致初学者的深度学习入门系列(三)—— 深度学习目标检测篇(上)
目标定位
在softmax层中不仅仅只输出分类信息,还可以输出目标的外接矩形框的角点和长宽,这样就可以转化为一个逻辑回归的问题。只要在训练集上对相应信息进行标注,以及定义合适的损失函数,就可以通过实现对目标的定位。
目标检测
滑动窗口法
首先设定固定大小的窗口,以固定步长遍历图像,每次都将窗口内的图像传入分类网络进行分类,以达到对目标的检测效果。但是,步长的选择无法适应不同情况。过大的步长计算成本低,但检测的精确度下降,无法很好的框选目标;过小的步长又会导致传入网络的窗口数量过多,计算成本巨大。
- 滑动窗口在卷积上的实现
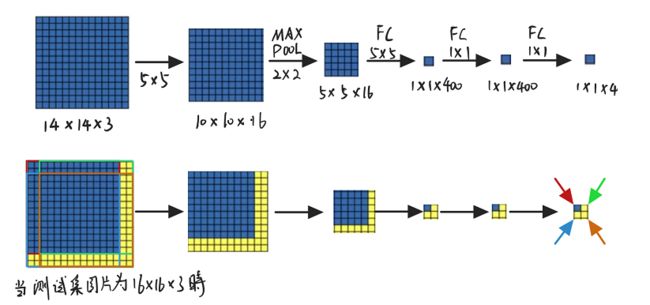
对于滑动窗口传入分类网络,并不需要单独每一次都把窗口内的图像单独传入网络进行分类,这样明显效率低下。根据卷积的特性,不同窗口经过多层卷积,最终只对应feature maps上的一个像素点,只要访问其中一个像素点就可以得到对应窗口经过分类网络得到的结果。
全卷积层(FCN)
传统的CNN其确定的网络输入图像的大小也是固定的,因为全连接层的每个节点都与上一层的全部节点项链,当输入图像大小不同时,全连接层前的feature map的大小也不相同。由于卷积只需要用卷积核在图像上遍历即可得到结果,并不会限制输入图像的尺寸。所以只要将全连接层也转化为卷积层,就可以使得神经网络输入图像的尺寸不受到限制。
且实现全连接层需要进行Flatten操作,将二维的feature maps被压缩成一维,丢失了空间信息,这对语义分割造成了困难,所以我们需要丢弃全连接层。

FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图(heatmap)上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。

非极大值抑制(NMS)
采用滑动窗口进行目标检测时,对同一对象可能会生成多个检测框。由于只要大于一定的阈值就会生成检测框,所以程序并不知道这些检测框对应的是同一个检测对象,此时就要用到非极大值抑制。
IOU(Intersection Over Union)
$$
IOU=\dfrac{A\cap B}{A \cup B} \quad\text{(交并比)}
$$
对于Bounding Box列表B机器置信度S,选择具有最大S的检测框M,将其从B中移除并加入到最终检测结果D中,将B中剩余检测框与M的IOU大于某阈值的从B中移除,重复直到B为空。
Top-1 正确率和Top-5正确率
Top-1正确率指正确标签为最佳概率的样本数除以总样本数
Top-5正确率指正确标签包含在前五个分类概率的样本数除以总的样本数
目标检测网络的框架
- Input:Image、Patches、Image Pyramid等。
- BackBone:目标检测网络的主干,主要作用是对进行特征提取,常需要对大型数据集进行与训练。常见有VGG系列、ResNet系列、SpineNet、EfficientNet系列等。
- Head:目标检测网络的头部,主要作用是预测对象所属的类别和可边界框的位置大小。分为one-stage和two-stage两种。one-stage以YOLO、SSD、RetinaNet为代表,two-stage以R-CNN系列为代表。
- two-stage方法:主要思路是先通过启发式算法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类和回归。例如R-CNN、Fast R-CNN、Faster R-CNN等,其优势是准确度较高。
- one-stage方法:主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步。例如YOLO、SSD等,其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。
- Neck:随着后来的发展,人们常在BackBone和Head之间添加一些网络层,称为Neck。Neck常由几个自下而上的path或自上而下的path组成。主要分为Additional Blocks和Path-aggregation blocks。
- Additional Blocks:SPP、ASPP、RFB、SAM。
- Path-aggregation blocks:FPN、PAN、BiFPN、NAS-FPN。
目标检测网络的发展历程
R-CNN
- Selective Search
首先通过图像分割算法(Efficient Graph-Based Image Segmentation)得到图像初始区域,使用贪心算法对区域进行迭代分组:
- 计算所有邻近区域之间的相似性;
- 两个最相似的区域被组合在一起;
- 计算合并区域和相邻区域的相似度;
- 重复2、3过程,直到整个图像变为一个地区。
度量相似性时采用一些多样性策略,对颜色相似度、纹理相似度、尺度相似度、形状重合度进行计算并进行加权求和得到最终的相似度,以此判断合并。
- BackBone:AlexNet
分类过程:
- 首先采用Selective Search算法生成Region Proposal,并且使用非极大值抑制剔除重叠区域。
- 在ImageNet上进行预训练,将成熟的权重参数作为网络的初始化参数进行fine-tune。
- 将区域内的图像输入到AlexNet中进行预测,并得到一个固定长度的特征向量。
- 用SVM对该特征向量做类别预测。
- 采用逻辑回归函数,对Bounding Box进行回归计算,进行目标定位。
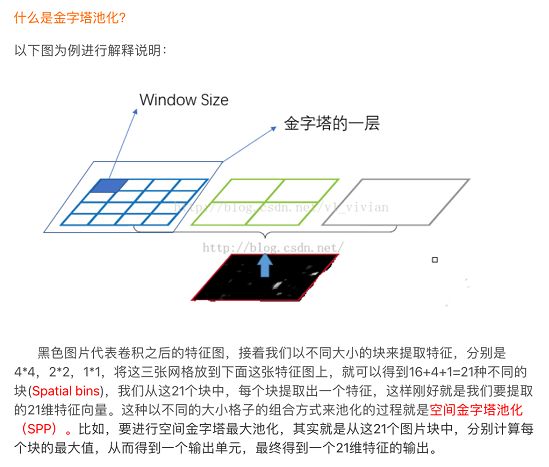
SPP-Net(空间金字塔池化网络)
- 候选区域映射
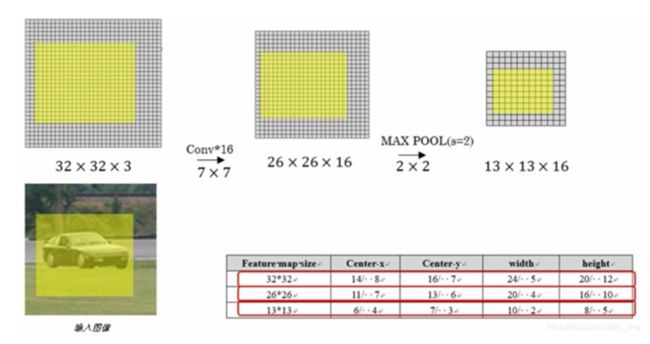
候选区域通过卷积层运算,虽然尺寸会发生变化,但同样能够达到框选目标对象的效果。所以没有必要单独将候选区域中的图像输入到分类网络中,只需要一次性计算出feature maps,对应映射后的候选区域可以直接用在feature maps上。

- 空间金字塔池化层
分类过程:
- 采用Selective Search算法生成Region Proposal,并且使用非极大值抑制剔除重叠区域。
- 一次性输入到CNN中得到feature maps。在其中找到各个候选框,对其采用金字塔空间池化提取出固定长度的特征向量。
- SVM进行特征向量分类识别。
Fast R-CNN
- ROI Pooling

将候选区域分成mxn个块,每个块执行Max Pooling。不同尺寸的候选区域都分成同样多的块做最大池化,提取成固定尺寸的特征。
- Muli-task Loss

- SVD加速全连接层
SVD的定义:
A = U ∑ V T A=U\sum V^T A=U∑VT
其中,A为mxn的矩阵,U为AAT的m个特征向量组成的mxm矩阵,V为ATA的n个特征向量组成的nxn矩阵。\sum是除了对角线上是奇异值其他位置都为0的矩阵。
奇异值
σ i = λ i λ i 为 A T A 的 特 征 值 \sigma_i=\sqrt{\lambda_i} \quad \lambda_i为A^TA的特征值 σi=λiλi为ATA的特征值
SVD常用于降维算法中的矩阵分解。
计算过程:
计算全连接时的一次前向传播
y = w x ( w 为 权 重 ) y=wx\quad(w为权重) y=wx(w为权重)
计算复杂度为mxn。
将w进行SVD分解并用前t个特征值近似。
y = w x = U ∑ V T x = U z y=wx=U\sum V^Tx=Uz y=wx=U∑VTx=Uz
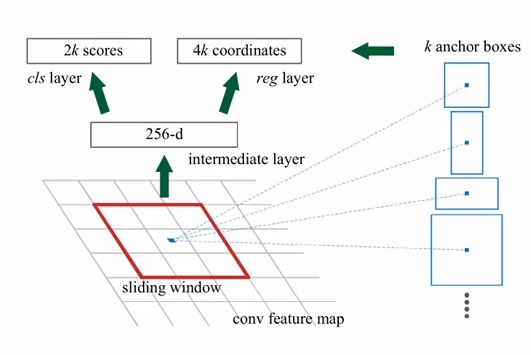
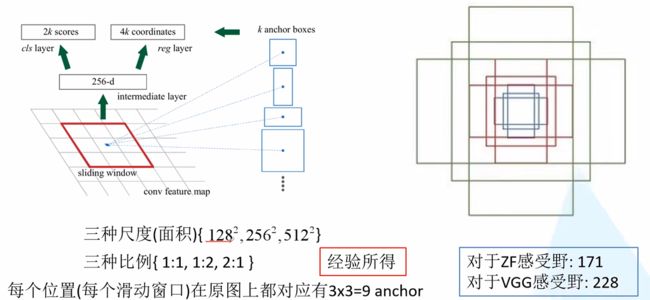
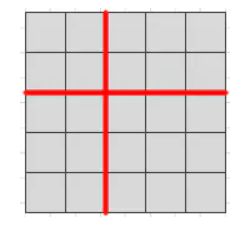
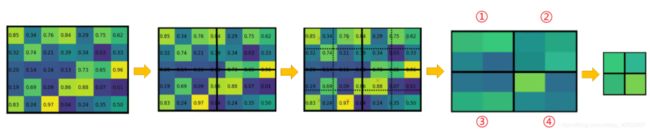
计算复杂度为mxt+nxt 通常随机选取256个样本,其中128个正样本,128个负样本。IOU<0.7选取为正样本,IOU为0.3选取为负样本。 感受野:feature map上的像素映射在输入图像上的区域。 对于特征图上的每个3x3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出k(一般为9)个anchor boxes,生成一维向量,通过两个全连接层得到2k个scores(背景和非背景的softmax)和4k个coordinates(x, y, w, h)。通过这些量来生成候选区域。 anchor boxes: 其余均与fast R-CNN一致。 ROI Align ROI Pooling的量化误差问题 由于ROI Pooling操作会产生区域不匹配的问题,而像素值只能为整数,此时就只能对像素取整处理,引入了一次量化误差 示例:输入特征图尺寸为55,而网络输入尺寸为22,那么网格的划分结果为 而对于每个小网格进行Max Pooling又要进行一次量化操作,这两次量化操作在feature maps上映射会原图就会产生较大的误差。 为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。(双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将虚拟的位置点对应的像素值估计出来。) Mask-RCNN的BackBone为ResNet,当输入的Bounding Box传入网络到ResNet的倒数第四层时,得到7x7x1024的ROI Feature,然后分为两个分支,其中一个与Faster R-CNN一样负责分类和回归计算,另一分支采用FCN(全卷积网络)进行升维到与输入图像尺寸一致的单通道map。每个像素的值用0和1表示,1代表属于该分类物体,0代表不属于,生成的map称为Mask(即做到像素级的分类,以达到实例分割的效果)。 L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask Lmask定义为the average binary cross-entropy loss ,定义的Lmask允许网络为每一类生成一个mask,而不用和其它类进行竞争;我们依赖于分类分支所预测的类别标签来选择输出的mask。这样将分类和mask生成分解开来。 喜欢的话可以关注一下我的公众号技术开发小圈,尤其是对深度学习以及计算机视觉有兴趣的朋友,我会把相关的源码以及更多资料发在上面,希望可以帮助到新入门的大家!
Faster R-CNN
Mask R-CNN


后续
