Redis黑马2022笔记(基础篇)
- 本文省略了Redis的安装配置笔记,笔记的内容有添加,有减少,但总线是按黑马2022的Redis,仅供学习参考,可以随意转载。
- 本人使用的是云服务器,因此ip的配置不是127.0.0.1,大家根据自己实际情况进行配置,具体操作可以观看视频的前几节
- 本文会对一些知识进行补充:例如设置RedisSerializer为什么能解决乱码问题
黑马2022Redis教程
Redis命令官方文档
Redis通用命令
KEYS查
KEYS:查看符合模板的key(模糊查询),单线程,且不适合大规模的生产环境
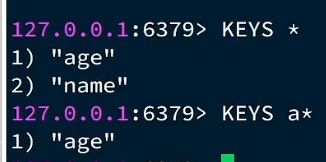
DEL删
可以一次删一个or一次删多个
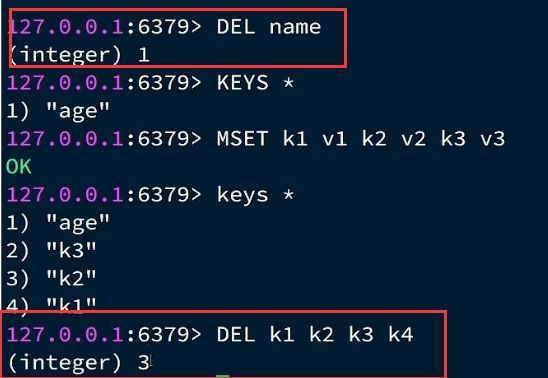
EXIST判断是否存在
返回值就是个数
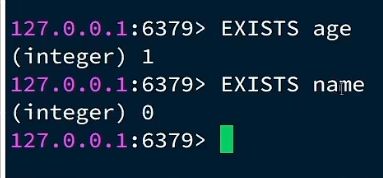
EXPIRE设置有效期
到有效期后自动删除。Redis消耗的是内存空间,为了节省空间or满足应用场景(例如短信验证码就必须在几分钟之内确认)
单位是seconds
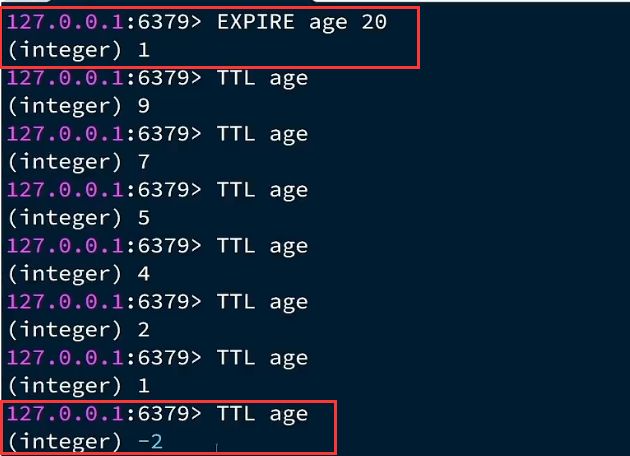
TTL查看剩余有效期
- 这个命令跟EXPIRE配合使用
- TTL 某key :查看剩余有效期
- >0时:剩余有效期
- -1时:永久有效,or未设置EXPIRE
- -2时:已失效
键值对分层存储
- SET数据时可能存在“用户id==手机id”的情况,但他们又同属一个项目不应分割,因此引入key类型分层
- Redis允许key有多个层级,用冒号:隔开,例如
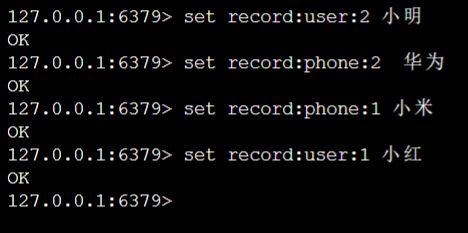
SET 项目名(手机购买记录) : 业务名(顾客) :key(1) value’{Json字符串}’
SET record : user : 1 ‘{“id” : 1 , “name” : “小明” , “age” : 18}’
SET 第一层:第二层:第三层:key value
5种常见Redis数据结构
- Redis是一个key-value数据库,key是String类型,value的类型就很多,如下
- 剩下不常见的例如GEO,BitMap,HyperLog不在此文中记录
- 数据结构指的是Value的结构,key是固定String的
总结
把一些小的总结写在前面 = =
- key都是String类型
- 当value是String时,存储的结构是一个字符串而不是表
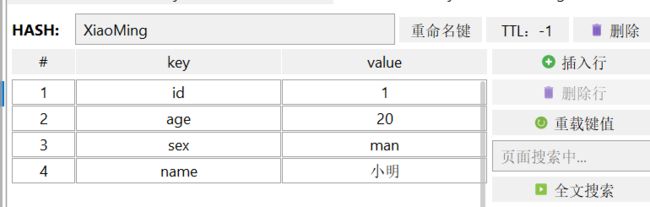
- 当value是Hash时,存储的结构是一个细粒度的二维表单
- 当value是List、Set时,存储的结构是细粒度的有序or无序的一维表单
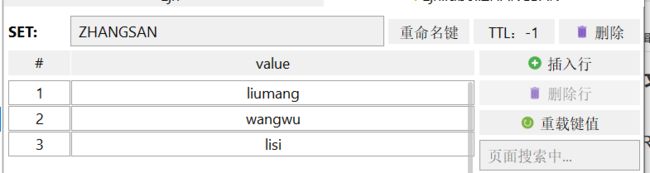
String
- 字符串类型,还可细分为:String普通字符串、int整数、float浮点
- 后两者可以自增自减 or 指定步长自增自减
- SET可添可改,SETNX才是真正意义上的添加

Hash
类似Java中的HashMap
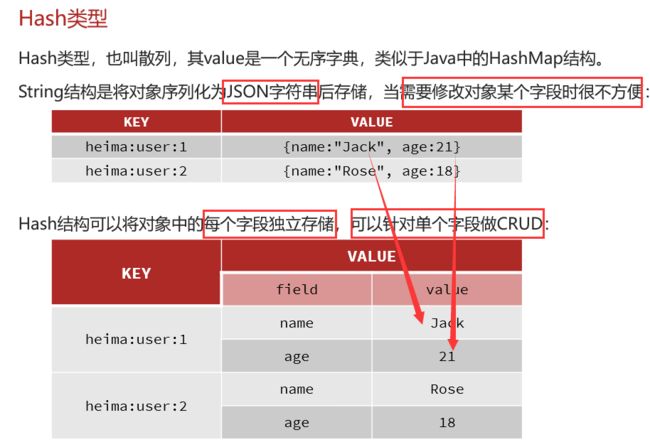 把String操作命令的开头加上H就是Hash类型的操作命令语句
把String操作命令的开头加上H就是Hash类型的操作命令语句

添加数据并查看:
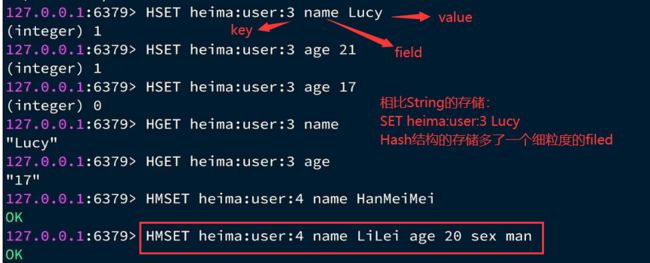
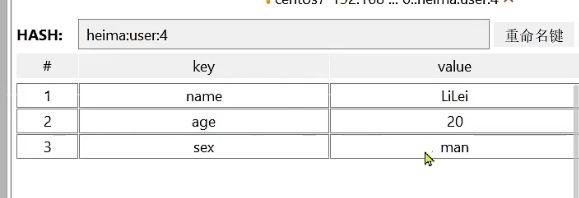
List
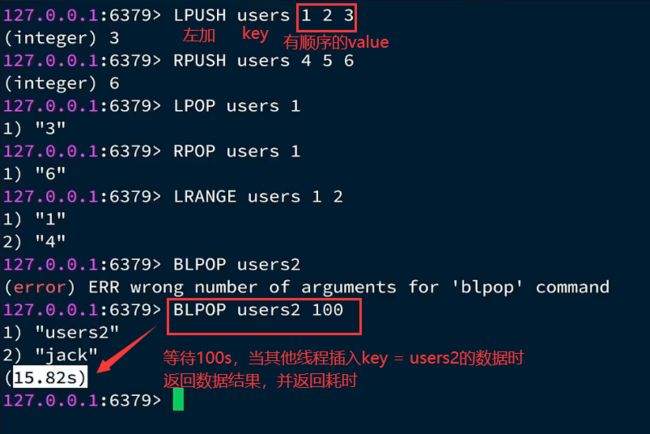
- 双向链表,类似LinkedList,增删快,查改一般;支持正向or反向检索;有序;
- 常用于存储有序数据eg:朋友圈点赞、评论列表

操作示例:

Set
无序不可重复,查询效率高;支持交集 并集 差集的功能
如下添加了黑马视频中“好友”案例的提示

SortedSet
可排序的Set类似TreeSet,且不可重复,查询快
底层是调表+hash表
每一个元素都必须有一个得分score属性,可以由此排序,可实现排行榜的功能

Redis的Java客户端
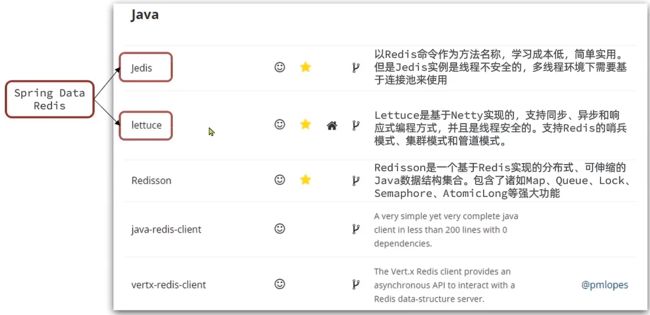
Jedis
Jedis基本用法
redis.clients
jedis
3.8.0
- 首先要配置ip 端口 密码,建立连接
- Jedis的命令和Redis命令一样,下面的例子用String和Hash举例
- 最后需要释放资源
单元测试
在Junit5中使用@BeforeEach来指定所有@Test之前的操作,@AfterEach来指定所有@Test结束之后的操作
Junit4中分别是@Before和@After
@SpringBootTest
class BootAjaxtestApplicationTests {
private Jedis jedis;//因为是new,所以无序@Autowired注入
@BeforeEach//任意@Test之前进行配置
public void connectRedis() {
jedis = new Jedis("124.xxx.xxx.176", 6379);//ip和端口
jedis.auth("xxxxxxx");//密码
jedis.select(1);//选择库
}
@AfterEach//任意@Test之后关闭连接
public void closeRedis() {
if (jedis != null) {
jedis.close();
}
}
@Test
public void redisTest1() {
//1.测试String
jedis.set("测试key", "测试value");
System.out.println(jedis.get("测试key"));
//2.测试Hash
jedis.hset("分层:Hash测试1", "属性1","111");
jedis.hset("分层:Hash测试1", "属性2","222");
jedis.hset("分层:Hash测试2", "属性a","aaa");
jedis.hset("分层:Hash测试2", "属性b","bbb");
System.out.println(jedis.hgetAll("分层:Hash测试2"));
}
}


Jedis连接池用法
虽然使用简单,但Jedis实例本身线程不安全,多线程环境下需要使用Jedis线程池
来替代Jedis
配置连接池
-
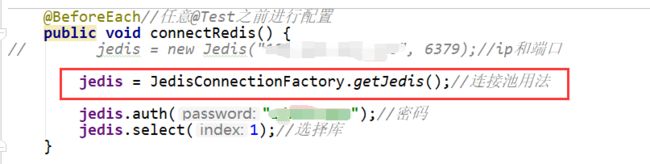
JedisConnectionFactory有一个静态方法getJedis,返回一个Jedis实例
-
配置的顺序是:JedisPoolConfig——JedisPool——getResource()返回Jedis实例
连接池JedisConnectionFactory如下:
public class JedisConnectionFactory { //在static静态代码块中初始化 private static final JedisPool pool; //静态代码块,随类的加载而加载 static{ //1.jedis连接池配置类 JedisPoolConfig config = new JedisPoolConfig(); //1.1可用连接实例的最大数目,默认值为8; config.setMaxTotal(10); //1.2控制一个pool最多有多少个状态为idle(空闲的)的jedis实例,默认值8。 //设置没人访问时,最多有5个空闲;设置太大占内存 config.setMaxIdle(5); //1.3pool的最小idle数,默认为8 //设置没人访问时,释放连接数的底线;设置太小无法快速应对突然的请求 config.setMinIdle(3); //1.4设置最长等待时间,当池中没有线程可用时,超出时间就报错 //-1表示无限等待,这里设置为1000ms config.setMaxWaitMillis(1000); //2.创建连接池对象,形参为(上面的配置类对象config,ip,端口,连接超时时间,密码) pool = new JedisPool(config, "xxx.xxx.xxx.xxx", 6379, 1000, "xxxxxxxx"); } //3.静态方法:从pool中获取一个资源(实例) public static Jedis getJedis(){ return pool.getResource(); }}
使用连接池
- 之前用new Jedis,现在是使用连接池获取
- 之前是直接关闭Jedis,现在是把Jedis归还给连接池
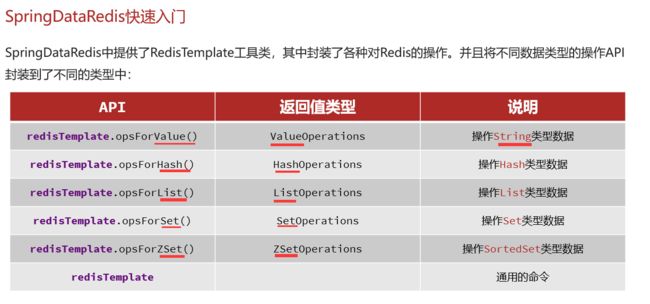
SpringDataRedis——RedisTemplate
为什么引入?:Jedis虽然学习成本低,但不同的数据结构对应的不同方法实在是太多了,显得十分臃肿;
引入SpringDataRedis,其中提供了工具类RedisTemplate,封装了各种Redis操作
直接使用RedisTemplate
依赖
该案例基于springboot
注意区别之前的Jedis依赖,这两个是新的依赖
那么什么时候需要之前那个Jedis依赖呢?:springboot默认的是lettuce依赖,所以使用lettuce作为连接池时不需要Jedis依赖;但如果是想使用Jedis作为连接池,就需要引入之前的Jedis依赖
org.springframework.boot
spring-boot-starter-data-redis
org.apache.commons
commons-pool2
第一个是springboot对redis整合,第二个是底层连接池(无论是lettuce还是jedis都需要这个依赖)
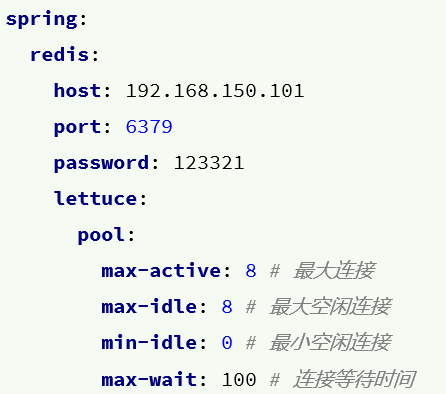
配置
springboot对redis进行了整合,因此可以直接在application.yaml中进行配置
一定要手动配置
注入使用
直接@Autowired
@SpringBootTest
class BootAjaxtestApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void redisTest1(){
redisTemplate.opsForValue().set("张三","18");
//形参可以任意类,RedisTemplate自动序列化(默认使用JDK的序列化工具)
System.out.println(redisTemplate.opsForValue().get("张三"));
}
}
新的问题(乱码)
这个键值对中key指定的是“张三”,但在redis中存储的是一串字符串编码,占用了十分多的空间,并且可读性差
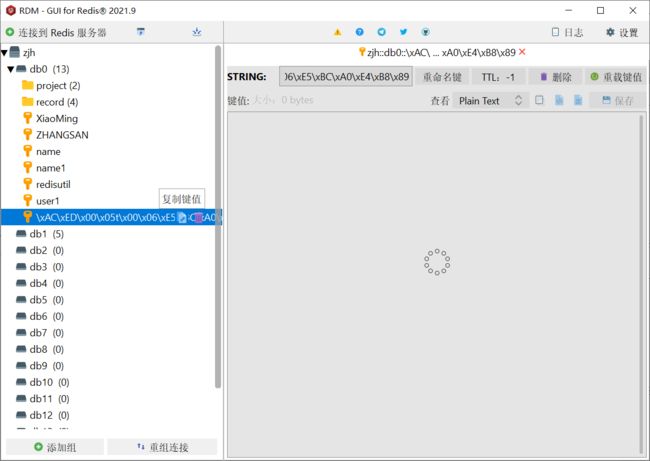
这是由于:使用了原生的JDK序列化器JdkSerializationRedisSerializer
补:问题分析
由于我们并没有对工具类RedisTemplate进行任何修改而直接使用,因此我们进入源码进行分析
默认序列化器defaultSerializer = null ;
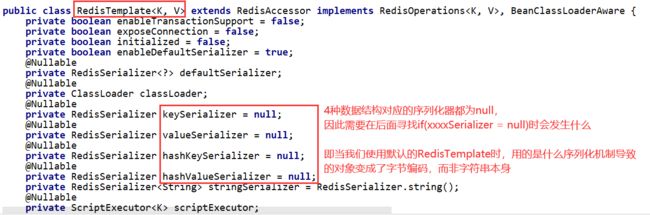
默认使用JDK序列化器
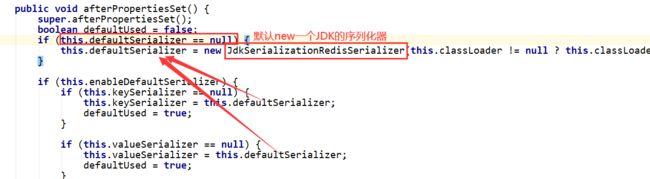
JDK序列化器JdkSerializationRedisSerializer的内核是对象流:把对象存储为字节码的形式,而不是文本,因此看到的必然乱码,同理用对象流保存数据到txt文件中也会乱码

补:解决问题
- JDK的序列化器协议不是JSON,因此我们需要一个能传JSON字符串的序列化器
- 既然是因为底层用了JDK序列化器JdkSerializationRedisSerializer,使用的对象流,那么我们只需要改变RedisTemplate的序列化器RedisSerializer,例如:StringRedisSerializer、GenericJackson2JsonRedisSerializer
补:序列化器、序列化协议
序列化协议
序列化协议参考
参考2
序列化协议有很多,流行的有:
- JDK序列化:底层是对象流(字节流),传输到redis上人类看不懂
- XML序列化:人类可读性强,底层是 字节流传输+xml解析
- JSON序列化:跨平台,可读性强,底层是 字节流传输+JSON解析
- FastJSON序列化:JSON的高性能库
为什么用JSON序列化替代JDK序列化
-
jdk的序列化,就是序列化成字节流通过网络传输到redis里面存起来,但是你查出来的就是直接序列化的你看不懂的字节流的形式,默认是十六进制数据
-
而其他满足JSON协议的序列化器,序列化成字节流通过网络传输到redis里面存起来的同时,还可以转化为字符串,让人类能够看得懂,本质上还是序列化
为什么Redis需要序列化
redis要序列化对象是使对象可以跨平台存储和进行网络传输。因为存储和网络传输都需要把一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象信息,所以进行“跨平台存储”和”网络传输”的数据都需要进行序列化。
改进:设置RedisSerializer序列化器
方案一:自动(反)序列化
- StringRedisSerializer:用于序列化String(Key和hashKey),并且传输之后能正确显示为String
- GenericJackson2JsonRedisSerializer: 满足JSON协议,用于序列化对象(value和hashValue)


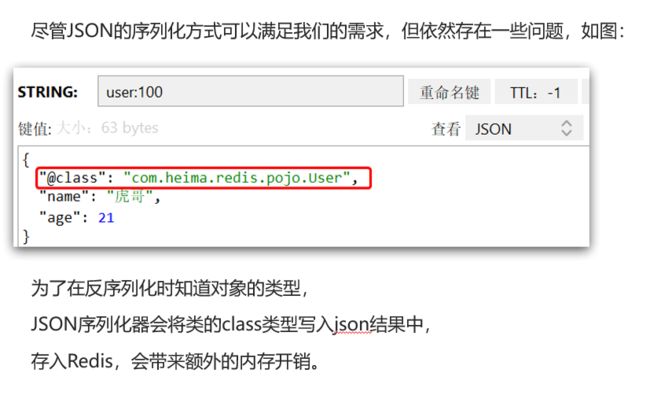
方案二:手动(反)序列化
-
JSON序列化器会把@class的类路径信息也进行包装传输,非常浪费时间,因此不能用JSON序列化器来传输对象
-
**使用StringRedisTemplate工具类(注意不是StringRedisSerializer序列化器)**来传输String字符串
ps:查看源码可知StringRedisTemplate是RedisTemplate的子类,配置好了键值对都必须是String
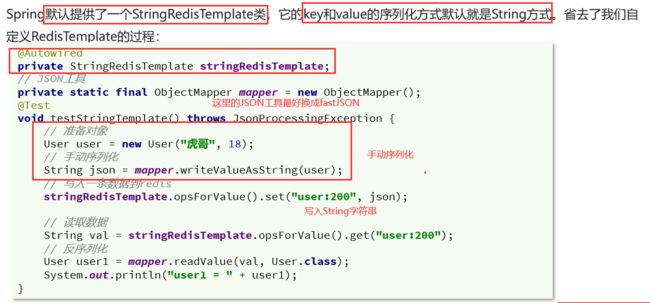
最佳方案三:FastJSON+StringRedisTemplate
- 方案3本质也是方案2
- 利用Fastjson把对象——>String字符串
- 利用Spring提供的StringRedisTemplate来把String字符串——>传输到redis,并且不乱码
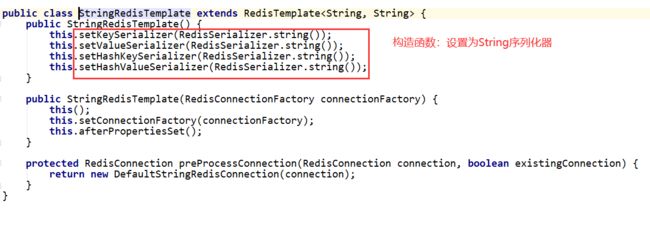
StringRedisTemplate源码解析
StringRedisTemplate本质是一个配置好String序列化器的RedisTemplate
下载Fastjson的jar包并导入,配置
具体操作步骤可以稍微参考下我的这一篇笔记,或者搜一下”如何导入FastJson“
操作步骤
或者参考菜鸟教程
测试fastjson是否可用
Managers managers = new Managers();
managers.setSex("男");
managers.setAge(18);
managers.setName("张三");
String s = JSON.toJSONString(managers);
System.out.println(s);
正式使用
- 直接注入StringRedisTemplate即可,配置信息在application.yaml中
- JSON即fastjson的工具类,主要调用toJSONString()和parseObject(,)两个方法
- 因为只对String进行操作,所以只需要opsForValue()即可:stringRedisTemplate.opsForValue().set()或.get()
示例:
@SpringBootTest
class BootAjaxtestApplicationTests {
//1.注入String序列化模板
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void test1(){
Managers managers = new Managers();
managers.setSex("男");
managers.setAge(18);
managers.setName("张三");
//2.fastjson序列化对象
String s = JSON.toJSONString(managers);
//3.写入数据到redis
stringRedisTemplate.opsForValue().set("test张三", s);
//4.读取数据并反序列化
String r = stringRedisTemplate.opsForValue().get("test张三");
Managers managers1 = JSON.parseObject(r, Managers.class);
System.out.println(managers1);//Managers(name=张三, sex=男, age=18)
}}
StringRedisTemplate之哈希表
- StringRedisTemplate只能对String进行交互,因此无论如何都要先用fastjson进行转换
- 增:
键值对: stringRedisTemplate.opsForValue().set(“test张三”, JSON.toJSONString(managers))
哈希表: stringRedisTemplate.opsForHash().put(“test李四”, “manager”, JSON.toJSONString(managers)); - 查:
键值对:stringRedisTemplate.opsForValue().get(“test张三”)
哈希表:stringRedisTemplate.opsForHash().entries(“test李四”) - JSON.parseObject()进行反序列化
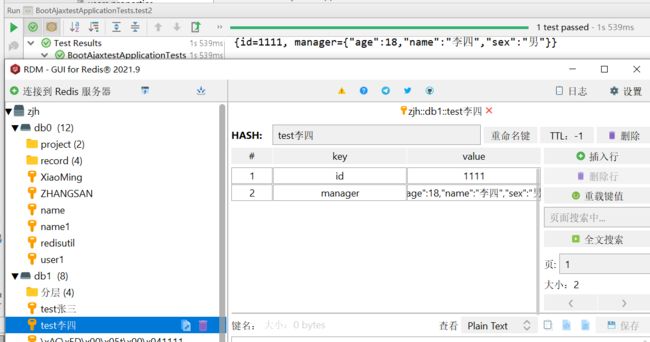
测试:
@Test
public void test2(){
Managers managers = new Managers();
managers.setSex("男");
managers.setAge(18);
managers.setName("李四");
stringRedisTemplate.opsForHash().put("test李四", "id","1111" );
stringRedisTemplate.opsForHash().put("test李四", "manager", JSON.toJSONString(managers));
Map map = stringRedisTemplate.opsForHash().entries("test李四");
System.out.println(map);
}
小结
- springboot项目可以统一使用StringRedisTemplate而不直接使用原生的RedisTemplate从而免去了很多配置
- 为了防止出现乱码,需要使用JSON转换框架例如:fastjson
- 配置信息直接写在application.yaml中