深度学习框架tensorflow二实战(回归问题:天气预报)
此前没了解过tensorflow2的魅力的朋友可以先了解一下该网站:Click
首先准备一个小型数据集,2019年的某个地方的天气情况,各位同学也可以自行伪造一份符合正态分布的数据集。
这里提供了一份下载的链接。点击直通temp.csv。
废话不多说,直接加载我们的数据集看一下。Click:为某地方一年的温度
读取数据展示:
features = pd.read_csv('temps.csv')
print(features.head())#显示读取的文件的前面几行,默认是前五行
print('数据维度:', features.shape)
输出结果:
362行,小型数据集,可以在CPU或者GPU版本都可以运行
数据表中
year,moth,day,week分别表示的具体的时间
temp_2:前天的最高温度值
temp_1:昨天的最高温度值
average:在历史中,每年这一天的平均最高温度值
actual:这就是我们的标签值了,当天的真实最高温度
random:这一列是凑热闹的,随机猜测的值
year month day week temp_2 temp_1 average actual random
0 2019 1 1 Fri 5.0 5.3 5.6 5 -15
1 2019 1 2 Sat 4.4 5.2 5.7 4 -16
2 2019 1 3 Sun 5.0 4.0 5.8 1 -15
3 2019 1 4 Mon 4.0 1.0 5.9 0 -16
4 2019 1 5 Tues 1.0 0.0 6.0 4 -19
数据维度: (362, 9)
处理时间数据:
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
#print(dates)
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
print(dates)
输出结果:
[datetime.datetime(2019, 1, 1, 0, 0), datetime.datetime(2019, 1, 2, 0, 0), datetime.datetime(2019, 1, 3, 0, 0), datetime.datetime(2019, 1, 4, 0, 0), datetime.datetime(2019, 1, 5, 0, 0), datetime.datetime(2019, 1, 6, 0, 0), dat...省略了
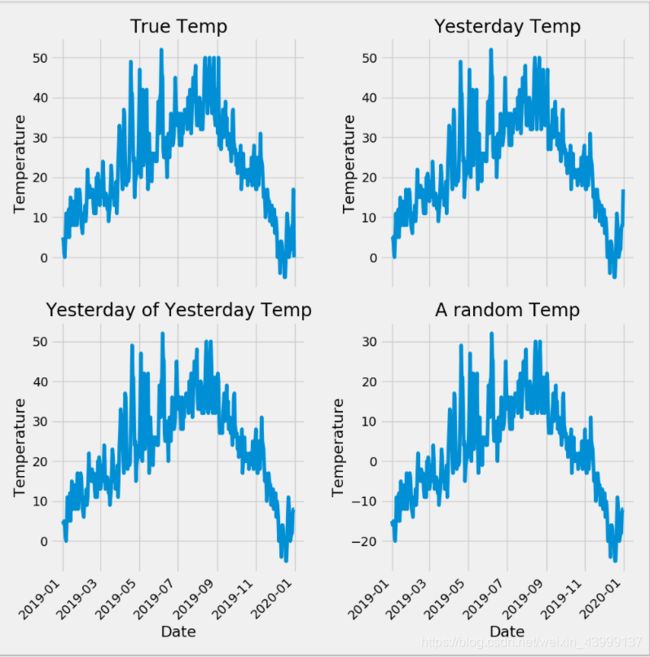
展示温度图像:
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)#设置x坐标的标志为四十五度
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('True Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Yesterday Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Yesterday of Yesterday Temp')
# 一个随机预测的温度
ax4.plot(dates, features['random'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('A random Temp')
plt.tight_layout(pad=2)#自动紧凑布局
plt.show()
输出结果:
数据预处理
第一步首先是把星期几使用onehot编码进行量化
第二步把features的真实标签保存为labels
第三步把输入的真实值以及随机预测值都给剔除
第四步则是对输入数据进行预处理,无量纲化
print(features.head().shape)
# 独热编码
features = pd.get_dummies(features) #one-hot编码,对不是数字的会进行one-hot编码
print(features.head(1).shape)
# 标签,真实的温度
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
features= features.drop('random', axis = 1)
#print(features.columns)
# 保存标头,即每列数据对应的含义保存一下
feature_list = list(features.columns)#
# 转换成合适的格式,只保留数据了
features = np.array(features)
print(features)
print(features.shape)
#preprocessing 为预处理库,里面封装了很多预处理操作
#无量纲化:
#标准化:(x-列均值)/ 列标准差
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
#print(input_features)
#print(input_features.shape)
数据预处理完,接下来就是Tensorflow2的新展示了,使用keras的API
#模型堆叠
model = tf.keras.Sequential()
model.add(layers.Dense(16)) #全连接层,16个神经元
model.add(layers.Dense(32)) #全连接层,32个神经元
model.add(layers.Dense(1)) #全连接层,输出层
#compile相当于对网络进行配置,指定好优化器和损失函数等
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),
loss='mean_squared_error')
model.fit(input_features, labels, validation_split=0.15, epochs=10, batch_size=64)#validation_split指的是验证集比例
model.summary()
输出结果
可以看到训练集已经基本收敛,但测试集的损失值还是比较大的。
Train on 271 samples, validate on 91 samples
Epoch 1/10
271/271 [==============================] - 0s 2ms/sample - loss: 821.1113 - val_loss: 285.1090
Epoch 2/10
271/271 [==============================] - 0s 48us/sample - loss: 677.4314 - val_loss: 356.1234
Epoch 3/10
271/271 [==============================] - 0s 43us/sample - loss: 375.2623 - val_loss: 632.0933
Epoch 4/10
271/271 [==============================] - 0s 44us/sample - loss: 108.9708 - val_loss: 691.7151
Epoch 5/10
271/271 [==============================] - 0s 44us/sample - loss: 50.2127 - val_loss: 598.7165
Epoch 6/10
271/271 [==============================] - 0s 79us/sample - loss: 40.9568 - val_loss: 514.2609
Epoch 7/10
271/271 [==============================] - 0s 72us/sample - loss: 36.6869 - val_loss: 454.2624
Epoch 8/10
271/271 [==============================] - 0s 65us/sample - loss: 34.8708 - val_loss: 472.3111
Epoch 9/10
271/271 [==============================] - 0s 49us/sample - loss: 33.7877 - val_loss: 409.8574
Epoch 10/10
271/271 [==============================] - 0s 49us/sample - loss: 32.2860 - val_loss: 347.9267
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 224
_________________________________________________________________
dense_1 (Dense) multiple 544
_________________________________________________________________
dense_2 (Dense) multiple 33
=================================================================
Total params: 801
Trainable params: 801
Non-trainable params: 0
_________________________________________________________________
解决办法:
非常非常多,我们可以把迭代次数调到30次,就可以完美收敛了。
Train on 271 samples, validate on 91 samples
Epoch 1/30
271/271 [==============================] - 1s 2ms/sample - loss: 814.3073 - val_loss: 247.3884
Epoch 2/30
271/271 [==============================] - 0s 47us/sample - loss: 677.9860 - val_loss: 229.9150
Epoch 3/30
271/271 [==============================] - 0s 43us/sample - loss: 416.3268 - val_loss: 267.2840
Epoch 4/30
271/271 [==============================] - 0s 43us/sample - loss: 158.0090 - val_loss: 227.4088
Epoch 5/30
271/271 [==============================] - 0s 43us/sample - loss: 56.7685 - val_loss: 196.2745
Epoch 6/30
271/271 [==============================] - 0s 43us/sample - loss: 35.3764 - val_loss: 169.8626
Epoch 7/30
271/271 [==============================] - 0s 43us/sample - loss: 31.4925 - val_loss: 150.9355
Epoch 8/30
271/271 [==============================] - 0s 42us/sample - loss: 29.9851 - val_loss: 139.6017
Epoch 9/30
271/271 [==============================] - 0s 43us/sample - loss: 29.0805 - val_loss: 136.3649
Epoch 10/30
271/271 [==============================] - 0s 42us/sample - loss: 29.9907 - val_loss: 112.3794
Epoch 11/30
271/271 [==============================] - 0s 42us/sample - loss: 28.2350 - val_loss: 102.6311
Epoch 12/30
271/271 [==============================] - 0s 43us/sample - loss: 29.1364 - val_loss: 107.4938
Epoch 13/30
271/271 [==============================] - 0s 43us/sample - loss: 27.1924 - val_loss: 100.6108
Epoch 14/30
271/271 [==============================] - 0s 43us/sample - loss: 26.5309 - val_loss: 96.0920
Epoch 15/30
271/271 [==============================] - 0s 63us/sample - loss: 26.0549 - val_loss: 88.7254
Epoch 16/30
271/271 [==============================] - 0s 69us/sample - loss: 25.7222 - val_loss: 84.9858
Epoch 17/30
271/271 [==============================] - 0s 72us/sample - loss: 25.2887 - val_loss: 82.5212
Epoch 18/30
271/271 [==============================] - 0s 87us/sample - loss: 25.0895 - val_loss: 80.9025
Epoch 19/30
271/271 [==============================] - 0s 75us/sample - loss: 25.6907 - val_loss: 75.7480
Epoch 20/30
271/271 [==============================] - 0s 80us/sample - loss: 25.4387 - val_loss: 74.5455
Epoch 21/30
271/271 [==============================] - 0s 56us/sample - loss: 24.7823 - val_loss: 69.4842
Epoch 22/30
271/271 [==============================] - 0s 50us/sample - loss: 24.4951 - val_loss: 66.2443
Epoch 23/30
271/271 [==============================] - 0s 50us/sample - loss: 24.9533 - val_loss: 64.3459
Epoch 24/30
271/271 [==============================] - 0s 47us/sample - loss: 24.7001 - val_loss: 62.5857
Epoch 25/30
271/271 [==============================] - 0s 45us/sample - loss: 24.9280 - val_loss: 55.9608
Epoch 26/30
271/271 [==============================] - 0s 43us/sample - loss: 24.1338 - val_loss: 60.5551
Epoch 27/30
271/271 [==============================] - 0s 57us/sample - loss: 24.5145 - val_loss: 57.6269
Epoch 28/30
271/271 [==============================] - 0s 55us/sample - loss: 24.2341 - val_loss: 52.8076
Epoch 29/30
271/271 [==============================] - 0s 72us/sample - loss: 23.7565 - val_loss: 48.5504
Epoch 30/30
271/271 [==============================] - 0s 90us/sample - loss: 23.8610 - val_loss: 50.4723
一些别的解决思路:
"""
#更改初始化方法
model.add(layers.Dense(16,kernel_initializer='random_normal'))
model.add(layers.Dense(32,kernel_initializer='random_normal'))
model.add(layers.Dense(1,kernel_initializer='random_normal'))
#加入正则化惩罚项
model.add(layers.Dense(16,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(32,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(1,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
"""
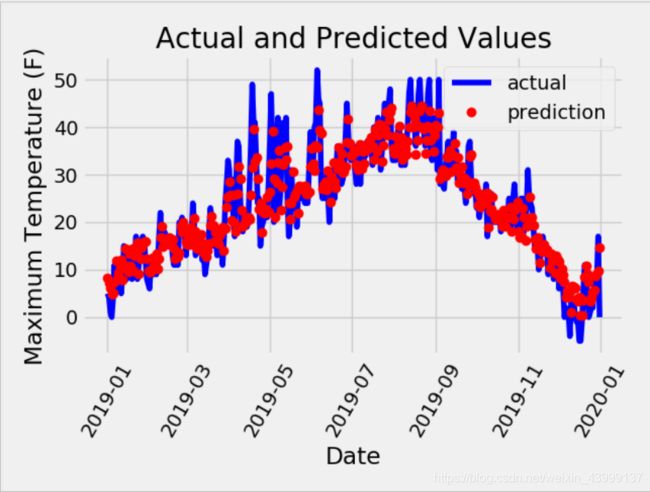
预测值与真实值展示:
predict = model.predict(input_features) #把输入传进去,得到我们的预测结果
print(predict.shape)
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60')
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values')
plt.show()
输出结果:
完整代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras.layers as layers
import tensorflow.keras
import warnings
warnings.filterwarnings("ignore")
# 处理时间数据
import datetime
features = pd.read_csv('temps.csv')
print(features.head())#显示读取的文件的前面几行,默认是前五行
print('数据维度:', features.shape)
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
#print(dates)
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
print(dates)
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)#设置x坐标的标志为四十五度
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('True Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Yesterday Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Yesterday of Yesterday Temp')
# 一个随机预测的温度
ax4.plot(dates, features['random'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('A random Temp')
plt.tight_layout(pad=2)#自动紧凑布局
plt.show()
print(features.head().shape)
# 独热编码
features = pd.get_dummies(features) #one-hot编码,对不是数字的会进行one-hot编码
print(features.head(1).shape)
# 标签,真实的温度
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
features= features.drop('random', axis = 1)
#print(features.columns)
# 保存标头,即每列数据对应的含义保存一下
feature_list = list(features.columns)#
# 转换成合适的格式,只保留数据了
features = np.array(features)
print(features)
print(features.shape)
#preprocessing 为预处理库,里面封装了很多预处理操作
#无量纲化:
#标准化:(x-列均值)/ 列标准差
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
#print(input_features)
#print(input_features.shape)
#数据预处理完,接下来就是Tensorflow2的新展示了,使用keras的API
#模型堆叠
model = tf.keras.Sequential()
model.add(layers.Dense(16)) #全连接层,16个神经元
model.add(layers.Dense(32)) #全连接层,32个神经元
model.add(layers.Dense(1)) #全连接层,输出层
"""
#更改初始化方法
model.add(layers.Dense(16,kernel_initializer='random_normal'))
model.add(layers.Dense(32,kernel_initializer='random_normal'))
model.add(layers.Dense(1,kernel_initializer='random_normal'))
#加入正则化惩罚项
model.add(layers.Dense(16,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(32,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(1,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.03)))
"""
#compile相当于对网络进行配置,指定好优化器和损失函数等
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),
loss='mean_squared_error')
model.fit(input_features, labels, validation_split=0.15, epochs=30, batch_size=64)#validation_split指的是验证集比例
model.summary()#展示网络层参数
predict = model.predict(input_features) #把输入传进去,得到我们的预测结果
print(predict.shape)
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60')
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values')
plt.show()
Over~~~~~~~~