NeuIPS2020|视频表示学习的自监督协同训练

本文由牛津大学提出
作者主要研究针对视觉的自监督视频表示学习:
(i)研究了在基于实例的信息噪声对比估计(InfoNCE)训练中添加语义类肯定句的好处,表明这种形式的监督式对比学习可以明显改善性能;
(ii)提出了一种自监督协同训练方案,通过使用一个视图获取同一数据源的正视图样本来利用同一数据源的不同视图,即RGB流和光流的互补信息来改善InfoNCE损失。
(iii)在两个不同的下游任务(动作识别和视频检索)上全面评估所学表示的质量。
引言
作者以自监督视频表示学习为目标,提出一个问题:实例判别是否在充分利用数据?从两个方面证明答案是否定的:
首先,作者表明在自监督的训练中忽略了hard positives,如果包括这些hard positives,则学习表示的质量也会大大提高。
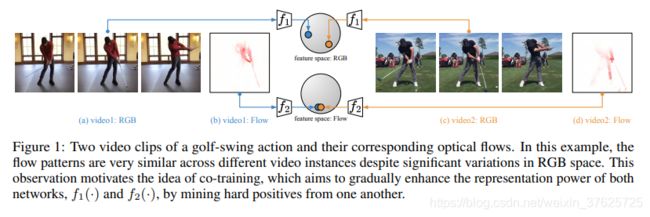
图1 视频片段与其对应的光流
其次,作者提出一种称为CoCLR的自监督式联合训练方法,代表“视觉表示的联合训练对比学习”,目的是通过使用数据的其他互补视图。作者选择RGB视频帧和光流作为两个视图。如图1所示,从流中获得的正值可用于“弥合” RGB视频剪辑实例之间的间隙。 反过来,从RGB视频片段获得的正片可以链接相同动作的光流片段。使用CoCLR算法进行训练的结果,超过了使用InfoNCE进行基于实例的训练所获得的性能,并且接近使用UberNCE进行的Oracle训练的性能。
作者通过改进视觉表示的对比学习中的采样过程来针对training regime训练制度。
这样做有两个好处:
第一,在训练中使用相同类别的(硬性hard)正面示例(例如,图1中所示的高尔夫挥杆动作);
第二,将这些正样本从实例级别的负样本中删除
本文主要使用另一视图提供的补充信息来改进RGB和Flow网络的表示。为了进行推断,可以选择仅使用RGB网络或Flow网络,或同时使用这两种网络。
作者为此进行了一个oracle实验,在该实验中,基于语义类标签将阳性样本合并到基于实例的训练过程中。在纯基于实例的学习和oracle版本之间观察到明显的性能差距。oracle是监督式对比学习的一种形式,它鼓励根据类标签进行要素表示的线性可分离性。
InfoNCE, UberNCE and CoCLR
通过InfoNCE和UberNCE学习
InfoNCE 给定具有N个原始视频剪辑的数据集,例如 D = { x 1 , x 2 , . . } D = \{x1,x2,.. \} D={x1,x2,..} 自监督视频表示学习的目标是获得一个函数 f ( ⋅ ) f(·) f(⋅),该函数可有效地用于对各种下流任务(例如视频)的视频剪辑进行编码,,如动作识别,检索等
假设有一个增强函数 ψ ( ⋅ ; a ) ψ(·; a) ψ(⋅;a),其中a是从一组预定义的数据增强转换A中采样的,该转换A应用于D。对于特定样本 x i x_i xi,正集合 P i P_i Pi和负集合 N i N_i Ni 定义为: P i = { ψ ( x i ; a ) ∣ a 〜 A } P_i = \{ψ(x_i; a)| a〜A\} Pi={ψ(xi;a)∣a〜A}, N i = { ψ ( x n ; a ) ∣ ∀ v n ! = i , a 〜 A } N_i = \{ψ(x_n; a)|∀v_n!= i,a〜A\} Ni={ψ(xn;a)∣∀vn!=i,a〜A}。 给定 z i = f ( ψ ( x i ; ⋅ ) ) z_i = f(ψ(x_i;·)) zi=f(ψ(xi;⋅)),则InfoNCE损失为:
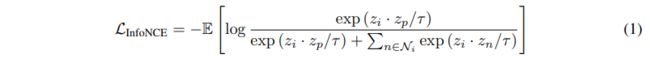
其中 z i ⋅ z p z_i·z_p zi⋅zp指两个向量之间的点积。
UberNCE 假设一个带有注释的数据集 D = ( ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) ) D = {((x_1,y_1),(x_2,y_2),... ,(x_N,y_N))} D=((x1,y1),(x2,y2),...,(xN,yN)),其中 y i y_i yi是剪辑 x i x_i xi的类标签。通过优化与等式1相同的InfoNCE来搜索函数 f ( ⋅ ) f(·) f(⋅),正集 P i P_i Pi和负集 N i N_i Ni可以包括具有相同语义标签的样本。
自监督CoCLR
作为先前符号的扩展,给定视频剪辑 x i x_i xi,考虑两个不同的视图 x i = { x 1 i , x 2 i } x_i = \{x_{1i},x_{2i}\} xi={x1i,x2i}, x 1 i x_{1i} x1i和 x 2 i x_{2i} x2i指的是RGB帧及其无监督的光流。自监督视频表示学习的目的是学习函数 f 1 ( ⋅ ) f_1(·) f1(⋅)和 f 2 ( ⋅ ) f_2(·) f2(⋅),其中 z 1 i = f 1 ( x 1 i ) z_{1i} = f_1(x_{1i}) z1i=f1(x1i)和 z 2 i = f 2 ( x 2 i ) z_{2i} = f_2(x_{2i}) z2i=f2(x2i)是指RGB流和光流的表示, 可以有效地用于执行各种下游任务。
CoCLR的关键思想以及该方法与InfoNCE和UberNCE的不同之处在于构造样本 x i x_i xi的正集合 ( P i ) (P_i) (Pi)和负集合 ( N i ) (N_i) (Ni)。通过从其他数据视图中挖掘正对来共同训练模型。 用多实例InfoNCE 损失更新RGB表示 f 1 ( ⋅ ) f_1(·) f1(⋅):
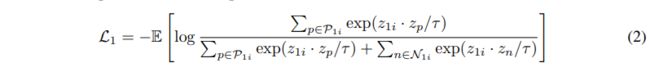
公式2的分子定义为样本 x 1 i x_{1i} x1i(在RGB视图中)与正集之间的“相似度”之和,该正集由与 x 2 i x_{2i} x2i最相似的视频片段(光流视图):
![]()
z 2 i ⋅ z 2 j z_{2i}·z_{2j} z2i⋅z2j指的是光流视图中第i个视频和第j个视频之间的相似性, t o p K ( ⋅ ) topK(·) topK(⋅)运算符在所有可用N个样本上选择topK个项并返回其索引。K代表正向挖掘的严格性的超参数。样本 x i x_i xi的负集 N 1 i N_{1i} N1i是正集的补数, N 1 i = P 1 i N_{1i}= P_{1i} N1i=P1i。正集由光流特征空间中最靠前的K个邻居加上视频片段自身的增强组成,而负集则包含所有其他视频片段及其增强。
同样,要更新光流表示 f 2 ( ⋅ ) f_2(·) f2(⋅),可以优化为:
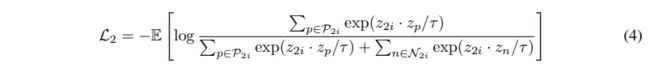
公式4与(2)是相同的目标函数,只不过现在是根据RGB视图中的相似性等级构造正集的:
![]()
CoCLR算法 两阶段进行:初始化和轮换。
初始化 首先,使用InfoNCE独立训练具有不同视图的两个模型,即通过优化 L I n f o N C E L_{InfoNCE} LInfoNCE来训练RGB和Flow网络。
轮换 一旦使用 L I n f o N C E L_{InfoNCE} LInfoNCE进行了训练,RGB和Flow网络都比随机初始化的网络获得了更强大的表示能力。协同训练过程将按照等式2和等式4中所述进行。例如:优化L1,使用Flow网络挖掘(hard positive)硬正对;优化L2,使用RGB网络挖掘硬正对。
这两种优化是轮换进行的:每回第一次从其他网络中挖掘硬正对,然后独立地最小化网络的损失
定义轮换过程的关键超参数是:用于检索K个与语义相关的视频剪辑的K值,以及使每个损失函数(即轮换的粒度)最小化的迭代次数(或epochs)。其中每个iteration指的是对L1和L2的完全优化; 轮换仅在RGB或流网络收敛后发生。
实验
数据集 使用两个视频动作识别数据集进行自监督的CoCLR训练:UCF101, Kinetics-400

表1 三种方法的对比
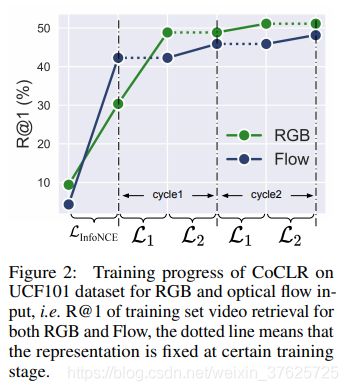
图2 网络的训练进程
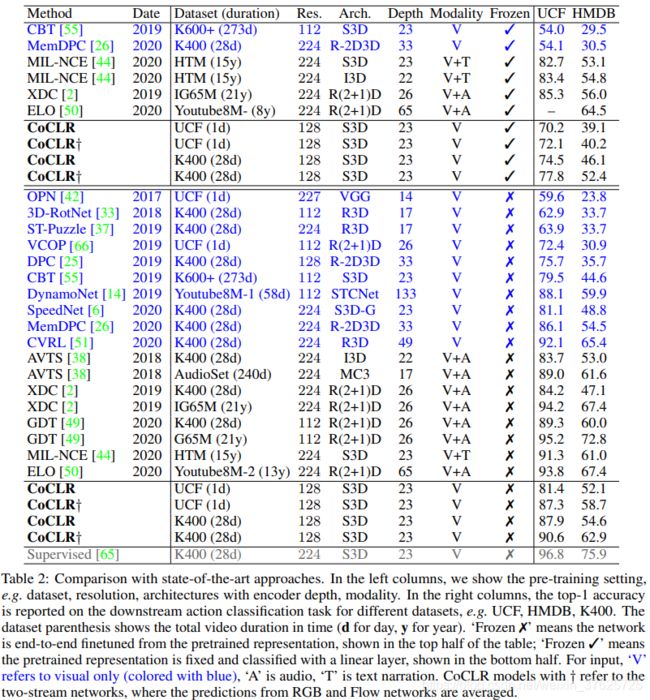
表2 与先进方法的对比
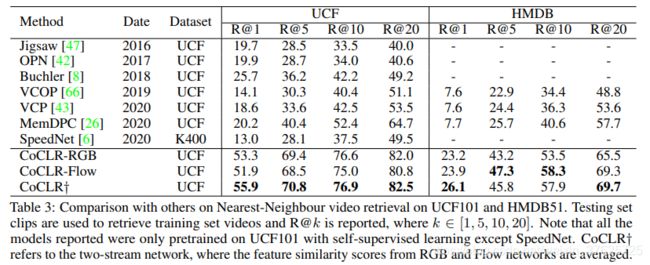
表3 不同数据集的对比

图3 CoCLR表示的最近邻检索结果
结论
作者表明,可以使用视频的互补视图来弥合相同类别的RGB视频剪辑实例之间的差距,并使用它来生成积极的训练集。与针对视频表示的InfoNCE实例训练相比,提高了性能。
作者研究了从RGB帧,无监督光流或两者中学习的视觉自监督视频表示,并做出了以下贡献:
(i)具有语义类标签访问权限的oracle可以提高基于实例的对比学习的性能;
(ii)提出了一种自监督式联合训练计划CoCLR,以利用来自同一数据源的不同观点的补充信息来改善InfoNCE的训练制度;
(iii)评估模型在数据集UCF101和HMDB51上的两个下游任务,即视频动作识别和检索。
实验展示了优于其他自监督方法的最新技术或相当的性能,同时效率显着提高,即自监督预训练所需的数据更少。
CoCLR的样例伪代码

论文 https://arxiv.org/pdf/2010.09709.pdf
训练所需的数据更少。
CoCLR的样例伪代码
[外链图片转存中…(img-AxLLDaqO-1604073521474)]
论文 https://arxiv.org/pdf/2010.09709.pdf
工程链接 http://www.robots.ox.ac.uk/~vgg/research/CoCLR/
AI算法后丹修炼炉是一个由各大高校以及一线公司的算法工程师组建的算法与论文阅读分享组织。我们不定期分享最新论文,资讯,算法解析,以及开源项目介绍等。欢迎大家关注,转发,点赞。同时也欢迎大家来平台投稿,投稿请添加下方小助手微信。
QQ交流群:216912253
查看更多交流方式
微信公众号:AI算法后丹修炼炉
小助手ID:jintianandmerry
