《再也不怕elasticsearch》安装ik中文分词器
大家好我是迷途,一个在互联网行业,摸爬滚打的学子。热爱学习,热爱代码,热爱技术。热爱互联网的一切。再也不怕elasticsearch系列,帅途会慢慢由浅入深,为大家剖析一遍,各位大佬请放心,虽然这个系列帅途有时候更新的有点慢,但是绝对不会烂尾!如果你喜欢本系列的话,就快点赞关注收藏安排一波吧~
文章目录
-
-
- 前言
- 正文
-
-
- 什么是分词器
- 常见中文分词器
- 安装IK分词器
- IK分词器分词词典
- IK配置远程拓展词典
-
- 总结
-
前言
最近帅途沉迷算法,突然发现在leetcode上面,最简单的题帅途都要冥思苦想好久。流下了没技术的泪水。最近es系列更新时间线拖得很长。可能后面还会出一部分es拓展方面的文章,例如elk、es-sql、es的日志等。至于集成IK分词器,本来帅途是不怎么想写的,因为实在太简单!拆箱即用。但是有的小伙伴最近在跟帅途聊天的时候提到了这个问题。所以这里还是单独列一篇文章讲解IK分词器的集成和使用吧。当然各位如果有更多想看或者想一起学习的东西,也可私信帅途,说不定下一篇文章就是你推荐的哦~

正文
什么是分词器
分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。英文本身是以单词为单位, 单词与单词之间, 句子之间通常是空格、逗号、句号分隔. 因而对于英文, 可以简单的以空格来判断某个字符串是否是一个词, 比如: I love China, love和China很容易被程序处理。
但是中文是以字为单位的, 字与字再组成词, 词再组成句子. 中文: 我爱中国, 电脑不知道“爱中”是一个词, 还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分, 这就是中文分词器所要解决的问题。
常见的有一元切分法“我爱中国”: 我、爱、中、国. 二元切分法“我爱中国”: 我爱、爱中、中国。
常见中文分词器
- 1、SCWS
Hightman开发的一套基于词频词典的机械中文分词引擎,它能将一整段的汉字基本正确的切分成词。采用的是采集的词频词典,并辅以一定的专有名称,人名,地名,数字年代等规则识别来达到基本分词,经小范围测试大概准确率在 90% ~ 95% 之间,已能基本满足一些小型搜索引擎、关键字提取等场合运用。45Kb左右的文本切词时间是0.026秒,大概是1.5MB文本/秒,支持PHP4和 PHP 5。
- 2、 ICTCLAS
这可是最早的中文开源分词项目之一,ICTCLAS在国内973 专家组组织的评测中活动获得了第一名,在第一届国际中文处理研究机构SigHan组织的评测中都获得了多项第一名。ICTCLAS3.0分词速度单机 996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M.ICTCLAS全部采用C/C++编写,支持Linux、 FreeBSD及Windows系列操作系统,支持C/C++、C#、Delphi、Java等主流的开发语言。
- 3、HTTPCWS
HTTPCWS 是一款基于HTTP协议的开源中文分词系统,目前仅支持Linux系统。HTTPCWS 使用“ICTCLAS 3.0 2009共享版中文分词算法”的API进行分词处理,得出分词结果。HTTPCWS 将取代之前的 PHPCWS 中文分词扩展。 庖丁解牛分词: Java 提供lucence 接口,仅支持Java语言。
- 4、CC-CEDICT
一个中文词典开源项目,提供一份以汉语拼音为中文辅助的汉英辞典,截至2009年2月8 日,已收录82712个单词。其词典可以用于中文分词使用,而且不存在版权问题。Chrome中文版就是使用的这个词典进行中文分词的。
- 5、IK
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包。从 2006年12月推出1.0版开始,IKAnalyzer 已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对 Lucene的默认优化实现。
- 6、Paoding
Paoding (庖丁解牛)基于Java的开源中文分词组件,提供lucene和solr 接口,具有极 高效率 和 高扩展性 。引入隐喻,采用完全的面向对象设计,构思先进。高效率:在PIII 1G内存个人机器上,1秒 可准确分词 100万 汉字。采用基于 不限制个数 的词典文件对文章进行有效切分,使能够将对词汇分类定义。能够对未知的词汇进行合理解析
- 7、MMSEG4J
MMSEG4J 基于Java的开源中文分词组件,提供lucene和solr 接口 1、mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。 2、MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
安装IK分词器
- 1、下载IK中文分词器(需要跟ES版本对应,否者可能导致兼容性问题)
下载地址:IK分词器下载,由于帅途这里ES是7.3.2版本所有,我这里下载7.3.2版本分词器。
-
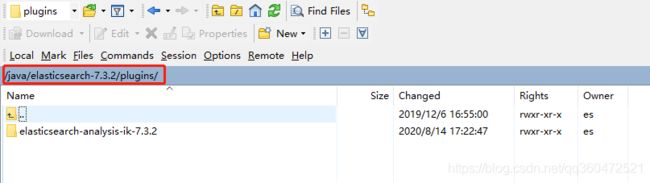
2、将我们下载好的分词器解压到ES的/plugins文件夹中。
在ES的安装目录中,找到plugins文件夹,将我们下载好的ik分词器解压到plugins文件夹中。注意,如果是集群环境,每台es都需要安装ik分词器。否者业务分发时候可能造成分词异常。
-
3、重启elastic search服务
// 在es的bin文件夹中启动es // ES_JAVA_OPTS="-Xms2g -Xmx2g":es启动参数,如果不填默认读取config文件夹中jvm.options配置 // -d :后台启动 ES_JAVA_OPTS="-Xms2g -Xmx2g" ./elasticsearch -d -
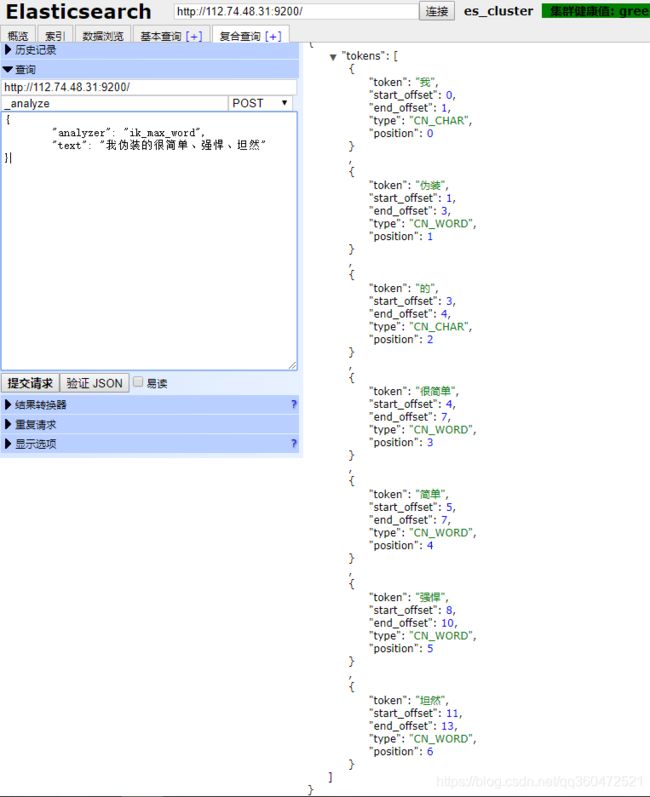
4、测试分词器安装是否成功
http://112.74.48.31:9200/_analyze --POST { "analyzer": "ik_max_word", "text": "我伪装的很简单、强悍、坦然" }
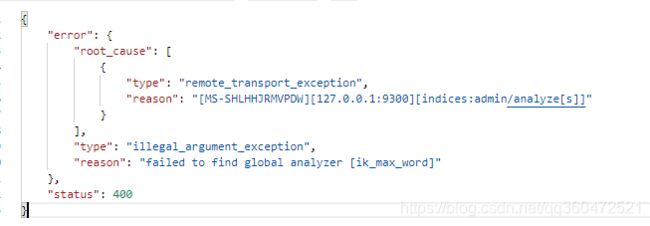
如果未安装成功则会弹出下图提示,假查ik是否解压到plugins文件夹中,分词器文件是否有缺失。
IK分词器分词词典
要配置分词词典我们需要,找我们plugins文件夹中找到我们的IK分词器,在config文件中找到IKAnalyzer.cfg.xml文件。
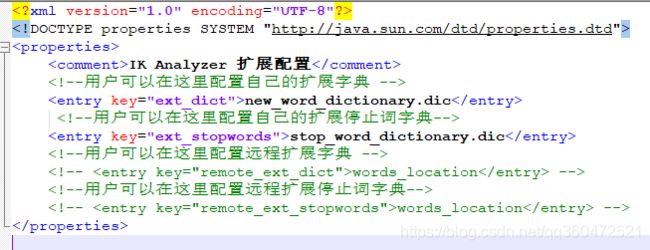
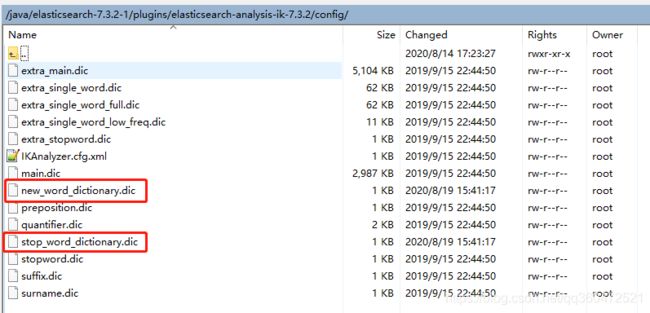
在上面的配置文件中我们可以看到,帅途分别配置了一个拓展字典和一个停用词字段。分别是new_word_dictionary.dic和stop_word_dictionary.dic,然后在对应config配置目录下新建对应词典即可。
接下来咋门来测试一下,帅途这里搜索这样一句话:帅途最近沉迷英雄联盟。
-
1、请求之前的查询结果
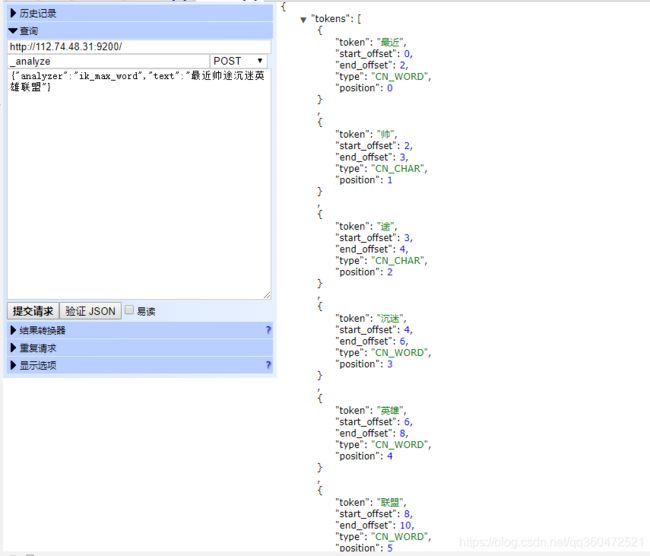
上图我们可以看到,帅途、英雄联盟这两个词是没有分词的。然后我们去修改我们的拓展词词典new_word_dictionary。
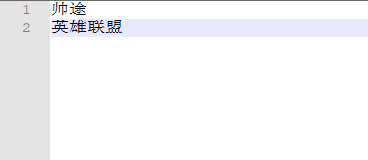
修改之后重启es,再次搜索:帅途最近沉迷英雄联盟。
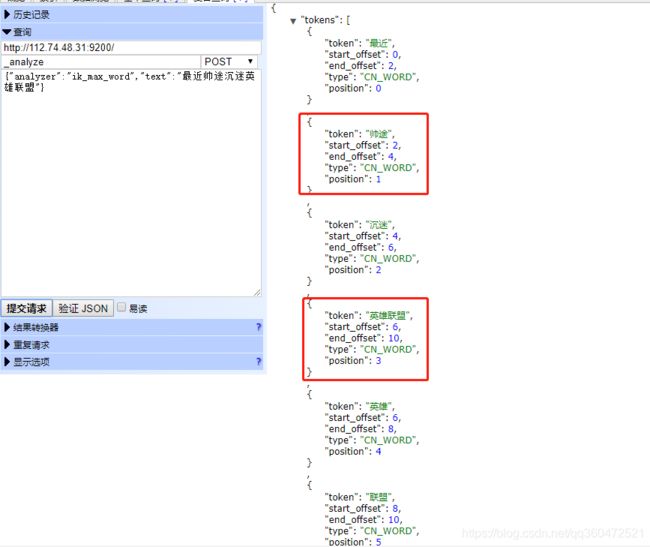
由此我们可以看到,我们拓展词典的词语就可以正常分词了。过滤词典与拓展词典一致。小伙伴们可以参考瞎拓展词典配置
IK配置远程拓展词典
看到这里不禁有小伙伴有疑问,如果我配置自定义词典,每次配置后都需要重启节点,并且如果是集群环境那么我有100个节点就需要配置一百次词典,所以IK为我们提供了远程拓展词典,本质上就是通过一个HTTP请求访问远程词典,然后加载到我们的es当中,并且无需重启es。
- 1、提供HTTP访问接口
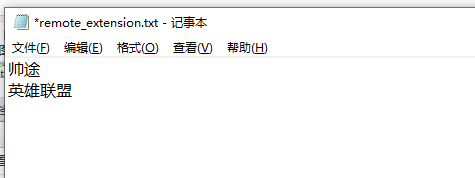
帅途这里就直接通过tomcat来进行提供,小伙伴们可以根据业务需要自己提供接口。再tomcat访问页下新建文件remote_extension.txt,在里面新增我们的拓展分词。
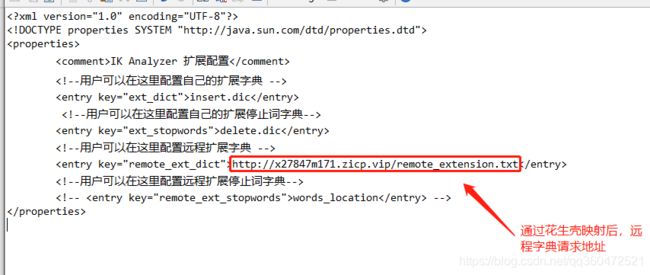
- 2、在我们的IK分词器配置文件IKAnalyzer.cfg.xml里面配置HTTP请求地址
由于帅途用的是公网环境所以使用花生壳映射一下本机8080端口,以供ES服务器调用。
- 3、配置完毕之后重启ES节点,这里的重启指的是我们第一次配置远程拓展字典访问地址的时候,配置完毕之后IK的远程字典自带热更新功能。更新字典就不用重启节点了。
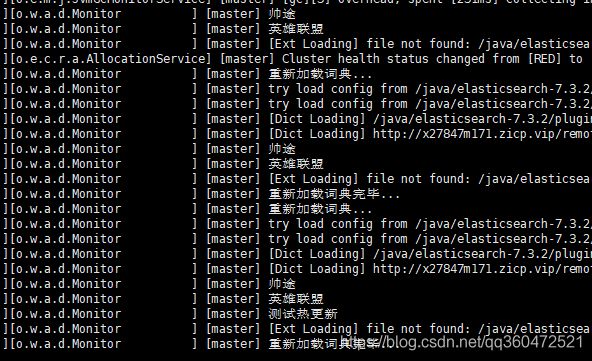
由上图可以看出,我们配置远程字典访问接口之后,ES每隔一段时间会为我们重新加载词典,帅途这里配置的是拓展字典,过滤词字典也是同理。
总结
IK分词器的配置和使用帅途就为大家列举到这里了。其实配置IK分词器就三个步骤。
- 1、将IK分词器安装到ES对应plugins文件夹中
- 2、在IK分词器的config文件夹中配置IKAnalyzer.cfg.xml文件
- 3、根据我们在IKAnalyzer.cfg.xml中的配置,配置对应的拓展字典、停用词字典文件,远程字典访问路径即可。
- 4、需要注意一个小问题,我们的自定义字典不支持热更新,而我们的远程字典是支持热更新的。所以推荐使用远程字典。一般来说我们在项目中常把远程字典放在nginx或者tomcat中。可以根据自己的需求选择。
最后,大家可能发现帅途的更新很不稳定,有时候很久才会更新一篇文章,其实不是帅途不想更新,是有时候实在太忙,然后其实写一篇技术文章真的是比较费心血的,不太熟悉的东西要查阅大量相关资料,毕竟写出来的东西至少要对自己负责嘛。所以希望各位大佬看到这了,就点个赞关注一下再走吧。如有不足也请指出。一起共同成长~

另外私信帅途,还有免费的学习资料送给你哟~