Spark Streaming(二)Spark Streaming整合Kafka
现在工作中正在使用flink,避免对Spark流式处理的遗忘,在此进行总结。主要分为以下几个方面,均附有实际代码:
- Spark Streaming简介
- Spark Streaming架构
- 基础概念
- 作业提交
- Spark Streaming窗口操作
- Spark Streaming容错性分析
- WAL工作原理
- Spark Streaming整合Kafka
- createStream与createDirectStream的区别
- 连接kafka0.8与Kafka0.10的区别
- Spark Streaming应用程序如何保证Exactly-Once?
- 代码优化
3.Spark Streaming整合Kafka
3.1createStream与createDirectStream的区别
createStream
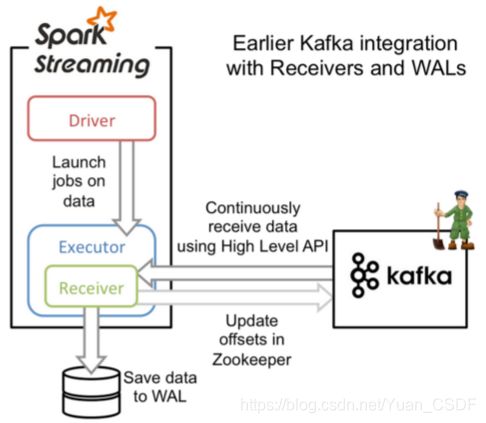
offset存储在zookeeper,由Receiver维护,Spark获取数据存入executor中,调用Kafka高阶API。
此方法Receiver接收数据。Receiver是使用Kafka高级消费者API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark执行器中,然后由Spark Streaming启动的作业处理数据。但是,在默认配置下,此方法可能会在失败时丢失数据(为确保零数据丢失,必须在Spark Streaming中另外启用Write Ahead Logs(在Spark 1.2中引⼊)。这将同步保存所有收到的Kafka将数据写入分布式文件系统(例例如HDFS)上的预写日志,以便在发⽣故障时可以恢复所有数据,但是性能不不好。
createDirectStream

offset存储和维护,由Spark Driver维护,且可以从每个分区读取数据,从调用Kafka低阶API
这种新的不基于Receiver的直接⽅方式,是在Spark 1.3中引⼊的,从⽽能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种⽅式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
区别:
- 简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafkapartition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDDpartition之间,有一个一对一的映射关系。
- 高性能:如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,⽽这⾥又会复制一份到WAL中。而基于direct的⽅方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。
- 一次且仅一次的事务机制: 基于receiver的⽅方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
- 降低资源。 Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够⽀持更大的业务。
- 降低内存。 Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并⽆无需那么多的内存。⽽而Direct 因为没Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
- 鲁棒性更好。 Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch 计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
3.2连接kafka0.8与Kafka0.10的区别
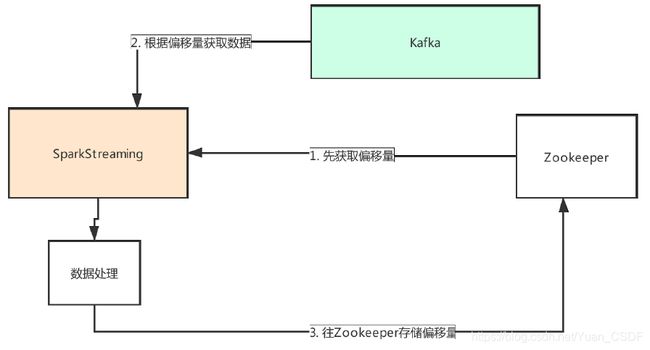
Spark与Kafka0.8结合使用。是通过Spark的Receiver维护。要想保证数据不丢失,最简单的就是靠checkpoint的机制,但是checkpoint机制有个特点,代码升级了,checkpoint机制就失效了。所以如果想实现数据不丢失,那么就需要自己管理offset。即需要自己开发代码维护偏移量。核心代码如下:
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"group.id" -> groupId,
"enable.auto.commit" -> "false"
)
//关键步骤一:设置监听器,帮我们完成偏移量的提交
/**
* 监听器的作用就是,我们每次运行完一个批次,就帮我们提交一次偏移量。
* 比方说,foreach运行完后会自动提交任务
*/
ssc.addStreamingListener(
new MyListener(kafkaParams));
//关键步骤二: 创建对象,然后通过这个对象获取到上次的偏移量,然后获取到数据流
val km = new KafkaManager(kafkaParams)
//步骤三:创建一个程序入口 //从上一次 偏移量开始消费
val messages = km.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
//messages 确实是还有我们的偏移量的信息的
messages.foreachRDD(rdd=>{
/**
* DStream --> RDD
*
*/
/**
* 业务处理(RDD)
*/
/**
* 偏移量提交
*/
})
//完成你的业务逻辑即可
messages
.map(_._2) // 这里会让message中的偏移量信息丢失
.flatMap(_.split(","))
.map((_,1))
.foreachRDD( rdd =>{
rdd.foreach( line =>{
// println(line)
//
// println("-==============进行业务处理就可以了=====================batch=========")
// //就把处理结果存储到Mysql,hbase,kafka
})
})
ssc.start()
ssc.awaitTermination()
ssc.stop()偏移量存在zookeeper,有可视化工具。但是Spark Streaming任务较多时,对zookeeper压力较大。
在Kafka0.10中,偏移量存在了Kafka自己的Topic中。

Kafka0.8默认偏移量存于zookeeper
kafka0.10默认偏移量存于Kafka的_consumer_offset主题
3.3Spark Streaming应用程序如何保证Exactly-Once?
一个流式计算如果想要保证Exactly-Once(不重不丢),那么首先要对这三个点有有要求:
(1)Source支持Replay。 (2)流计算引擎本身处理理能保证Exactly-Once。 (3)Sink支持幂等或事务更新
也就是说如果要想让一个SparkSreaming的程序保证Exactly-Once,那么从如下三个角度出发:
(1)接收数据:从Source中接收数据。 (2)转换数据:用DStream和RDD算子转换。(SparkStreaming内部天然保证Exactly-Once) (3)储存数据:将结果保存至外部系统。 如果SparkStreaming程序需要实现Exactly-Once语义,那么每一个步骤都要保证Exactly-Once。
代码如下:
/**
* SparkStreaming EOS:
* Input:Kafka
* Process:Spark Streaming
* Output:Mysql
*
* 保证EOS:
* 1、偏移量自己管理,即enable.auto.commit=false,这里保存在Mysql中
* 我们这次的方案没有把偏移量存储到zk,或者是kafka
* 2、使用createDirectStream
* 3、事务输出: 结果存储与Offset提交在Driver端同一Mysql事务中
*/
object SparkStreamingEOSKafkaMysqlAtomic {
@transient lazy val logger = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
val topic="topic1"
val group="spark_app1"
//Kafka配置
val kafkaParams= Map[String, Object](
"bootstrap.servers" -> "node1:6667,node2:6667,node3:6667",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"auto.offset.reset" -> "latest",//latest earliest
"enable.auto.commit" -> (false: java.lang.Boolean),
"group.id" -> group)
//在Driver端创建数据库连接池
ConnectionPool.singleton("jdbc:mysql://node3:3306/bigdata", "", "")
val conf = new SparkConf().setAppName(this.getClass.getSimpleName.replace("$",""))
val ssc = new StreamingContext(conf,Seconds(5))
//1)初次启动或重启时,从指定的Partition、Offset构建TopicPartition
//2)运行过程中,每个Partition、Offset保存在内部currentOffsets = Map[TopicPartition, Long]()变量中
//3)后期Kafka Topic分区动扩展,在运行过程中不能自动感知
val initOffset=DB.readOnly(implicit session=>{
sql"select `partition`,offset from kafka_topic_offset where topic =${topic} and `group`=${group}"
.map(item=> new TopicPartition(topic, item.get[Int]("partition")) -> item.get[Long]("offset"))
.list().apply().toMap
})
//CreateDirectStream
//从指定的Topic、Partition、Offset开始消费
val sourceDStream =KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Assign[String,String](initOffset.keys,kafkaParams,initOffset)
)
sourceDStream.foreachRDD(rdd=>{
if (!rdd.isEmpty()){
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(offsetRange=>{
logger.info(s"Topic: ${offsetRange.topic},Group: ${group},Partition: ${offsetRange.partition},fromOffset: ${offsetRange.fromOffset},untilOffset: ${offsetRange.untilOffset}")
})
//统计分析
//将结果收集到Driver端
val sparkSession = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import sparkSession.implicits._
val dataFrame = sparkSession.read.json(rdd.map(_.value()).toDS)
dataFrame.createOrReplaceTempView("tmpTable")
val result=sparkSession.sql(
"""
|select
| --每分钟
| eventTimeMinute,
| --每种语言
| language,
| -- 次数
| count(1) pv,
| -- 人数
| count(distinct(userID)) uv
|from(
| select *, substr(eventTime,0,16) eventTimeMinute from tmpTable
|) as tmp group by eventTimeMinute,language
""".stripMargin
).collect()
//在Driver端存储数据、提交Offset
//结果存储与Offset提交在同一事务中原子执行
//这里将偏移量保存在Mysql中
//事务
DB.localTx(implicit session=>{
//结果存储
result.foreach(row=>{
sql"""
insert into twitter_pv_uv (eventTimeMinute, language,pv,uv)
value (
${row.getAs[String]("eventTimeMinute")},
${row.getAs[String]("language")},
${row.getAs[Long]("pv")},
${row.getAs[Long]("uv")}
)
on duplicate key update pv=pv,uv=uv
""".update.apply()
})
//Offset提交
offsetRanges.foreach(offsetRange=>{
val affectedRows = sql"""
update kafka_topic_offset set offset = ${offsetRange.untilOffset}
where
topic = ${topic}
and `group` = ${group}
and `partition` = ${offsetRange.partition}
and offset = ${offsetRange.fromOffset}
""".update.apply()
if (affectedRows != 1) {
throw new Exception(s"""Commit Kafka Topic: ${topic} Offset Faild!""")
}
})
})
}
})
ssc.start()
ssc.awaitTermination()
}
}
3.4代码优化
spark流式任务输出到外部数据源,既要保证输出精准一次消费,又要关注连接资源。在这里使用数据库连接池,代码如下:
def main(args: Array[String]) {
val sparkConf = new
SparkConf().setAppName("NetworkWordCountForeachRDD").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(5))
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("master", 9998,
StorageLevel.MEMORY_AND_DISK_SER)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//将结果保存到Mysql(七)
wordCounts.foreachRDD { (rdd, time) =>
rdd.foreachPartition { partitionRecords =>
val conn = ConnectionPool.getConnection
conn.setAutoCommit(false)
val statement = conn.prepareStatement(s"insert into wordcount(ts, word, count) values (?, ?, ?)")
partitionRecords.zipWithIndex.foreach { case ((word, count), index) =>
statement.setLong(1, time.milliseconds)
statement.setString(2, word)
statement.setInt(3, count)
statement.addBatch()
if (index != 0 && index % 500 == 0) {
statement.executeBatch()
conn.commit()
}
}
statement.executeBatch()
statement.close()
conn.commit()
conn.setAutoCommit(true)
ConnectionPool.returnConnection(conn)
}
}
//等待Streaming程序终止
ssc.awaitTermination()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
}其中ConnectionPool代码如下:
private static ComboPooledDataSource dataSource = new ComboPooledDataSource();
static {
dataSource.setJdbcUrl("jdbc:mysql://master:3306/test"); //设置连接数据库的URL
dataSource.setUser("root"); //设置连接数据库的用户名
dataSource.setPassword("root"); //设置连接数据库的密码
dataSource.setMaxPoolSize(40); //设置连接池的最大连接数
dataSource.setMinPoolSize(2); //设置连接池的最小连接数
dataSource.setInitialPoolSize(10); //设置连接池的初始连接数
dataSource.setMaxStatements(100); //设置连接池的缓存Statement的最大数
}
public static Connection getConnection() {
try {
return dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
public static void returnConnection(Connection connection) {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}