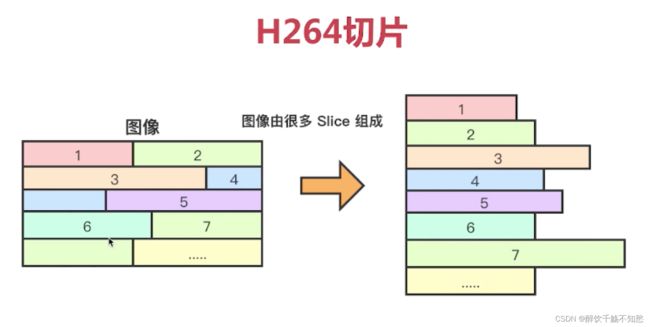
gop就是把相似的图片进行分组,一组就是一个gop。

H264中的I帧、P帧、B帧:
I帧(intraframe frame),关键帧,采用帧内压缩技术。IDR帧属于I帧。而且IDR帧还是第一帧(GOP中的第一帧),主要是用卡解决错误循环。
P帧(forward Predicted frame),向前参考帧。压缩时,只参考前面已经处理的帧,采用帧间压缩技术。它占I帧的一般大小。
B帧(Bidirectionall predicted frame),双向参考帧。压缩时,即参考前面已经处理的帧,也参考后面的帧,采用帧间压缩技术,它占I帧的1/4,虽然占用的内存少,但是比较消耗CPU,延迟大;所以一些实时通讯的场景中B帧用的比较少。
IDR帧与I帧的区别和联系
IDR(Instantaneous Decorder Refresh)解码器立即刷新,假如视频某个地方出错,但是在IDR帧的时候,在解码器端会把缓冲区的数据全部清空,重新开始。
每当遇到IDR帧时, 解码器就会清空解码器参考buffer中的内容
每个GOP中的第一帧就是IDR帧
IDR帧是一种特殊的I帧
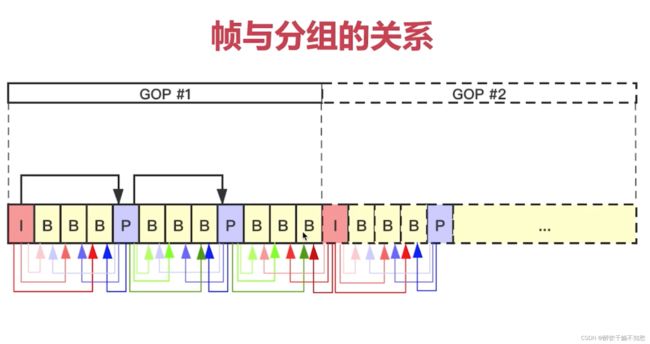
播放顺序:IBBBPBBB ,解码顺序:IPBBBPBBB。
SPS与PPS:
这两个相当于GOP的头文件,放在IRD帧的前面。
SPS(Sequencd ParameterSet):
序列参数集,作用于一串连续的视频图像。如 seq_parameter_set_id、帧数及POC(picture order count)的约束、参考帧数目、解码图像尺寸和帧场编码模式选择标识等。相当于修饰一组帧
PPS(Picture Parameter Set):
图像参数集,作用于视频序列中的图像。如pic_parameter_set_id、熵编码模式选择标识、片组数目、初始量化参数和去方块滤波系数调整标识等。相当于修饰图像的。
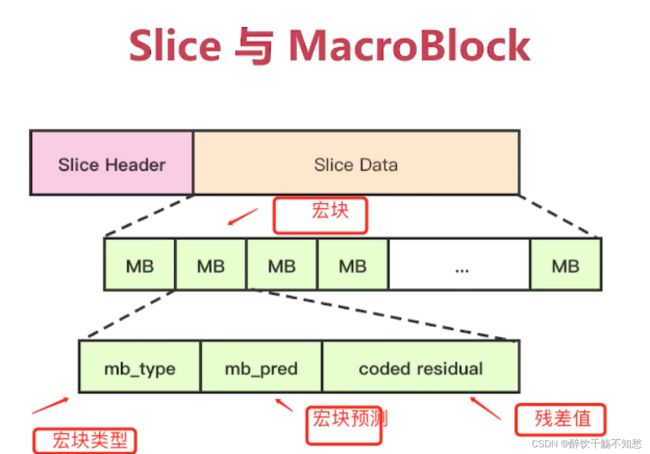
H264中的宏块:
1、帧内压缩技术,解决的是空域数据冗余问题(比如人眼对于亮度敏感,色度不敏感,我们就可以对色度进行压缩)
2、 帧间压缩,解决的是时域数据冗余问题(运动矢量、偏差值等)
3、整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化
4、CABAC压缩
上面的1、2是属于有损压缩,3、4属于无损压缩。
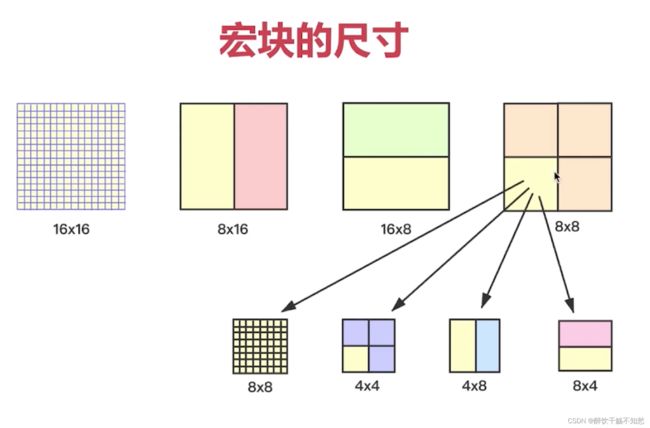
宏块:就是视频压缩的操作的基本单元,无论是帧内压缩还是帧间压缩,它们都是以宏块为单位。


左上角就是一个宏块8x8的像素。
帧内压缩的理论:
1、相邻的像素差别不大,所以可以进行宏块预测
2、人们对亮度的敏感度超过色度
3、YUV很容易将亮度和色度分开
有9中预测模式:


比如第一个,预测出了上、左的数据,我们只需要存储这两排数据,中间的数据可以预测出来,这样存储的数据就非常少了。
上图的左边是预测后的图,右边是原始图;但是还存在差距,这是因为我们缺少残差值。一般我们解码后会把预测图和原始图进行比较得出残差值。所以简单来说就是:原始图 = 预测图+残差值。

帧内压缩的帧类型: I帧、IDR帧
帧间压缩原理:
1、GOP
2、参考帧
3、运动估计(宏块匹配+运动矢量)
4、运动补偿(解码时补上残差值)

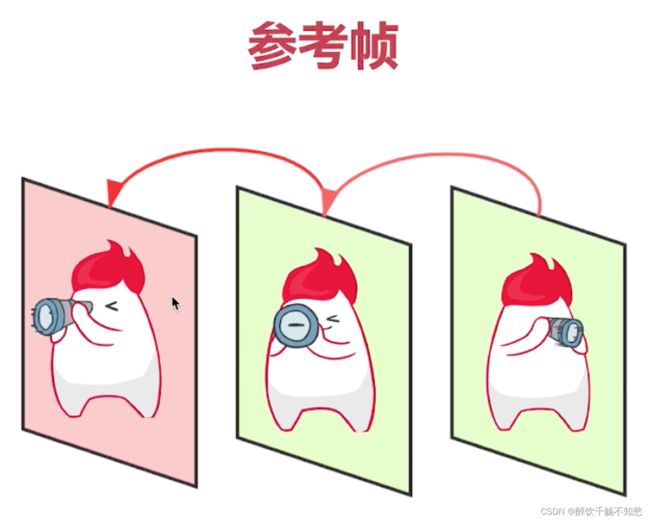
对于上图前两张图片,我们只需要找出不同的望远镜,并把望远镜的运动轨迹记录下来,对于第二张图片存储望远镜的运动矢量就行,其他相同的不需要存储。

解码后,通过运动矢量解码出来的图片,还要与参考帧进行比较补上残差值
视频花屏的原因:
如果GOP分组中有帧丢失,会造成解码端的图像发生错误,这会出现马赛克(花屏)
视频卡顿的原因:
为了避免花屏问题的发生,当发现有帧丢失时,就丢弃GOP内所有的帧,直到下一个IDR帧重新刷新图像。I帧的按照帧周期来的,需要一个比较长的时间周期,如果在下一个I帧来之前不显示后来的图像,那么视频就静止不动了,这就是出现了所谓的卡顿现象。
无损压缩:


离散余弦变换简称为DCT变换。它可以将L*L的图像块从空间域变换为频率域。
经过DCT变换后的结果。从图中可以看出经过DCT变换后,左上角的低频系数集中了大量能量,而右下角的高频系数上的能量很小。
信号经过DCT变换后需要进行量化。由于人的眼睛对图像的低频特性比如物体的总体亮度之类的信息很敏感,而对图像中的高频细节信息不敏感,因此在传送过程中可以少传或不传送高频信息,只传送低频部分。量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量。因此,量化是一个有损压缩的过程,而且是视频压缩编码中质量损伤的主要原因。
量化的过程可以用下面的公式表示:
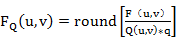
其中FQ(u,v)表示经过量化后的DCT系数;F(u,v)表示量化前的DCT系数;Q(u,v)表示量化加权矩阵;q表示量化步长;round表示归整,即将输出的值取为与之最接近的整数值。
合理选择量化系数,对变换后的图像块进行量化后的结果如图所示。

量化后的DCT系数
DCT系数经过量化之后大部分经变为0,而只有很少一部分系数为非零值,此时只需将这些非0值进行压缩编码即可。
熵编码:
熵编码是因编码后的平均码长接近信源熵值而得名。熵编码多用可变字长编码(VLC,Variable Length Coding)实现。其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。可变字长编码通常有霍夫曼编码、算术编码、游程编码等。其中游程编码是一种十分简单的压缩方法,它的压缩效率不高,但编码、解码速度快,仍被得到广泛的应用,特别在变换编码之后使用游程编码,有很好的效果。

混合编码:
上面介绍了视频压缩编码过程中的几个重要的方法。在实际应用中这几个方法不是分离的,通常将它们结合起来使用以达到最好的压缩效果。下图给出了混合编码(即变换编码+ 运动估计和运动补偿+ 熵编码)的模型。该模型普遍应用于MPEG1,MPEG2,H.264等标准中。
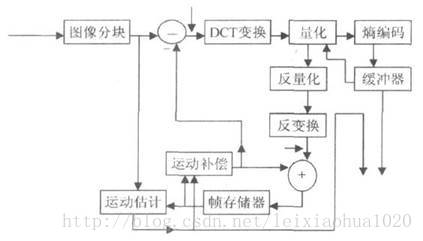
混合编码模型
从图中我们可以看到,当前输入的图像首先要经过分块,分块得到的图像块要与经过运动估计的预测图像相减得到差值图像X,然后对该差值图像块进行DCT变换和量化,量化输出的数据有两个不同的去处:一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。另一个应用是进行反量化和反变化后的到信号X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
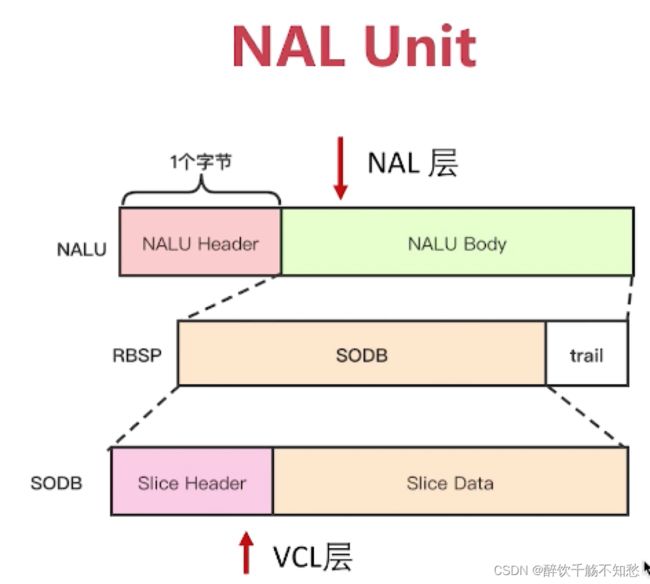
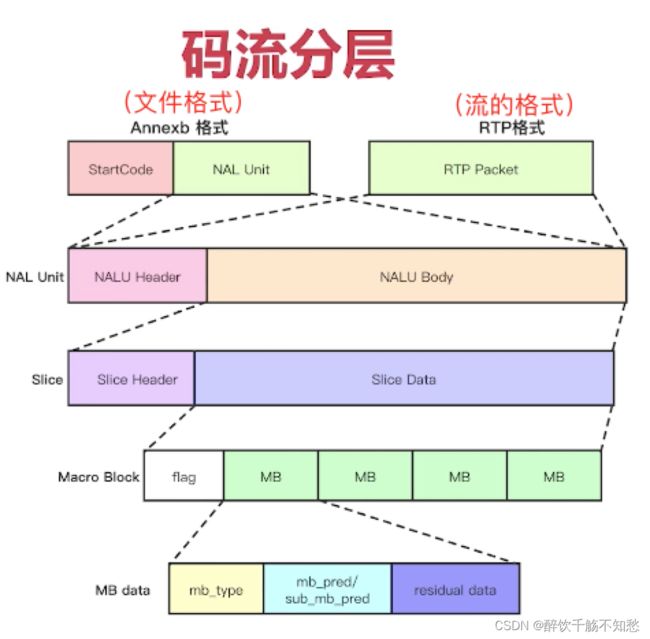
H264码流结构:
H264码流分层:
1、NAL层:Network Abstraction Layer,视频数据网络抽象层。主要是解决在码流在网络传输中出现的各种问题
2、VCL层:视频数据编码层

码流基本概念:
1、SODB(String Of Data Bits)
原始数据比特流,长度不一定是8 的倍数,故需要补齐。它是由VCL层产生的。
2、RBSP (Raw Byte Sequence Payload)
SODB + trailing bits,算法是如果SODB最后一个字节不对齐,则补1和多个0。按照字节对齐,使得SODB是8的整数倍
3、NALU
NAL Header(1Bit)+RBSP