Python 玩转数据 - 数据读写 Data I/O: Pandas 读写 CSV 和 Excel XLSX
Python 进阶学习 玩转数据系列 之 数据读写 Data I/O: Pandas 读写 CSV 和 Excel XLSX
引言
本文主要介绍 Pandas 对 CSV, Excel 格式数据的读写。
内容提要:
XLS, CSV Data I/O Modules in Python
Pandas 对 CSV 格式数据的读写
Pandas 对 Excel 格式数据的读写
XLS, CSV Data I/O Modules in Python
| Module | Installation / Load / Methods | URL / Comment |
|---|---|---|
| openpyxl | import openpyxl | Anaconda’s module to work with xls files |
| xlsxwriter | import xlsxwriter | Anaconda’s module to create xls files |
| unicodecsv | import unicodecsv | Anaconda’s module to handle csv unicode strings |
| csv | pip install csv | |
| pandas | import pandas as pd pd.read_csv(), df.to_csv() pd.read_excel(), df.to_excel() | https://pandas.pydata.org/pandas-docs/stable/io.htm |
Pandas:
- Reading 读 into Pandas DataFrame:
ASCI: pd.read_csv()
Binary: pd.read_excel() - Writing 写 Pandas DataFrame:
ASCII: df.to_csv()
Binary: df.to_excel()
Pandas: Reading from and Writing to CSV File Format
pd.read_csv(): 
重要参数:
sep : str, default ‘,’
指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’
\s表示匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \f\n\r\t\v]
而"\s+"则表示匹配任意多个上面的字符
delimiter : str, default None
定界符,备选分隔符(如果指定该参数,则sep参数失效)
delim_whitespace : boolean, default False.
指定空格(例如’ ‘或者’ ‘)是否作为分隔符使用,等效于设定sep=’\s+’。如果这个参数设定为Ture那么delimiter 参数失效。
在新版本0.18.1支持
header : int or list of ints, default ‘infer’
指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0 就会替换掉原来存在列名。header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉。
注意:如果skip_blank_lines=True 那么header参数忽略注释行和空行,所以header=0表示第一行数据而不是文件的第一行。
names : array-like, default None
用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。默认列表中不能出现重复,除非设定参数mangle_dupe_cols=True。
index_col : int or sequence or False, default None
用作行索引的列编号或者列名,如果给定一个序列则有多个行索引。
如果文件不规则,行尾有分隔符,则可以设定index_col=False 来是的pandas不适用第一列作为行索引。
usecols : array-like, default None
返回一个数据子集,该列表中的值必须可以对应到文件中的位置(数字可以对应到指定的列)或者是字符传为文件中的列名。例如:usecols有效参数可能是 [0,1,2]或者是 [‘foo’, ‘bar’, ‘baz’]。使用这个参数可以加快加载速度并降低内存消耗。
converters : dict, default None
列转换函数的字典。key可以是列名或者列的序号。
skiprows : list-like or integer, default None
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
nrows : int, default None
需要读取的行数(从文件头开始算起)
举例
hrdatabase.txt 部分数据:

import pandas as pd
fname = "../Python_data_wrangling/Python_data_wrangling_data_raw/data_raw/hrdatabase.txt"
hr_db_df = pd.read_csv (fname, header = 0, sep = '\s+')
rows_roi = range(0,5)
cols_roi = [0, 1, 2, 5, 7]
part_of_hr_db_df = hr_db_df.iloc[rows_roi, cols_roi]
print("part_of_hr_db_df:\n{}".format(part_of_hr_db_df))
# write into CSV with comma-delimited items
output_file = "csv_hr_db.csv"
hr_db_df.to_csv(output_file, sep = ",")
输出:
part_of_hr_db_df:
EMPLOYEE_ID FIRST_NAME LAST_NAME HIRE_DATE SALARY
0 100 Steven King 20030617 24000.0
1 101 Neena Kochhar 20050921 17000.0
2 102 Lex DeHaan 20010113 17000.0
3 103 Alexander Hunold 20060103 9000.0
4 104 Bruce Ernst 20070521 6000.0
新生成的 csv_hr_db.csv 中的部分内容

Pandas: Reading from and Writing to Excel XLSX File Format
read_excel 函数签名:
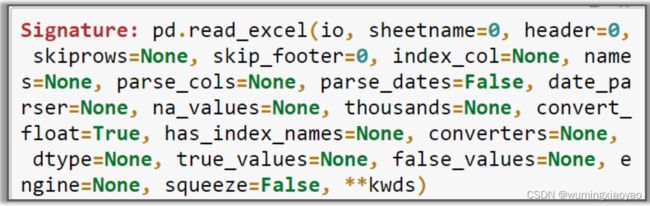
to_excel 函数签名:

举例:
weather.xlsx 有三个sheet

import pandas as pd
# Excel XLSX file with 3 sheets
# Examine the input file
ifname = "../Python_data_wrangling/Python_data_wrangling_data_raw/data_raw/weather.xlsx" # for input
# Read each sheet into a different DataFrame
temp_Mon = pd.read_excel(ifname, sheet_name='Monday', index_col=0)
temp_Tu = pd.read_excel(ifname, sheet_name='Tuesday', index_col=0)
humidity_Mon= pd.read_excel(ifname, sheet_name='Humidity', index_col=0)
# Merge different Excel sheets
merged_Mon = pd.concat([temp_Mon, humidity_Mon], axis=1)
merged_xlsx_df = pd.concat([merged_Mon, temp_Tu], keys=['Monday', 'Tuesday'])
print("temp_Mon:\n{}".format(temp_Mon))
print("temp_Tu:\n{}".format(temp_Tu))
print("humidity_Mon:\n{}".format(humidity_Mon))
print("merged_Mon:\n{}".format(merged_Mon))
print("merged_xlsx_df:\n{}".format(merged_xlsx_df))
# Write the data frame to the Excel XLSX file
ofname = "weather_write.xlsx"
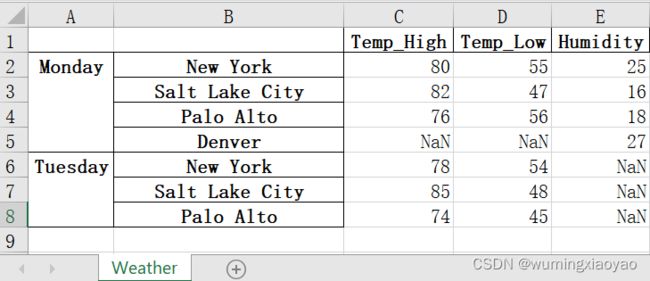
merged_xlsx_df.to_excel (ofname, sheet_name='Weather', na_rep='NaN')
输出:
temp_Mon:
Temp_High Temp_Low
New York 80 55
Salt Lake City 82 47
Palo Alto 76 56
temp_Tu:
Temp_High Temp_Low
New York 78 54
Salt Lake City 85 48
Palo Alto 74 45
humidity_Mon:
Humidity
New York 25
Salt Lake City 16
Palo Alto 18
Denver 27
merged_Mon:
Temp_High Temp_Low Humidity
New York 80.0 55.0 25
Salt Lake City 82.0 47.0 16
Palo Alto 76.0 56.0 18
Denver NaN NaN 27
merged_xlsx_df:
Temp_High Temp_Low Humidity
Monday New York 80.0 55.0 25.0
Salt Lake City 82.0 47.0 16.0
Palo Alto 76.0 56.0 18.0
Denver NaN NaN 27.0
Tuesday New York 78.0 54.0 NaN
Salt Lake City 85.0 48.0 NaN
Palo Alto 74.0 45.0 NaN
生成的 weather_write.xlsx 内容