Apache Kyuubi调研
1. QuickStart
1.1 下载安装启动
下载:https://github.com/NetEase/kyuubi/releases
tar zxvf kyuubi-1.2.0-bin-spark-3.0-hadoop2.7.tar.gz
cd /opt/software/kyuubi-1.2.0-bin-spark-3.0-hadoop2.7/bin
./kyuubi start

1.2 打开连接
Kyuubi服务器兼容Apache Hive beeline,也可以用$KYUUBI_HOME/externals/spark-3.0.1-bin-hadoop2.7/bin/beeline,我这里自己搭建了spark集群,所以直接使用的spark中的beeline
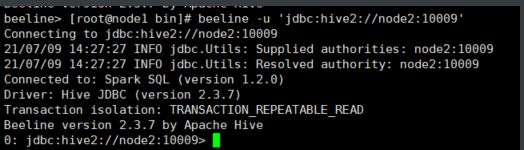
在这种情况下,会话将为名为“anonymous”的用户创建。
可以为另一个用户创建一个新的会话,比如名字为***zhoujing***

beeline -u 'jdbc:hive2://node2:10009' -n zhoujing

在这种情况下,之前为用户 ‘anonymous’ 创建的 Spark 应用程序将不会被重用,而是会为用户 ‘zhoujing’ 提交一个全新的应用程序。
可以看到本地环境中运行了三个进程,一个是KyuubiServer实例和两个SparkSubmit实例作为SQL引擎

1.3 执行语句
beeline 会话成功连接,那么您现在可以运行 Spark SQL 支持的任何查询。例如,
jdbc:hive2://node2:10009> select timestamp '2018-11-17';
2021-07-09 14:37:37.240 INFO operation.ExecuteStatement: Processing zhoujing's query[6cb35d18-7d89-489d-b016-4ae95d18ac76]: INITIALIZED_STATE -> PENDING_STATE, statement: select timestamp '2018-11-17'
2021-07-09 14:37:37.243 INFO operation.ExecuteStatement: Processing zhoujing's query[6cb35d18-7d89-489d-b016-4ae95d18ac76]: PENDING_STATE -> RUNNING_STATE, statement: select timestamp '2018-11-17'
2021-07-09 14:37:37.241 INFO operation.ExecuteStatement: Processing zhoujing's query[f10b2988-a92e-4409-9d96-6a67d7ad11d9]: INITIALIZED_STATE -> PENDING_STATE, statement: select timestamp '2018-11-17'
2021-07-09 14:37:37.242 INFO operation.ExecuteStatement: Processing zhoujing's query[f10b2988-a92e-4409-9d96-6a67d7ad11d9]: PENDING_STATE -> RUNNING_STATE, statement: select timestamp '2018-11-17'
2021-07-09 14:37:37.246 INFO operation.ExecuteStatement:
Spark application name: kyuubi_USER_zhoujing_61789680-18a2-4b07-8cfb-32fccab442b6
application ID: local-1625812350788
application web UI: http://node2:46202
master: local[*]
deploy mode: client
version: 3.0.2
Start time: 2021-07-09T06:32:29.296Z
User: zhoujing
2021-07-09 14:37:37.300 INFO spark.SparkContext: Starting job: collect at ExecuteStatement.scala:82
2021-07-09 14:37:37.311 INFO kyuubi.SQLOperationListener: Query [f10b2988-a92e-4409-9d96-6a67d7ad11d9]: Job 1 started with 1 stages, 1 active jobs running
2021-07-09 14:37:37.311 INFO kyuubi.SQLOperationListener: Query [f10b2988-a92e-4409-9d96-6a67d7ad11d9]: Stage 1 started with 1 tasks, 1 active stages running
2021-07-09 14:37:37.326 INFO kyuubi.SQLOperationListener: Finished stage: Stage(1, 0); Name: 'collect at ExecuteStatement.scala:82'; Status: succeeded; numTasks: 1; Took: 21 msec
2021-07-09 14:37:37.326 INFO scheduler.StatsReportListener: task runtime:(count: 1, mean: 8.000000, stdev: 0.000000, max: 8.000000, min: 8.000000)
2021-07-09 14:37:37.326 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.327 INFO scheduler.StatsReportListener: 8.0 ms 8.0 ms 8.0 ms 8.0 ms 8.0 ms 8.0 ms 8.0 ms 8.0 ms 8.0 ms
2021-07-09 14:37:37.327 INFO scheduler.StatsReportListener: shuffle bytes written:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
2021-07-09 14:37:37.327 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.327 INFO scheduler.StatsReportListener: 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B
2021-07-09 14:37:37.328 INFO scheduler.StatsReportListener: fetch wait time:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
2021-07-09 14:37:37.328 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.328 INFO scheduler.StatsReportListener: 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms 0.0 ms
2021-07-09 14:37:37.329 INFO scheduler.StatsReportListener: remote bytes read:(count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
2021-07-09 14:37:37.329 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.329 INFO scheduler.StatsReportListener: 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B 0.0 B
2021-07-09 14:37:37.330 INFO scheduler.StatsReportListener: task result size:(count: 1, mean: 1402.000000, stdev: 0.000000, max: 1402.000000, min: 1402.000000)
2021-07-09 14:37:37.331 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.331 INFO scheduler.StatsReportListener: 1402.0 B 1402.0 B 1402.0 B 1402.0 B 1402.0 B 1402.0 B 1402.0 B 1402.0 B 1402.0 B
2021-07-09 14:37:37.332 INFO scheduler.StatsReportListener: executor (non-fetch) time pct: (count: 1, mean: 12.500000, stdev: 0.000000, max: 12.500000, min: 12.500000)
2021-07-09 14:37:37.332 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.332 INFO scheduler.StatsReportListener: 13 % 13 % 13 % 13 % 13 % 13 % 13 % 13 % 13 %
2021-07-09 14:37:37.333 INFO scheduler.StatsReportListener: fetch wait time pct: (count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000)
2021-07-09 14:37:37.333 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.333 INFO scheduler.StatsReportListener: 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 % 0 %
2021-07-09 14:37:37.334 INFO scheduler.StatsReportListener: other time pct: (count: 1, mean: 87.500000, stdev: 0.000000, max: 87.500000, min: 87.500000)
2021-07-09 14:37:37.334 INFO scheduler.StatsReportListener: 0% 5% 10% 25% 50% 75% 90% 95% 100%
2021-07-09 14:37:37.334 INFO scheduler.StatsReportListener: 88 % 88 % 88 % 88 % 88 % 88 % 88 % 88 % 88 %
2021-07-09 14:37:37.334 INFO kyuubi.SQLOperationListener: Query [f10b2988-a92e-4409-9d96-6a67d7ad11d9]: Job 1 succeeded, 0 active jobs running
2021-07-09 14:37:37.334 INFO scheduler.DAGScheduler: Job 1 finished: collect at ExecuteStatement.scala:82, took 0.034323 s
2021-07-09 14:37:37.338 INFO operation.ExecuteStatement: Processing zhoujing's query[f10b2988-a92e-4409-9d96-6a67d7ad11d9]: RUNNING_STATE -> FINISHED_STATE, statement: select timestamp '2018-11-17', time taken: 0.096 seconds
2021-07-09 14:37:37.345 INFO operation.ExecuteStatement: Query[6cb35d18-7d89-489d-b016-4ae95d18ac76] in FINISHED_STATE
2021-07-09 14:37:37.345 INFO operation.ExecuteStatement: Processing zhoujing's query[6cb35d18-7d89-489d-b016-4ae95d18ac76]: RUNNING_STATE -> FINISHED_STATE, statement: select timestamp '2018-11-17', time taken: 0.102 seconds
+----------------------------------+
| TIMESTAMP '2018-11-17 00:00:00' |
+----------------------------------+
| 2018-11-17 00:00:00.0 |
+----------------------------------+
1 row selected (0.124 seconds)
操作日志中还会打印一些有关与此连接关联的后台 Spark SQL 应用程序的有用信息。例如,可以从日志中获取 Spark Web UI 以进行调试或调整。



1.4 停止服务
bin/kyuubi stop
发现问题,次命令可以讲KyuubiServer进程停掉,但是启动的两个SparkSubmit无法停止,bug~~~
1.5 用DBeaver进行连接
看看元数据在哪里
DESC NAMESPACE DEFAULT;
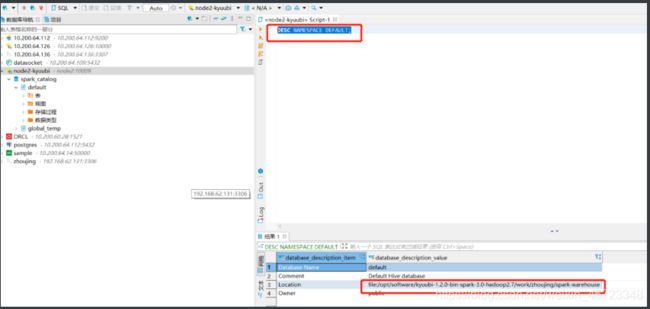
创建张表,插入条数据试试:
CREATE TABLE spark_catalog.`default`.SRC(KEY INT, VALUE STRING) USING PARQUET;
INSERT INTO TABLE spark_catalog.`default`.SRC VALUES (11215016, 'Kent Yao');
查询看看
SELECT KEY % 10 AS ID, SUBSTRING(VALUE, 1, 4) AS NAME FROM spark_catalog.`default`.SRC;

删除看看
DROP TABLE spark_catalog.`default`.SRC;
删除完全OK

1.6 用java的jdbc进行连接
pom中需要引用的依赖如下:
org.apache.hive
hive-jdbc
2.3.7
org.apache.hadoop
hadoop-common
2.7.3
代码如下所示:
package com.gridsum.datacenter;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.sql.*;
public class KyuubiJDBC {
private static String drivername = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://node2:10009/default;";
private static Connection conn = null;
private static Statement statement = null;
private static ResultSet res = null;
@Before
public void init() throws ClassNotFoundException, SQLException {
Class.forName(drivername);
conn = DriverManager.getConnection(url, "zhoujing", "zhoujing");
statement = conn.createStatement();
}
@After
public void destory() throws SQLException {
if (res != null) statement.close();
if (statement != null) statement.close();
if (conn != null) conn.close();
}
/**
* 查看所有库
*/
@Test
public void showDB() throws SQLException {
res = statement.executeQuery("show databases");
while (res.next()){
System.out.println(res.getString(1));
}
}
/**
* 创建表
*/
@Test
public void createTable() throws SQLException {
statement.execute("CREATE TABLE " +
"spark_catalog.`default`.TEST(KEY INT, VALUE STRING) " +
"USING ORC");
}
/**
* 查看表结构
*/
@Test
public void descTab() throws SQLException {
res = statement.executeQuery("desc spark_catalog.`default`.TEST");
while (res.next()){
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
}
/**
* 加载数据
*/
@Test
public void loadData() throws SQLException {
statement.execute("INSERT INTO TABLE " +
"spark_catalog.`default`.TEST " +
"VALUES (2900084, 'Zhoujing');");
}
/**
* 查看表中数据
*/
@Test
public void queryData() throws SQLException {
res = statement.executeQuery("SELECT * FROM spark_catalog.`default`.TEST;");
ResultSetMetaData metadata = res.getMetaData();
int count = metadata.getColumnCount();
while (res.next()){
for (int i = 1; i <= count; i++) {
System.out.print(res.getString(i));
System.out.print("\t");
}
System.out.println();
}
}
}
2. Kyuubi 高可用调研
2.1 非HA模式下,使用内嵌Zookeeper
如果未启动HA模式情况下启动KyuubiServer则内部是内嵌了一个Zookeeper,使用的端口默认为2181,如果与Hadoop集群合部的情况下,会报错,2181端口被占用。

分开端口后,启动内嵌zookeeper的情况如下图所示:

2.2 Kyuubi高可用
作为基于Apache Spark构建的企业级 ad-hoc SQL 查询服务,Kyuubi 以高可用性 (HA) 为主要特性,旨在确保约定的服务可用性水平,例如高于正常的正常运行时间。
在 HA 模式下运行 Kyuubi 是在 Kyuubi 上使用支持 SQL 查询服务的计算机或容器组,这些计算机或容器可以在最少停机时间的情况下可靠地使用。Kyuubi 通过使用Apache ZooKeeper在组中利用冗余服务实例来运行,这些实例在一个或多个组件出现故障时提供持续服务。
如果没有 HA,如果服务器崩溃,Kyuubi 将无法使用,直到崩溃的服务器被修复。有了 HA,这种情况将通过硬件/软件故障自动检测来补救,并且另一个 Kyuubi 服务实例将立即准备好提供服务,而无需人工干预。
2.2.1 负载均衡
对于企业服务,服务级别协议 (SLA) 承诺必须非常高。并且并发性需要足够健壮以支持整个企业的请求。Spark Thrift Server 作为单一的 Spark 应用,没有高可用,很难满足 SLA 和并发需求。当有大的查询请求时,Spark Driver 的元数据服务访问、调度和内存压力,或者应用程序的整体计算资源约束都存在潜在的瓶颈。
Kyuubi提供基于Zookeeper的高可用和负载均衡解决方案, 如下图所示
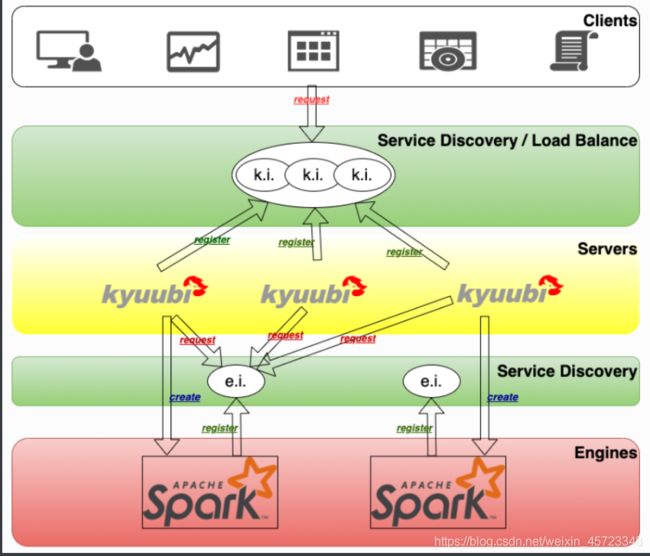
- 图的顶部是客户层。一个客户端可以从服务发现层的命名空间中找到多个注册的 Kyuubi 实例(ki)实例,然后选择连接。注册到同一命名空间的 Kyuubi 实例提供了相互负载平衡的能力。
- 选定的 Kyuubi 实例将从服务发现层的引擎命名空间中选择一个可用的引擎实例 (ei) 来建立连接。如果没有找到可用的实例,它会创建一个新的实例,等待引擎完成注册,然后继续连接。
- 如果同一个人请求新的连接,该连接将建立到同一个或另一个 Kyuubi 实例,但引擎实例将被重用。
- 对于来自不同用户的连接,将重复步骤 2 和 3。这是因为在服务发现层,用于存储引擎实例地址的命名空间是基于用户隔离的(默认情况下),不同的用户不能跨命名空间访问其他的实例。
2.2.2 配置
使用 Hive JDBC Driver,客户端可以在 JDBC 连接字符串中指定服务发现模式,即serviceDiscoveryMode=zooKeeper;和 set zooKeeperNameSpace=kyuubiserver;,然后它可以从/kyuubiserver路径中指定的 ZooKeeper 地址中随机选择一个 Kyuubi 服务 uri 。
当我们设置kyuubi.ha.enabled为 时true,默认情况下启用负载平衡模式。请确保通过kyuubi.ha.zookeeper.quorum和指定正确的 ZooKeeper 地址kyuubi.ha.zookeeper.client.port。
下面我们操作一下:
配置kyuubi-defaults.conf中添加下面项目 :
kyuubi.ha.enabled true
kyuubi.ha.zookeeper.quorum zhoujing:2181,node1:2181,node2:2181
kyuubi.ha.zookeeper.client.port 2181

启动两个节点:效果如下

连接方式也是不一样的,可以用beeline直接连接zk集群
./beeline -u "jdbc:hive2://zhoujing:2181,node1:2181,node2:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi" --property-file ../conf/hive-site.xml -n zhoujing
2.2.3 AQS
1)SparkContext初始化失败**
连接方式与上面一致:


经过定位发现是由于hadoop代理用户未开启权限的问题。
修改hadoop的配置core-site.xml,重启后则正常,修改配置项为:
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
2)Zookeeper服务发现模式登陆报错**
登陆方式:
./beeline -u "jdbc:hive2://zhoujing:2181,node1:2181,node2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi" -n zhoujing
报错如下:

解决方式,换登陆指定hive配置文件即可:
./beeline -u "jdbc:hive2://zhoujing:2181,node1:2181,node2:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi" --property-file ../conf/hive-site.xml -n zhoujing
3. 概述
3.1 架构

Kyuubi是网易数帆旗下易数大数据团队开源的一个企业级数据湖探索平台,建立在Apache Spark之上。Kyuubi 是一个高性能的通用 JDBC 和 SQL 执行引擎。Kyuubi的目标是方便用户像处理普通数据一样处理大数据。
- Kyuubi 的愿景是建立在 Apache Spark 和数据湖技术之上,统一门户,成为理想的数据湖管理平台。它可以以纯 SQL 方式支持数据处理(例如 ETL)和分析(例如 BI)。所有工作负载都可以在一个平台上完成,使用一份数据副本和一个 SQL 接口。
- Kyuubi提供了一个标准化的JDBC接口,在大数据场景下可以方便地进行数据访问。终端用户可以专注于开发自己的业务系统和挖掘数据价值,而无需了解底层的大数据平台(计算引擎、存储服务、元数据管理等)。
- Kyuubi依赖Apache Spark提供高性能的数据查询能力,引擎能力的每一次提升,都能帮助Kyuubi的性能实现质的飞跃。此外,Kyuubi通过引擎缓存提升了ad-hoc响应能力,并通过横向扩展和负载均衡提升了并发能力。
- Kyuubi提供完整的认证和授权服务,确保数据和元数据的安全。
- Kyuubi提供强大的高可用性和负载均衡,以保证SLA的承诺。
- Kyuubi提供两级弹性资源管理架构,有效提高资源利用率,同时覆盖所有场景的性能和响应需求,包括交互式,或批处理和点查询,或全表扫描。
- Kyuubi拥抱Spark,并在Spark之上构建了一个生态系统,这它使得能够快速扩展现有的生态系统,并引入新的特性,例如云原生支持和
Data Lake/Lake House支持。
3.1.1 架构概述
Kyuubi系统的基本技术架构如下图所示。

图的中间部分是Kyuubi服务端的主要部分,它处理来自图像左边所示的客户端的连接和执行请求。在Kyuubi中,这些连接请求被维护为Kyuubi Session,执行请求被维护为Kyuubi Operation,并与相应的session进行绑定。
Kyuubi Session的创建可以分为两种情况:轻量级和重量级。大多数session的创建都是轻量级的,用户无感知。唯一重量级的情况是在用户的共享域中没有实例化或缓存SparkContext,这种情况通常发生在用户第一次连接或长时间没有连接的时候。这种一次性成本的session维护模式可以满足大部分的ad-hoc快速响应需求。
Kyuubi以松耦合的方式维护与SparkConext的连接。这些SparkContexts可以是本服务实例在客户端部署模式下在本地创建的Spark程序,也可以是集群部署模式下在Yarn或Kubernetes集群中创建的。在高可用模式下,这些SparkConext也可以由其他机器上的Kyuubi实例创建,然后由这个实例共享。
这些SparkConext实例本质上是由Kyuubi服务托管的远程查询执行引擎程序。这些程序在Spark SQL上实现,并对SQL语句进行端到端编译、优化和执行,以及与元数据(如Hive Metastore)和存储(如HDFS)服务进行必要的交互,最大限度地发挥Spark SQL的威力。它们可以自行管理自己的生命周期,自行缓存和回收,并且不受Kyuubi服务器上故障转移的影响。
3.1.2 统一接口
Kyuubi实现了Hive Service RPC模块,它提供了与HiveServer2和Spark Thrift Server相同的数据访问方式。在客户端,您可以构建出色的业务报表、BI应用,甚至ETL工作,只通过Hive JDBC模块。
只需要熟悉结构化查询语言 (SQL) 和 Java 数据库连接 (JDBC) 即可处理海量数据。它可以帮助您专注于业务系统的设计和实施。
- SQL是访问关系型数据库的标准语言,在大数据生态中也非常流行。
- JDBC为工具/数据库开发者提供了一个标准的API,使得使用纯Java API编写数据库应用成为可能。
- 目前有很多免费或商业的JDBC工具。
3.1.3 运行时资源弹性
Kyuubi和Spark Thrift Server(STS)最大的区别在于,STS是一个单一的Spark应用。例如,如果一个应用运行在Apache Hadoop Yarn集群上,这个应用也是一个单一的Yarn应用,创建后只能存在于Yarn集群的特定固定队列中。Kyuubi支持提交多个Spark应用。
对于资源管理,Yarn失去了资源管理器的角色,没有起到相应的资源隔离和共享的作用。当来自客户端的用户拥有不同的资源队列权限时,这种情况下STS将无法处理。
对于数据访问,单个Spark应用在全球范围内只有一个用户,也就是sparkUser,我们必须赋予它一个类似超级用户的角色,才能让它对不同的客户端用户进行数据访问,这在生产环境中是一种极不安全的做法。
- Kyuubi会根据客户端的连接请求创建不同的Spark应用,这些应用可以放在不同的共享域中,供其他连接请求共享。
- Kyuubi在启动过程中不会占用集群管理器(如Yarn)的任何资源,如果没有任何活跃的session与
SparkContext交互,Kyuubi会将所有资源返还。 - Spark还提供了动态资源分配,根据工作负载动态调整应用程序占用的资源。这意味着应用可以将不再使用的资源还给集群,当有需求时再次请求。如果多个应用程序在您的Spark集群中共享资源,这个特性特别有用。
通过这些特性,Kyuubi提供了一个两级弹性资源管理架构,以有效提高资源利用率。
比如:
./beeline - u 'jdbc:hive2://kyuubi.org:10009/; \
hive.server2.proxy.user=tom# \
spark.yarn.queue=thequeue; \
spark.dynamicAllocation.enabled=true \
spark.dynamicAllocation.maxExecutors=500 \
spark.shuffle.service.enabled=true \
spark.executor.cores=3; \
spark.executor.memory=10g'
如果名为tom的用户打开了像上面这样的连接,Kyuubi将尝试在Yarn集群中名为thequeue的队列中创建一个拥有[3,500]个执行器(3核,每个10g mem)的Spark SQL引擎应用程序。
一方面,由于tom启用了Spark的动态资源请求特性,Spark会根据SQL操作的规模和队列中的可用资源,高效地请求和回收程序内的执行器。另一方面,当Kyuubi发现程序闲置时间过长时,也会对程序本身进行回收。
3.1.4 高可用与负载均衡
对于企业服务来说,服务级别协议(SLA)的承诺必须达到很高的水平。而并发量也需要足够强大,以支持整个企业的请求。Spark Thrift Server作为单一的Spark应用,在没有实现High Availability的情况下,很难满足SLA和并发的要求。当有大的查询请求时,在元数据服务访问、Spark Driver的调度和内存压力,或者是应用的整体计算资源限制等方面都有潜在的瓶颈。
Kyuubi提供基于Zookeeper的高可用和负载均衡解决方案,如下图所示。
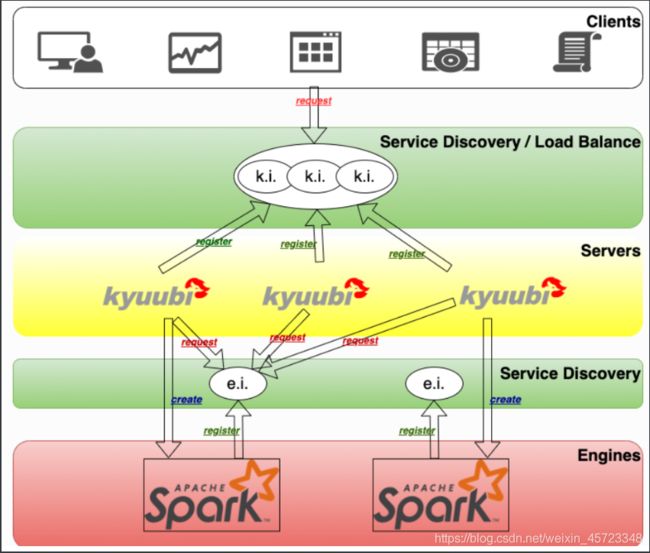
根据上图从上到下分解它。
- 图的顶部是客户层。一个客户端可以从服务发现层的命名空间中找到多个注册的 Kyuubi 实例(ki)实例,然后选择连接。注册到同一命名空间的 Kyuubi 实例提供了相互负载平衡的能力。
- 选定的 Kyuubi 实例将从服务发现层的引擎命名空间中选择一个可用的引擎实例 (ei) 来建立连接。如果没有找到可用的实例,它会创建一个新的实例,等待引擎完成注册,然后继续连接。
- 如果同一个人请求新的连接,该连接将建立到同一个或另一个 Kyuubi 实例,但引擎实例将被重用。
- 对于来自不同用户的连接,将重复步骤 2 和 3。这是因为在服务发现层,用于存储引擎实例地址的命名空间是基于用户隔离的(默认情况下),不同的用户不能跨命名空间访问其他的实例。
3.1.5 认证与授权
在一个安全的集群中,服务应该能够识别和认证调用。由于用户声称的事实并不意味着这一定是真的。Kyuubi的认证过程用于验证客户端用来与Kyuubi服务器对话的用户身份。一旦完成,如果成功,客户端和服务器之间将建立一个可信的连接;否则拒绝。
经过验证的客户端用户也将是创建关联引擎实例的用户,然后可以应用数据库对象或存储的授权。我们还创建了一个Submarine: Spark Security作为外部插件,实现基于SQL标准的细粒度授权。
3.1.6 结论
Kyuubi 是一个统一的多租户 JDBC 接口,用于大规模数据处理和分析,构建在Apache Spark™之上。它扩展了 Spark Thrift Server 在企业应用中的场景,其中最重要的是多租户支持。
3.2 Kyuubi vs HiveServer2
3.2.1 介绍
HiveServer2 是一项服务,使客户端能够在支持多客户端并发和身份验证的 Hive 上执行 Hive QL 查询。Kyuubi 使客户端能够直接在支持多客户端并发和身份验证的 Spark 上执行 Spark SQL 查询。
它们都旨在为 JDBC 和 ODBC 等开放 API 客户端提供更好的支持,以管理和分析大数据。
3.2.2 Hive on Spark
Hive on Spark 的目的是将 Spark 添加为第三个执行后端,与 MR 和 Tez 并行。与 MR 上的 Hive 相比,Spark DAG 将有助于提高 Hive 查询的性能,尤其是那些具有多个 reducer 阶段的查询。
3.2.3 Kyuubi 和 HiveServer2 的区别

3.3 Kyuubi vs Spark Thrift JDBC/ODBC Server(STS)
3.3.1 介绍
Apache Spark Thrift JDBC/ODBC Server是Apache Spark 社区基于HiveServer2 实现的Thrift 服务。它旨在与 HiveServer2 无缝兼容,通过 JDBC 接口以纯 SQL 方式为最终用户提供 Spark SQL 功能。这种“开箱即用”的模型最大限度地减少了用户使用 Spark 的障碍和成本。
Kyuubi 和 Spark 在这个目标上是一致的。最重要的是,Kyuubi 在多租户支持、服务可用性、服务并发能力、数据安全等方面进行了增强。
3.3.2 Spark ThriftServer的设计、实现与不足
产生背景
在最初使用Spark时,只有理解了Spark RDD模型和其提供的各种算子时,才能比较好地使用Spark进行数据处理和分析,显然由于向上层暴露了过多底层实现细节,Spark有一定的高使用门槛,在易用性上对许多初入门用户来说并不太友好。
SparkSQL的出现则较好地解决了这一问题,通过使用SparkSQL提供的简易API,用户只需要有基本的编程基础并且会使用SQL,就可以借助Spark强大的快速分布式计算能力来处理和分析他们的大规模数据集。
而Spark ThriftServer的出现使Spark的易用性又向前迈进了一步,通过提供标准的JDBC接口和命令行终端的方式,平台开发者可以基于其提供的服务来快速构建它们的数据分析应用,普通用户甚至不需要有编程基础即可借助其强大的能力来进行交互式数据分析。
核心设计
顾名思义,本质上,Spark ThriftServer是一个基于Apache Thrift框架构建并且封装了SparkContext的RPC服务端,或者从Spark的层面来讲,我们也可以说,Spark ThriftServer是一个提供了各种RPC服务的Spark Driver。但不管从哪个角度去看Spark ThriftServer,有一点可以肯定的是,它是一个Server,是需要对外提供服务的,因此其是常驻的进程,并不会像一般我们构建的Spark Application在完成数据处理的工作逻辑后就退出。其整体架构图如下所示:

Apache Thrift是业界流行的RPC框架,通过其提供的接口描述语言(IDL),可以快速构建用于数据通信的并且语言无关的RPC客户端和服务端,在带来高性能的同时,大大降低了开发人员构建RPC服务的成本,因此在大数据生态其有较多的应用场景,比如我们熟知的hiveserver2即是基于Apache Thrift来构建其RPC服务。
当用户通过JDBC或beeline方式执行一条SQL语句时,TThreadPoolServer会接收到该SQL,通过一系列的Session和Operation的管理,最终会使用在启动Spark ThriftServer时已经构建好的SparkContext来执行该SQL,并获取最后的结果集。
从上面的基本分析中我们可以看到,在不考虑Spark ThrfitServer的底层RPC通信框架和业务细节时,其整体实现思路是比较清晰和简单的。
基本实现
前面提到的TThreadPoolServer是Apache Thrift提供的用于构建RPC Server的一个工作线程池类,在Spark ThriftServer的Service体系结构中,ThriftBinaryService正是使用TThreadPoolServer来构建RPC服务端并对外提供一系列RPC服务接口:
Spark ThriftServer Service体系

ThriftBinaryService基于TThreadPoolServer构建RPC服务端
// org.apache.hive.service.cli.thrift.ThriftBinaryCLIService#run
public class ThriftBinaryCLIService extends ThriftCLIService {
@Override
public void run() {
// ...省略其它细节...
// TCP Server
server = new TThreadPoolServer(sargs);
server.setServerEventHandler(serverEventHandler);
server.serve();
// ...省略其它细节...
}
}
ThriftBinaryService提供的RPC服务接口
// org.apache.hive.service.cli.thrift.TCLIService.Iface
TOpenSessionResp OpenSession(TOpenSessionReq req);
TCloseSessionResp CloseSession(TCloseSessionReq req);
TGetInfoResp GetInfo(TGetInfoReq req);
TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req);
TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req);
TGetCatalogsResp GetCatalogs(TGetCatalogsReq req);
TGetSchemasResp GetSchemas(TGetSchemasReq req);
TGetTablesResp GetTables(TGetTablesReq req);
TGetTableTypesResp GetTableTypes(TGetTableTypesReq req);
TGetColumnsResp GetColumns(TGetColumnsReq req);
TGetFunctionsResp GetFunctions(TGetFunctionsReq req);
TGetOperationStatusResp GetOperationStatus(TGetOperationStatusReq req);
TCancelOperationResp CancelOperation(TCancelOperationReq req);
TCloseOperationResp CloseOperation(TCloseOperationReq req);
TGetResultSetMetadataResp GetResultSetMetadata(TGetResultSetMetadataReq req);
TFetchResultsResp FetchResults(TFetchResultsReq req);
TGetDelegationTokenResp GetDelegationToken(TGetDelegationTokenReq req);
TCancelDelegationTokenResp CancelDelegationToken(TCancelDelegationTokenReq req);
TRenewDelegationTokenResp RenewDelegationToken(TRenewDelegationTokenReq req);
可以看到,其提供的相当一部分接口都是提供SQL服务时所必要的能力。
当然,不管是使用标准的JDBC接口还是通过beeline的方式来访问Spark ThriftServer,必然都是通过Spark基于Apache Thrift构建的RPC客户端来访问这些RPC服务接口的,因此我们去看Spark ThriftServer提供的RPC客户端,其提供的方法接口与RPC服务端提供的是对应的,可以参考org.apache.hive.service.cli.thrift.TCLIService.Client。
主要限制
Driver程序瓶颈
Spark 的Driver既要充当 Spark 应用程序的调度程序,又要充当来自客户端的数千个连接和操作的处理程序。在这种情况下,它很可能会遇到瓶颈。Spark 分析器解析所有查询所依赖的 Hive Metastore 客户端是一个且唯一的,因此访问 HMS 时会出现更明显的并发问题。
资源隔离问题
过大的 Spark 作业占用了过多的 Spark ThriftServer 资源,导致其他作业延迟或卡住。

多租户限制
Spark ThriftServer 本身应该是一个多租户系统,即它可以接受来自不同客户端和用户的请求。但是,从Spark的设计来看,单个Spark应用中实现的Spark ThriftServer并不能完全支持多租户,因为整个应用***只有一个全局唯一的用户名***,包括驱动端和执行端。因此,它必须使用单个租户访问所有用户的数据。
Spark ThriftServer 占用单个资源队列(YARN Queue / Kubernetes Namespace),从资源隔离和共享的角度来看,难以细粒度或弹性地控制每个租户可用的资源池大小。没有人愿意重启服务器并停止服务以调整某些池的权重或增加总计算资源。
高可用限制
Spark ThriftServer 的社区版不支持高可用性 (HA)。很难想象一个没有高可用的服务器端应用能否支持SLA承诺。将 HA 实现应用于 Spark ThriftServer 并不难,但很棘手。例如,已经有一个JIRA :SPARK-11100并附有拉取请求,请参阅 [SPARK-11100]。Spark ThriftServer的HA实现一般有两种方式,分别是Active/Standby和LoadBalancing。
Active/Standby 模式***由主用 Spark ThriftServer 和多个备用服务器组成。当活动节点崩溃或挂起时,备用节点会触发领导者选择,成为新的活动节点来接管。这里的问题是不可否认的:只有一个活动节点运行时,所以***并发能力有限。当由于硬件和软件故障而发生故障转移时,所有当前连接和正在运行的作业都将失败。这种故障转移对于客户端用户来说是昂贵的。客户端将同时重试,因此新选出的活动服务器很难处理即将到来的客户端重试潮。很有可能再次崩溃。不论是否开启Spark动态资源分配,Standby节点都会造成集群资源的严重浪费。解决服务器端单点问题的更合适的方法是添加自己的 LoadBalancing 支持。这样当客户端请求增加时,可以横向扩展 Spark ThriftServer。但是,这个模型也有一些局限性。每个 Spark ThriftServer 都是有状态的,具有瞬态数据或功能,例如一些全局临时视图、UDF 等,不能在两个服务器之间共享。并且与计算资源一起扩展是昂贵的。
UDF问题
对于操作ADD JAR ...· or ·CREATE TEMPORARY FUNCTION ... USING...·,类或者jar包可能会在 Spark ThriftServer 中发生冲突。且没有这种冲突时删除的方法。此外,由于UDF是直接加载到Spark ThriftServer中,如果其中包含一些无意或恶意的逻辑,例如调用,可能会直接杀死服务,或者一些影响全局服务器行为的操作,如Kerberos认证。
3.3.3 Kyuubi .vs. Spark Thrift Server


一致的接口
Kyuubi、Spark Thrift Server 和 HiveServer2 在接口和协议方面是相同的。因此,从用户的角度来看,使用方式是不变的。与HiveServer2相比,前两者最显着的优势应该是性能的提升。
从 SQL 语法兼容性的角度来看,Kyuubi 和 Spark Thrift Server 完全兼容 Spark SQL,因为它们完全委托给 Spark SQL Catalyst 层。Spark SQL 也完全支持 Hive QL 集合,只有少数可枚举的 SQL 行为和语法差异。
多租户架构
Kyuubi、Spark ThriftServer 和 HiveServer2 是为典型的多租户架构场景而设计的。
首先,我们需要考虑如何 1) 基于资源隔离更安全、更高效地使用这些计算资源,以及 2) 如何让用户对自己的资源有足够的控制权。
HiveServer2 应该是最灵活的。每个 SQL 都被编程到几个 Spark 应用程序中执行,并且在执行之前可以设置资源队列、内存等。但是这种方式会导致 Spark bootstrap 延迟极高,无法有效利用资源。
Spark ThriftServer 则相反,因为只有一个 Spark 应用程序。由于已经预先启动,因此无法从用户端界面调整队列、内存和其他与资源相关的配置。可以将查询发送到预设以单独运行。在只能火花应用程序内提供低隔离和火花ThriftServer开始前进行配置。Fair Scheduler Pools``Fair Scheduler Pools
Kyuubi 用另外两个系统实现中和了这些方面。Kyuubi 应用了基于 Kyuubi Engines 概念的多租户特性,其中 Engine 是一个 Spark 应用程序。
在Kyuubi的系统中,引擎是根据租户进行隔离的。租户,也就是用户,通过 JDBC 连接是统一的和端到端的。Kyuubi 服务器将识别和验证用户,然后检索或创建属于该特定用户的引擎。此用户将用作 Engine 的提交者,并且它必须有权使用来自 YARN、Kubernetes 或仅本地机器等的资源。在 Engine 内部,Engine 的用户,等等,也将是相同的。当引擎运行从 JDBC 连接接收的查询时,引擎的用户还必须有权访问数据。另外,如果在这个过程中需要访问元数据,那么我们现在也可以通过Submarine Spark Security Plugin在元数据层添加一个细粒度的SQL标准ACL管理Spark User.
引擎有它们的生命周期,这与kyuubi.session.engine.share.level通过客户端配置指定的相关。例如,如果设置为CONNECTION,那么将为每个 JDBC 连接创建相应的 Engine 并在我们关闭连接时自行终止。再例如,如果设置为USER,则相应的 Engine 会被缓存并与来自同一用户的所有 JDBC 连接共享,即使是通过 HA 模式下的不同 Kyuubi 服务器。在所有会话关闭后,引擎最终将超时。
由于需要创建Engines,一方面,我们可以在启动时配置所有Spark配置。另一方面,它确实带来了 Spark 应用程序引导的开销,但总的来说,这只是一次性成本。引擎用户的所有查询或连接都将共享此应用程序。它运行的查询越多,bootstraps开销越低。
高可用性能力
Spark ThriftServer 中的 HA 问题已经在上一节中介绍过,这里不再赘述。在Kyuubi,我们以LoadBlancing. Kyuubi 是轻量级的,因为它在启动时不会创建任何引擎。添加 Kyuubi HA 节点很便宜,因此水平扩展不会过于繁重。
客户端并发
HiveServer2 和 Spark ThriftServer 中查询的编译和优化都是在服务器端完成的。相比之下,Kyuubi会在Engine端做这些。它有助于减少服务器的工作量和提高客户端的并发性。属于计算阶段的任务调度也发生在Kyuubi Engine端。它不像 Spark ThriftServer 那样繁重,客户端并发和任务调度之间存在激烈的竞争。原则上,执行者越多,或者处理的数据量越大,服务器端的压力就越大。
服务稳定性
客户端并发和任务调度的激烈竞争,增加了 Spark ThriftServer 的 GC 问题和 OOM 风险。由于服务器和引擎分离,Kyuubi在这方面没有问题。UDF 风险也不会损害服务的稳定性。就好像用户加载并调用了一个无效的UDF,只会损坏自己的Engine,不会影响其他用户或Kyuubi服务器。
概况
Kyuubi在基于统一接口的多租户模型中扩展了Spark ThriftServer的使用,并依靠多租户的概念与集群管理器交互,最终获得资源共享/隔离和数据安全的能力。Kyuubi Server 和 Engine 的松耦合架构极大地提高了服务本身的并发性和服务稳定性。
4. Spark 引擎特性在Kyuubi上的展示
4.1 动态资源分配(DRA)
在 Kyuubi 中,我们从集群管理器获取计算资源以提交引擎。引擎响应各种类型的客户端请求,其中一些需要消耗大量计算资源来处理,而另一些可能需要很少的资源来完成。如果我们有固定大小的引擎,也就是固定数量的 for spark.executor.instances,对于一些轻量级的工作负载可能会造成资源浪费,而对于一些重量级的工作负载,它可能没有足够的并发能力导致性能不佳。
当引擎有 executor 空闲时,我们应该及时将其释放回资源池,反之,当引擎在做重型任务时,我们应该能够更有效地获取和使用更多资源。一方面,我们需要依靠资源管理器的能力进行高效的资源分配、资源隔离和共享。另一方面,我们需要为引擎的执行程序的弹性伸缩启用 Spark 的 DRA 功能。
4.4.1 动态资源分配的基础知识
Spark 提供了一种***根据工作负载动态调整应用程序资源的机制***,这意味着应用程序可以将不再使用的资源还给集群,并在以后有需求时再次请求它们。如果多个应用程序在 YARN、Kubernetes 和其他平台上共享资源,则此功能非常方便。
对于典型的 Spark 应用程序 Kyuubi 引擎,动态分配允许 Spark 根据工作负载动态扩展分配给它们的集群资源。当启用动态分配,并且引擎有待处理任务的积压时,它可以通过ExecutorAllocationManager. 当引擎有空闲的执行器时,执行器被释放,占用的资源还给集群管理器。然后在同一队列中运行的其他引擎或其他应用程序可以获取资源。
4.1.2 如何启用动态资源分配
启用此功能的先决条件是下游阶段可以正确访问 shuffle 数据,即使生成数据的执行程序被回收。
Spark 提供了两种用于 shuffle 数据跟踪的实现。如果启用了其中一个,我们就可以正确使用 DRA 功能。
带有外部 Shuffle 服务的动态资源分配
拥有外部 shuffle 服务 (ESS) 可确保所有数据都存储在执行程序之外。这个先决条件是必需的,因为 Spark 需要确保执行程序的删除不会删除 shuffle 数据。使用提供 ESS 的集群管理器部署 Kyuubi 时,请使用以下配置为所有引擎启用 DRA。
spark.dynamicAllocation.enabled=true
spark.shuffle.service.enabled=true
另一件要确定的事情是spark.shuffle.service.port应该将其配置为指向运行 ESS 的端口。
没有外部随机服务的动态分配
ESS 功能的实现依赖于集群管理器。以 Yarn 为例,ESS 需要在集群范围内部署,并且实际上运行在 Yarn 的NodeManager组件中。尽管如此,如果在 Kubernetes 上运行 Kyuubi 的引擎,那么 ESS 还不是一个选择。从 Spark 3.0 开始,DRA 可以在没有 ESS 的情况下运行。SPARK-27963引入了调用的相关功能。Shuffle Tracking
当使用没有 ESS 或 ESS 没有吸引力的集群管理器部署 Kyuubi 时,请为具有以下配置的所有引擎启用 DRA 。Shuffle Tracking
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=true
当启用时,控制超时对于持有Shuffle数据执行人。默认情况下,Spark 将依靠垃圾收集的 shuffle 来释放执行程序。当垃圾收集没有足够快地清理 shuffle 时,这个超时会强制 Spark 删除 executor,即使它们正在存储 shuffle 数据。Shuffle Tracking spark.dynamicAllocation.shuffleTracking.timeout(default: infinity)`
4.1.3 使用动态资源分配调整引擎大小
单个执行程序的资源(例如 CPU 和内存)可以是固定大小的。因此,范围 [ minExecutors, maxExecutors] 决定了引擎可以从集群管理器获取多少资源。
一方面, minExecutors告诉 Spark 至少保留多少个执行者。如果它设置的太接近 0(默认),如果集群管理器很忙并且很长一段时间,引擎可能会抱怨资源不足。然而,越大minExecutors,在引擎的空闲时间期间可能浪费的资源越多。
另一方面,maxExecutors决定了引擎的执行者可以达到的上限。从单个引擎的角度来看,该值越大越好,以处理较重的查询。但是,就整个集群的资源而言,我们必须将其限制在一个合理的范围内。否则,大型查询可能会触发它运行的引擎消耗队列/命名空间中的过多资源并占用它们相当长的时间,这对于有效使用资源来说可能是一个坏主意。在这种情况下,我们希望在有限的并发量下更慢地完成如此庞大的任务。
以下 Spark 配置包括 DRA 的大小调整。
spark.dynamicAllocation.minExecutors=10
spark.dynamicAllocation.maxExecutors=500
此外,另一个名为的配置spark.dynamicAllocation.initialExecutors可用于决定在引擎引导或故障转移期间要请求多少个执行程序。
理想情况下,它们之间的大小关系应为minExecutors<= initialExecutors< maxExecutors。
4.1.4 资源分配政策
当 DRA 注意到当前资源不足以满足当前工作负载时,它会请求更多的执行器。

默认情况下,动态分配将根据要处理的任务数量请求足够多的执行器来最大化并行度。

虽然这最大限度地减少了作业的延迟,但对于小任务,默认行为可能会由于执行器分配开销而浪费许多资源,因为某些执行器甚至可能不做任何工作。
在这种情况下,我们可以spark.dynamicAllocation.executorAllocationRatio调低一点,以减少完全并行的执行器数量。例如,0.5 会将目标执行程序数除以 2。

完成一项任务后,Spark Driver 会为具有可用内核的 executor 安排一个新任务。当待处理的任务越来越少时,一些执行器会因为没有新的任务而变得空闲。

如果一个 executor 达到 maximn 超时,它将被删除。
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=infinity
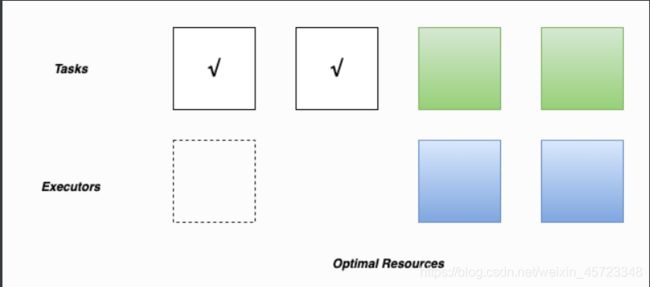
如果 DRA 发现有待处理的任务积压超过超时时间,则将请求新的执行程序,由以下配置控制。
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s
4.1.5. 将 DRA 应用于 Kyuubi 的最佳实践
Kyuubi 是一项长期运行的服务,旨在让最终用户在没有很多 Spark 基础知识的情况下更容易使用 Spark SQL。必须有一个适用于服务器端大多数场景的资源管理基本配置。
设置默认配置
spark-defaults.conf在引擎端配置是使用 DRA 设置 Kyuubi 的最佳方式。所有引擎都将在启用 DRA 的情况下进行实例化。
这是我们在部署 Kyuubi 时在我们的平台中使用的配置设置。
spark.dynamicAllocation.enabled=true
##false if perfer shuffle tracking than ESS
spark.shuffle.service.enabled=true
spark.dynamicAllocation.initialExecutors=10
spark.dynamicAllocation.minExecutors=10
spark.dynamicAllocation.maxExecutors=500
spark.dynamicAllocation.executorAllocationRatio=0.5
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=30min
# true if perfer shuffle tracking than ESS
spark.dynamicAllocation.shuffleTracking.enabled=false
spark.dynamicAllocation.shuffleTracking.timeout=30min
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s
spark.cleaner.periodicGC.interval=5min
请注意,spark.cleaner.periodicGC.interval=5min当spark.dynamicAllocation.shuffleTracking.enabled启用时,这里很有用,因为我们可以告诉 Spark 对于 shuffle 数据 GC 更加活跃。
设置用户默认设置
在服务器端,不同用户的工作负载可能不同。
然后,我们可以通过为他们设置的不同的默认值用户默认的$KYUUBI_HOME/conf/kyuubi-defaults.conf
# For a user named kent
___kent___.spark.dynamicAllocation.maxExecutors=20
# For a user named bob
___bob___.spark.dynamicAllocation.maxExecutors=600
在这种情况下,named 的用户kent只能为其引擎使用 20 个执行程序,但bob可以使用 600 个执行程序以获得更好的性能或处理繁重的工作负载。
动态设置
所有与 AQE 相关的配置都是 Spark 核心的静态配置,并且SET在每次 SQL 查询之前无法通过语法进行更改。例如,
SET spark.dynamicAllocation.maxExecutors=33;
SELECT * FROM default.tableA;
4.2 自适应查询执行(AQE)
4.2.1 AQE 的基础知识
Spark Adaptive Query Execution (AQE) 是在查询执行期间发生的查询重新优化。
在技术架构上,AQE是一个基于运行时统计的动态规划和重新规划查询的框架,支持多种优化,例如,
- 动态切换Join策略
- 动态合并 Shuffle 分区
- 动态处理倾斜连接
在Kyuubi中,强烈建议您默认开启Kyuubi引擎的所有AQE功能,无论您在什么平台上运行Kyuubi和Spark。
4.2.2 动态切换Join策略
Spark 支持多种Join策略,其中当任何连接端适合内存时,BroadcastHash Join 通常是性能最高的。 出于这个原因,如果连接关系的估计大小小于 spark.sql.autoBroadcastJoinThreshold,Spark 会计划使用一个 BroadcastHash Join。
spark.sql.autoBroadcastJoinThreshold=10M
没有AQE,Join关系的估计大小来自原始表的统计信息。 在大多数现实世界的情况下,它可能会出错。 例如,连接关系是收敛但复合的操作,而不是单表扫描。 在这种情况下,Spark 可能无法将 join-strategy 切换为 BroadcastHash Join。 而使用 AQE,我们可以在运行时准确计算复合操作的大小。 然后,如果大小适合 spark.sql.autoBroadcastJoinThreshold,Spark 现在可以明确无误地重新规划Join策略。

更重要的是,当 spark.sql.adaptive.localShuffleReader.enabled=true 并且将 SortMerge Join 转换为 BroadcastHash Join 后,Spark 还会通过将常规 shuffle 转换为本地化 shuffle 来进行未来优化以减少网络流量。

如上图所示,本地 shuffle 读取器可以从其本地存储中读取所有需要的 shuffle 文件,实际上无需跨网络执行 shuffle。
本地shuffle reader优化包括在应用AQE规则后SortMerge Join转换为BroadcastHash Join时避免shuffle。
4.2.3 动态合并shuffe分区
如果没有这个功能,Spark 本身有时可能会成为一个小文件生产商,尤其是像 Kyuubi 那样的纯 SQL 方式,例如,
- 当
spark.sql.shuffle.partitions与总输出大小相比设置得太大时,shuffle 阶段后会出现非常小的文件或空文件。 - 当 Spark 一起执行一系列优化的
BroadcastHash Join和Union时,每个分区的最终输出大小可能会因 join 条件而减少。 但是,最终输出文件的总数会爆炸。 - 一些带有选择性过滤器的流水线作业来生成临时数据。
- 等等
读取小文件会导致非常小的分区或任务。 Spark 任务的 I/O 吞吐量会更差,并且往往会受到更多调度开销和任务设置开销的影响。

合并小分区可以节省资源并提高集群吞吐量。 Spark 提供了多种方法来处理小文件问题,例如,使用distribute by 子句或使用HINT 在分区列上添加额外的shuffle 操作。 在大多数情况下,您需要很好地掌握数据、Spark 作业和配置,以便逐个应用这些解决方案。 大多数情况下,日常使用的配置 - spark.sql.shuffle.partitions 是依赖于数据的,并且无法通过单个 Spark SQL 查询进行更改。 对于具有多个阶段的真实 Spark 作业,不可能将其用作一种尺寸以适应所有阶段。
但是有了 AQE,你会觉得更舒服,因为 Spark 会自动进行分区合并。

在运行 Spark SQL 查询时,它可以简化 shuffle 分区数的调整。 您不需要设置合适的 shuffle 分区号来适合您的数据集。
要启用此功能,我们需要将以下两个配置设置为 true。
4.2.4 动态处理倾斜连接
如果没有 AQE,那么 map-reduce 计算模型在 shuffle 阶段很可能会出现数据偏斜。 数据倾斜会导致 Spark 作业有一个或多个拖尾任务,严重降低查询的性能。 此功能通过将倾斜的任务拆分(并在需要时复制)成大致均匀大小的任务来动态处理 SortMerge Join 中的倾斜。 例如,优化会将过大的分区拆分为子分区,并将它们加入到另一方的相应分区中。

要启用此功能,我们需要将以下两个配置设置为 true。
spark.sql.adaptive.enabled=true
spark.sql.adaptive.skewJoin.enabled=true
5. 源码研究
5.1 模块划分

Kyuubi从整体上可以分为用户层、服务发现层、Kyuubi Server层、Kyuubi Engine层,其整体概述如下:
-
用户层
指通过不同方式使用Kyuubi的用户,比如通过JDBC或beeline方式使用Kyuubi的用户。
-
服务发现层
服务发现层依赖于Zookeeper实现,其又分为Kyuubi Server层的服务发现和Kyuubi Engine层的服务发现。
服务发现层主要是指Zookeepr服务以及Kyuubi Server层的KyuubiServer实例和Kyuubi Engine层的SparkSQLEngine在上面注册的命名空间(即node节点),以提供负载均衡和高可用等特性,因此它分为Kyuubi Server层的服务发现和Kyuubi Engine层的服务发现。
-
Kyuubi Server层
由多个不同的KyuubiServer实例组成,每个KyuubiServer实例本质上为基于Apache Thrift实现的RPC服务端,其接收来自用户的请求,但并不会真正执行该请求的相关SQL操作,只会作为代理转发该请求到Kyuubi Engine层用户所属的SparkSQLEngine实例上。
-
Kyuubi Engine层
由多个不同的SparkSQLEngine实例组成,每个SparkSQLEngine实例本质上为基于Apache Thrift实现的并且持有一个SparkSession实例的RPC服务端,其接收来自KyuubiServer实例的请求,并通过SparkSession实例来执行。在Kyuubi的USER共享层级上,每个SparkSQLEngine实例都是用户级别的,即不同的用户其会持有不同的SparkSQLEngine实例,以实现用户级别的资源隔离和控制。
SparkSQLEngine实例是针对不同的用户按需启动的。在Kyuubi整体系统启动之后,如果没有用户访问Kyuubi服务,实际上在整个系统中只有一个或多个KyuubiServer实例,当有用户通过JDBC或beeline的方式连接KyuubiServer实例时,其会在Zookeeper上去查找是否存在用户所属的SparkSQLEngine实例,如果没有,则通过
spark-submit提交一个Spark应用,而这个Spark应用本身就是SparkSQLEngine,启动后,基于其内部构建的SparkSession实例,即可为特定用户执行相关SQL操作。
5.2 源码编译
Kyuubi这个组件整体编译没遇到什么太大的阻塞,比较好解决。这边编译好就可以细细研究它了。

5.3 Kyuubi源码剖析
5.3.1 Kyuubi Service体系与组合关系
Sevice体系

基于Kyuubi提供的核心功能,可以大致按Kyuubi Server层和Kyuubi Engine层来将整个体系中的Service类进行一个划分:
- Kyuubi Server层
- 功能入口
- KyuubiServer:提供main方法,是Kyuubi Server层KyuubiServer实例初始化和启动的入口; - 服务发现
- KyuubiServiceDiscovery:封装了zkClient,用来与Zookeeper服务进行交互; - 核心功能
- FrontendService:封装了Apache Thrift的TThreadPoolServer,在Kyuubi Server层,其主要用于向用户层提供RPC服务;
- KyuubiBackendService:封装了来自用户层不同RPC请求的处理逻辑,比如openSession、executeStatement、fetchResults等; - Session管理
- KyuubiSessionManager:提供对用户层的请求会话(session)管理; - Operation管理
- KyuubiOperationManager:提供对用户层的请求操作(operation)管理;
- 功能入口
- Kyuubi Engine层
- 功能入口
- SparkSQLEngine:提供main方法,是Kyuubi Engine层SparkSQLEngine实例初始化和启动的入口; - 服务发现
- EngineServiceDiscovery:封装了zkClient,用来与Zookeeper服务进行交互; - 核心功能
- FrontendService:封装了Apache Thrift的TThreadPoolServer,在Kyuubi Engine层,其主要用于向Kyuubi Server层提供RPC服务;
- SparkSQLBackendService:封装了来自Kyuubi Server层不同RPC请求的处理逻辑,比如openSession、executeStatement、fetchResults等; - Session管理
- SparkSQLSessionManager:提供对Kyuubi Server层的请求会话(session)管理; - Operation管理
- SparkSQLOperationManager:提供对Kyuubi Server层的请求操作(operation)管理;
- 功能入口
Session与SessionHandle
Session对象的存储实际上由SessionManager来完成,在SessionManager内部其通过一个Map来存储Session的详细信息,其中key为SessionHandle,value为Session对象本身。SessionHandle可以理解为就是封装了一个唯一标识一个用户会话的字符串,这样用户在会话建立后进行通信时只需要携带该字符串标识即可,并不需要传输完整的会话信息,以避免网络传输带来的开销。
Operation与OperationHandle
用户在建立会话后执行的相关语句在Kyuubi内部都会抽象为一个个的Operation。
由于Operation都是建立在Session之下的,所以我们在看前面的组合关系时可以看到,用于管理Operation的OperationManager为SessionManager的成员属性。
Operation对象的存储实际上由OprationManager来完成,在SessioOprationManagerManager内部其通过一个Map来存储Session的详细信息,其中key为OperationHandle,value为Operation对象本身。OperationHandle可以理解为就是封装了一个唯一标识一个用户操作的字符串,这样用户基于会话的操作时只需要携带该字符串标识即可,并不需要传输完整的操作信息,以避免网络传输带来的开销。
5.3.2 Kyuubi启动流程
在Kyuubi的bin目录下去执行./kyuubi start命令去启动KyuubiServer时,就会去执行KyuubiServer的main方法:
def main(args: Array[String]): Unit = {
info(
"""
| Welcome to
| __ __ __
| /\ \/\ \ /\ \ __
| \ \ \/'/' __ __ __ __ __ __\ \ \____/\_\
| \ \ , < /\ \/\ \/\ \/\ \/\ \/\ \\ \ '__`\/\ \
| \ \ \\`\\ \ \_\ \ \ \_\ \ \ \_\ \\ \ \L\ \ \ \
| \ \_\ \_\/`____ \ \____/\ \____/ \ \_,__/\ \_\
| \/_/\/_/`/___/> \/___/ \/___/ \/___/ \/_/
| /\___/
| \/__/
""".stripMargin)
info(s"Version: $KYUUBI_VERSION, Revision: $REVISION, Branch: $BRANCH," +
s" Java: $JAVA_COMPILE_VERSION, Scala: $SCALA_COMPILE_VERSION," +
s" Spark: $SPARK_COMPILE_VERSION, Hadoop: $HADOOP_COMPILE_VERSION," +
s" Hive: $HIVE_COMPILE_VERSION")
info(s"Using Scala ${Properties.versionString}, ${Properties.javaVmName}," +
s" ${Properties.javaVersion}")
SignalRegister.registerLogger(logger)
val conf = new KyuubiConf().loadFileDefaults()
UserGroupInformation.setConfiguration(KyuubiHadoopUtils.newHadoopConf(conf))
startServer(conf)
}
在加载完配置信息后,通过调用startServer(conf)方法,就开始了KyuubiServer的启动流程:
def startServer(conf: KyuubiConf): KyuubiServer = {
if (!ServiceDiscovery.supportServiceDiscovery(conf)) {
zkServer.initialize(conf)
zkServer.start()
conf.set(HA_ZK_QUORUM, zkServer.getConnectString)
conf.set(HA_ZK_ACL_ENABLED, false)
}
val server = new KyuubiServer()
server.initialize(conf)
server.start()
Utils.addShutdownHook(new Runnable {
override def run(): Unit = server.stop()
}, 100)
server
}
可以看到,实际上KyuubiServer的启动包括两部分:初始化和启动。
KyuubiServer的初始化和启动实际上是一个***递归初始化***和***启动***的过程。我们前面提到,KyuubiServer为Service体系下的一个CompositeService,它本身的成员又包含了多个Service对象,它们都保存在保存在serviceList这个成员当中,因此初始化和启动KyuubiServer实际上就是初始化和启动serviceList中所包含的各个Service对象。而这些Service对象本身又可能是CompositeService,因此KyuubiServer的启动和初始化实际上就是一个递归初始化和启动的过程。
KyuubiServer–>Serverable–>CompositeService
## CompositeService
// 递归初始化serviceList下的各个服务
override def initialize(conf: KyuubiConf): Unit = {
serviceList.foreach(_.initialize(conf))
super.initialize(conf)
}
// 递归启动serviceList下的各个服务
override def start(): Unit = {
serviceList.zipWithIndex.foreach { case (service, idx) =>
try {
service.start()
} catch {
case NonFatal(e) =>
error(s"Error starting service ${service.getName}", e)
stop(idx)
throw new KyuubiException(s"Failed to Start $getName", e)
}
}
super.start()
}
重点关注一下FontendService和ServiceDiscoveryService的初始化和启动流程。
FrontendService的初始化和启动
KyuubiServer实例对外提供RPC服务都是由***FrontendService***作为入口来完成的。
其初始化时主要是获取和设置了Apache Thrift内置的用于构建RPC服务端的TThreadPoolServer的相关参数:
override def initialize(conf: KyuubiConf): Unit = synchronized {
this.conf = conf
try {
hadoopConf = KyuubiHadoopUtils.newHadoopConf(conf)
val serverHost = conf.get(FRONTEND_BIND_HOST)
serverAddr = serverHost.map(InetAddress.getByName).getOrElse(InetAddress.getLocalHost)
portNum = conf.get(FRONTEND_BIND_PORT)
val minThreads = conf.get(FRONTEND_MIN_WORKER_THREADS)
val maxThreads = conf.get(FRONTEND_MAX_WORKER_THREADS)
val keepAliveTime = conf.get(FRONTEND_WORKER_KEEPALIVE_TIME)
val executor = ExecutorPoolCaptureOom(
name + "Handler-Pool",
minThreads, maxThreads,
keepAliveTime,
oomHook)
authFactory = new KyuubiAuthenticationFactory(conf)
val transFactory = authFactory.getTTransportFactory
val tProcFactory = authFactory.getTProcessorFactory(this)
val serverSocket = new ServerSocket(portNum, -1, serverAddr)
portNum = serverSocket.getLocalPort
val tServerSocket = new TServerSocket(serverSocket)
val maxMessageSize = conf.get(FRONTEND_MAX_MESSAGE_SIZE)
val requestTimeout = conf.get(FRONTEND_LOGIN_TIMEOUT).toInt
val beBackoffSlotLength = conf.get(FRONTEND_LOGIN_BACKOFF_SLOT_LENGTH).toInt
val args = new TThreadPoolServer.Args(tServerSocket)
.processorFactory(tProcFactory)
.transportFactory(transFactory)
.protocolFactory(new TBinaryProtocol.Factory)
.inputProtocolFactory(
new TBinaryProtocol.Factory(true, true, maxMessageSize, maxMessageSize))
.requestTimeout(requestTimeout).requestTimeoutUnit(TimeUnit.SECONDS)
.beBackoffSlotLength(beBackoffSlotLength)
.beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executor)
// TCP Server
server = Some(new TThreadPoolServer(args))
server.foreach(_.setServerEventHandler(new FeTServerEventHandler))
info(s"Initializing $name on host ${serverAddr.getCanonicalHostName} at port $portNum with" +
s" [$minThreads, $maxThreads] worker threads")
} catch {
case e: Throwable =>
throw new KyuubiException(
s"Failed to initialize frontend service on $serverAddr:$portNum.", e)
}
super.initialize(conf)
}
可以看到主要是host、port、minThreads、maxThreads、maxMessageSize、requestTimeout等,这些参数都是可配置的,关于其详细作用可以参考KyuubiConf这个类的说明。
其启动比较简单,主要是调用TThreadPoolServer的server()方法来完成:
override def start(): Unit = synchronized {
super.start()
if(!isStarted) {
serverThread = new NamedThreadFactory(getName, false).newThread(this)
serverThread.start()
isStarted = true
}
}
override def run(): Unit = try {
info(s"Starting and exposing JDBC connection at: jdbc:hive2://$connectionUrl/")
server.foreach(_.serve())
} catch {
case _: InterruptedException => error(s"$getName is interrupted")
case t: Throwable =>
error(s"Error starting $getName", t)
System.exit(-1)
}
ServiceDiscoverService的初始化和启动
初始化时主要是创建一个用于后续连接ZooKeeper的zkClient:
private var _namespace: String = _
override def initialize(conf: KyuubiConf): Unit = {
this.conf = conf
_namespace = conf.get(HA_ZK_NAMESPACE)
val maxSleepTime = conf.get(HA_ZK_CONN_MAX_RETRY_WAIT)
val maxRetries = conf.get(HA_ZK_CONN_MAX_RETRIES)
setUpZooKeeperAuth(conf)
_zkClient = buildZookeeperClient(conf)
zkClient.getConnectionStateListenable.addListener(new ConnectionStateListener {
private val isConnected = new AtomicBoolean(false)
override def stateChanged(client: CuratorFramework, newState: ConnectionState): Unit = {
info(s"Zookeeper client connection state changed to: $newState")
newState match {
case CONNECTED | RECONNECTED => isConnected.set(true)
case LOST =>
isConnected.set(false)
val delay = maxRetries.toLong * maxSleepTime
connectionChecker.schedule(new Runnable {
override def run(): Unit = if (!isConnected.get()) {
error(s"Zookeeper client connection state changed to: $newState, but failed to" +
s" reconnect in ${delay / 1000} seconds. Give up retry. ")
stopGracefully()
}
}, delay, TimeUnit.MILLISECONDS)
case _ =>
}
}
})
zkClient.start()
super.initialize(conf)
}
当然这里还看到其获取了一个HA_ZK_NAMESPACE的配置值,其默认值为kyuubi:
val HA_ZK_NAMESPACE: ConfigEntry[String] = buildConf("ha.zookeeper.namespace")
.doc("The root directory for the service to deploy its instance uri. Additionally, it will" +
" creates a -[username] suffixed root directory for each application")
.version("1.0.0")
.stringConf
.createWithDefault("kyuubi")
在ServiceDiscoveryService进行启动的时候,就会基于该namesapce来构建在Kyuubi Server层进行服务发现所需要的KyuubiServer实例信息:
override def start(): Unit = {
val instance = server.connectionUrl
_serviceNode = createZkServiceNode(conf, zkClient, namespace, instance)
// Set a watch on the serviceNode
val watcher = new DeRegisterWatcher
if (zkClient.checkExists.usingWatcher(watcher).forPath(serviceNode.getActualPath) == null) {
// No node exists, throw exception
throw new KyuubiException(s"Unable to create znode for this Kyuubi " +
s"instance[${server.connectionUrl}] on ZooKeeper.")
}
super.start()
}
在这里,就会在Zookeeper的/kyuubi节点下面创建一个包含KyuubiServer实例详细连接信息的节点,假设KyuubiServer实例所配置的host和post分别为node2和10009,那么其所创建的zk节点为:

KyuubiSessionManager的初始化与启动
### SessionManager#initailize
override def initialize(conf: KyuubiConf): Unit = synchronized {
addService(operationManager)
val poolSize: Int = if (isServer) {
conf.get(SERVER_EXEC_POOL_SIZE)
} else {
conf.get(ENGINE_EXEC_POOL_SIZE)
}
val waitQueueSize: Int = if (isServer) {
conf.get(SERVER_EXEC_WAIT_QUEUE_SIZE)
} else {
conf.get(ENGINE_EXEC_WAIT_QUEUE_SIZE)
}
val keepAliveMs: Long = if (isServer) {
conf.get(SERVER_EXEC_KEEPALIVE_TIME)
} else {
conf.get(ENGINE_EXEC_KEEPALIVE_TIME)
}
_confRestrictList = conf.get(SESSION_CONF_RESTRICT_LIST).toSet
_confIgnoreList = conf.get(SESSION_CONF_IGNORE_LIST).toSet
execPool = ThreadUtils.newDaemonQueuedThreadPool(
poolSize, waitQueueSize, keepAliveMs, s"$name-exec-pool")
super.initialize(conf)
}
### SessionManager#start
override def start(): Unit = synchronized {
startTimeoutChecker()
super.start()
}
private def startTimeoutChecker(): Unit = {
val interval = conf.get(SESSION_CHECK_INTERVAL)
val timeout = conf.get(SESSION_IDLE_TIMEOUT)
val checkTask = new Runnable {
override def run(): Unit = {
val current = System.currentTimeMillis
if (!shutdown) {
for (session <- handleToSession.values().asScala) {
if (session.lastAccessTime + timeout <= current &&
session.getNoOperationTime > timeout) {
try {
closeSession(session.handle)
} catch {
case e: KyuubiSQLException =>
warn(s"Error closing idle session ${session.handle}", e)
}
} else {
session.closeExpiredOperations
}
}
}
}
}
在这里主要完成的事情:
- 获取session check interval;
- 获取session timout;
- 起一个schedule的调度线程;
- 根据interval和timeout对handleToSession的session进行检查;
- 如果session超时(超过timeout没有access),则closesession;
SparkSQLEngine启动流程
在KyuubiServer为用户建立会话时会去通过服务发现层去Zookeeper查找该用户是否存在对应的SparkSQLEngine实例,如果没有则通过spark-submit的启动一个属于该用户的SparkSQLEngine实例。
后面在分析KyuubiServer Session建立过程会提到,实际上KyuubiServer是通过调用外部进程命令的方式来提交一个Spark应用的,为了方便分析SparkSQLEngine的启动流程,这里将其大致的命令贴出来:
opt/software/spark/spark-3.0.3-bin-hadoop2.7/bin/spark-submit \
--class org.apache.kyuubi.engine.spark.SparkSQLEngine \
--conf spark.sql.adaptive.logLevel=info \
--conf spark.yarn.queue=kyuubi \
--conf spark.kyuubi.ha.zookeeper.client.port=2181 \
--conf spark.app.name=kyuubi_USER_lisi_1f8073ae-3d3a-4d51-a541-afa040b1f3de \
--conf spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=400m \
--conf spark.hive.server2.thrift.resultset.default.fetch.size=1000 \
--conf spark.driver.memory=512m \
--conf spark.executor.instances=1 \
--conf spark.kyuubi.ha.zookeeper.namespace=/kyuubi_USER/zhoujing \
--conf spark.driver.cores=1 \
--conf spark.kyuubi.ha.zookeeper.quorum=zhoujing:2181,node1:2181,node2:2181 \
--conf spark.master=yarn \
--conf spark.yarn.tags=KYUUBI \
--conf spark.sql.adaptive.forceApply=false \
--conf spark.executor.memory=512m \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.executor.cores=1 \
--conf spark.cleaner.periodicGC.interval=5min \
--conf spark.kyuubi.ha.enabled=true \
--proxy-user zhoujing /opt/software/kyuubi-1.2.0-bin-spark-3.0-hadoop2.7/externals/engines/spark/kyuubi-spark-sql-engine-1.2.0.jar
kyuubi-spark-sql-engine-1.2.0.jar是Kyuubi发布版本里面的一个jar包,里面就包含了SparkSQLEngine这个类,通过-class参数我们可以知道,实际上就是要运行SparkSQLEngine的main方法,由于开启了SparkSQLEngine的启动流程。
看一下SparkSQLEngine的main方法:
def main(args: Array[String]): Unit = {
SignalRegister.registerLogger(logger)
var spark: SparkSession = null
var engine: SparkSQLEngine = null
try {
spark = createSpark()
engine = startEngine(spark)
info(KyuubiSparkUtil.diagnostics)
// blocking main thread
countDownLatch.await()
} catch {
case t: Throwable =>
error("Error start SparkSQLEngine", t)
if (engine != null) {
engine.stop()
}
} finally {
if (spark != null) {
spark.stop()
}
}
}
通过createSpark()创建一个SparkSession对象,后续SQL的真正执行都会交由其去执行,其创建方法如下:
def createSpark(): SparkSession = {
val sparkConf = new SparkConf()
sparkConf.setIfMissing("spark.sql.legacy.castComplexTypesToString.enabled", "true")
sparkConf.setIfMissing("spark.master", "local")
sparkConf.setIfMissing("spark.ui.port", "0")
val appName = s"kyuubi_${user}_spark_${Instant.now}"
sparkConf.setIfMissing("spark.app.name", appName)
kyuubiConf.setIfMissing(KyuubiConf.FRONTEND_BIND_PORT, 0)
kyuubiConf.setIfMissing(HA_ZK_CONN_RETRY_POLICY, RetryPolicies.N_TIME.toString)
// Pass kyuubi config from spark with `spark.kyuubi`
val sparkToKyuubiPrefix = "spark.kyuubi."
sparkConf.getAllWithPrefix(sparkToKyuubiPrefix).foreach { case (k, v) =>
kyuubiConf.set(s"kyuubi.$k", v)
}
if (logger.isDebugEnabled) {
kyuubiConf.getAll.foreach { case (k, v) =>
debug(s"KyuubiConf: $k = $v")
}
}
val session = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
kyuubiConf.get(KyuubiConf.ENGINE_INITIALIZE_SQL).split(";").foreach(session.sql(_).show)
session
}
创建完成SparkSession后才调用startEngine(spark)方法启动SparkSQLEngine本身:
def startEngine(spark: SparkSession): SparkSQLEngine = {
val engine = new SparkSQLEngine(spark)
engine.initialize(kyuubiConf)
engine.start()
sys.addShutdownHook(engine.stop())
currentEngine = Some(engine)
engine
}
可以看到也是先进行初始化,然后再启动,SparkSQLEngine本身是CompositeService,所以初始化和启动过程跟KyuubiServer是一模一样的(当然其包含的成员会有所差别),都是递归对serviceList中所包含的各个Service对象进行初始化和启动.
5.3.3 Kyuubi Session建立过程
Kyuubi Session的建立实际上包含两部分,分别是KyuubiServer Session建立和SparkSQLEngine Session建立,这两个过程不是独立进行的,KyuubiServer Session的建立伴随着SparkSQLEngine Session的建立,KyuubiServer Session和SparkSQLEngine Session才完整构成了Kyuubi中可用于执行特定Operation操作的Session。
KyuubiServer Session建立过程
当用户通过JDBC或beeline的方式连接Kyuubi时,实际上就开启了KyuubiServer Session的一个建立过程,此时KyuubiServer中FrontedService的OpenSession方法就会被执行:
### FrontendService#OpenSession
override def OpenSession(req: TOpenSessionReq): TOpenSessionResp = {
debug(req.toString)
info("Client protocol version: " + req.getClient_protocol)
val resp = new TOpenSessionResp
try {
val sessionHandle = getSessionHandle(req, resp)
resp.setSessionHandle(sessionHandle.toTSessionHandle)
resp.setConfiguration(new java.util.HashMap[String, String]())
resp.setStatus(OK_STATUS)
Option(CURRENT_SERVER_CONTEXT.get()).foreach(_.setSessionHandle(sessionHandle))
} catch {
case e: Exception =>
warn("Error opening session: ", e)
resp.setStatus(KyuubiSQLException.toTStatus(e, verbose = true))
}
resp
}
进而开启了KyuubiServer Session建立以及后续SparkSQLEngine实例启动.
服务发现与SparkSQLEngine实例启动
第一次建立特定user的session时,在zk的/kyuubi_USER path下是没有相关user的节点的,比如/kyuubi_USER/xpleaf,因此在代码执行流程中,其获取的值会为None,这就触发了其调用外部命令来启动一个SparkSQLEngine实例。
启动完成之后,就会在Zookeeper上面注册自己的节点信息。
对于KyuubiSessionImpl#open方法,在不超时的情况下,循环会一直执行,直到其获取到用户的SparkSQLEngine实例信息,循环结束,进入下面跟SparkSQLEngine实例建立会话的过程。
建立与SparkSQLEngine实例的会话
SparkSQLEngine本质上也是一个RPC服务端,为了与其进行通信以建立会话,就需要构建RPC客户端,这里KyuubiSessionImpl#openSession方法中构建RPC客户端。
在发送请求给SparkSQLEngine的时候,又会触发SparkSQLEngine Session建立的过程(这个接下来说明),在跟其建立完Session之后,KyuubiSessionImpl会将其用于标识用户端会话的sessionHandle、用于跟SparkSQLEngine进行通信的RPC客户端和在SparkSQLEngine实例中进行Session标识的remoteSessionHandle缓存下来,这样在整个Kyuubi体系中,就构建了一个完整的Session映射关系:userSessionInKyuubiServer-RPCClient-KyuubiServerSessionInSparkSQLEngine,后续的Operation都是建立在这样一个体系之下。
KyuubiServer在Session建立完成后会给客户端返回一个SessionHandle,后续客户端在与KyuubiServer进行通信时都会携带该SessionHandle,以标识其用于会话的窗口。
SparkSQLSession建立过程
在接收到来自KyuubiServer的建立会话的RPC请求之后,SparkSQLEngine中FrontedService的OpenSession方法就会被执行,其整体流程与KyuubiServer Session的建立过程是类似的,主要不同在于SparkSQLSessionManager#openSession方法执行上面。
### SparkSQLSessionManager#openSession
override def openSession(
protocol: TProtocolVersion,
user: String,
password: String,
ipAddress: String,
conf: Map[String, String]): SessionHandle = {
info(s"Opening session for $user@$ipAddress")
val sessionImpl = new SparkSessionImpl(protocol, user, password, ipAddress, conf, this)
val handle = sessionImpl.handle
try {
val sparkSession = spark.newSession()
sessionImpl.normalizedConf.foreach {
case ("use:database", database) => sparkSession.catalog.setCurrentDatabase(database)
case (key, value) => setModifiableConfig(sparkSession, key, value)
}
sessionImpl.open()
operationManager.setSparkSession(handle, sparkSession)
setSession(handle, sessionImpl)
info(s"$user's session with $handle is opened, current opening sessions" +
s" $getOpenSessionCount")
handle
} catch {
case e: Exception =>
sessionImpl.close()
throw KyuubiSQLException(e)
}
}
SparkSQLEngine在Session建立完成后会给KyuubiServer返回一个SessionHandle,后续KyuubiServer在与SparkSQLEngine进行通信时都会携带该SessionHandle,以标识其用于会话的窗口。
5.3.4 KyuubiServer SQL执行流程
提交Statement
当用户通过JDBC或beeline的方式执行一条SQL语句时,就开启了SQL语句在Kyuubi中的执行流程,此时KyuubiServer中FrontedService的ExecuteStatement方法就会被执行
### FrontedService#ExecuteStatement
override def ExecuteStatement(req: TExecuteStatementReq): TExecuteStatementResp = {
debug(req.toString)
val resp = new TExecuteStatementResp
try {
val sessionHandle = SessionHandle(req.getSessionHandle)
val statement = req.getStatement
val runAsync = req.isRunAsync
// val confOverlay = req.getConfOverlay
val queryTimeout = req.getQueryTimeout
val operationHandle = if (runAsync) {
be.executeStatementAsync(sessionHandle, statement, queryTimeout)
} else {
be.executeStatement(sessionHandle, statement, queryTimeout)
}
resp.setOperationHandle(operationHandle.toTOperationHandle)
resp.setStatus(OK_STATUS)
} catch {
case e: Exception =>
warn("Error executing statement: ", e)
resp.setStatus(KyuubiSQLException.toTStatus(e))
}
resp
}
client实际上就是我们前面在KyuubiServer Session建立过程中建立的用于与SparkSQLEngine通信的RPC客户端,ExecuteStatement需要client来发送执行SQL语句的请求给SparkSQLEngine实例,不过需要注意的是,这里的ExecuteStatement是KyuubiServer体系下的,其类全路径为org.apache.kyuubi.operation.ExecuteStatement,因为后面在分析SparkSQLEngine SQL执行流程时,在SparkSQLEngine体系下也有一个ExecuteStatement,但其类全路径为org.apache.kyuubi.engine.spark.operation.ExecuteStatement。
## kyuubi.operation.ExecuteStatement#executeStatement
private def executeStatement(): Unit = {
try {
MetricsSystem.tracing { ms =>
ms.incCount(STATEMENT_OPEN)
ms.incCount(STATEMENT_TOTAL)
}
val req = new TExecuteStatementReq(remoteSessionHandle, statement)
req.setRunAsync(shouldRunAsync)
req.setQueryTimeout(queryTimeout)
val resp = client.ExecuteStatement(req)
verifyTStatus(resp.getStatus)
_remoteOpHandle = resp.getOperationHandle
} catch onError()
}
这里statement实际上就是要执行的SQL语句,所以本质上就是向SparkSQLEngine发送了一个用于执行SQL语句的RPC请求,这样就会触发SparkSQLEngine执行提交Statement的一个过程(这个接下来会分析),请求成功后,KyuubiServer会将SparkSQLEngine实例用于记录该操作的operationHandle记录下来,就是赋值给成员变量_remoteOpHandle,_remoteOpHandle用后续用于查询statement在SparkSQLEngine实例中的执行状态和FetchResults。
在提交完Statement之后,KyuubiServer会将operationHandle返回给用户端,用于后续获取执行结果。