文件操作
我们可以使用python来操作文件,比如读取文件内容、写入新的内容等,因为任何计算机文件的本质都是一些有不同后缀的字符组成的。
python文件操作的两种模式
打开模式
- while,写入模式,简写为 w ,指定的文件不存在则创建文件,存在则打开并清空内容,并且将文件指针(光标)放在文件的开头。
- read,读取模式,简写为 r ,文件不存在则报错,存在则打开文件,并且将文件指针放在文件的开头。
- append,追加模式,简写为 a ,文件不存在则创建文件,存在则打开文件,并且将指针放在文件末尾。
- xor,异或模式,简写为 x ,文件存在则报错,不存在则创建文件,将文件指针放在文件的开头。
扩展模式
扩展模式是用来配合打开模式的辅助模式,扩展模式单独不能使用。
- plus,增强模式,简写为 + ,可以让打开模同时具有读写功能。
- bytes,bytes模式,简写为 b ,将文件按照二进制字节流编码进行读写。
因此我们根据这两种大的模式可以组合成为16种操作文件的方法。
| 模式 | 作用 | 模式 | 作用 |
|---|---|---|---|
| w | 写入模式,只可写,不可读。 | a | 追加模式,只可写,不可读。 |
| w+ | 写入模式,可写可读。 | a+ | 追加模式,可写可读。 |
| wb | 写入模式,按照二进制字节流编码可写不可读 | ab | 追加模式,按照二进制字节流可写不可读 |
| wb+ | 写入模式,按照二进制字节流编码可写可读 | ab+ | 追加模式,按照二进制字节流可写可读。 |
| r | 读取模式,只可读,不可写。(默认模式) | x | 异或模式,只可写,不可读。 |
| r+ | 读取模式,可写可读。 | x+ | 异或模式,可写可读。 |
| rb | 读取模式,按照二进制字节流编码可读不可写。 | xb | 异或模式,二进制字节流可写不可读。 |
| rb+ | 读取模式,按照二进制字节流编码可读可写。 | xb+ | 异或模式,二进制字节流可写可读。 |
异或模式和写入模式的区别在于,异或模式如果打开的文件在指定的路径中如果存在,就会报错;而写入模式是直接打开不会报错,但是会将源文件中的所有内容清空。因为写入模式和读取模式之间的互相配合,异或模式的使用频率越来越少,正在逐步淘汰当中。
编码格式的了解
编码是信息从一种形式或格式转换为另一种形式的过程,就是用预先规定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号。这样做的目的是为了简化信息之间的传递。但是为保证编码的正确性,编码要规范化、标准化,即需有标准的编码格式。常见的编码格式有ASCII、ANSI、GBK、GB2312、Unicode、UTF-8等。
所有的编码格式,都是将字符转换成对应的二进制格式。将西方的字母文字和数字按照一个字节的方式存储,而将亚洲中中、日、朝等文字按照多字节存储。这是因为西方的字母语言,字母的数量远少于东方的文字数量,因此编程工作中一般更加的倾向与尽量多的使用英文的原因,因为相对的来说使用汉字等字符较少的程序可以占据更少的系统资源。
常用的编码格式
英文原始编码:ASCII码
ACSII编码只有128个字符,26个英文字母的大小写之外,还有一些常用的符号,还有一些不可或缺的系统控制字符等。ACSII编码中没有除了英文字母之外的其它语言字符。
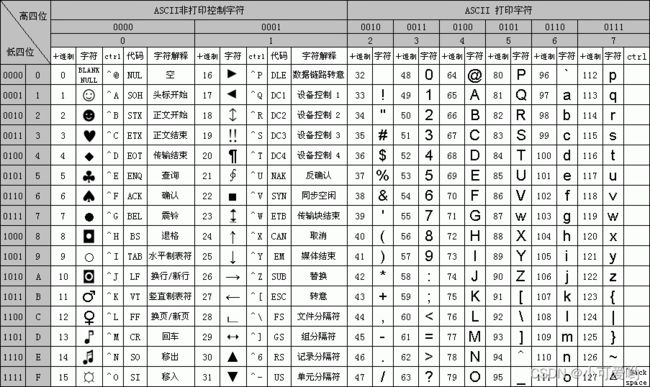
中文国家标准编码:GB系列编码
凡是由GB开头的编码集都是属于中国国家的标准编码字符集,只是不同的版本而已,使用这个编码的汉字占用的系统资源最少,中文使用2个字节的存储空间。比如GB2312。
万国码:Unicode编码
Unicode编码包含世界上所有的文字,无论什么字符都以4个字节进行存储。这是Unicode编码的缺点,虽然拥有世界上最齐全的字符,但是占用的系统资源很大,所以很少使用。
因此在这个基础之上改进,创建了可变长的Unicode编码集,UTF系列。这是目前世界上最主流的编码字符集,在这个编码集当中,不用担心任何字符会乱码,字母文字和数字使用一个字节的存储空间,中文等字符使用三个字节的存储空间,大大节省了空间的占用。比如UTF-8。
open函数的使用
python中操作文件要使用到open函数,open函数的作用是用于打开一个文件,创建一个file对象,使用相关的方法调用它对文件进行读写操作。
语法:open(file, mode=None, encoding=None)
参数说明:
- file:文件的位置和名称
- mode:操作的模式,使用简写,就是我们上述的16中操作方式
- encoding:指定编码类型,比如UTF-8、GB2312、ACSII等
open函数指定这些信息之后,返回一个TextIOWrapper对象,使用这个对象,我们可以按照指定的操作模式和编码格式来操作我们指定的文件。
文件的写入(写入模式)
现在我们在使用open函数创建一个文件,并写入内容。
可以看到我们当前的目录当中只有一个main.py文件,我们现在写入代码。
# 指定文件的位置,要使用字符串,可以使用绝对路径和相对路径
# 操作模式的选择,我们要创建一个新的文件并写入内容,使用 w
# 指定编码格式为UTF-8,这是最常使用的编码格式
# fp就是文件的IO对象,问价句柄,用来操作文件
# i --- > input 输入
# o --- > output 输出
fp = open('test.txt', 'w', encoding='UTF-8')
# 使用write函数写入内容
fp.write('Hello motherland')
# 使用close函数关闭文件
fp.close()
执行python代码之后,我们发现在原来的目录下面多出了一个名为test.txt的文件。
打开这个文件我们就会发现,文件中的内容就是我们写下的内容。

现在我们重新使用 w 模式打开这个文件,但是不操作任何东西,让我们看看结果如何。
fp = open('test.txt', 'w', encoding='UTF-8')
fp.close()

没错,这个文件中的内容被清空了,这就是w模式的如果文件存在,就打开文件并清空。
文件的读取(读取模式)
我们现在执行下面的代码,使用 r 模式读取文件中的内容。
# 使用 r 模式打开msr.txt文件
fp = open('msr.txt', 'r', encoding='UTF-8')
# 读取文件中的内容
res = fp.read()
print(res)
# 关闭文件
fp.close()
发现程序报错了,这是为什么?因为使用 r 模式如果指定的文件不存在就会报错。
那我们先创建一个msr.txt文件在重新读取一下。
# 先创建一个msr.txt文件
fp = open('msr.txt', 'w', encoding='UTF-8')
# 写入内容
fp.write('刘德华太帅了。')
# 关闭文件
fp.close()
# 然后重新读取这个文件
fp = open('msr.txt', 'r', encoding='UTF-8')
# 读取文件中的内容
res = fp.read()
# 打印读取的内容
print(res) # 刘德华太帅了。
# 关闭文件
fp.close()
不再报错了,而且也成功的打印出来文件中的内容。
文件内容追加(追加模式)
追加模式如果文件不存在就创建文件,反之就打开文件,但是可写入模式的不同之处就在于,追加模式打开文件不会清空文件中的原有的数据内容。
打开msr.txt文件,我们看到只有一行文字。

现在我们执行下面的代码
# 使用追加模式打开文件
fp = open('msr.txt', 'a', encoding='UTF-8')
# 在文件中写入内容
fp.write('但是刘德华没有博主帅。')
# 关闭文件
fp.close()
打开文件我们看到,原有的数据并没有被清空掉,并且写入了新的内容。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-monzJF4R-1647692650673)(
)]
字节流的转换
bytes是用来传输或者是存储的数据格式,如果是在文件的操作过程中按照bytes的模式操作的话,就需要将数据格式转换成为bytes流才可以。
二进制的字节流就是底层的代码。
使用 b 前缀
在字符串之前加上字符 b 代表是二进制的字节流,但是范围只是ASCII编码,也就是说这样并不支持中文。
# 在字符串之前加上 b 前缀
bytechar = b'hello motherland'
print(bytechar) # b'hello motherland'
# 该字符串的数据类型就变成了bytes流
print(type(bytechar)) #
bytechar = b'你好祖国' # error,只能将ACSII编码中的字符变成bytes流
使用函数
使用encode函数和decode函数可以将字符串在普通字符串和字节流的形式中来回的转换,而且可以将所有的字符变成bytes字节流,因为默认使用UTF-8编码,当然你也可以指定转换的编码格式。
| 函数 | 作用 |
|---|---|
| encode | 将字符串转换为二进制的字节流 |
| decode | 将二进制的字节流转换为字符串 |
语法:
string.encode(encoding='UTF-8')
bytes.decode(encoing='UTF-8')
var = '我的祖国'
# 将字符串变成字节流,默认使用UTF-8编码
res = var.encode()
print(res) # b'\xe6\x88\x91\xe7\x9a\x84\xe7\xa5\x96\xe5\x9b\xbd'
print(type(res)) #
# 指定编码格式UTF-8
res = var.encode(encoding='UTF-8')
print(res) # b'\xe6\x88\x91\xe7\x9a\x84\xe7\xa5\x96\xe5\x9b\xbd'
# 可以看到指定为UTF-8编码的和默认的结果是一样的
# 指定编码格式为ASCII
res = var.encode('ASCII') # error
# 因为原字符串是中文,所以不能使用ASCII编码
# 指定为GBK编码
res = var.encode('GBK')
print(res) # b'\xce\xd2\xb5\xc4\xd7\xe6\xb9\xfa'
# 可以看到GBK的编码中文可以节省更多的空间
# 可以使用 len 函数检测字节流的长度
print(len(res)) # 8
# 解码
var = res.decode() # error
# 应为默认使用的UTF-8解码,但是res的编码格式是GBK,所以失败
# 只能使用对应的编码格式解码
var = res.decode('GBK')
print(var) # 我的祖国
存储二进制的字节流
如果在操作文件的时候要使用字节流的方式,在使用open函数选择模式的时候要加上 b ,表示进行字节流的操作,然后open函数就不能在指定编码格式了,因为现在的操作的都是字节流,然而字节流本身就已经是指定的编码格式编码过了。
# 如果指定了字节流模式还要指定encoding参数就会报错
fp = open('test.txt', 'wb', encoding='UTF-8') # error
# 使用字节流模式只能进行字节流的写入
fp = open('test.txt', 'wb')
# fp.write('hello motherland') # error,不能直接使用字符串
fp.write(b'hello motherland')
fp.write('我的祖国'.encode())
fp.close()
写在文件中的内容还是原来的样子,不是字节流的形式
注意事项:
- 使用字节流模式编辑过的文件只能使用字节流模式去操作
- 使用什么格式的字节流写入文件的内容,读取的时候只能使用对应的编码格式去解码
- 任何文件都可以使用字节流模式去读取内容,读取的内容是字节流,如果这个文件是按照某个编码格式写入的,解码需要使用对应的编码格式;如果这个文件的内容不是使用字节流模式写入,读取的字节流默认是UTF-8格式的。
上下文管理器
在python中,有一些任务是当你开启之后,结束的时候需要专门的关闭任务,比如文件操作,在结束操作的使用需要使用close()函数专门的关闭文件、结束任务,这样就很繁琐,所以python中推出了 with …… as ……的语法,在 with 代码块中如果结束操作,不需要在专门的结束任务。
上下文管理器,任何需要进行上下文操作的对象,都可以使用此语法。
语法:with 任务 as 操作句柄:
# 不需要在使用close()函数专门的关闭文件,结束任务了
with open('test.txt', 'wb') as fp:
fp.write(b'hello motherland')
刷新缓冲区
我们学习了这么久,每次都一定要关闭文件、结束任务,这样做的意义是什么?
比较直观的目的就是为了保存文件,但是好奇的我们早就测试了不使用close()关闭文件,写入的内容一样是保存了文件中的,这是怎么回事?
看下面的代码,发现我们文件中依然是保存了我们写入的内容。
fp = open('test.txt', 'w', encoding='UTF-8')
fp.write('我和我的祖国,就像是海和浪花一朵。')
这是因为,关闭文件的根本目的是为了刷新缓冲区,然而刷新缓冲区的方法不止一种。
- 当文件关闭的时候自动刷新缓冲区
- 当整个程序运行结束的时候自动刷新缓冲区
- 当缓冲区写满还自动刷新缓冲区
- 手动刷新缓冲区
刷新缓冲区的意义在于最后的保存文件,就好像在使用文档编辑器的时候,虽然写满内容,但最后不点击保存按钮内容也不会保存下来。
而我们上面的例子就是因为程序运行结束的时候自动刷新了缓冲区,所以才保存了写入文件的内容,而close的作用就是关闭文件,关闭文件也可以刷新缓冲区,所以这就是每次要关闭文件的原因所在,为了防止自动刷新的失败。
那么什么情况之下程序就没有办法执行完呢?
比如说程序的意外中断、或者是死循环,下面的代码中就是因为死循环的原因导致程序没有办法执行完成,而没有保存新写入的内容。
下面的代码,先是写入了内容,然后就是一个死循环,这样程序永远都不会执行完成,就不能自动的刷新缓冲区,如果程序意外中断,内容也不会写入文件当中,你可以将程序运行起来之后,强制中断测试一下,会发现是一个空文件。
with open('test.txt', 'w', encoding='UTF-8') as fp:
fp.write('我和我的祖国,一刻也不能分割。')
while True:
pass
手动刷新
上面的例子中,文件没有办法关闭,程序没有办法执行完成,貌似缓冲区也很难写满,难道我们的内容就没有办法保存了吗?
你机智的写上了一行代码,是close()函数,这样就关闭了文件,就可以将死循环之前的内容保存了嘛。
with open('test.txt', 'w', encoding='UTF-8') as fp:
fp.write('我和我的祖国,一刻也不能分割。')
fp.close() # 关闭文件
while True:
pass
你经过测试,上面的代码的确的保存了写入的内容,但是我们关闭了文件,再次操作文件的时候就必须重新开启文件,不然没有办法继续操作。
with open('test.txt', 'w', encoding='UTF-8') as fp:
fp.write('我和我的祖国,一刻也不能分割。')
fp.close()
fp.write('我和我的祖国,就像是海和浪花一朵。') # error,文件已经关闭
while True:
pass
发现写入的第二条内容根本就没法执行了,怎么办?使用fiush()函数手动刷新缓冲区。
with open('test.txt', 'w', encoding='UTF-8') as fp:
fp.write('我和我的祖国,一刻也不能分割。')
fp.flush()
fp.write('我和我的祖国,就像是海和浪花一朵。')
fp.flush()
while True:
pass
发现手动刷新将内容保存了下来,而且没有影响程序的执行。以后如果程序任务过大,没有执行完成就意外中断,这样就有一点数据保存不下来的风险,我们就可以隔着一段任务手动刷新一下,就不至于将所有的数据全部丢失。
文件的扩展模式
我们经过上面的学习,用到了写、读、手动刷新、关闭文件等几种操作文件的函数,但是除此之外,还有一些常用的相关函数。
| 函数 | 作用 |
|---|---|
| write | 写入数据 |
| read | 读取数据 |
| fiush | 手动刷新缓冲区 |
| close | 关闭文件 |
| seek | 调整指针(光标)的位置 |
| tell | 返回当前指针左侧所有的字节数 |
| readable | 判断文件对象是否可读 |
| writeable | 判断文件对象是否可写 |
| readline | 读取文件的一行内容 |
| readlines | 将文件中的内容按照换行读取到列表当中 |
| writelines | 将内容是字符串的可迭代数据写入文件当中 |
| truncate | 把要截取的字符串提取出来,然后清空内容并将截取的内容重新写入 |
read的使用
plus增强模式的使用
在open函数中,使用 + 号,进入增强模式,可读可写。
我们现在使用 r+ 模式打开之前的文件,读取其中的内容。
with open('test.txt', 'r+', encoding='UTF_8') as fp:
# 读取内容
res = fp.read()
print(res) # 我和我的祖国,一刻也不能分割。我和我的祖国,就像是海和浪花一朵。
# 可以指定字符的个数,读取指定个数的字符
res = fp.read(5)
print(res) #
发现什么第二遍没有读取出任何的内容,我们重新打开一遍文件,重新读取。
with open('test.txt', 'r+', encoding='UTF_8') as fp:
# 读取五个字符
res = fp.read(5)
print(res) # 我和我的祖
# 再读取五个字符
res = fp.read(5)
print(res) # 国,一刻也
发现第二遍读取的内容是接着第一遍读取的内容之后的,我们重新打开一遍文件,写一些内容。
with open('test.txt', 'r+', encoding='UTF_8') as fp:
# 写入内容
fp.write('我永远和我的祖国在一起')
# 读取其中的内容
res = fp.read()
print(res) # 能分割。我和我的祖国,就像是海和浪花一朵。
读取内容的时候,发现没有我们写入的内容,而且读取的文件内容怎么看起来好怪异的感觉啊,怎么少了些内容?
我们重新打开文件读取一遍
with open('test.txt', 'r+', encoding='UTF_8') as fp:
res = fp.read()
print(res) # 我永远和我的祖国在一起能分割。我和我的祖国,就像是海和浪花一朵。
为什么我们的写入的内容在文件的开头,而且还替换掉了原有的一部分数据?我们上面的一系列操作为什么那么的奇怪?
这都是因为光标的作用在做怪。
光标的作用
还记得我们之前介绍四种打开模式的时候吗?写入模式光标在文档最后,读取模式光标在文档最前,追加模式光标在文档最前,异或模式光标在文档最前。
写入的内容和读取的内容都是从光标的位置开始的。
read()函数默认读取光标一右侧所有的内容。而不是文档中的所有内容,之前的测试之所以可以一次性的读取出所有的内容是因为我们打开文档使用的是读取模式,光标的位置在文档的开头。光标会随着读取的内容而移动,读取到哪个字符光标就移动到哪个字符的后面。
write()写入内容的时候是覆盖模式。我们都知道我们的计算机系统中的文本输入方式是有两种的,使用insert键就可以切换着两种模式。一种是插入模式,一种是覆盖模式。
插入模式是我们平常最经常使用的,比如说我们打开一个文本编辑软件,随便的写入一段内容,然后把光标移动到文档的开头,写入内容,发现新的内容是插入到了旧的内容之前的,旧的内容不会消失,而是后移,这就是插入模式;然后重新将光标移动到文档的开头,然后按下insert键,这个时候你的输入方式就变成了覆盖模式,现在的你每当输入一个新的字符就会覆盖掉后面的一个旧字符,这就是覆盖模式,python的文本编辑就是这种覆盖模式。光标随着写入的内容向后移动。
光标位置的移动
我们刚才的时候就了解到了有一个可以调整光标位置的函数,叫做seek,使用这个函数我们可以随意的调节光标的位置,从而编辑文件的时候可以更加的随心所欲。
seek(offset: int, [whence: int = 0])
seek(偏移量, [基准位置])
seek函数的两个参数都是整型。
第一个参数表示的是偏移量,单独使用时表示将光标移动到从文档的开头算起的第N个字节的位置后;
第二个参数表示的光标的位置,使用的时候只有0、1、2三个选型,且偏移量必须为0;
0代表的是文档的最开端
1代表的是光标的当前位置
2代表的是文档的最后端
# 先使用 w+ 模式打开一个文件,这个时候的文件为空,光标在文档的开头位置
with open('test.txt', 'w+', encoding='UTF-8') as fp:
# 我们写入内容,这个时候光标的位置随着写入的内容到了文档的最后
fp.write('hello motherland.')
# 所以现在的光标的右侧没有任何一个字节符,所以读不出任何的内容
res = fp.read()
print(repr(res)) # ''
# 所以光标还是在最后的位置,使用seek切换光标的位置为开头,读取刚才写入的内容
fp.seek(0)
res = fp.read()
print(repr(res)) # 'hello motherland.'
# 读取完内容之后,光标又到了文档的最后的位置,调整到开头的第五个字节符的位置
fp.seek(5)
# 再次读取文件的内容,这一次只读取5个字符,发现前五个字符没有了
res = fp.read(5)
print(repr(res)) # ' moth'
# 现在光标在文档的第十个字符位置,我们将光标切换到文档的最后,然后读取文档发现什么内容也没有
fp.seek(0, 2)
res = fp.read()
print(repr(res)) # ''
注意到了吗?我说的seek移动的是字节的数量,什么是字节的数量?
我们之前说的不同的编码格式对于不同的字符都是不一样的,但是所有的编码格式对于英文字母为主的一些的字符都是一个字节的大小,但是汉字不一样,汉字在GB中是两个字节、UTF中是三个字节、Unicode中是四个字节。
seek的偏移单位是字节,不是字符,所以在使用seek在操作bytes字节流时,要注意移动的间隔,因为移动的是字节位数,而在GB编码中一个汉字两个字节,在Unicode(UTF-8)中,一个汉字三个字节,如果seek将指针移动至汉字之间,就会导致读取时汉字的编码不完整而导致错误。
# 重新写入一个文件,注意我们的编码格式
with open('test.txt', 'w+', encoding='UTF-8') as fp:
fp.write('我和我的祖国,一刻也不能分割。我和我的祖国,就像是海和浪花一朵。')
# 我们现在读取除了第一句话之后的内容,前面的内容一共是15个字符,我们使用seek跳过去
fp.seek(15)
res = fp.read()
print(repr(res)) # '国,一刻也不能分割。我和我的祖国,就像是海和浪花一朵。'
# 咦?怎么只跳过了五个汉字?因为我们使用的UTF-8的编码,一个汉字由3个字节,真好是15个单位
# 你是幸运的,如果我们在右移一个字节的单位,就是一个汉字都没有完全迁移完会怎么样?
fp.seek(1)
# res = fp.read()
# print(res) # error, 报错了,因为剩下的字符不是完整的,所以没有办法读出,就报错了
# 就像是你好的UTF-8编码是六个字节组成的,
print('你好'.encode()) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
# 如果去掉了一个字节,就是不完整的了,还能解码出来吗?
print(b'\xbd\xa0\xe5\xa5\xbd'.decode()) # error,解码失败
所以在使用seek函数的时候一定要慎用。
tell的使用
# tell 当前光标左侧所有的字节数(返回字节数)
# 使用阅读模式打开文件
with open('test.txt', 'r+', encoding='UTF-8') as fp:
# 使用tell函数查看贯标左侧的字节数
res = fp.tell()
print(res) # 0
# 因为阅读模式的光标在文件的开头,所以返回0个字节数
# 使用seek将光标移动到文档的末尾
fp.seek(0, 2)
# 使用tell查看整个文档的字节数,这就是文档的大小
res = fp.tell()
print(res) # 96
# 快去看看你的文件信息中的文件大小是不是96字节的?
其它的相关函数
判断文件对象可读可写
# 使用 r+ 模式打开文件
with open('test.txt', 'r+', encoding='UTF-8') as fp:
# 使用readable 和 readable 查看这个文档是否可读可写
if fp.readable():
print('本文档可读')
if fp.writable():
print('本文档可写')
'''
结果:
本文档可读
本文档可写
'''
readline
读取一行内容
# 打开文件,重新写入多行内容
with open('test.txt', 'w+', encoding='UTF-8') as fp:
# 可以使用多行字符串
fp.write('''11111
22222
33333
''')
# 也可以使用转义字符进行换行
fp.write('44444\n55555\n66666')

with open('test.txt', 'r+', encoding='UTF-8') as fp:
# 使用read读取的整个文档的内容
res = fp.read()
print(res)
'''
结果:
11111
22222
33333
44444
55555
66666
'''
# 使用readline读取一一行的内容
fp.seek(0)
res = fp.readline()
print(res) # 11111
# 再读取一行
res = fp.readline()
print(res) # 22222
# 可以指定读取的字符个数
res = fp.readline(3)
print(res) # 333
# 如果指定的个数大于本行的字符个数,就读取本行所有的内容
res = fp.readline(1000)
print(res) # 33
# 为什么是33不是44444?因为readline也要受到光标的影响
readlines
将文件中的内容按照换行读取到列表中
with open('test.txt', 'r+', encoding='UTF-8') as fp:
res = fp.readlines()
print(res) # ['11111\n', '22222\n', '33333\n', '44444\n', '55555\n', '66666'
注意:readlines不会影响光标的移动,但是读取的是光标的右侧数据;而且readlines的读取将换行符也读取上了,因为换行符本身也是一行的内容。
按行读取内容我一般使用到readlines函数,但是也可以使用其它的方法,比如直接遍历open实例化对象,open实例化对象本身就是一个可迭代对象,它将文件中的内容按照换行符分开。
with open('text.txt', 'r', encoding='UTF-8') as fp:
for line in fp:
print(line)
writelines
将内容是字符串的可迭代性数据写入文件中,writelines不会根据元素换行。
lst = ['china', 'america', 'russia']
with open('test.txt', 'w+', encoding='UTF-8') as fp:
# 使用writelines写入内容
fp.writelines(lst)
fp.seek(0)
# 读取数据
res = fp.readlines()
print(res) # ['chinaamericarussia']
truncate
文件中的内容只保留截取的内容。
从文件开头开始,截取指定字节长度的内容,然后将文件清空,然后将截取的内容重新填入文件中。
# 打开一个文件
with open('test.txt', 'w+', encoding='UTF-8') as fp:
# 写入一段内容
fp.write('1234567890')
# 保留截取的内容,只保留前5个字节的内容
fp.truncate(5)
# 查看文件的内容
fp.seek(0)
res = fp.read()
print(res) # 12345
关于生成文件MD5心得
我在工作时需要给调用翻译狗的一个API,用于上传文献并翻译返回,但是对方需要文件MD5进行验证,我们需要在接入接口的时候,需要将文件md5传入,这个时候就出现了一些问题,我在传入文件和文件MD5的时候,被对方回应文件MD5不匹配,我很好奇,为什么会出现这样的情况?
我在使用这个接口当中,有好几处地方比如token的生成和文件md5的地方都会需要md5加密,所以为此我们专门将生成md5的代码封装成为一个函数(将字符串输入,返回md5,代码如下:
import hashlib
def enMD5(target):
""" MD5加密 """
res = hashlib.md5(target.encode()).hexdigest()
return res
python中生成md5需要输入字节流格式的数据,而我一开始只有字符串的数据需要使用md5加密,所以我在函数中将字符串变成字节流。token就是传入字符串得到的。
但是文件md5的话可以直接读出字节流的格式,但是因为再使用这个函数不方便,所以我使用正常读取文档的方式读取文件中的内容,然后放入函数中,结果就是上面说的,和对方得出的文件md5并不匹配。我自认为我的代码是没有问题的,于是我们依次查找问题的所在,后来我发现网上很多博主的方法都是直接从文件读取二进制字节流的方式获取的,我实在是没有办法了,就想会不会就是读取方式的问题呢?果然,我就发现不同格式读取的出来的结果是不同的,测试的案例如下:
with open(file_path, 'w', encoding='UTF-8') as fp:
fp.write('msr\nhello\r\nmotherland.')
with open(file_path, 'rb') as fp:
print(fp.read())
with open(file_path, 'r', encoding='UTF-8') as fp:
print(r'f', repr(fp.read()), sep='')
上述的结果为:
b'msr\r\nhello\r\r\nmotherland.'
f'msr\nhello\n\nmotherland.'
没错,我发现直接使用b模式和普通模式读取内容然后转化成为bytes的结果是不同的,那么也必将导致最后文件md5是不正确的。大家也看到了,不管是哪一种读取的方法其实和我写入的内容都是不同的,在本次的测试案例当中对于换行有着不同的认知,读取的原因我没有深入了解,但是我注意到了官方文档中说b模式就是专门读取文件字节流格式的,所以以后大家生成文件md5的时候,一定要直接使用b模式读取文件内容。
上述的测试环境是:
python: python3.6.8_win_x64(Cpython)
system: windows_10_x64