论文笔记(R3Det,AAAI2021)

文章
R3Dethttps://arxiv.org/abs/1908.05612 https://arxiv.org/abs/1908.05612
https://arxiv.org/abs/1908.05612
代码
Tensorflow版本https://github.com/yangxue0827/RotationDetectionhttps://github.com/yangxue0827/RotationDetectionPyTorch版本https://github.com/SJTU-Thinklab-Det/r3det-on-mmdetectionhttps://github.com/SJTU-Thinklab-Det/r3det-on-mmdetection
带着问题读文章
1.从粗粒度到细粒度的渐进回归方法是什么?
2.特征细化模块是什么?
3.近似SkewIoU的损失函数是如何定义的?
4.实验效果如何?
从粗粒度到细粒度的渐进回归方法
前半部分和RetinaNet一样,用resnet提取特征,FPN建立特征图,每层特征图进行分类和回归。从粗粒度到细粒度的渐进回归方法有点像双阶段检测器,第一阶段使用速度更快、召回率更高的水平anchor,长宽比为{1, 1/2, 2, 1/3, 3, 5, 1/5} 、规格为{2^0 , 2^1/3 , 2^2/3}。后续的细化阶段使用旋转的anchor以适应密集的场景,角度为{−90◦ , −75◦ , −60◦ , −45◦ , −30◦, −15◦}。
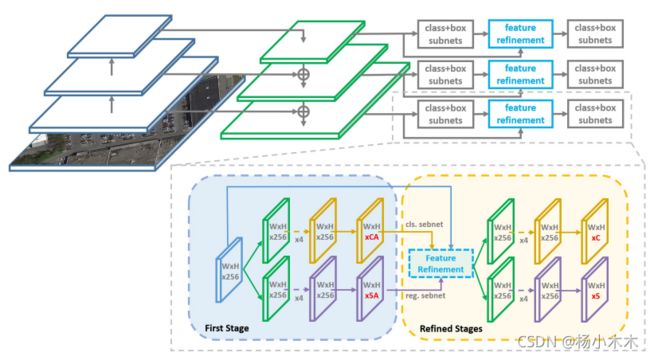
Figure 1: The architecture of the proposed Refined Rotation Single-Stage Detector (RetinaNet as an embodiment). The refinement stage can be repeated by multiple times. ’A’ indicates the number of anchors on each feature point, and ’C’ indicates the number of categories.
特征细化模块
回归的结果在这里添加角度然后过滤出得分最高的anchor,特征图经过5x1和1x5以及1x1的卷积组合而成的“大核”进行特征重组。
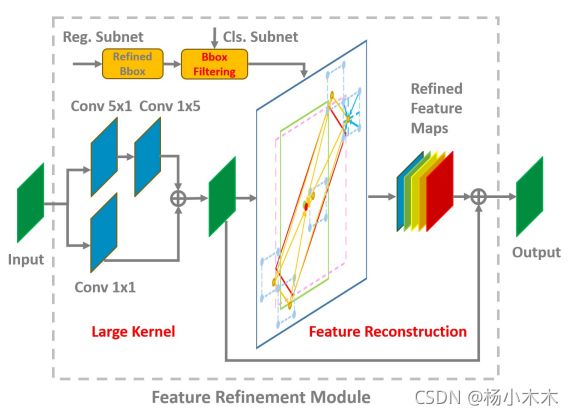
Figure 5: Feature Refinement Module FRM. It mainly includes three parts: refined bounding box filtering (BF), large kernel (LK) and feature reconstruction (FR).
许多细化检测器仍然使用相同的特征图进行多次分类和回归,而没有考虑边界框位置变化引起的特征错位。

Figure 4: Root cause analysis of feature misalignment and the core idea for our proposed feature refinement module.
图4 (c) 描绘了没有特征细化的细化过程,导致特征不准确,这对于那些具有大纵横比或小样本量的类别来说可能是不利的。 此方法将当前细化的边界框(橙色矩形)的位置信息重新编码为对应的特征点(红色点2),从而通过逐像素的方式重建整个特征图以实现特征的对齐。整个过程如图4(d)所示。 为了准确地获取与细化边界框对应的位置特征信息,此方法采用双线性特征插值方法,如图4(b)所示。 特征插值可以表述如下:
![]()
其中A表示图4(b)中的Area,F∈R C×1×1表示特征图上点的特征向量。
基于上述结果,此方法设计了特征细化模块,其结构和伪代码分别如图5和算法3.2所示。

具体来说,通过双向卷积加入特征图,得到一个新的特征(大核,LK)。 在细化阶段只保留每个特征点得分最高的边界框以提高速度(框过滤,BF),同时确保每个特征点只对应一个细化的边界框。 边界框的过滤是特征重建(FR)的必要步骤。对于特征图的每个特征点,此方法根据细化边界框的五个坐标(一个中心点和四个角点)得到特征图上对应的特征向量。 通过双线性插值得到更准确的特征向量,我们添加五个特征向量并替换当前特征向量。 遍历特征点后,重建整个特征图。 最后将重构后的特征图添加到原始特征图中完成整个过程。
细化阶段可以添加并重复多次。 每个细化阶段的特征重建过程模拟如下:
![]()
其中Fi+1代表第i+1阶段的特征图,Bi、Si分别代表第i阶段预测的边界框和置信度分数
近似SkewIoU损失函数
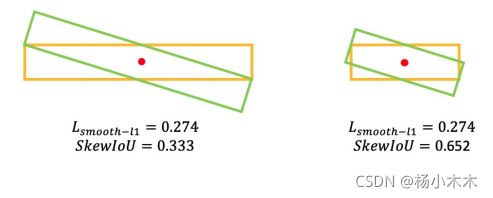
Figure 2: Comparison between SkewIoU and Smooth L1 Loss.
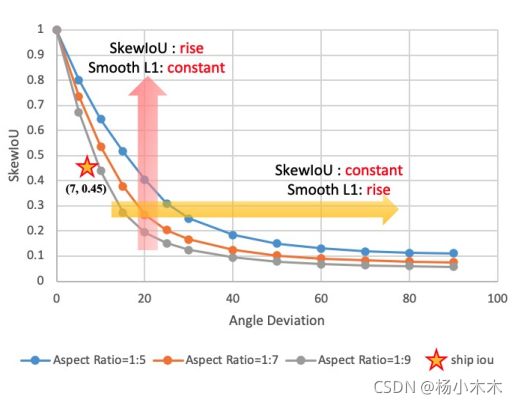
Figure 3 (b): The SkewIoU scores vary with the angle deviation.
从图 2和图 3(b) 中我们可以得出,Smooth L1 损失函数仍然不适合旋转检测,特别是对于具有大长宽比的目标,它们对 SkewIoU 很敏感。由于两个旋转框之间的SkewIoU计算函数是不可推导的,这意味着不能直接使用 SkewIoU 作为回归损失函数。所以此方法设计了一个可推到的近似SkewIoU损失函数,定义为:
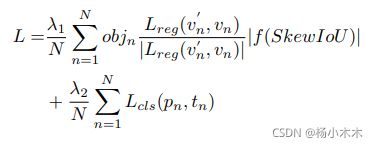
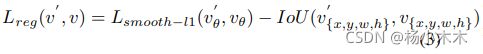
其中 N 表示anchor的数量,objn 是一个二进制值(objn = 1 表示前景,objn = 0 表示背景,背景无回归)。 v'表示预测的偏移向量,v 表示ground-truth 的目标向量。 tn 表示对象的标签,pn 是通过 sigmoid 函数计算的各个类别的概率分布。 SkewIoU 表示预测框和真实值的重叠。 超参数 λ1、λ2 控制权衡,默认设置为 1。 分类损失 Lcls 由Focal Loss实现。 |.| 用于获取向量的模数,不参与梯度反向传播。 f(.) 表示与 SkewIoU 相关的损失函数。 IoU(.)表示水平边界框IoU计算函数。
 负责终止梯度传播的方向(单位向量),这是确保损失函数可推导的重要部分。
负责终止梯度传播的方向(单位向量),这是确保损失函数可推导的重要部分。 ![]() 负责调整损失值(梯度的大小),不需要可推导(标量)。 考虑到 SkewIoU 和Smooth L1 损失之间的不一致,此方法使用等式 3 作为回归损失的主要梯度函数。 通过这样的组合,损失函数是可推导的,而其大小与 SkewIoU 高度一致。
负责调整损失值(梯度的大小),不需要可推导(标量)。 考虑到 SkewIoU 和Smooth L1 损失之间的不一致,此方法使用等式 3 作为回归损失的主要梯度函数。 通过这样的组合,损失函数是可推导的,而其大小与 SkewIoU 高度一致。
SkewIoU 分数对角度的变化很敏感,轻微的角度偏移会导致 IoU 分数快速下降,如图 3 所示。 因此,预测框的细化有助于提高旋转检测的召回率。 此方法加入了多个具有不同 IoU 阈值的细化阶段。 除了在第一阶段使用前景 IoU 阈值 0.5 和背景 IoU 阈值 0.4 外,第一阶段细化的阈值分别设置为 0.6 和 0.5。 如果有多个细化阶段,剩余的阈值为 0.7 和 0.6。 精炼检测器的整体损失定义如下:
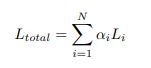
其中 Li 是第 i 个细化阶段的损失值,权衡系数 αi 默认设置为 1。
实验
1.DOTA

Table 6: Detection accuracy on different objects (AP) and overall performance (mAP) evaluation on DOTA. R3Det† indicates that two refinement stages have been added. MS indicates that multi-scale training or testing is used.
2.HRSC2016
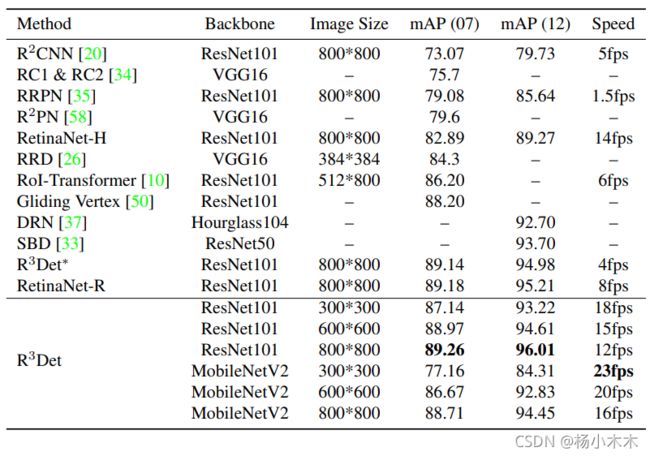
Table 7: Accuracy and speed on HRSC2016. 07 (12) means using the 2007 (2012) evaluation metric.
3.UCAS-AOD

Table 8: Performance evaluation on UCAS-AOD datasets.