TPAMI 2022 | 国防科大等高校提出光场解耦机制,在超分辨与视差估计任务上取得优异性能...
关注公众号,发现CV技术之美
光场相机可以通过记录光线的强度与方向信息将3维场景编码至4维光场图像。近年来,卷积神经网络被广泛应用于各项光场图像处理任务。然而,由于光场的空间信息与角度信息随空变的视差高度耦合,现有的卷积网络难以有效处理高维的光场数据。
鉴于此,该文提出了一种通用的光场解耦机制,通过设计一系列的解耦卷积将高维光场解耦至多个低维子空间,实现了光场数据的高效处理。基于所提解耦机制,该文针对空间超分辨、角度超分辨以及视差估计任务分别设计了DistgSSR、DistgASR以及DistgDisp三个网络。
实验结果表明该文所提网络能够在以上三个任务中取得一致优异的性能,验证了所提光场解耦机制的有效性、高效性与通用性。 相关论文收录于IEEE TPAMI期刊,代码已开源。

论文: https://arxiv.org/pdf/2202.10603.pdf
主页: https://yingqianwang.github.io/DistgLF/
▊ 引言(Introduction)
光场(light field,LF)相机可以同时记录光线的强度和角度信息,在重聚焦、深度估计、虚拟现实、增强现实等方面具有广泛的应用。随着深度学习的发展,卷积神经网络被应用于各类光场图像处理任务并不断取得性能提升。
然而,光场图像的空间信息与角度信息高度耦合于空变的视差(disparity),使得卷积神经网络难以直接从高维光场中提取有用信息。现有方法通常采用“分而治之”的策略,通过处理部分光场图像(如相邻视角、极平面图像或行列子光场)实现数据降维。这样的策略虽然能够解决高维光场数据处理的难题,却无法充分利用所有视角的信息,从而限制了算法的性能。
该文提出了一个通用的 光场解耦机制 以实现高维光场数据的处理。基于光场图像的结构先验,该文设计了空间、角度、极平面三类解耦卷积,将光场解耦至不同的二维子空间中,而后通过设计相应的模块对不同子空间提取的信息进行融合。
相比于现有的基于卷积网络的光场图像处理框架,该文所提解耦机制具有 三个显著优点:
1)可以很好地结合光场的结构先验并充分利用所有视角的信息;
2)通过将4维光场解耦至不同的2维子空间,降低了单个子空间内卷积层的学习难度,从而提升了网络的性能;
3)所提解耦机制具有通用性并且可以应用至不同的光场图像处理任务中。
基于所提光场解耦机制,该文分别提出了DistgSSR、DistgASR以及DistgDisp三个网络用于空间超分辨、角度超分辨以及视差估计三个典型的光场图像处理任务。实验结果表明,该文所提网络能够在以上三个任务中取得一致优异的性能,验证了所提光场解耦机制的有效性、高效性与通用性。
▊ 光场解耦机制(The LF Disentangling Mechanism)
光场的表示与可视化
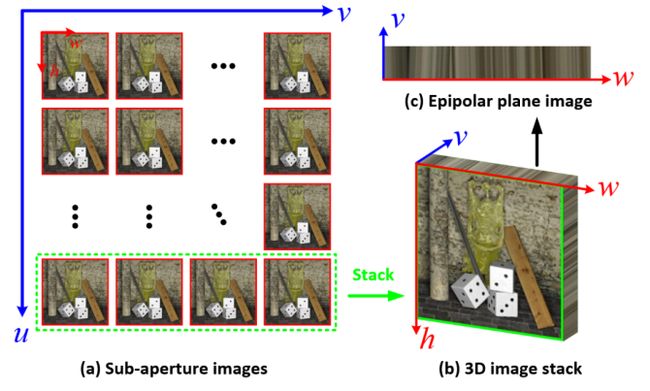
图1 光场图像的阵列子图像(SAI)与极平面图像(EPI)示意图
光场图像在不同的维度具有不同的特性。如图1(a)所示,4维光场可以可视化为U×V的阵列子图像(sub-aperture image,SAI),每一幅子图像的分辨率均为H×W。
此外,如图1(b)和图1(c)所示,当固定一个空间维度(如h)和一个角度维度(如u)时,4维光场可以被可视化为极平面图像(epipolar plane image,EPI)。场景中的物体在不同视角图像上的投影表现为极平面图像上的一条斜线,而斜线的斜率体现了该物体在不同视角图像间的视差(disparity),与该物体所处的深度相关。

图2 光场图像的阵列子图像(SAI)与宏像元图像(MacPI)示意图
若将每幅阵列子图像相同空间位置的像元按照视角顺序进行排列,则可以构成如图2(b)所示的宏像元图像(macro-pixel image,MacPI)。在宏像元图像中,各个视角的信息被紧密编码在空间相邻的像元中,基于这一特殊的结构,该文通过设计特定的卷积算子灵活地结合特定维度的信息,实现了光场的解耦。
光场解耦机制

图3 该文所提光场解耦卷积算子示意图。图中红色卷积为角度特征提取子(AFE),紫色卷积为空间特征提取子(SFE),绿色卷积为水平/竖直极平面特征提取子(EFE-H/EFE-V)。
图3为简化的光场宏像元图像示意图。在该示例中,光场的空间分辨率为3×4,角度分辨率为3×3。图中涂有不同底色的区域表示不同的宏像元,每个宏像元内的像元标有不同的字母,表示其属于不同的视角。设光场图像的角度分辨率为A×A,该文所提解耦卷积算子的定义如下:
- 空间特征提取子SFE定义为kernel size=3×3,stride=1,dilation=A的卷积;
- 角度特征提取子AFE定义为kernel size=A×A,stride=A的卷积;
- 水平极平面特征提取子EFE-H定义为kernel size=1×(A^2),stride=[1, A]的卷积;
- 竖直极平面特征提取子EFE-V定义为kernel size= (A^2)×1,stride=[A ,1]的卷积;
将AFE应用于宏像元图像时,只有单个宏像元内(不同视角、相同空间位置)的像元参与卷积运算,而不同宏像元之间的信息不互通;将SFE应用于宏像元图像时,只有属于相同视角的像元参与卷积运算,而属于不同视角的像元不互通。
因此,通过采用AFE与SFE,4维光场可以被解耦至U-V和H-W两个相互正交的2维子空间,使得后续的卷积层能够独立处理光场的空间和角度特征,降低了光场特征学习的难度。
此外,考虑到极平面图像中的斜线能够很好地反映空间与角度之间的关联,将EFE应用于宏像元图像(等价于在极平面图像上做A×A卷积)可以将4维光场解耦至U-H和V-W两个相互正交的2维极平面子空间。通过结合属于相同行(列)视角的局部空间角度信息,可以加强网络对光场空间角度关联的建模能力。
上述所提的特征提取子(解耦卷积)可以将4维光场解耦至不同的子空间,在每一个子空间内,光场的特征分布更有规律,从而降低了卷积层进行特征学习的难度。在将该解耦机制应用于各类光场图像处理任务中时,不同类型的解耦卷积可以组合为不同的模块。通过堆叠多个解耦模块,所提解耦卷积可以实现协同工作,并对复杂的光场数据进行多子空间联合学习,通过扩大网络的感受野以覆盖空变的视差。
▊ 基于光场解耦的空间超分辨(DistgSSR)
光场空间超分辨(LF spatial super-resolution),也常被称为光场图像超分辨(LF image super-resolution),旨在通过低分辨率的光场图像(例如128×128像素)重建出高分辨率的光场图像(例如512×512像素)。基于所提光场解耦机制,该文构建了用于空间超分辨的DistgSSR网络。
网络结构

图4 DistgSSR网络结构图
DistgSSR网络结构如图4所示,该网络将低分辨率(HA×WA)的光场图像恢复为高分辨率(αHA×αWA)的光场图像,其中α(α=2, 4)为空间上采样系数。
性能比较
该文在5个公开数据集上将DistgSSR与领域多个单图超分辨算法以及光场图像超分辨算法进行了比较,结果如下:
表1 不同图像超分辨方法PSNR与SSIM数值结果比较
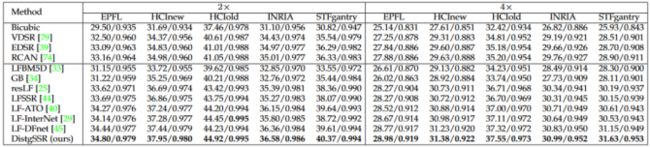
由表1可见,DistgSSR在各个数据集上均能取得领先的性能。图5展示了不同超分辨算法的视觉效果,DistgSSR能够生成更加真实丰富的细节,且能够较好地保持光场的结构特性(EPI线更加清晰)。

图5 不同图像超分辨方法视觉效果比较
表2比较了不同图像超分辨算法的运行效率与性能。如表所示,即使将DistgSSR的主通道数从64减少至32(参数量减小为原模型的1/4),该网络仍然可以达到领先的超分辨性能,同时参数量与运算量远小于resLF、LF-InterNet、LF-DFnet等网络。
这主要是因为,通过所提解耦机制将光场解耦至不同的子空间降低了卷积网络学习特征映射的难度,因此用更少的参数量可以实现更好的性能。这充分表明了所提解耦机制在空间超分辨任务上的有效性。
表2 不同超分辨方法运行效率比较

以下视频展示了DistgSSR网络输出的光场不仅具有更加丰富的细节,而且具有更高的角度一致性。
视频链接:https://wyqdatabase.s3.us-west-1.amazonaws.com/DistgLF-SpatialSR.mp4
▊ 基于光场解耦的角度超分辨(DistgASR)
光场角度超分辨(LF angular SR),也常被称为光场重建(LF reconstruction)或视角合成(view synthesis),旨在通过角度维度上稀疏采样的光场(例如2×2视角)重建出密集视角采样的光场(例如7×7视角)。基于所提光场解耦机制,该文构建了用于角度超分辨的DistgASR网络。
网络结构

图6 DistgASR网络结构图
DistgASR网络结构如图6所示,该网络将稀疏采样(HA×WA)的光场图像恢复为密集采样(βHA×βWA)的光场图像,其中β为角度上采样系数(对于2×2→7×7的角度超分辨而言β=7/2)。
算法性能比较
该文在5个公开数据集上将DistgASR与领域多个角度超分辨算法进行了比较,结果如下:
表3 不同光场角度超分辨方法PSNR与SSIM数值结果比较

由表3可见,DistgASR在4个数据集上取得最优的光场重建性能。图7展示了不同角度超分辨算法的视觉效果与重建误差,DistgASR能够更加精确地重建出新视角,且能够较好地保持光场的结构特性(EPI线更加清晰)。以上结果验证了该文所提解耦机制在光场角度超分辨任务上的有效性。
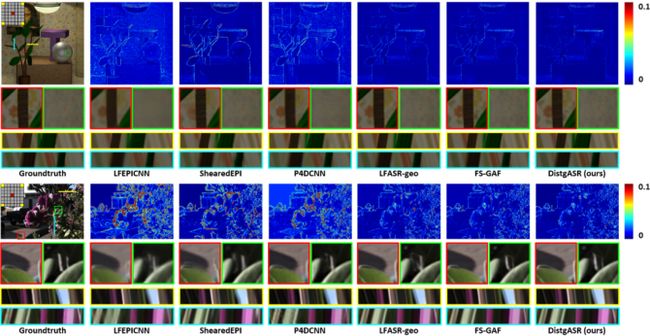
图7 不同光场角度超分辨方法视觉效果与重建误差比较
以下视频展示了DistgASR网络重建出的光场具有丰富的细节和更高的角度一致性。
视频链接:https://wyqdatabase.s3.us-west-1.amazonaws.com/DistgLF-AngularSR.mp4
▊ 基于光场解耦的视差估计(DistgDisp)
光场视差估计(LF disparity estimation),也常被称为光场深度估计(LF depth estimation),旨在估计场景中的物体在各个视角图像之间的相对位移值。由于视差与光场相机的基线长度以及物体所处的深度相关,因此可以通过视差推断出物体所在的深度。基于所提光场解耦机制,该文构建了用于光场视差估计的DistgDisp网络。
网络结构

图8 DistgDisp网络结构图
如图8所示,DistgDisp网络的输入是宏像元形式的光场图像,输出是中心视角的视差图。网络主要分为 特征提取、匹配代价构建、匹配代价聚合 以及 视差回归 四个阶段。DistgDisp网络在特征提取阶段采用含批归一化的SFE对输入光场的空间邻域信息进行解耦与建模。
在匹配代价构建阶段,DistgDisp网络基于所提解耦机制设计了视差选择性角度特征提取子(disparity-selective angular feature extractor,DS-AFE)。将DS-AFE应用于宏像元图像可以实现预定视差下的角度信息提取,即匹配代价的构建。
算法性能比较
该文在HCI 4D LF Benchmark上将DistgDisp与领域多个视差估计算法进行了比较,结果如下。
表4 不同光场视差估计方法的数值结果比较


图9 不同视差估计算法的视觉效果展示
由表4和图9可见,DistgDisp网络能够达到领域先进的视差估计性能,具有较小的视差估计误差。作者将DistgDisp提交至HCI 4D LF Benchmark并与Benchmark上的其他方法做了广泛的比较,结果如图10所示。在共计81个提交算法中,DistgDisp的各项误差指标均排名前4。
值得一提的是,由于所提DS-AFE能够替代耗时的特征位移操作而通过卷积的方式构建匹配代价,因此在运行时间方面具有较大优势(在benchmark上排名第一)。

图10 HCI 4D LF Benchmark上的排名截图(2021年7月)。在当时81个提交结果中,DistgDisp算法在各项误差指标上排前4名,运行时间排第1名。
作者在该文最后将所提DistgSSR、DistgASR以及DistgDisp进行了集成,从稀疏采样的低分辨率光场(2×2×256×256)重建出密集采样的高分辨率光场(7×7×512×512),且通过重建的光场估计了场景的视差(相对深度)分布。而后,作者根据所估计的视差图引导重聚焦算法进行深度辅助的光场重聚焦,展示了所提算法的应用前景。
视频链接:https://wyqdatabase.s3.us-west-1.amazonaws.com/DistgLF-demo.mp4
▊ 结论(Conclusion)
该文提出了一个通用的光场解耦机制,通过设计空间、角度和极平面特征提取子将四维光场解耦至不同的子空间,促进了卷积神经网络学习光场的内里结构。该文所提解耦机制高效紧凑且适用于不同的光场图像处理任务。
基于所提解耦机制,作者设计了DistgSSR、DistgASR和DistgDisp分别应用于空间超分辨、角度超分辨和视差估计三个典型的光场图像处理任务。实验结果表明所提三个网络在各自任务中均达到了领域领先的性能,从而验证了所提解耦机制的有效性与通用性。

END
欢迎加入「光场技术」交流群备注:光场
