CIA-SSD
CIA-SSD: Confifident IoU-Aware Single-Stage Object Detector From Point Cloud
文章:CIA-SSD
代码:CIA-SSD
文章发表于AAAI2021,来自于港中文的博士生,Wu Zheng。通讯作者是港中文的博导Chi-Wing Fu
Abstract
当前问题:
用于在点云中定位目标的现有单级探测器常常将目标定位和分类作为分开的任务,所以定位准确度和分类置信度不能很好的对齐。
解决方法:
- 为了解决这个问题,我们提出了一个名叫
Confident IoU-Aware Single-Stage object Detector (CIA-SSD)的单级检测器。首先,为了准确的预测边界框和分类置信度,我们设计轻量级的空间-语义特征集合的模块(Spatial-Semantic Feature Aggregation)来自适应的融合高级抽象语义特征和低级空间特征。 - 预测的置信度会进一步被我们设计的
IoU感知置信度矫正模块(IoU-aware confifidence rectifification module)矫正来保证置信度和位置准确度更加一致性。 - 基于矫正后的置信度,我们进一步构建了距离变量
IOU权重的NMS来获得更平滑的回归和避免多余的预测。
结果:
CIA-SSD在KITT数据集上的测试集上的表现为moderate AP为80.28%,超过32FPS的推理速度。
Introduction
当前问题:
现存的方法将3D目标检测器当成目标定位和分类作为分开的任务,所以定位准确度和类别置信度由不太一致的问题。在两极目标检测中,这个问题表现的不是那么明显,因为第二个阶段会对分类置信度进行优化。但是在单级目标检测中,则表现不是很理想。
现存的解决方法:
SA-SSD提出了插值的方法获得区域候选特征,进而对分类置信度进行修正。
现存方法的不足:
这种差值方法相对复杂。
解决方法:
-
置信度修正模块(
confidence rectifification module):其核心观点建立在基于锚定特征基础上的IoU预测是决定性的,尤其是在边界框的准确和不准确的回归之间。因此,利用凸函数增强这种确定性,我们在准确回归和不准确回归之间极化了交并比预测效果,并有效的修正了后处理的置信度。
-
空间-语义特征聚合(
Spatial Semantic Feature Aggregation):自适应的融合高级抽象语义特征和低级空间特征,进而获得更为准确的边界框和分类置信度预测。 -
距离变量交并比加权
NMS:获得更平滑的回归和避免多余的预测。
Related Work
- two-stage detectors:
PointRCNN,PointNet++,Part-A^2,STD,PV-RCNN - single-stage detectors:
VoxelNet,PointPillar,SECOND,TANet,PointGNN,3DSSD,SASSD
Confident IoU-Aware Single Stage Detector
-
稀疏卷积网络(
SPConvNet) -
SSFA模块,用于提取空间-语义特征
-
带有矫正分类分数的置信度方程的多任务头和用于后处理的
DI-NMS
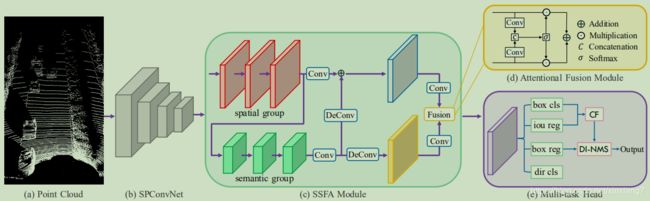
Point Cloud Encoder
- 体素化点云,计算每个体素中点的均值坐标和强度,作为初始化特征,可以参考
VoxelNet的体素梳理方法 - 利用稀疏卷积网络(
SPConvNet),从稀疏体素中提取特征。- 稀疏卷积网络由4个模块构成,4个模块由 { 2 , 2 , 3 , 3 } \{2,2,3,3\} {2,2,3,3}
SSC层和一个SC层构成。SC层用于每个模块的最后一层,对3D特征映射进行降采样(2x)。 - 将稀疏体素特征转化为稠密特征映射,并在z轴上进行叠加,来生成
BEV特征映射,作为SSFA模块的输入。
- 稀疏卷积网络由4个模块构成,4个模块由 { 2 , 2 , 3 , 3 } \{2,2,3,3\} {2,2,3,3}
Spatial-Semantic Feature Aggregation
- 由两组卷积层和一个注意力融合模块构成。两组卷积层分别称为空间组合语义组,输出的特征分别是空间特征和语义特征。
- 空间特征的尺寸和输入保持一致,避免空间特征信息的损失
- 将空间特征作为输入,首先用卷积,长宽下降一倍,通道增加一倍。之后再利用
Decon使得其恢复与空间特征一致的尺寸,便于求和,同时利用另一个Decon恢复其原有尺寸,便于之后的注意力融合。 - 融合的过程如图所示,首先将每个特征的通道压缩成一个,并合并结果。之后利用
softmax函数对正则化两个合并后的结果,再分离成两个BEV注意力映射。最后我们将上述BEV注意力映射作为各个特征的权重,并对加权后的特征求和。进而完成了语义特征和空间特征的融合。
IoU-Aware Confidence Rectification
"real IoU": 指的是在基于锚定的预测边界框和它最近的真实框的交并比;
predicted IoU: 在对应基于锚定的预测边界框上的网络预测交并比;
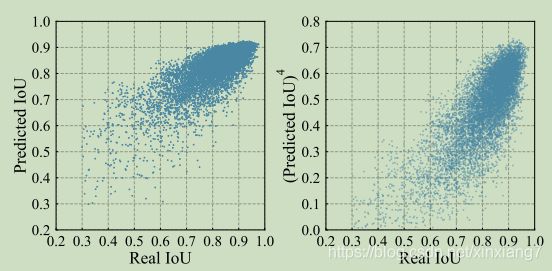
较高的确定性预测高IoU,因为该特征已经包含足够的位置信息。 另一方面,如果锚特征产生不精确的回归,例如当锚远离地面真相时,该特征很可能导致具有高不确定性的低IoU预测。
为了抑制这种低IoU预测的不确定性,并增大确定性和不确定性之间的区别。我们引入了修正项g:
g = i β g = i ^ {\beta}\\ g=iβ
置信度方程:
f = c ∗ g = c ∗ i β c : 分 类 分 数 f = c * g = c * i^{\beta}\\ c: 分类分数 f=c∗g=c∗iβc:分类分数
文章只在测试阶段使用confidence function,为后续的NMS提供矫正后的分类置信度。
Distance-Variant IoU-Weighted NMS
问题:由于远距离区域的点的稀疏性,远距离目标的预测常常是低分类置信度和高回归不确定性。
- 回归边界框上的严重震荡
- 多余的
false-positive预测
方法:
DI-NMS

- Step 1-2,我们计算每对锚定和预测框之间的
BEV中心点的L_2距离,利用距离偏量来优化置信度。 - Step 5-7选择最高分类置信度的框 c ′ c' c′,选择交并比超过阈值的重叠框
L'。之后辅助框的交并比预测值和候选边界框的真实交并比的乘积的累加和 - 我们使用光滑的高斯权重来考虑远距离预测中的震动辅助边界框
Loss Function
F o c a l l o s s ( L c l s ) S m o o t h − L 1 l o s s ( L b o x ) c r o s s − e n t r o p y l o s s ( L d i r ) i o u t = 2 ∗ ( i o u − 0.5 ) L = L c l s + w L b o x + μ L d i r + λ L i o u w = 2.0 , μ = 0.2 , λ = 1.0 Focal loss (L_{cls})\\ Smooth-L1 loss (L_{box})\\ cross-entropy loss(L_dir)\\ iou_t = 2 * (iou - 0.5)\\ L = L_{cls} + wL_{box} + \mu L_{dir} + \lambda L_{iou} \\ w = 2.0, \mu = 0.2, \lambda = 1.0 Focalloss(Lcls)Smooth−L1loss(Lbox)cross−entropyloss(Ldir)iout=2∗(iou−0.5)L=Lcls+wLbox+μLdir+λLiouw=2.0,μ=0.2,λ=1.0
Experiments
training set: 3712
validation set: 3769
test set: 7518
IoU threshold = 0.7
Implementation Detail
a grid of resolutions [0.05, 0.05, 0.1] meters in ranges [0, 70.4], [-40, 40], and [-3, 1] meters along the x, y, and z axes
archors: width=1.6m, length=3.9m, height=1.56m, two possible orientations (0◦ or 90◦).
three categories (positive, negative, and ignored) with IoU thresholds 0.45 and 0.6
数据增强:
-
global augmentation on the entire point cloud, including random rotation, scaling, and flipping
-
local augmentation on a portion of the point cloud around a ground-truth object, including random rotation and translation
-
a ground-truth augmentation following SECOND
-
filter out objects with difficulty levels not attributed to easy, moderate, and hard to improve the quality of the positive samples, and take also objects of similar categories, such as van for car, as the targets to alleviate model confusion in the training
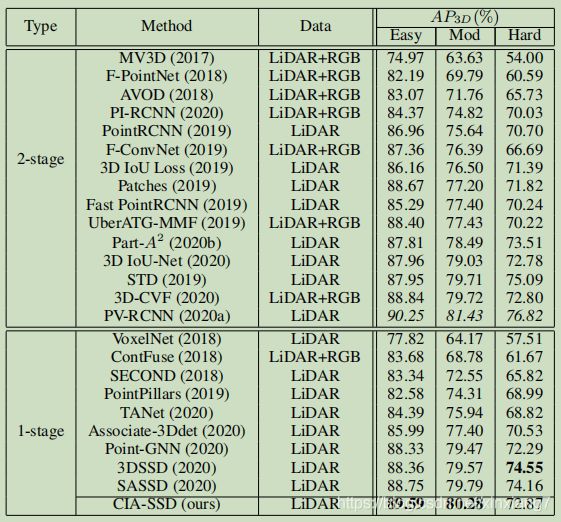
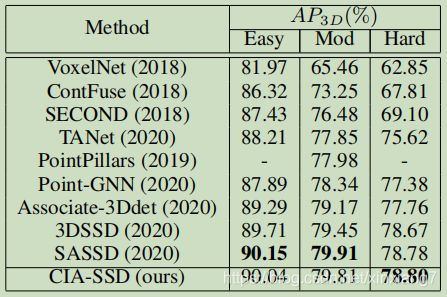
Comparison with State-of-the-Arts
Ablation Study
Effect of data processing

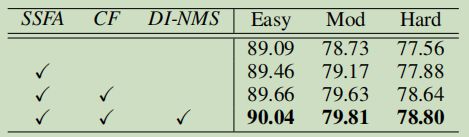
Effect of SSFA module & confifidence function & Effect of DI-NMS
Runtime Analysis
![]()

| pre-process | process | post-process | total |
|---|---|---|---|
| 2.84 | 24.33 | 3.59 | 30.76 |
Conclusion
-
置信度修正模块(
confidence rectifification module):其核心观点建立在基于锚定特征基础上的IoU预测是决定性的,尤其是在边界框的准确和不准确的回归之间。因此,利用凸函数增强这种确定性,我们在准确回归和不准确回归之间极化了交并比预测效果,并有效的修正了后处理的置信度。
-
空间-语义特征聚合(
Spatial Semantic Feature Aggregation):自适应的融合高级抽象语义特征和低级空间特征,进而获得更为准确的边界框和分类置信度预测。 -
距离变量交并比加权
NMS:获得更平滑的回归和避免多余的预测。