线程与进程理论知识入门(二)
volatile,最轻量的同步机制
volatile保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这个新值对其他线程来说是立即可见的。
举个例子:
public class VolatileTest {
public static int num = 1;
public static boolean isStop = false;
public static class UseThread extends Thread{
@Override
public void run() {
while (!isStop){
}
System.out.println("num = "+ num);
}
}
public static void main(String[] args){
UseThread useThread = new UseThread();
useThread.start();
SleepTools.ms(50);
num =50;
isStop = true;
SleepTools.second(5);
System.out.println("main end ___________");
}
}上述代码中,虽然我们在主线程中修改了isStop变量,但是while(isStop)根本不会中断。
有些人认为,加上了volatile关键字,就是线程安全的,就像是加锁了一样。这说想法是错误的,volatile只能保证线程的可见性,并不能保证线程的排他性,举个例子:
package com.example.retrofit.ex2;
import com.example.retrofit.cn.tools.SleepTools;
public class VolatileUnsafeTest {
private volatile int count =1;
private void add(){
count++;
}
public static class ThreadOne extends Thread{
VolatileUnsafeTest test;
public ThreadOne(VolatileUnsafeTest unsafeTest) {
test = unsafeTest;
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
test.add();
}
}
}
public static class ThreadTwo extends Thread{
VolatileUnsafeTest test;
public ThreadTwo(VolatileUnsafeTest unsafeTest) {
test = unsafeTest;
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
test.add();
}
}
}
public static void main(String[] args){
VolatileUnsafeTest test = new VolatileUnsafeTest();
ThreadOne threadOne = new ThreadOne(test);
ThreadTwo threadTwo = new ThreadTwo(test);
threadOne.start();
threadTwo.start();
SleepTools.second(5);
System.out.println("last count = "+test.count);
}
}
上述启动两个线程,都对加了关键字volatile的变量count进行相加10000,理论如果的线程安全的,最后得出的count应该的20000,但是结果并不是20000。由此可见volatile关键字并不能保证线程安全。
volatile关键最适用的场景:一个线程写,多个线程读。
ThreadLocal解析:
相较于synchronized关键字,Java中还有一个ThreadLocal。它们之间还是有很大区别的:
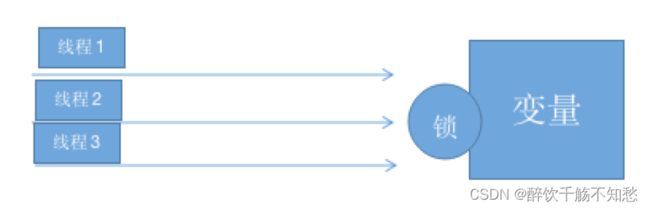
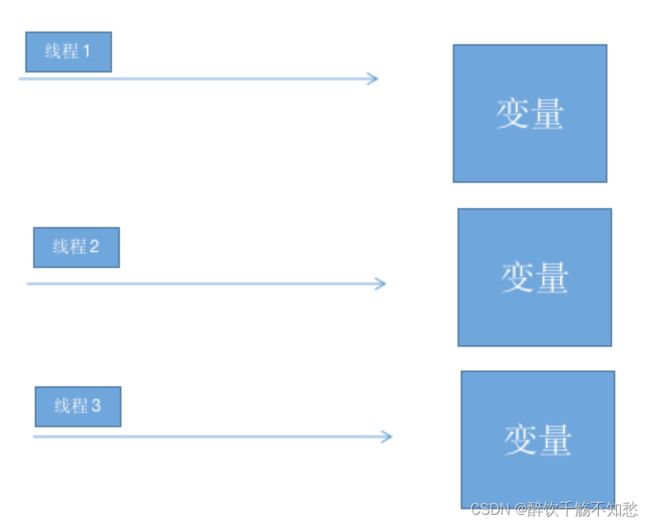
synchronized的利用锁的机制,使得变量或者代码块在某一时刻仅仅只能被一个线程访问。而ThreadLocal是为每个线程都提供了一个单独的变量,使得每个线程在某一时刻访问到的并非是同一个对象,这样就隔离了多个线程对数据的共享。
在之前讲的JVM中的对象分配的时候就讲过,分配对象的时候要考虑安全性,有CAS和TLAB,TLAB就是本地线程缓冲,在Eden区给线程创建一个缓冲区(或者说是一个副本)给这个线程使用,在这个缓冲区中可以做各种操作,所以是单独、独立的,即线程安全。
可以这么理解:
synchronized:
ThreadLocal:
ThreadLocal的使用:
1、public void set(T value) 设置当前线程的线程局部变量的值
2、public T get() 该方法返回当前线程多对应的线程局部变量值
3、public void remove() 将当前线程局部变量的值删除,目的的减少内存的占用。需要指出的是线程结束后,对应该线程的局部变量会自动的被垃圾回收,所以显示调用该方法清除线程的局部变量并不是必须操作,但是它可以加快内存的回收。
4、protected T initialValue() 该方法返回该线程局部变量的初始值,该方法是一个protected的方法,显然是为了让子类覆盖而设计的。这个方法是一个延迟调用,在线程第一次调用get()或者set(T value)方法时才会执行,并且只调用一次。ThreadLocal中的缺省实现会直接返回null。
private static ThreadLocal local1 = new ThreadLocal<>(){
@Nullable
@Override
protected Integer initialValue() {
return super.initialValue();
}
}; 实现解析:
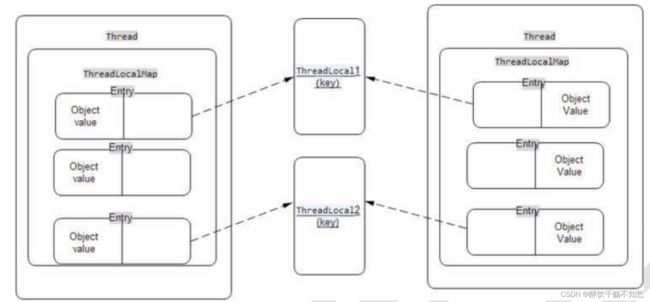
Thread->ThreadLocalMap->Entry(key,value)key是ThreadLocal,value是值。
源码的话,set()、get()方法的大致流程就是:
get():
public T get() {
Thread t = Thread.currentThread(); // 获取当前线程
ThreadLocalMap map = getMap(t); // 根据线程获取ThreadLocalMap
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); // 根据ThreadLocalMap获取Entry
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value; // 通过Entry获取value
return result;
}
}
return setInitialValue(); //如果Entry为null,通过初始方法获取,如果没实现InitialValue()方法,则返回null
}set():
public void set(T value) {
Thread t = Thread.currentThread();// 获取当前线程
ThreadLocalMap map = getoMap(t);// 获取ThreadLocalMap
if (map != null)
map.set(this, value);// 如果map!=null,经过一系列操作往Entry中添加value
else
createMap(t, value);// 如果map==null,创建一个新的ThreadLocalMap 往Entry中添加value
}以上操作和HashMap操作有点类似。
ThreadLocal引发的内存泄漏
首先我们来看一下,为什么ThreadLocalMap类中的Entry继承的是弱引用,至于引用的类型,大家可以参考之前的JVM文章。
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
} 因为弱引用的话,我们GC一次,就会去回收这些弱引用对象,这是防止内存泄漏用的。
那么既然这里用的是弱引用为什么还会产生内存泄漏呢?
这是因为弱引用要在GC的时候弱引用对象会回收,一个线程什么时候会GC呢,那就是这个线程执行完毕后。
那线程没有执行完的话,线程里面的一些资源就不能释放回收,这就导致了内存泄漏。
那有没有方法预防这种情况呢?
ThreadLocal为我们提供了一个remove(key)方法
//Remove the entry for key.
private void remove(ThreadLocal key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}所以我们在调用set(T value)方法的时候,为了多一层保险,每次set()的时候调用一次remove()方法。ThreadLocal的内存管理如下图:
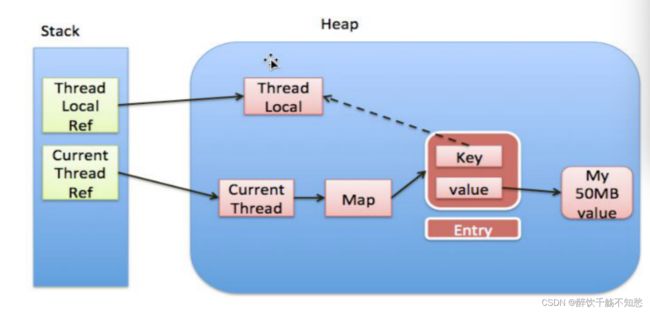
注意:ThreadLocalMap中保存的相当于是一个对象,假如这个对象是共享的对象,比如:
public static Object o = new Object();
这种静态修饰的Object本来就是全局共享是对象,如果把这种当做一个value放入ThreadLocalMap中,是不能实现数据隔离的,ThreadLocal了也就失去了作用。
线程间的协作
线程之间相互配合,完成某项工作,比如:A线程修改了某个值,B线程感知后做出相应的操作。前者是生产者,后者是消费者,这种模式隔离了“做什么”(what)和“怎么做”(how),简单的做法就是不断的让消费者循环检查出变量是否符合预期在while循环中设置不满足条件,如果满足条件则推出while循环,从而完成消费者的工作,却存在如下问题:
1、难以确保及时性,即使变量发生了变化,也只有循环遍历到了,消费者才会感知
2、难以降低开销。如果降低睡眠时间,比如休眠1ms,这样消费者虽然更快 感知条件的变化,但是却可能消耗更多的CPU资源,造成无端的浪费
等待/通知机制
是指一个线程A调用了对象O的wait()方法进入等待状态,另一个线程B调用了对象O的notify()或者notifyAll()后,线程A收到通知后从对象O的wait()方法返回,进而执行后续操作。
等待和通知的标准规范:
等待方遵循如下原则:
1、获取对象的锁
2、如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件
3、条件满足则执行对应的逻辑
通知放遵循如下原则:
1、获取对象的锁
2、改变条件
3、通知所有等待在对象上的线程
在调用wait()、notify()系列方法之前,线程必须获取该对象的对象级别锁,即只能在同步方法或者同步块调用wait()、notify()系列方法。
那么在同步方法或者同步块中调用了wait()方法,会释放锁吗?答案是肯定得要释放,要是不释放锁,那么notify()方法不就是永远都拿不到锁,拿不到锁还怎么通知呢。
那么调用了notify()后,什么时候会释放锁呢?那就是在锁的同步代码这块执行完毕后,就自然而然的释放了锁,所以notify()系列方法一般都会放在同步代码的最后一行。
package com.example.retrofit.ex2;
import com.example.retrofit.cn.tools.SleepTools;
public class WaitAndNotify {
public static Object object = new Object();
private static int num =0;
public static class WaitThread extends Thread{
@Override
public void run() {
synchronized (object){
while (num<10){
try {
object.wait();
} catch (InterruptedException e) {
System.out.println("InterruptedException?????");
e.printStackTrace();
}
}
}
System.out.println("WaitThread do something");
}
}
public static class NotifyThread extends Thread{
@Override
public void run() {
synchronized (object){
while (num<10){
// 10s后通知A
SleepTools.second(1);
num++;
}
object.notifyAll();
System.out.println("notify WaitThread do something");
}
}
}
public static void main(String[] args){
WaitThread waitThread = new WaitThread();
NotifyThread notifyThread = new NotifyThread();
waitThread.start();
notifyThread.start();
SleepTools.second(1);
System.out.println("main do end~~~~~~~~~~");
}
}
总结:
调用yield()、sleep()、wait()、notify()等方法对锁有何影响?
yield()、sleep()被调用后,都不会释放当前线程所有持的锁。
wait()上面说过了,会释放当前线程持有的锁。
notify()被调用后,对于锁无影响,线程会在syn同步代码执行完毕后释放锁。
notify()、notifyAll(),该用哪一个呢?
尽可能的使用notifyAll(),因为使用notify()只会唤醒一个线程,我们无法保证这个被唤醒的线程就一定是我们所需要的线程。
线程的并发工具类:
1、Fork-Join
Fork-Join的设计思想是分治法,将一个难以直接解决的大问题,分割成一个个规模较小的相同的问题,以便各个击破,分而治之。
常用的算法中,快速排序、归并排序、二分查找就是用的分治法。
Fork-Join框架:就是在必要是情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆分时),再将一个个的小任务运算的结果进行join汇总。
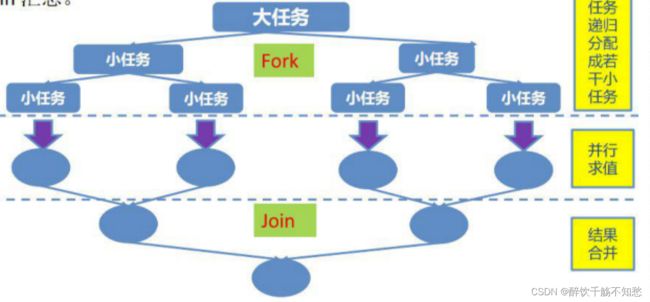
工作取密:
即当前线程的TASK已经全部被执行完毕,则自动取到其他线程的TASK池中取出TASK继续执行。
ForkJoinPool中维护着多个线程(一般为CPU核数)在不断的执行TASK,每个线程除了执行自己职务内的TASK之外,还会根据自己工作线程的闲置情况去获取其他繁忙的工作线程的TASK,如此一来就能够减少线程阻塞或者闲置的时间,提高CPU效率。
Fork-Join使用时的标准范式
我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork和join的操作,通常我们不能直接继承ForkJoinTask类,只需要直接继承其子类
1、RecursiveAction,用于没有返回结果的任务
2、RecursiveTask,用于有返回值的任务
task要通过ForkJoinPool来执行,使用submit或者invoke提交,两者的区别是:invoke是同步执行调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行。
join和get方法当任务完成的时候返回计算结果
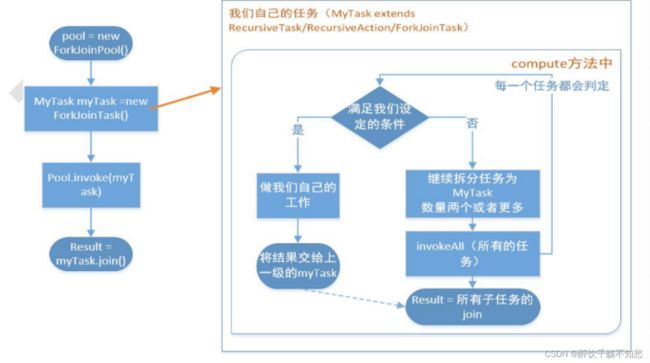
在我们自己实现的compute方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用invokeAll方法时,又会进入compute方法,看看当前子任务是否需要继续分割成更小的任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待执行完毕并得到其结果。
同步代码如下:
package com.example.retrofit.ex2;
import com.example.retrofit.cn.ch2.forkjoin.sum.MakeArray;
import com.example.retrofit.cn.tools.SleepTools;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.RecursiveTask;
/**
* Fork-Join 同步
*/
public class ForkJoinSyn {
public static class MyTask extends RecursiveTask{
//划分每个子任务的大小
public static final int THRESHOLD= MakeArray.ARRAY_LENGTH/10;
public int fromIndex;
public int toIndex;
public int[] nums;
public MyTask(int fromIndex, int toIndex, int[] nums) {
this.fromIndex = fromIndex;
this.toIndex = toIndex;
this.nums = nums;
}
@Override
protected Integer compute() {
//是一个最小的任务
if (toIndex-fromIndex 异步代码如下:
package com.example.retrofit.ex2.forkjoin;
import com.example.retrofit.cn.ch2.forkjoin.sum.MakeArray;
import com.example.retrofit.cn.tools.SleepTools;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
/**
* Fork-Join 同步
*/
public class ForkJoinSubmit {
public static class MyTask extends RecursiveTask{
//划分每个子任务的大小
public static final int THRESHOLD= MakeArray.ARRAY_LENGTH/10;
public int fromIndex;
public int toIndex;
public int[] nums;
public MyTask(int fromIndex, int toIndex, int[] nums) {
this.fromIndex = fromIndex;
this.toIndex = toIndex;
this.nums = nums;
}
@Override
protected Integer compute() {
//是一个最小的任务
if (toIndex-fromIndex CountDownLatch
闭锁,CountDownLatch这个类能够使一个线程等待其他线程完成各自的任务后再执行。CountDownLatch是通过一个计数器来实现的
举个例子:
计数器CNT=5,TW1、TW2线程执行了await()方法后需要等待;Ta、Tb、Tc、Td这四个线程每调用一次countDown(),计数器CNT-1,之后这四个线程可以继续运行或者结束;直到CNT=0之后,通知A、B线程继续运行。

实例代码如下:
package com.example.retrofit.ex2.countdownlatch;
import com.example.retrofit.cn.tools.SleepTools;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchTest {
// 初始化CountDownLatch,并且计数器设为6
static CountDownLatch latch =new CountDownLatch(6);
//初始化线程
public static class InitThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"init work end~~~");
latch.countDown();
for (int i = 0; i < 3; i++) {
SleepTools.ms(5);
System.out.println(Thread.currentThread().getName()+" do something~~~");
}
}
}
// 业务线程
public static class BusinessThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" I need wait count = 0");
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" wait is end~~");
}
}
public static void main(String[] args){
new Thread(){
@Override
public void run() {
latch.countDown();
System.out.println(Thread.currentThread().getName()+" I can down two counts");
latch.countDown();
}
}.start();
for (int i = 0; i < 4; i++) {
new InitThread().start();
}
new BusinessThread().start();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main do something");
}
}
CyclicBarrier
CyclicBarrier(循环屏障),作用有点类似CountDownLatch,但是又有区别(这个后面讲)。
先给大家大致看一下图解:

如上图所示, CyclicBarrier是每一个线程跑到屏障之后会等待,知道所有线程都到达屏障后;一起继续执行。如果加入了BarrierAction的话,会在所有线程到达屏障后,再继续执行。
比喻:操场赛道上有3个人在跑步,第一个跑到终点后,会等待其他2个人。当3个人都跑到终点后,假如使用了BarrierAction,3个人会在终点统计一下各自花费的时间,统计完之后,继续跑;假如没有使用BarrierAction,3个人在到达终点后,继续跑。
代码如下:
package com.example.retrofit.ex2;
import com.example.retrofit.cn.tools.SleepTools;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierTest {
// parties:线程数 ,barrierAction:处理每个线程的数据汇总
public static CyclicBarrier barrier = new CyclicBarrier(4,new BarrierActionThread());
// 存储每个线程的数据
public static ConcurrentHashMap map = new ConcurrentHashMap<>();
// 用户线程
public static class UseThread extends Thread{
@Override
public void run() {
Long id = Thread.currentThread().getId();
map.put(id+"",Thread.currentThread().getId());
System.out.println(id+"start~~~~");
try {
SleepTools.second(1);
barrier.await();
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
// 可以多次调用await()方法,每调用一次在BarrierAction就计算统计一次
barrier.await();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println(id+"do something~~~~");
}
}
// 处理用户线程的返回结果
public static class BarrierActionThread extends Thread{
@Override
public void run() {
Long result=0l;
Set> entries = map.entrySet();
for (Map.Entry entry:entries
) {
result = result+(Long) entry.getValue();
}
System.out.println("BarrierActionThread result is: "+result);
}
}
public static void main(String[] args){
for (int i = 0; i < 4; i++) {
new UseThread().start();
}
System.out.println("main is end~~~~~~~~~~~");
}
}
那么CyclicBarrier和CountDownLatch看起来有点类似,那么它们之间有什么区别呢?
1、CyclicBarrier构造方法中的parties就是对应的线程数,CountDownLatch的count参数对应的是计数器的值,不是线程数
2、CyclicBarrier可以把每个线程的数据进行统计或者说操作,CountDownLatch却不行
3、CyclicBarrier的await方法是作用于每个线程自己的,CountDownLatch的await方法是受其他线程影响的(比如代码中的初始化线程影响业务线程)
4、CyclicBarrier可以多次反复调用await()方法,每调用一次在BarrierAction就计算统计一次;而CountDownLatch的await方法调用一次和多次没区别。
Semaphore
Semaphore,我们俗称信号量,一般用于数据流控,比如控制一定数量的线程(假如我们有30个线程,我们只允许最多10线程同时操作)。
举个生活中常见的例子:排队做核酸
假如我们去排队做核酸,一个队伍有100号人去做核酸。大家都在等待做核酸,这时工作人员说:想要做核酸的话,到他那领取一个手牌,只有有了手牌的人才能进去做核酸;而且手牌只有10个,一次只能有10个人做核酸。做完核算后,手牌要交给工作人员。这样,就保证了每次最多只有10个人做核酸。相信这样说,大家应该能理解。
实例代码如下:
// 定义一个手牌类
public class ShouPaiBean {
}// 模拟做核酸拿手牌和放回手牌的类
public class HeSuanSemaphoreTest {
//定义手牌的个数10
private static final int SHOU_PAI_NUM = 10;
// 定义两个操作:一个拿手牌、一个交还手牌
private static Semaphore getSemaphore, releaseSemaphore;
//定义放手牌的池子
private static LinkedList pool = new LinkedList<>();
//初始化手牌池,里面总共有10个手牌
static {
for (int i = 0; i < SHOU_PAI_NUM; i++) {
pool.add(new ShouPaiBean());
}
}
public HeSuanSemaphoreTest() {
getSemaphore = new Semaphore(SHOU_PAI_NUM);
releaseSemaphore = new Semaphore(SHOU_PAI_NUM);
}
// 从手牌池拿手牌
public ShouPaiBean takeShouPai() throws Exception {
getSemaphore.acquire();
ShouPaiBean shouPaiBean;
synchronized (pool){
shouPaiBean = pool.removeFirst();
}
releaseSemaphore.release();
return shouPaiBean;
}
// 归还手牌到手牌池
public void returnShouPai(ShouPaiBean bean) throws Exception{
if (bean!=null){
System.out.println("当前手牌池有:"+getSemaphore.getQueueLength()+"个人等待拿手牌!!"
+"可用的手牌数: "+getSemaphore.availablePermits());
releaseSemaphore.acquire();
synchronized (pool){
pool.add(bean);
}
getSemaphore.release();
}
}
} // 模拟50个人排队去做核酸
public class ImitateHesuan {
private static HeSuanSemaphoreTest SPPool = new HeSuanSemaphoreTest();
private static class HesuanThread extends Thread{
@Override
public void run() {
Random r = new Random();//让每个线程持有连接的时间不一样
long start = System.currentTimeMillis();
try {
// 领取手牌
ShouPaiBean shoupai = SPPool.takeShouPai();
System.out.println("Thread_"+Thread.currentThread().getId()
+"_获取手牌连接共耗时【"+(System.currentTimeMillis()-start)+"】ms.");
SleepTools.ms(100+r.nextInt(100));//模拟业务操作,线程持有连接查询数据
System.out.println("做核酸完成,归手牌!");
SPPool.returnShouPai(shoupai);
} catch (InterruptedException e) {
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
Thread thread = new HesuanThread();
thread.start();
}
}
}Exchange
Exchange就是两个线程(注意:只支持两个线程,所以一般我们用的不多)各自执行Exchange后,将两个线程的数据进行交换。
如下图所示:
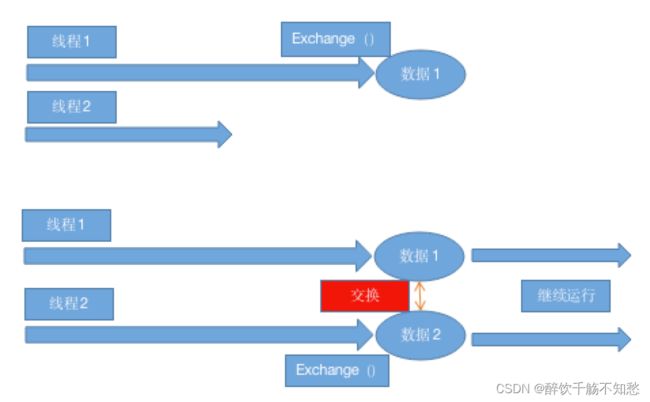
代码如下:
package com.example.retrofit.ex2;
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.Exchanger;
public class ExchangeTest {
private static final Exchanger> SET_EXCHANGER = new Exchanger<>();
public static void main(String[] args){
new Thread(){
@Override
public void run() {
Set setA = new HashSet<>();
setA.add("A1");
setA.add("A2");
setA.add("A3");
try {
setA = SET_EXCHANGER.exchange(setA);
System.out.println("线程A交换后的数据: "+setA);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
new Thread(){
@Override
public void run() {
Set setB = new HashSet();//存放数据的容器
try {
setB.add("B1");
setB.add("B2");
setB.add("B3");
setB = SET_EXCHANGER.exchange(setB);//交换set
System.out.println("线程B交换后的数据: "+setB);
} catch (InterruptedException e) {
}
}
}.start();
}
}
Callable、Future和FutureTask
相信大家对于这几个都不陌生,Callable的用来做什么的呢?之前我们也讲到实现线程的方式有两者一个是Thread,一个是Runnable;这两个的话都没有返回值,所以才有了Callable。有的人可能会说,实现线程的方式有3种或者4种。其实我们去看Thread的源码会发现,人家官方注释的就只有Thread和Runnable。
Callable->包装成FutureTask->implements RunnableFuture->RunnableFuture
通过上面的情况,我们可以看出Callable----------->Runnable。
UML图如下:
