ABAP 是一门企业级应用编程语言,其 740 版本于 2013 年发布,增添了许多新的语法和关键字:
其中一个亮点就是新引入的 REDUCE 关键字。这个关键字的作用和在大规模数据集并行计算领域里广泛使用的 Map-Reduce 编程模型中的 Reduce 操作类似,可以按照字面意思理解为归约 。
什么是 Map-Reduce 思想?
Map-Reduce 是一种编程模型和相关实现,用于在集群上使用并行分布式算法,生成和处理大规模数据集。
一个 Map-Reduce 程序由一个 Map 过程和一个 Reduce 方法组成。Map 过程负责执行过滤和排序,例如将学生按名字排序到队列中,每个名称由一个队列维护。
Reduce 方法负责执行汇总操作,例如计算学生的数量。
Map-Reduce 系统通过编排分布式服务器,来并行运行各种任务,管理系统各个部分之间的所有通信和数据传输,以及提供数据冗余,实现容错机制。
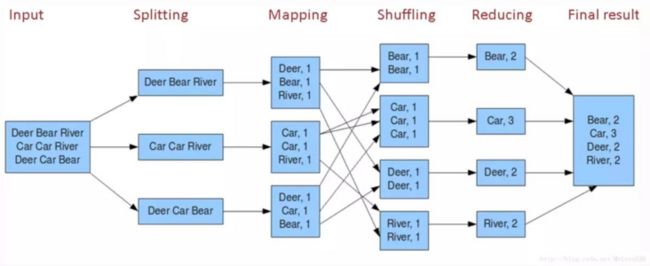
下图是 Map Reduce 框架的工作步骤,统计一个海量输入数据集(比如大于 1TB )中的单词出现次数。工作步骤包含 Splitting, Mapping, Shuffling, Reducing 以得到最后的输出结果。
Map-Reduce 编程模型已经广泛运用于大数据处理领域的工具和框架,比如 Hadoop 之中。
Map-Reduce 在 CRM 系统中的一个实际应用
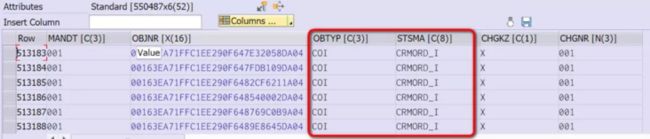
我们来看一个笔者工作中的实际任务。我需要在某个 CRM 测试系统上做个统计,列出在数据库表 CRM_JSTO 里,OBTYP(Object Type) 和 STSMA(Status Schema) 这两列拥有相同值的内表行的个数。大家可以把 OBTYP 和 STSMA 两列具有相同值的内表行 这个描述,类比成上图中重复出现的单词。
下图是系统中数据库表 CRM_JSTO 的部分行:
下图是笔者最终完成的统计结果:
测试系统上数据库表总的行数超过 55 万行,其中有 90279 行,只维护了 OBTYP 为TGP,而没有维护 STSMA.
排名第二的是 COH 和 CRMLEAD 的组合,出现了 78722 次。
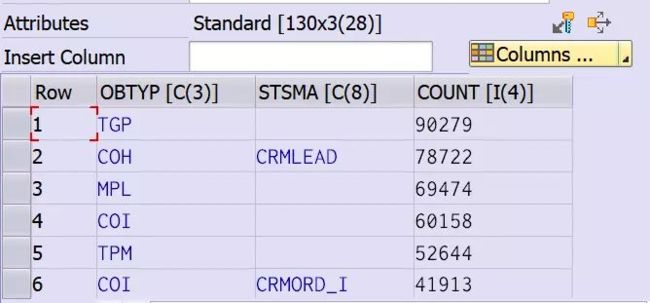
上图这个结果是怎么统计出来的呢?
稍稍做过一些 ABAP 开发的朋友们,一定会立即写出下面的代码:
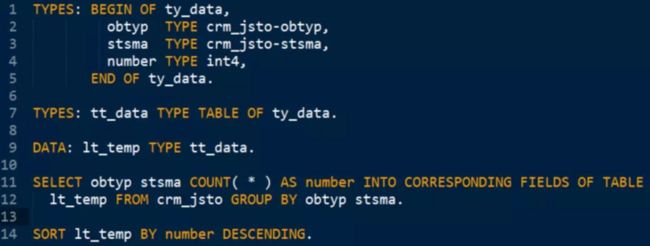
利用 SELECT COUNT 直接在数据库层完成统计工作。这也是 SAP 推荐的做法,即所谓 Code pusudown 准则,即能放到 HANA 数据库层面进行的操作,就尽量放进去,以充分利用 HANA 强大的计算能力。在数据库能够完成计算逻辑的前提下,尽量避免把计算逻辑放到 Netweaver ABAP 应用层去做。
不过,我们也需要注意到这种方式的局限性。SAP CTO 曾经有过一句名言:
There is no future with ABAP alone
There is no future in SAP without ABAP

未来的 ABAP 会走向开放,互联的道路。回到这个需求本身,假设待检索的输入数据不是从 ABAP 数据库表中来,而是来自 HTTP 请求,或者第三方系统发过来的 IDOC,此时我们无法再使用 OPEN SQL 本身的 SELECT COUNT 操作,而只能在 ABAP 应用层解决这个问题。
下面介绍两种用 ABAP 编程语言完成这一需求的解决方案。
第一种方式比较传统,实现在方法 get_result_traditional_way 里:
ABAP 的 LOOP AT GROUP BY 这个关键字组合简直就像是为这个需求量身定做一般:给 GROUP BY 指定 obtyp 和 stsma 这两列,然后 LOOP AT 会自动将输入内表的行记录根据这两列的值进行分组,每组行记录的个数通过关键字 GROUP SIZE 自动计算出来,每组各自的 obtyp 和 stsma 的值,以及组内行记录的条目数,存储在 REFERENCE INTO 指定的变量 group_ref 里。ABAP 开发人员需要做的事情,只是简单地把这些结果存储到输出内表即可。

第二种办法,就是本文标题所述,使用 ABAP 740 新引入的 REDUCE 关键字:
REPORT zreduce1.
DATA: lt_status TYPE TABLE OF crm_jsto.
SELECT * INTO TABLE lt_status FROM crm_jsto.
DATA(lo_tool) = NEW zcl_status_calc_tool( ).
lo_tool = REDUCE #( INIT o = lo_tool
local_item = VALUE zcl_status_calc_tool=>ty_status_result( )
FOR GROUPS OF IN lt_status
GROUP BY ( obtyp = -obtyp stsma = -stsma )
ASCENDING NEXT local_item = VALUE #( obtyp = -obtyp
stsma = -stsma
count = REDUCE i( INIT sum = 0 FOR m IN GROUP
NEXT sum = sum + 1 ) )
o = o->add_result( local_item ) ).
DATA(ls_result) = lo_tool->get_result( ). 上面的代码乍一看可能觉得有点晦涩,但仔细阅读后发现这种方式本质上也采用了和方法一 LOOP AT GROUP BY 同样的分组策略——根据 obtyp 和 stsma 分组,这些子组通过变量 group_key标识,然后通过第 10 行的 REDUCE 关键字,通过累加的方式,手动计算这个组的条目数——把一个大的输入集根据 GROUP BY 指定的条件归约成一个个规模更小的子集,然后分别针对子集进行计算——这就是 REDUCE 关键字通过字面含义传递给 ABAP 开发人员的处理思想。
总结和比较一下这三种实现方式:当待统计的数据源为 ABAP 数据库表时,一定优先选用 OPEN SQL 的方式,使计算逻辑在数据库层完成,以获得最佳的性能。
当数据源并非 ABAP 数据库表,而分组统计的需求为简单的计数操作(COUNT)时, 优先用LOOP AT ... GROUP BY ... GROUP SIZE,使得计数操作通过 GROUP SIZE 在ABAP kernel 完成,以获得较好的性能。
当数据源并非 ABAP 数据库表,而分组统计的需求为自定义的逻辑时,用本文介绍的第三种 REDUCE 解法,将自定义统计逻辑写在第 11 行的 NEXT 关键字后。
三种解法的性能评测
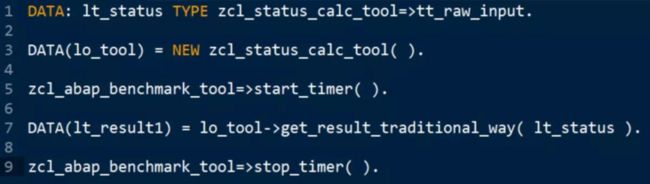
我编写了一个简单的报表进行性能评测:
DATA: lt_status TYPE zcl_status_calc_tool=>tt_raw_input.
SELECT * INTO TABLE lt_status FROM crm_jsto.
DATA(lo_tool) = NEW zcl_status_calc_tool( ).
zcl_abap_benchmark_tool=>start_timer( ).
DATA(lt_result1) = lo_tool->get_result_traditional_way( lt_status ).
zcl_abap_benchmark_tool=>stop_timer( ).
zcl_abap_benchmark_tool=>start_timer( ).
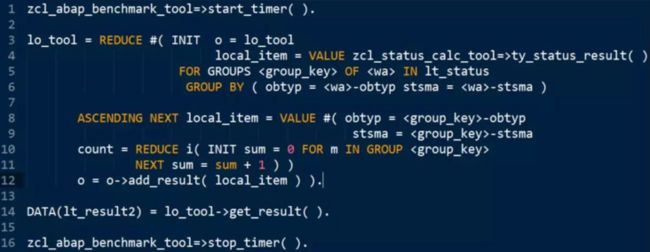
lo_tool = REDUCE #( INIT o = lo_tool
local_item = VALUE zcl_status_calc_tool=>ty_status_result( )
FOR GROUPS OF IN lt_status
GROUP BY ( obtyp = -obtyp stsma = -stsma )
ASCENDING NEXT local_item = VALUE #( obtyp = -obtyp
stsma = -stsma
count = REDUCE i( INIT sum = 0 FOR m IN GROUP
NEXT sum = sum + 1 ) )
o = o->add_result( local_item ) ).
DATA(lt_result2) = lo_tool->get_result( ).
zcl_abap_benchmark_tool=>stop_timer( ).
ASSERT lt_result1 = lt_result2. 测试数据如下:

这三种解法的性能依次递减,不过适用的场合和灵活程度依次递增。
LOOP AT ... GROUP BY ... GROUP SIZE 这种解决方案,在笔者工作的 ABAP 测试服务器上,处理 55 万条记录,用了 0.3 秒,而 REDUCE 则需花费 0.8 秒, 两种解法的性能处于同一数量级之内。
总结
Map-Reduce 是一种编程模型和相关实现,用于在集群上使用并行分布式算法,生成和处理大规模数据集。ABAP 编程语言从语言层面支持对大规模数据的 REDUCE 操作。本文分享了笔者工作中使用 Map-Reduce 思路处理大规模数据集的一个实际案例,并与传统的另外两种解决方案做了比较。在性能不逊于传统解决方案的前提下,基于 Map-Reduce 的解决方案,具有更为广泛的应用场合和可扩展性。希望本文分享的内容对大家使用 ABAP 处理类似问题时有所启发,感谢阅读。
