Q-learning理解、实现以及动态分配应用(一)
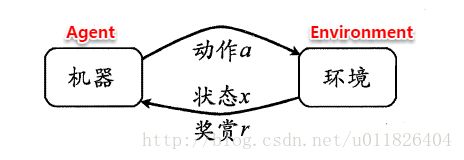
强化学习的概念,通俗的讲,强化学习就是通过agent,也就是动作的发起者,对环境造成一个影响,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。在强化学习中,包含两种基本的元素:状态与动作,在某个状态下执行某种动作,这便是一种策略,学习器要做的就是通过不断地探索学习,从而获得一个好的策略。
若将状态看作为属性,动作看作为标记,易知:监督学习和强化学习都是在试图寻找一个映射,从已知属性/状态推断出标记/动作,这样强化学习中的策略相当于监督学习中的分类/回归器。但在实际问题中,强化学习并没有监督学习那样的标记信息,通常都是在尝试动作后才能获得结果,因此强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到:在什么样的状态下选择什么样的动作可以获得最好的结果。
强化学习(Reinforcement Learning)是一种机器学习算法,强调如何基于环境而行动,以取得最大化的预期利益,在机器人领域应用较为广泛。Q-Learning属于强化学习的经典算法,用于解决马尔可夫决策问题。为无监督学习。
监督学习中的数据中是提前做好了分类的信息的,如垃圾邮件检测中,他的训练样本是提前存在分类的信息,也就是对垃圾邮件和非垃圾邮件的标记信息;无监督学习是另一种常用的机器学习算法,与监督学习不同的是,无监督学习的样本是不包含标签信息的,只有一定的特征,所以由于没有标签信息,学习过程中并不知道分类结果是否正确,比较典型的是一些聚合新闻网站,利用爬虫爬取新闻后对新闻进行分类的问题。无监督学习的典型问题就是上面说的聚类问题,比较有代表性的算法有K-Means算法(K均值算法)、DBSCAN算法等;聚类算法是无监督学习算法中最典型的一种学习算法,它是利用样本的特征,将具有相似特征的样本划分到同一个类别中,而不会去关心这个类别是什么;除了聚类算法外,无监督学习中还有一类重要的算法就是降维的算法,原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集的低维表示。
因此,强化学习的主要任务就是通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作。
一个策略的优劣取决于长期执行这一策略后的累积奖赏,换句话说:可以使用累积奖赏来评估策略的好坏,最优策略则表示在初始状态下一直执行该策略后,最后的累积奖赏值最高。长期累积奖赏通常使用下述两种计算方法:

http://mnemstudio.org/path-finding-q-learning-tutorial.htm







用python实现
QLearning:
1. :给定参数和R矩阵
2. 初始化 Q
3. for each episode:
3.1随机选择一个出事状态s
3.2若未达到目标状态,则执行以下几步
(1)在当前状态s的所有可能行为中选取一个行为a
(2)利用选定的行为a,得到下一个状态 。
(3)按照 Q(s,a)=R(s,a)+max{Q(,)}
(4)
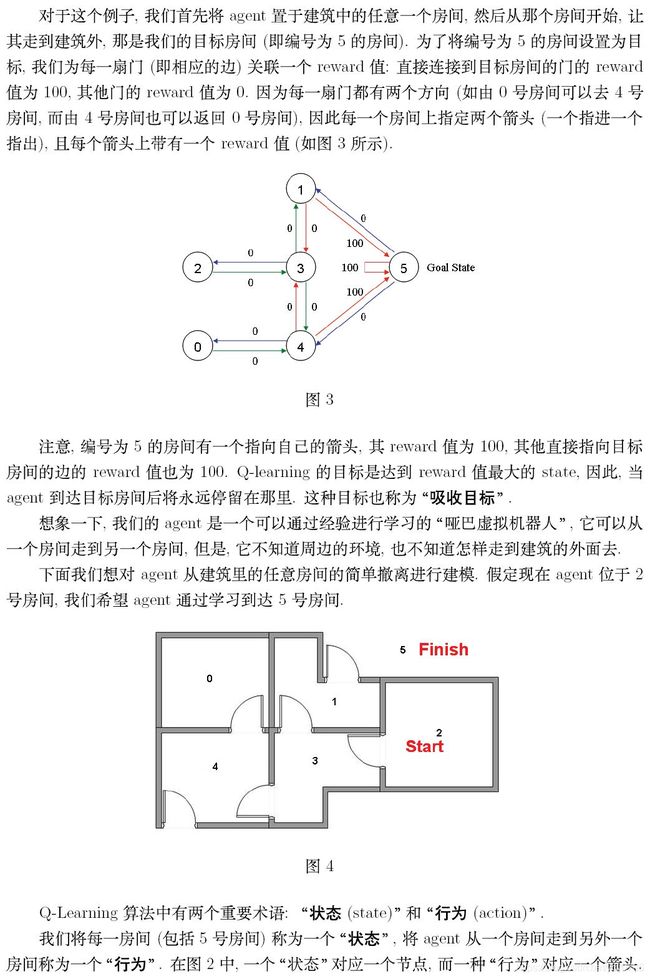
为学习参数, R为奖励机制, 为在s状态下,执行Q所得到的值。随机选择一个一个状态,即开始搜索的起点,在为100的点为终点。下面是程序。
import numpy as np
GAMMA = 0.8
Q = np.zeros((6,6))
R=np.asarray([[-1,-1,-1,-1,0,-1],
[-1,-1,-1,0,-1,100],
[-1,-1,-1,0,-1,-1],
[-1,0, 0, -1,0,-1],
[0,-1,-1,0,-1,100],
[-1,0,-1,-1,0,100]])
def getMaxQ(state):
return max(Q[state, :])
def QLearning(state):
curAction = None
for action in xrange(6):
if(R[state][action] == -1):
Q[state, action]=0
else:
curAction = action
Q[state,action]=R[state][action]+GAMMA * getMaxQ(curAction)
count=0
while count<1000:
for i in xrange(6):
QLearning(i)
count+=1
print Q/5
上部分转载来自 :https://blog.csdn.net/meyh0x5vDTk48P2/article/details/79607890
学习了一篇论文,使用Q-learning解决动态规划问题,下面是学习内容。
提出了一种将空间优化与多Agent Q-learning相结合的空间任务分配优化策略的智能方法,能够对大规模众包问题保持较高的效率。该方法通过一种基于网格的空间分析方法将空间众包优化分解为多个子目标。这种分解使每个Agent能够处理其空间区域中的某些子问题。在此背景下,可以将大规模复杂的众包问题作为每个学习Agent的简单任务分配进行优化。空间任务分配将其建模为一个复合MDP,并针对问题结构提出了一种简单的局部Q-learning方法,以使动态环境的长期回报最大化。 比以前的方法具有更好的可伸缩性。
本文的贡献在于介绍并讨论了如何将空间优化和多智能体Q-Learning相结合,作为空间众包的智能分配框架。提出的SMAQL将空间工作者和任务分配建模为系统优化问题,由协作Agent解决。所有这些协作代理都使用Q-learning员工和任务分配策略。Q-Learning使自治Agent能够监视其网格区域的状态,并采取影响其本地环境的行动,以便以协作的方式学习最优策略。SMAQL将Q-Learning扩展到空间任务分配中,使得协作区域Agent能够有效地优化大规模和不确定众包应用中的子问题。提出的算法可以有效地将空间任务分配给人群工作者。
补充 基础知识
增强学习(二)----- 马尔可夫决策过程MDP
马尔可夫决策过程(Markov Decision Processes,MDP)
强化学习研究的问题都是基于马尔可夫决策过程的,分为有限马尔可夫决策过程和无限马尔可夫决策过程。这里主要介绍有限马尔可夫决策过程。
马尔可夫性质:根据每个时刻观察到的状态,从可用的行动集合中选用一个行动作出决策,系统下一步(未来)的状态是随机的,并且其下一步状态与历史状态无关。
马尔可夫决策过程可以描述为:一个机器人(agent)通过采取行动(action)改变自身状态(state),与环境(E)互动得到回报(Reward)。目的是通过一定的行动策略(π)获得最大回报。它有5个元素构成:
S:所有可能的状态的集合(元素可能会很多,设计的时候需要合并或舍弃)
A:在状态S下可以做出的行为
p:Pa(S, S'),表示在a行为下t时刻状态S转化为t+1时刻状态S'的概率
Gamma:衰减变量,距离当前时刻t越远的回报R对当前决策的影响越小,避免在无限时间序列中导致的无偏向问题
V:衡量策略(π)的价值,与当前立即回报以及未来预期回报有关,v(S) = E [U|St],U = R(t+1)+Gamma*R(t+2)+Gamma^2*R(t+3)...,其中R(t+n)表示在t+n时刻的回报
转载:https://blog.csdn.net/mvksfg/article/details/72786729
1. 马尔可夫模型的几类子模型
大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM)。它们具有的一个共同性质就是马尔可夫性(无后效性),也就是指系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。
马尔可夫决策过程(Markov Decision Process, MDP)也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考虑更早之前的状态和动作,即s’是根据s和a随机生成的。
我们用一个二维表格表示一下,各种马尔可夫子模型的关系就很清楚了:
| 不考虑动作 | 考虑动作 | |
| 状态完全可见 | 马尔科夫链(MC) | 马尔可夫决策过程(MDP) |
| 状态不完全可见 | 隐马尔可夫模型(HMM) | 不完全可观察马尔可夫决策过程(POMDP) |
2. 马尔可夫决策过程
一个马尔可夫决策过程由一个四元组构成M = (S, A, Psa, ?) [注1]
- S: 表示状态集(states),有s∈S,si表示第i步的状态。
- A:表示一组动作(actions),有a∈A,ai表示第i步的动作。
- ?sa: 表示状态转移概率。?s? 表示的是在当前s ∈ S状态下,经过a ∈ A作用后,会转移到的其他状态的概率分布情况。比如,在状态s下执行动作a,转移到s'的概率可以表示为p(s'|s,a)。
- R: S×A⟼ℝ ,R是回报函数(reward function)。有些回报函数状态S的函数,可以简化为R: S⟼ℝ。如果一组(s,a)转移到了下个状态s',那么回报函数可记为r(s'|s, a)。如果(s,a)对应的下个状态s'是唯一的,那么回报函数也可以记为r(s,a)。
MDP 的动态过程如下:某个智能体(agent)的初始状态为s0,然后从 A 中挑选一个动作a0执行,执行后,agent 按Psa概率随机转移到了下一个s1状态,s1∈ Ps0a0。然后再执行一个动作a1,就转移到了s2,接下来再执行a2…,我们可以用下面的图表示状态转移的过程。

如果回报r是根据状态s和动作a得到的,则MDP还可以表示成下图:

3. 值函数(value function)
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
用Vπ(s)表示策略π下,状态s的值函数。ri表示未来第i步的立即回报,常见的值函数有以下三种:
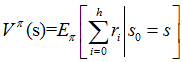


其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。接下来我们只讨论第三种形式,
现在将值函数的第三种形式展开,其中ri表示未来第i步回报,s'表示下一步状态,则有:
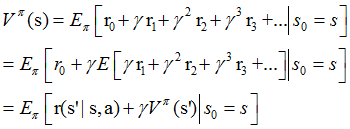
给定策略π和初始状态s,则动作a=π(s),下个时刻将以概率p(s'|s,a)转向下个状态s',那么上式的期望可以拆开,可以重写为:

上面提到的值函数称为状态值函数(state value function),需要注意的是,在Vπ(s)中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
定义动作值函数(action value functionQ函数)如下:

给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:

在Qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是Qπ(s,a)和Vπ(a)的主要区别。
知道值函数的概念后,一个MDP的最优策略可以由下式表示:

即我们寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
4. 值函数与Q函数计算的例子
上面的概念可能描述得不够清晰,接下来我们实际计算一下,如图所示是一个格子世界,我们假设agent从左下角的start点出发,右上角为目标位置,称为吸收状态(Absorbing state),对于进入吸收态的动作,我们给予立即回报100,对其他动作则给予0回报,折合因子γ的值我们选择0.9。
为了方便描述,记第i行,第j列的状态为sij, 在每个状态,有四种上下左右四种可选的动作,分别记为au,ad,al,ar。(up,down,left,right首字母),并认为状态按动作a选择的方向转移的概率为1。

1.由于状态转移概率是1,每组(s,a)对应了唯一的s'。回报函数r(s'|s,a)可以简记为r(s,a)
如下所示,每个格子代表一个状态s,箭头则代表动作a,旁边的数字代表立即回报,可以看到只有进入目标位置的动作获得了回报100,其他动作都获得了0回报。 即r(s12,ar) = r(s23,au) =100。

2. 一个策略π如图所示:
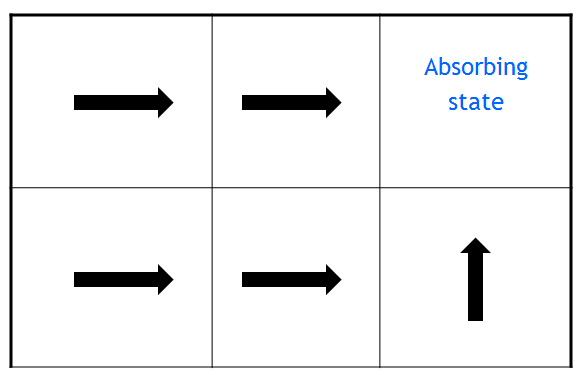
3. 值函数Vπ(s)如下所示
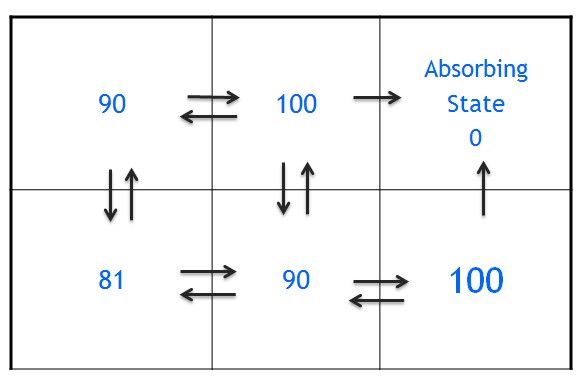
根据Vπ的表达式,立即回报,和策略π,有
Vπ(s12) = r(s12,ar) = r(s13|s12,ar) = 100
Vπ(s11)= r(s11,ar)+γ*Vπ(s12) = 0+0.9*100 = 90
Vπ(s23) = r(s23,au) = 100
Vπ(s22)= r(s22,ar)+γ*Vπ(s23) = 90
Vπ(s21)= r(s21,ar)+γ*Vπ(s22) = 81
4. Q(s,a)值如下所示

有了策略π和立即回报函数r(s,a), Qπ(s,a)如何得到的呢?
对s11计算Q函数(用到了上面Vπ的结果)如下:
Qπ(s11,ar)=r(s11,ar)+ γ *Vπ(s12) =0+0.9*100 = 90
Qπ(s11,ad)=r(s11,ad)+ γ *Vπ(s21) = 72
至此我们了解了马尔可夫决策过程的基本概念,知道了增强学习的目标(获得任意初始条件下,使Vπ值最大的策略π*),下一篇开始介绍求解最优策略的方法。
[注]采用折合因子作为值函数的MDP也可以定义为五元组M=(S, A, P, γ, R)。也有的书上把值函数作为一个因子定义五元组。还有定义为三元组的,不过MDP的基本组成元素是不变的。
转载:http://www.cnblogs.com/jinxulin/p/3517377.html
论文中引入马尔可夫决策过程。
传统上,优化方法需要先验知识,但是,这种方法并不适用于动态环境,在这种环境中,工作人员的可用性会受到频繁和不可预测的到来和变化的影响。为了解决这个问题,定义了一个组合MDP来建模动态和不确定的众包环境,引入了马尔可夫决策过程(MDP)的概念。MDP是一种典型的人工智能方法,用于不确定条件下顺序决策问题的建模。设计了MDP,对动态空间众包中的工人和任务分配和适应过程进行了示意性的演示。基本上,对于每个agent i,提出了基于马尔可夫决策过程的空间众包模型,称为SCMDP,它简单地用空间任务代替MDP中的状态,用人群工作者代替行动,用质量向量来奖励。
本文将大规模空间众包问题视为组合MDP的协作策略识别问题。组合MDP可以定义如下。
定义5(复合MDP)复合MDP是一组N分量的SCMDP{Mi}N1。
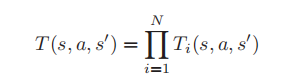
该模型旨在映射单个代理的情况,该代理并行地解决了不同的众包问题。一个大规模的复合材料MDP可以被形式化地分解为N个分量的SCMDP。因此,我们的目标是在复合MDP上找到最优策略。最优组合策略可以定义为使组件MDP的累计折扣报酬最大化的策略。
空间众包不同于传统的Q-Learning,因为每个学习Agent同时需要优化两个或多个目标[15],每个迭代学习步骤都提供奖励。在空间任务分配中存在N个子问题,学习Agent必须并行地为一组不同的子目标优化其行动策略。
本部分采用了一种多Agent协同技术.一个多Agent系统是由多个学习Agent组成的协作.多Agent可以解决单个Agent所要处理的复杂子问题.在此基础上,将多Agent协作技术集成到所提出的空间众包模型中,对于每个具有固定策略的Agent i(N≥i≥1),都有相应的代理。 有一个对应的状态-动作值函数![]() ,满足Bellman方程.
,满足Bellman方程.
总之,优化问题是基本体系结构的多目标问题。
马尔可夫问题求解
主要思想有3类:动态规划(不适用于大型问题),蒙特卡洛方法, Temporal-Difference Learning。其中蒙特卡洛方法与蒙特卡洛搜索树在原理上有相似性,容易被混淆。
Q-Learning属于Temporal-Difference Learning的一种,思想如下:

(来源:Reinforcement Learning - An Introduction,CHAPTER 6. TEMPORAL-DIFFERENCE LEARNING)

其中α是学习率,一般取(0,1)之间的数,学习率越大,收敛速度越快,但可能会导致过拟合问题。Q(S,A)指在状态S下执行A的质量(越大越好)
6.1多智能体Q学习在动态空间众包中的应用
在这一部分中,首先引入了Q-Learning来解决SCMDP问题,每个智能Agent都可以在Q-Learning的基础上优化自己的SCMDP问题。其次,定义了Q-Learning Agent的奖励函数.最后,提出了一种基于空间分解的多Agent Q-Learning算法,这使得Q-Learning Agent组能够有效地解决动态众包优化问题。
(1)SCMDP的Q-Learning算法
1)Agent Q-Learning迭代框架:优化目标是使SCMDP的累积报酬函数最大化。SCMDP的解决方案是策略π,它建议众包代理对给定的状态采取行动。策略由该策略生成的状态序列的实用程序值计算。最优策略意味着策略生成最高的实用价值。本文利用折扣奖励函数定义了状态序列的效用,
 (14)
(14)
在γ是折扣因子的情况下,它决定了未来奖励的重要性,而γ是介于0到1之间的一个数字。接近0的因素意味着代理人只考虑当前的奖励,而1的因数则意味着代理人一直在追求长期的高回报。
- Learning的目的是最大化回报效用。它的工作方式是学习在给定状态下采取行动的预期效用,并确定最优策略。Q-Learning已经被证明,它最终确定了在任何有限的MDP上的最优策略。
对于每个s和a,代理智能地选择动作并观察可能同时依赖于先前状态和所选动作的奖励和新状态,q被更新。Q-Learning算法的核心是简单的Q(s,a)迭代更新.在每次q(s,a)为当前存储Qπ的估计Q-值表使用以下规则进行更新:
 (15)
(15)
学习速率α∈[0,1]决定了现有的Qπ(s,a)估计对新估计的贡献。如果代理的策略随着时间的推移趋向于贪婪的选择,则q(s,a)值 E最终收敛于最优值函数q∗(s,a)。为了实现这一点,使用了Boltzman概率,它决定了选择随机操作的概率。
2)Agent Q-Learning的奖励函数:Q-Learning是处理序贯决策问题的有效方法[11]。为了最大限度地获得长期回报,Q-Learning是用来帮助代理人的。 在动态的众包环境中选择员工。在本文中,基于众包的工人与任务分配是一个双目标优化问题.
假设一群工作人员完成一项空间任务可以通过质量分数![]() 进行评估。此外,它要求每个人群工作者从地点x到y来执行任务,这就产生了一个旅行成本qostc。旅费由两个地点之间的距离Dist(x,y)决定。在此背景下,利用QoS向量[qosqs,qostc]估计奖励函数。由于每个QoS属性的范围不同,需要将QoS值映射到间隔[0,1]中。使用max-min作为操作符,映射函数可以定义为
进行评估。此外,它要求每个人群工作者从地点x到y来执行任务,这就产生了一个旅行成本qostc。旅费由两个地点之间的距离Dist(x,y)决定。在此背景下,利用QoS向量[qosqs,qostc]估计奖励函数。由于每个QoS属性的范围不同,需要将QoS值映射到间隔[0,1]中。使用max-min作为操作符,映射函数可以定义为
鉴于现实世界的众包问题需要在多个质量目标之间进行权衡。空间众包的回报函数是加权和法,它计算所有目标的q值的线性加权和。
 (16)
(16)
权重可以使用户有能力或多或少地强调人群的每一个质量目标。在学习迭代过程中,众包代理通过最大限度地获取收益的总和来确定其最优的众包环境策略。我们设计了一个Q-Learning框架来描述解决SCMDP问题的学习过程,如图1所示。

6.2 基于空间感知的多智能体Q-学习在动态任务分配中的应用
Q-Learning在解决简单决策问题的可扩展性方面受到限制.然而,大规模的众包问题本质上是复杂的和空间的工人和任务分配是与如此众多的人群工作者候选人和众包任务。因此,在这一部分中,我们提出了一种新的有效的分布式算法,称为空间感知多智能体Q-Learning(SMAQL),解决大规模的分配问题。SMAQL结合了空间优化和多Agent Q-Learning技术的进展.
SMAQL首先基于网格空间分析方法将整个众包问题划分为n个子问题.每个子问题都由较小规模的群体工作者组成,从而扩展了Q学习技术来解决多目标子问题.多目标问题可由一组q-学习Agent Agent1,Agent2,···,Agent n有效地解决。
- 基于网格的众包分解空间分析:SMAQL的挑战在于找到一种将复杂的空间众包问题分解为子问题的方法。提出了一种基于网格的分布式空间众包分解方法.将复杂的众包问题分解为基于网格索引的子问题。
多Agent Q-Learning采用一种基于网格的空间分析方法,将大规模的位置数据处理到空间众包上。在这种情况下,整个MDP数据由几个分区组成,这些分区是通过将每个维度分割成一个预先定义的片数来创建的。每个分区都具有二维网格的形式。在下面,一个网格区域i是由代理Agent i学习的。网格可以用地理边界来表示。本文以网格区域的左下角和右上角分别表示的两点l i和uj定义了网格区域Gridi。

基于网格的空间分解可以有效地将空间众包问题划分为子问题。然后,用SMAQL分别求解每个子问题.
2)SMAQL算法:一个空间众包问题是将一组空间任务分配给一组人群,同时满足几个特定的质量约束。为了解决这一问题,我们提出了一种基于空间感知的多智能体在众包应用中的动态任务匹配方法。为了不断提高众包的性能,我们将Q-Learning技术引入到决策实体中,并将其建模为Agent.Agent同时发现最优解用Q-Learning算法求解子问题。
每个众包子问题都是作为一个独立的Q-Learning来解决的,这使得每个Agent能够适应并学习如何为空间任务分配最好的工作人员。第一代众包代理Q-Learning的更新规则可以定义为
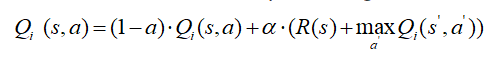 (17)
(17)
如果N≥i≥1和α是学习速率的参数,则可以根据HQ(s,a)确定整体的单一策略,该策略可以使用所有子目标的Q值来导出。在每个状态,第一个众包代理确定了优化其本地区域网格效用的工人候选人。每个代理人都建议自己的工作和任务分配与齐值。
此外,为了选择全局最优的工人和任务动作,将Top-Q-Learning技术集成到了所提出的SMAQL算法中。SMAQL将HQ值指定为众包状态下的最高Q值.任务和工作分配操作基于最大HQ值,而HQ(s,a)可以计算为
 (18)
(18)
在当前s的情况下,计算每个众包代理的![]() 值。最大的HQ值可以导出为
值。最大的HQ值可以导出为
 (19)
(19)
总之,SMAQL算法的全局众包功能可以定义为:
![]() (20)
(20)
在SMAQL中,工人和任务分配操作对于空间众包来说是最优的.在每个步骤中,在选择并执行具有最高HQ值的工人和任务分配操作之后,通过上述定义中的规则更新最高Q值。