TIOVX 学习笔记其二:TIVOX
TIOVX 学习笔记其二:TIVOX
- 1. TIOVX(TI’s OpenVX)
- 2. 步骤示例:Mono-camera Analytics Processing Graph
-
- 2.1 代码实现步骤
- 3 Node 和 Graph 参数定义
- 4 流水线[^1]
- 5 Key API
-
- 5.1 vxCreateContext
- 5.2 vxReleaseContext
- 5.3 vxGetStatus
- 5.4 vxAllocateUserKernelId
- 5.5 vxAddUserKernel
- 5.6 vx_kernel_validate_f
- 5.7 vxAddParameterToKernel
- 5.8 vxFinalizeKernel
- 5.9 vxReleaseKernel
- 5.10 vxRemoveKernel
- 5.11 tivxCreateNodeByKernelEnum
- 5.12 vxSetReferenceName
- 5.13 vxQueryImage
- 5.14 vxQueryReference
- 5.15 tivxMemShared2TargetPtr
- 5.16 tivxMemBufferMap
- 5.17 vxCreateTensor
- 5.18 vxVerifyGraph
- 5.19 vxScheduleGraph
- 5.20 vxWaitGraph
- 5.21 tivxMapTensorPatch
- 5.22 tivxCheckStatus
Reference:
- Hardware Accelerated Structure From Motion on TDA4VM
- TIOVX (TI OpenVX)简介及例程
CPU(Central Processing Unit,中央处理器)发展出来三个分枝,一个是DSP(Digital Signal Processing/Processor,数字信号处理),另外两个是MCU(Micro Control Unit,微控制器单元)和 MPU(Micro Processor Unit,微处理器单元)。
MCU 集成了片上外围器件;MPU 不带外围器件(例如存储器阵列),是高度集成的通用结构的处理器,是去除了集成外设的 MCU;DSP运算能力强,擅长很多的重复数据运算,而 MCU 则适合不同信息源的多种数据的处理诊断和运算,侧重于控制,速度并不如 DSP。MCU区别于 DSP 的最大特点在于它的通用性,反应在指令集和寻址模式中。
1. TIOVX(TI’s OpenVX)
TIOVX 是 TI 对 OpenVX 标准的实现。
TIOVX 允许用户使用 OpenVX API 创建视觉和计算应用程序。TIOVX 完全符合 OpenVX v1.1 规范,这些 OpenVX 应用完全可以在如 TDA2x、TDA3x 等 TI SoC 上执行。TIOVX 还为 C66x DSP(C66x 可以看成是一种 DSP 架构?TDA4上搭载了一个C7x和两个C66x)提供了优化的 OpenVX 内核。扩展 API 允许用户集成自己本地开发的自定义内核,并使用 OpenVX API 调用它们。
TIOVX 的顶层框图如下所示:

其中:
- OpenVX API:由 Khronos 定义的 OpenVX API;
- TIOVX API:为了在 TI 平台上有效地使用 OpenVX,TI 扩展和额外的 API;
- Target kernel:TI 特定的接口,用于在 target CPU(如DSP-Digital signal processors) 上集成 user kernel; The OpenVX specification describes how users can plugin their own kernels (which are only executed on the host core) into OpenVX.
- User kernel:使用标准的 Khronos OpenVX API 在 host CPU 上集成 user kernel 的接口; Since the OpenVX specification only supports host-side user kernels, TI has created its own vendor extension which adds support for users to add kernels on other targets in the system.
这里的 target 和 host CPU 与交叉编译中的意思不太相同---- target CPU 将处理后的数据传递给 host CPU, 如一些硬件加速模块 VPAC 等;而 host CPU 可以看做是通用 CPU 模块,做最终集成,如 A72。(可以看成是 master 和 slave 的区别)
HOST:User Thread on HOST CPU, calls OpenVX APIs;
Taeget:TI OpenVX “Target” executes vision kernels. Target can run on same CPU as HOST. Multiple Targets on a CPU possible. Target execute in parallel to each other;
TIVOX Framework 为 TI 对 OpenVX 规范的实现,包含了官方和 TI 扩展框架,其中:
- OpenVX: Context, Parameter, Kernel, Node, Graph Array, Image, Scalar, Pyramid, ObjectArray;
- TI: Target, Target Kernel, Obj Desc。
TIOVX Kernel Wrapper 提供了由硬件模块 VPAC视觉处理加速器(Vision Pre-processing Accelerator)(其中的LDC模块常用于做remap)和 DMPAC深度和运动处理加速器(Depth and Motion Perception Accelerator)封装成的 Kernel,用户也可用 Wrapper 将自定义的算法(如 OpenCV 算法, DSP 算法)封装成 Kernel。
(VPAC contains modules to accelerate different image pre-processingsub tasks such as tone mapping, noise filtering, lens distortion correction, and so forth. VPAC 包括加速不同的图像预处理子任务,如色调映射,噪声滤波,镜头失真校正等)
(DMPAC contains two modules, a Stereo Disparity Engine, or SDE, to accelerate stereo depth estimation, and a Dense Optical Flow Engine, or DOF engine, to accelerate DOF. DMPAC 包含两个模块,一个是双目视差引擎,用于加速双目深度估计,另一个是密集光流引擎,用于加速 DOF。)
2. 步骤示例:Mono-camera Analytics Processing Graph
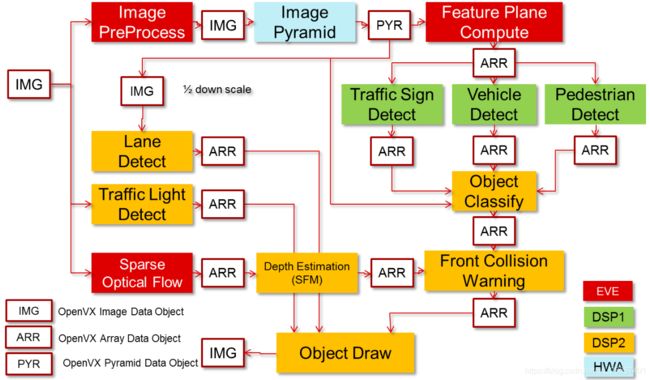 上图重点在于不同的 node,可以在不同的 target 上运作。
上图重点在于不同的 node,可以在不同的 target 上运作。
该示例的分布式图执行见下图:

分布式图形执行最小化了主机 ARM CPU 的开销,并减少了系统延迟。
2.1 代码实现步骤
Load and Save VX images—>Image manipulation using VXU APIs—>Image manipulation using graph and VX node APIs —>Graph with multiple targets, DSP1 and DSP2—>Graph generated with PyTIOVX tool —>Graph with user kernels on ARM—>Graph with target kernels on DSP
3 Node 和 Graph 参数定义
- Graph 参数:在 pipelining 模式下识别用户可排队在一个 graph 中的参数。通过创建一个图参数并显式地从 graph 中进入和离开该参数,应用程序就能够访问对象数据。否则,当使用流水线时,非 graph 参数在 graph 执行期间是不可访问的。
- Node 参数:在 TIOVX 实现中,应用使用 node 参数来标识在流水线的情况下需要在何处创建多个缓冲区。
4 流水线1
- tivxSetNodeParameterNumBufByIndex: 在开发流水线应用时,必须在流水线之间创建多个缓冲区2,以避免流水线中的任何停顿。根据 graph 中节点的延迟情况,需要针对特定的应用调整缓冲区的数量。这个 API 允许 graph 开发人员指定 框架在给定节点参数处内部使用的缓冲区数量。提供给这个 API 的节点参数必须是输出类型。此外,提供给该 API 的节点参数必须不能作为 graph 参数创建。要创建如下图所示的场景,使用 tivxSetNodeParameterNumBufByIndex 将 Node1 输出的缓冲区数设置为N。

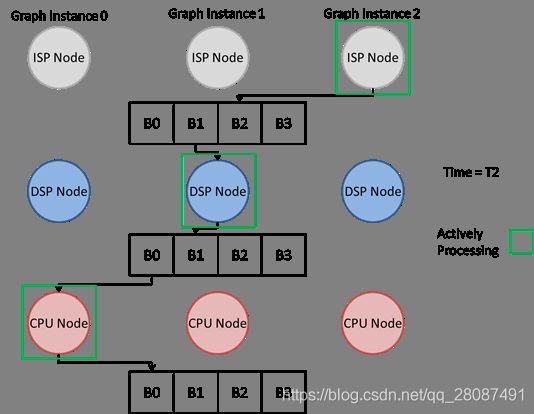
- tivxSetGraphPipelineDepth: 这个 API 允许应用程序开发人员显式地设置给定 graph 的管道深度。默认情况下,该值设置为 1。然而,为了获得充分的硬件利用率,需要根据 graph 配置设置管道深度值。考虑下图中所示的基本图表。这张图在 SoC 上使用了 3 个核心:一个 ISP, DSP 和 CPU。

如果没有流水线,一个新的 graph 执行将不能开始,直到最初的 graph 执行完成。然而,因为这里面的每个内核都可以并发运行,这个 graph 的执行并没有考虑到最佳的硬件利用率。TIOVX 流水线实现考虑到基于管道深度在内部创建多个 graph 实例来充分利用硬件。因此,这些 graph 中的每一个都将同时执行,这样每个核心都在积极地处理。tivxSetGraphPipelineDepth允许应用开发人员告诉框架要创建多少个这个 graph 的内部 instance。(注意:即使一个节点实现可以在多个核上运行,graph 的内部 instance 也被限制为跨所有 instance 的同一个核。)此值的最佳值必须基于给定的 graph 配置进行调整。下面的图片显示了这种情况的图解说明、如果上面显示的基本 graph 被设置为 3,框架将把图形当作有 3 个 instance 同时处理相同的 graph。下图显示了 T=2 时的图形处理,每个处理单元都是活动的。

除了设置流水线深度之外,上面所示的基本 graph 还可以使用 tivxSetNodeParameterNumBufByIndex API 在节点的输出处设置多个缓冲区。下图显示了当每个输出的 tivxSetNodeParameterNumBufByIndex 设置为 4 时,框架如何处理基本图形。如图所示,节点将写入缓冲区队列中的缓冲区,而下游节点正在处理缓冲区队列中的前一个缓冲区。
 当使用 TIOVX 设计流水线 graph 时,在实现 tivxSetGraphPipelineDepth 和 tivxSetNodeParameterNumBufByIndex API 时需要进行权衡。虽然性能会随着这些 API 设置的值的增加而增加,但使用的内存也会增加。对于 tivxSetGraphPipelineDepth API,如果管道深度值设置得太高,可能会创建不必要的内部创建的图结构。类似地,如果 tivxSetNodeParameterNumBufByIndex API 创建的缓冲区多于所需的,那么框架内用于额外缓冲区的内存也将是不必要的。TI 对应用程序开发的建议是,首先在初始开发时使用较大的管道深度和缓冲区数量,然后减少这些值,直到观察到性能下降。
当使用 TIOVX 设计流水线 graph 时,在实现 tivxSetGraphPipelineDepth 和 tivxSetNodeParameterNumBufByIndex API 时需要进行权衡。虽然性能会随着这些 API 设置的值的增加而增加,但使用的内存也会增加。对于 tivxSetGraphPipelineDepth API,如果管道深度值设置得太高,可能会创建不必要的内部创建的图结构。类似地,如果 tivxSetNodeParameterNumBufByIndex API 创建的缓冲区多于所需的,那么框架内用于额外缓冲区的内存也将是不必要的。TI 对应用程序开发的建议是,首先在初始开发时使用较大的管道深度和缓冲区数量,然后减少这些值,直到观察到性能下降。
5 Key API
5.1 vxCreateContext
vx_context VX_API_CALL vxCreateContext()
这必须首先在任何 OpenVX API 调用之前完成,返回的上下文被用作后续 OpenVX API 的输入。
vx_context context;
context = vxCreateContext();
5.2 vxReleaseContext
vx_status VX_API_CALL vxReleaseContext ( vx_context * context )
当使用完了 OpenVX 上下文时,释放掉它。在使用 vxCreateContext() 再次创建上下文之前,不应该再调用 OpenVX API。
vxReleaseContext(&context);
5.3 vxGetStatus
vx_status VX_API_CALL vxGetStatus ( vx_reference reference )
提供一个通用API,在对象构造函数失败时返回状态值。
如,检查 kernel 是否被成功加入到 OpenVX 上下文中:
vx_status status;
status = vxGetStatus((vx_reference)kernel);
5.4 vxAllocateUserKernelId
vx_status VX_API_CALL vxAllocateUserKernelId ( vx_context context,
vx_enum * pKernelEnumId )
分配并注册用户定义的 kernel 枚举到上下文。
如,动态分配一个 kernel ID 并将其存储在 ‘phase rgb user kernel ID’ 中:
// Kernel ID of the registered user kernel. Used to create a node for the kernel function.
static vx_enum phase_rgb_user_kernel_id = (vx_status)VX_ERROR_INVALID_PARAMETERS;//
status = vxAllocateUserKernelId(context, &phase_rgb_user_kernel_id);
5.5 vxAddUserKernel
vx_kernel VX_API_CALL vxAddUserKernel ( vx_context context, // 上下文的引用
const vx_char name[VX_MAX_KERNEL_NAME],
// kernel对应的字符串名
vx_enum enumeration,
// 客户端要使用的kernel的枚举值
vx_kernel_f func_ptr,
// 要调用的进程局部函数指针&&对于user kernel,该函数必须为non-NULL,对于target kernel,该函数必须为NULL
vx_uint32 numParams,
// 这个kernel的参数个数
vx_kernel_validate_f validate,
// 指向 vx_kernel_validate_f,它验证这个内核的参数&&对于OpenVX user kernel和TIOVX target kernel,这个函数的实现是相同的
vx_kernel_initialize_f init,
// kernel 的初始化函数&&这个函数通常只在user kernel中实现,在target kernel中为NULL
vx_kernel_deinitialize_f deinit
// kernel的de-init函数----这个函数在vxReleaseGraph期间被调用
) // Returns: vx_kernel 应该使用 vxGetStatus 检查任何可能阻止成功创建的错误…
(返回值为‘0’表明在添加kernel时有错误发生了||为‘*’表明kernel被成功添加到OpenVX)
将 kernel 注册到 OpenVX 上下文。
一个 kernel 可以用它的 kernel ID(vxAllocateUserKernelId 分配的)来标识;一个 kernel 也可以用它唯一的 kernel 名称字符串来标识。
kernel = vxAddUserKernel(
context,
TIVX_TUTORIAL_KERNEL_PHASE_RGB_NAME,
phase_rgb_user_kernel_id,
phase_rgb_user_kernel_run, // 这个函数在图形执行过程中被调用。在这里,实现了读取输入数据和写入输出数据的实际内核函数。
2, /* number of parameters objects for this user function */
phase_rgb_user_kernel_validate, // kernel validate function. Called during graph verify.
phase_rgb_user_kernel_init, // kernel init function. Called after phase_rgb_user_kernel_validate() during graph verify
phase_rgb_user_kernel_deinit); // kernel deinit function. Called during graph release.
5.6 vx_kernel_validate_f
typedef vx_status( * vx_kernel_validate_f)(vx_node node, const vx_reference parameters[], vx_uint32 num, vx_meta_format metas[])
// metas: 指向预先分配的系统保存的结构引用数组的指针。系统预先分配了一些 vx_meta_format 结构,仅用于输出参数,使用与 parameters[] 相同的索引索引。validation 函数为系统填写正确的类型、格式和维度,以用于创建内存或针对现有内存进行检查。
用户定义的 kernel node 参数验证函数。该函数只需要填充元数据结构。
5.7 vxAddParameterToKernel
vx_status VX_API_CALL vxAddParameterToKernel ( vx_kernel kernel,
vx_uint32 index,
// 参数在函数参数列表中的索引
vx_enum dir,
// 参数的方向: VX_INPUT 或 VX_OUTPUT
vx_enum data_type,
// 参数数据对象类型
vx_enum state
// 参数状态: VX_PARAMETER_STATE_REQUIRED 或 VX_PARAMETER_STATE_OPTIONAL)
为 kernel 定义参数。
index = 0;
if ( status == (vx_status)VX_SUCCESS){
status = vxAddParameterToKernel(kernel,
index,
(vx_enum)VX_INPUT,
(vx_enum)VX_TYPE_IMAGE,
(vx_enum)VX_PARAMETER_STATE_REQUIRED
);
index++;
}
if ( status == (vx_status)VX_SUCCESS){
status = vxAddParameterToKernel(kernel,
index,
(vx_enum)VX_OUTPUT,
(vx_enum)VX_TYPE_IMAGE,
(vx_enum)VX_PARAMETER_STATE_REQUIRED
);
index++;
}
5.8 vxFinalizeKernel
vx_status VX_API_CALL vxFinalizeKernel ( vx_kernel kernel )
将所有参数添加到 kernel 并准备好使用 kernel 之后,调用这个 API。注意,在调用 vxFinalizeKernel 之后,对 vxAddUserKernel 创建的 kernel 的引用仍然有效。(在 kernel 的所有参数定义好之后调用,即在 vxAddParameterToKernel 之后调用)
if (status == (vx_status)VX_SUCCESS){
status = vxFinalizeKernel(kernel);
}
5.9 vxReleaseKernel
vx_status VX_API_CALL vxReleaseKernel ( vx_kernel * kernel )
释放对 kernel 的引用。除非对象的总引用计数为零,否则不会对该对象进行垃圾收集。
if( status != (vx_status)VX_SUCCESS){
printf(" phase_rgb_user_kernel_add: ERROR: vxAddParameterToKernel, vxFinalizeKernel failed (%d)!!!\n", status);
vxReleaseKernel(&kernel);
kernel = NULL;
}
5.10 vxRemoveKernel
vx_status VX_API_CALL vxRemoveKernel ( vx_kernel kernel )
从上下文中删除一个自定义 kernel 并释放它。
static vx_kernel phase_rgb_user_kernel = NULL; // 首先在程序开头,要注册user kernel的句柄
phase_rgb_user_kernel = kernel; // 设置kernel句柄为全局user kernel句柄, 这个全局句柄在以后使用时用来释放kernel
status = vxRemoveKernel(phase_rgb_user_kernel); // 从上下文中删除kernel
phase_rgb_user_kernel = NULL; // 将全局phase_rgb_user_kernel设置为NULL
5.11 tivxCreateNodeByKernelEnum
vx_node tivxCreateNodeByKernelEnum ( vx_graph graph,
vx_enum kernelenum,
vx_reference params[], // 与枚举的kernel相对应的参数引用列表
vx_uint32 num // 参数列表中参数引用的数量)
如 5.5 中标识符所说,还有其他两种方式来使用相同 node 来创建 kernel:tivxCreateNodeByKernelRef 和 tivxCreateNodeByKernelName,用法相似。
vx_node node;
vx_reference refs[] = {(vx_reference)in, (vx_reference)out}; // 将参数放入引用数组中
node = tivxCreateNodeByKernelEnum(graph, // TIOVX API用graph、kernel ID和参数引用数组作为输入来创建节点
phase_rgb_user_kernel_id,
refs, sizeof(refs)/sizeof(refs[0])
);
5.12 vxSetReferenceName
vx_status VX_API_CALL vxSetReferenceName ( vx_reference ref, const vx_char * name )
此函数用于将名称与被引用的对象关联。OpenVX 实现可以在日志消息和任何其他报告机制中(如 vxQueryReference)使用这个名称。OpenVX 实现不会检查名称在引用范围(上下文或 graph)中是否唯一。多个引用可以具有相同的名称。
vxSetReferenceName((vx_reference)node, "PHASE_RGB");
vxSetReferenceName((vx_reference)in_image, "INPUT");
5.13 vxQueryImage
vx_status VX_API_CALL vxQueryImage ( vx_image image, vx_enum attribute, void * ptr, vx_size size )
// attribute: 要查询的属性,使用了 vx_image_attribute_e
下面为所有可以查询的属性——查询图像的宽度、高度、格式、平面、大小、空间、范围、范围和内存类型:
vxQueryImage(image, (vx_enum)VX_IMAGE_WIDTH, &width, sizeof(vx_uint32));
vxQueryImage(image, (vx_enum)VX_IMAGE_HEIGHT, &height, sizeof(vx_uint32));
vxQueryImage(image, (vx_enum)VX_IMAGE_FORMAT, &df, sizeof(vx_df_image));
vxQueryImage(image, (vx_enum)VX_IMAGE_PLANES, &num_planes, sizeof(vx_size));
vxQueryImage(image, (vx_enum)VX_IMAGE_SIZE, &size, sizeof(vx_size));
vxQueryImage(image, (vx_enum)VX_IMAGE_SPACE, &color_space, sizeof(vx_enum));
vxQueryImage(image, (vx_enum)VX_IMAGE_RANGE, &channel_range, sizeof(vx_enum));
vxQueryImage(image, (vx_enum)VX_IMAGE_MEMORY_TYPE, &memory_type, sizeof(vx_enum));
5.14 vxQueryReference
vx_status VX_API_CALL vxQueryReference ( vx_reference ref, vx_enum attribute, void * ptr, vx_size size )
// attribute: 要查询的属性,使用了 vx_reference_attribute_e
5.12中 vxSetReferenceName 设置的名字,通过下面方式可以获取:
// vx_reference_attribute_e:VX_REF_ATTRIBUTE_COUNT, VX_REF_ATTRIBUTE_TYPE, VX_REF_ATTRIBUTE_NAME
vxQueryReference((vx_reference)image, (vx_enum)VX_REFERENCE_NAME, &ref_name, sizeof(vx_char*));
vxQueryReference((vx_reference)image, (vx_enum)VX_REFERENCE_COUNT, &ref_count, sizeof(vx_uint32)); // 返回对象的引用计数
5.15 tivxMemShared2TargetPtr
void* tivxMemShared2TargetPtr ( const tivx_shared_mem_ptr_t * shared_ptr )
将 shared 指针转换成 target 指针
/* Get the Src and Dst descriptors */
src_desc = (tivx_obj_desc_image_t *)obj_desc[PHASE_RGB_IN0_IMG_IDX];
dst_desc = (tivx_obj_desc_image_t *)obj_desc[PHASE_RGB_OUT0_IMG_IDX];
/* Get the target pointer from the shared pointer for all buffers */
src_desc_target_ptr = tivxMemShared2TargetPtr(&src_desc->mem_ptr[0]);
dst_desc_target_ptr = tivxMemShared2TargetPtr(&dst_desc->mem_ptr[0]);
/* Map all buffers, which invalidates the cache */
tivxMemBufferMap(src_desc_target_ptr,
src_desc->mem_size[0], (vx_enum)VX_MEMORY_TYPE_HOST,
(vx_enum)VX_READ_ONLY);
tivxMemBufferMap(dst_desc_target_ptr,
dst_desc->mem_size[0], (vx_enum)VX_MEMORY_TYPE_HOST,
(vx_enum)VX_WRITE_ONLY);
5.16 tivxMemBufferMap
vx_status tivxMemBufferMap ( void * host_ptr, // 要映射的缓冲区内存
uint32_t size, // 以字节为单位映射的内存大小
vx_enum mem_type, // 该指针所属的内存类型
vx_enum maptype // 映射类型: VX_READ_ONLY, VX_WRITE_ONLY, VX_READ_AND_WRITE)
映射已分配的缓冲区地址,这会使缓存失效。示例见 5.15。
5.17 vxCreateTensor
vx_tensor VX_API_CALL vxCreateTensor ( vx_context context,
vx_size number_of_dims, // 维度的数量,一般用的二维,即值为2
const vx_size * dims,
vx_enum data_type, // 数据类型
vx_int8 fixed_point_position // 当输入元素类型为整数时,指定定点位置。如果为0,则执行整数数学计算。)
创建一个对 tensor 数据缓冲的不透明引用。
vx_size = {OUTPUT_SIZE, MAX_NUM_OF_OBJECTS};
vx_tensor cout_tensor = vxCreateTensor(context, 2, size, VX_TYPE_FLOAT32, 0);
5.18 vxVerifyGraph
vx_status VX_API_CALL vxVerifyGraph ( vx_graph graph )
在执行 graph 之前验证其状态。这对于捕获程序错误非常有用。如果未验证,则 graph 在处理之前进行验证。
5.19 vxScheduleGraph
vx_status VX_API_CALL vxScheduleGraph ( vx_graph graph )
为将来的执行安排一个 graph。如果 graph 还没有被验证,那么将立即执行对 graph 的验证(意思就是会自动做 5.18 vxVerifyGraph 的操作咯)。如果验证失败,这个函数将返回一个与 vxVerifyGraph 返回的状态相同的状态。在 graph 验证成功后,处理将会接着发生。如果 graph 之前通过 vxVerifyGraph 或 vxProcessGraph 验证,则该 graph 将被处理。
5.20 vxWaitGraph
vx_status VX_API_CALL vxWaitGraph ( vx_graph graph )
等待指定的 graph 完成。如果自最后一次调用 vxWaitGraph 以来,graph 已经被调度多次,则 vxWaitGraph 只在最后一次调度执行完成时返回。
status = vxVerifyGraph(graph); //5.18
if(status==(vx_status)VX_SUCCESS)
{
vxScheduleGraph(graph); //5.19
vxWaitGraph(graph); //5.20
}
5.21 tivxMapTensorPatch
VX_API_ENTRY vx_status VX_API_CALL tivxMapTensorPatch ( vx_tensor tensor,
vx_size number_of_dims, //tensor的维数
const vx_size * view_start, //每个维度中的patch起始点的数组。这是可选参数,当为NULL时为零。
const vx_size * view_end,
vx_map_id * map_id, //vx映射id变量的地址,该函数返回一个映射标识符。tivxUnmapTensorPatch时有用
vx_size * stride, //以字节为单位的所有维度的stride数组。索引0处的stride值必须是张量数据元素类型的大小。
void ** ptr, //指针的地址,函数将其设置为可以访问所请求数据的地址。返回的(*ptr)地址只在函数调用和对应的tivxUnmapTensorPatch调用之间有效。
vx_enum usage, //VX_READ_ONLY,VX_READ_AND_WRITE,VX_WRITE_ONLY
vx_enum mem_type //VX_MEMORY_TYPE_NONE,VX_MEMORY_TYPE_HOST
)
允许应用获得一个 patch of tensor object 的直接访问。
5.22 tivxCheckStatus
static void tivxCheckStatus ( vx_status * status, // 状态变量,注意是地址
vx_status status_temp // 暂时的状态变量
)
如果 status_temp 不为 VX_SUCCESS,将状态值赋给 status。
\newline
\newline
点击跳转:
TIOVX 学习笔记其一:OpenVX.
TIOVX 学习笔记其三:concerto makefile.
TIOVX 学习笔记其四:Objects.
流水线
Non-pipelined Execution:
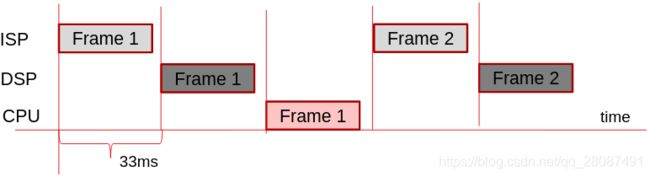 Frame-Level Pipelined Execution:
Frame-Level Pipelined Execution:
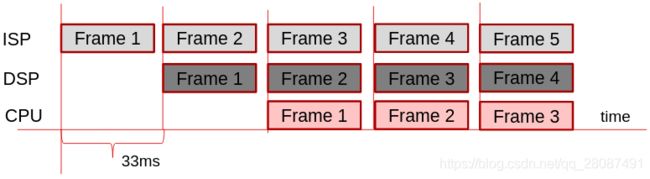 ↩︎
↩︎为什么要引入缓冲区?
高速设备与低速设备的不匹配,势必会让高速设备花时间等待低速设备,我们可以在这两者之间设立一个缓冲区。
缓冲区的作用:
* 可以解除两者的制约关系:数据可以直接送往缓冲区,高速设备不用再等待低速设备,提高了计算机的效率。(例如:我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情)
* 可以减少数据的读写次数,如果每次数据只传输一点数据,就需要传送很多次,这样会浪费很多时间,因为开始读写与终止读写需要花上较多时间,如果将数据送往缓冲区,待缓冲区满后再进行传送会大大减少读写次数,这样就可以节省很多时间。(例如:我们想将数据写入到磁盘中,不是立马将数据写到磁盘中,而是先输入缓冲区中,当缓冲区满了以后,再将数据写入到磁盘中,这样就可以减少磁盘的读写次数,不然磁盘很容易坏掉。)
简单来说,缓冲区就是一块内存区,它用在输入输出设备和 CPU 之间,用来存储数据。它使得低速的输入输出设备和高速的 CPU 能够协调工作,避免低速的输入输出设备占用 CPU,解放出 CPU,使其能够高效率工作。 ↩︎