Python数据结构与算法(3.2)——栈相关应用与习题
Python数据结构与算法(3.2)——栈相关应用与习题
-
- 0. 学习目标
- 1. 回文序列判断
- 2. 反转栈中元素
- 3. 最大跨度问题
- 4. 使用一个列表实现两个栈
- 5. 删除所有相邻的重复元素
- 相关链接
0. 学习目标
我们已经学习了栈的相关概念以及其实现,同时也了解了栈在实际问题中的广泛应用,本节的主要目的是通过栈的相关习题来进一步加深对栈的理解,同时能够利用栈降低一些复杂问题解决方案的时间复杂度。
1. 回文序列判断
[问题] 给定一字符串 string (如:abamaba),检查其是否为回文。
[思路] 由于 string 为字符串,因此最简单的方法是使用双索引法,其中一个索引位于字符串的开头,另一个位于字符串的末尾;每次比较两个索引处的值是否相同。如果值相同,则增加左索引、减少右索引,否则给定的字符串不是回文序列;持续上述过程,直到两个索引在中间相遇。
我们也可以利用栈来快速解决此问题,如下述[算法]所示。
[算法]
遍历字符串,将所有元素 push 到栈中
遍历字符串,将每个元素与栈顶元素进行比较
如果相同,则栈顶元素出栈并继续对比字符中的下一元素
如果不相同,则给定字符串并非回文,跳出循环
[代码]
def ispalindrome(string):
string_stack = Stack()
flag = True
for c in string:
string_stack.push(c)
for c in string:
if c != string_stack.pop():
flag = False
break
return flag
[时空复杂度] 时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( n ) O(n) O(n)。
2. 反转栈中元素
[问题] 给定一栈 stack,仅使用栈的操作反转栈中元素。
[思路] 由于栈的先进后出特性,可以构建新栈 new_stack,并将原来栈 stack 中的元素按出栈顺序压入 new_stack 中。
[算法]
实例化新栈 new_stack
如果栈 stack 非空:
栈顶元素出栈
出栈元素 push 进新栈 new_stack 中
[代码]
def reverse_stack(stack):
new_stack = Stack()
if not stack.isempty():
new_stack.push(stack.pop())
return new_stack
[时空复杂度] 时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( n ) O(n) O(n)。
3. 最大跨度问题
[问题3-1] 给定一列表 L,我们定义 L[i] 的跨度 S[i] 为紧邻 L[i]之前,并满足 L[j] <= L[i] 的连续元素个数,即 i - j。例如:
| i | L[i] | S[i] |
|---|---|---|
| 0 | 7 | 1 |
| 1 | 2 | 1 |
| 2 | 5 | 2 |
| 3 | 6 | 3 |
| 4 | 1 | 1 |
这一问题的一个常见实用场景通常为寻找峰值,例如查找低于当前股票价格的最大连续天数:
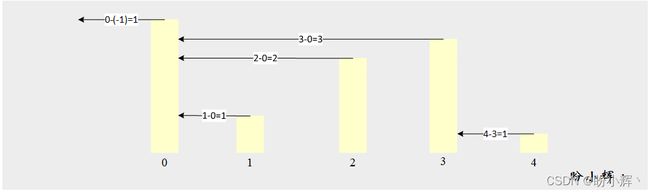
[思路3-1] 为了对此问题有一个清晰的认识,我们首先考虑采用遍历的方法,检查有多少连续元素值低于当前元素。
[代码3-1]
def finding_spans(L):
s = [None] * len(L)
for i in range(len(L)):
j = i - 1
while j >= 0 and L[i] > L[j]:
j -= 1
s[i] = i - j
return s
[时空复杂度3-1] 时间复杂度 O ( n 2 ) O(n^2) O(n2),空间复杂度 O ( 1 ) O(1) O(1)。
[问题3-2] 利用栈降低 [问题3-2] 的时间复杂度。
[思路3-2] 从 [算法3-1] 可以看出,如果我们知道了第 i 个元素前的第一个大于 L[i] 的元素索引,就可以很容易计算出第 i 天的跨度 S[i],假设该索引为 p,那么 S[i] = i - p,因此我们使用栈来保存大于当前元素的第一个元素的索引,初始时索引 p=-1。
[算法3-2]
实例化新栈 d,并初始化跨度列表 s
遍历列表 L:
如果栈 d 不为空,且当前元素大于栈顶元素:
d 出栈
否则:
p=栈顶元素值
计算 s[i],并将列表当前索引入栈
[代码3-2]
def finding_spans(L):
d = Stack()
s = [None] * len(L)
for i in range(len(L)):
# stack.peek()方法用于返回栈顶元素,并不出栈
while not d.isempty() and L[i] > L[d.peek()]:
d.pop()
if d.isempty():
p = -1
else:
p = d.peek()
s[i] = i - p
d.push(i)
return s
[时空复杂度3-2] 由于列表中的索引最多入栈 1 次,且最多出栈 1 次,虽然有内循环,但其总的执行次数为 n n n,因此算法的时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( n ) O(n) O(n)。
4. 使用一个列表实现两个栈
[问题] 仅使用一个定长列表实现两个栈,直到列表中没有空闲空间。
[思路] 一种可行的方法如下图所示:

[算法]
使用双索引,一个在列表左端,另一个在右端
使用左侧索引模拟第一个栈,右侧索引模拟第二个栈
第一个栈向右增长,第二个栈向左增长
[代码]
class TwoStack:
def __init__(self, size=10):
self.items = [None] * size
self.size = size
self.top_1 = -1
self.top_2 = size
def stack_1_push(self, data):
if self.top_2 - self.top_1 > 1:
self.top_1 += 1
self.items[self.top_1] = data
else:
raise("Stack Overflow!")
def stack_2_push(self, data):
if self.top_2 - self.top_1 > 1:
self.top_2 -= 1
self.items[self.top_2] = data
else:
raise("Stack Overflow!")
def stack_1_pop(self):
if self.top_1 < 0:
raise("Stack Underflow!")
else:
result = self.items[self.top_1]
self.top_1 -= 1
return result
def stack_2_pop(self):
if self.top_2 >= self.size:
raise("Stack Underflow!")
else:
result = self.items[self.top_2]
self.top_2 += 1
return result
[时空复杂度] 两个栈的 push 和 pop 操作的时间复杂度均为 O ( 1 ) O(1) O(1),空间复杂度为 O ( 1 ) O(1) O(1)。
5. 删除所有相邻的重复元素
[问题] 给定一字符串 string,从字符串中删除相邻的重复字符,使输出字符串中不包含相邻的重复项。如:输入字符串 cennection,输出为 tion。
[思路] 由于在 python 中字符串属于不可变序列,因此为了实现原地修改,首先将字符串 string 变为列表。然后直接将此列表作为栈,当栈顶的字符与当前字符不同时,将其添加到栈中;否则,跳过当前字符,直到该字符与栈顶不相同,然后从栈中移除该元素,最终栈中的元素即为所求结果。
[算法]
将字符串 string 变为序列,并初始化栈顶 ptr 和索引 i
遍历序列 string:
如果栈顶的字符与当前字符不同:
当前字符入栈
否则:
跳过当前字符,直到当前字符与栈顶不相同
栈顶元素出栈
[代码]
def remove_duplicates(string):
string = list(string)
ptr = -1
i = 0
size = len(string)
while i < size:
if ptr == -1 or string[ptr] != string[i]:
ptr += 1
string[ptr] = string[i]
i += 1
else:
while i < size and string[ptr] == string[i]:
i += 1
ptr -= 1
ptr += 1
string = ''.join(string[0:ptr])
return string
[时空复杂度] 时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( 1 ) O(1) O(1)。
相关链接
线性表基本概念
顺序表及其操作实现
单链表及其操作实现
栈及其实现