【Linux】多线程,你绝对不能错过,详解!
多线程,可重入、如何保证线程安全?
- 什么是多线程?
- 线程控制
- 重入和线程安全
- 互斥锁
- 条件等待
- 生产者与消费者模型
1)什么是多线程?
1.为什么要有多线程?
一个进程中并不是只有一个main函数的执行流,而是有很多个执行流在同一时刻占用不同的CPU进行运算,我们称之为并行。同一时间有多个执行流在执行代码,程序的运行效率就可以大大提高,创建一个线程就相当于创建了一个执行流。
2.什么是线程?
线程就是创建出来的执行流,它在内核中拷贝当前进程的PCB并创建了一块PCB,和进程共用一块虚拟地址空间。
创建一个进程(fork,vfork)
fork:子进程拷贝父进程的PCB创建出来一块PCB,PCB在内核中用双向链表管理起来。此时,父子进程共用同一块虚拟地址空间,若父进程或者子进程的内容即将发生改变,则给子进程重新开辟一个虚拟地址空间(写时拷贝技术)
vfork:拷贝父进程的PCB并创建,两个PCB一模一样,并且指向同一虚拟地址空间,因此共用同一栈空间。vfork为了解决调用栈混乱的问题,让子进程先运行,直到退出,父进程才开始运行。
创建一个线程(pthread_create)
pthread_create:在内核中拷贝进程PCB,并创建一块PCB,和进程共用同一虚拟地址空间,但是线程在虚拟地址的共享区,会有自己独立的东西(线程ID,栈,信号屏蔽字,错误信息,寄存器,调度优先级等)
注意事项: 在Linux中其实没有线程这一概念(是C库中的概念),Linux中叫轻量级进程(LWP)。线程的一系列接口都是C库提供的,因此链接时需要加上库名称。例:gcc test.c -o test -lpthread
3.线程的优缺点:
优点:
- 创建一个线程比创建进程的开销小(不用创建虚拟地址空间,页表,段表映射等等),且一些内容是共享的可以直接使用(例:数据段,代码段内容)
- 不同线程可以并行,提高了进程运行效率
缺点:滑稽吃鸡
- 健壮性/鲁棒性低(和2.的道理一样,缺乏安全性:一个崩溃全盘崩溃)
- 多线程的程序有多个执行流,当其中一个执行流异常,进而触发信号机制,会导致整个进程退出,所有线程也随之退出(桌子被掀翻)
- 缺乏访问控制(抢占式执行:不同的线程抢占同一资源,可能造成程序结果二义性)
- 编程难度高,多个执行流可以并发的执行,也就可能会访问到同一临界资源,我们需要对访问临界资源的顺序进行控制,防止程序产生二义性
- 性能损失,一个进程拥有很多个线程时,操作系统会不停的进行切换调度,而每次切换都要保存上下文信息(当前代码执行的信息和数据)和程序计数器(程序执行到代码哪一行)等。(重新拿到时间片)回调时会占用CPU先执行处理上下文信息,程序计数器,造成了性能损失。
总结:
1. 线程和进程拥有同一虚拟内存空间,且线程是并发式执行,即新增了一条执行流
2. 同一时刻一个资源最多只能有一个线程使用,否则可能造成二义性,因此要保证对临界资源的顺序访问,具体见 - 线程安全
4.线程的独有和共享:
线程拷贝进程的PCB并创建,共用同一块虚拟地址空间,在虚拟地址空间的共享区中有一块独有的空间。
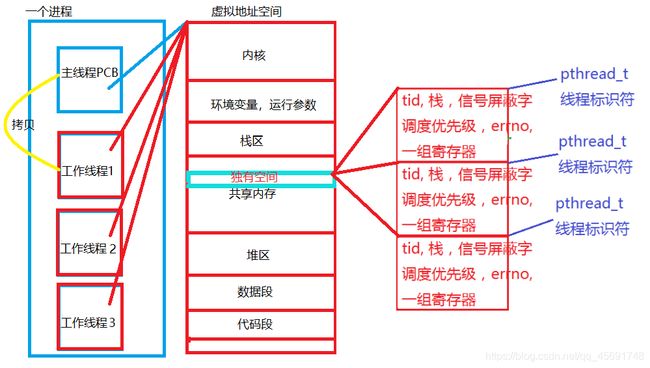
独有:(共享区内一块独有的)
- tid:线程ID
- 栈空间:因此线程不会造成调用栈混乱,因为每个线程在共享区都有独有的栈。一个进程的栈空间默认8M,用ulimit -s可修改
- 信号屏蔽字:信号阻塞的位图每个线程都不同
- 调度优先级:调用pthread_cond_wait()接口从PCB等待队列中出队时,优先出队级别高的线程
- errno:调用接口收到的错误信息
- 一组寄存器:保存当前线程切换时的上下文信息,程序计数器等
共享:(虚拟地址空间中其它的)
- 共享当前进程的虚拟地址空间(内核,环境参数,数据段,代码段):因此使用静态数据、全局数据的函数是不可重入的
- 文件描述符表:因此调用I/O库的函数是不可重入的
- 当前进程的工作路径,例运行程序时的./test
- 用户ID和用户组ID
- 信号的处理方式(SIG_DFL,SIG_IGN,自定义)
- 堆空间:因此申请堆上空间的函数也不可重入
总结:
1.线程都拥有各自的栈因此可以并行,不用担心调用栈混乱,而堆上空间是所有线程共享的。
2.若函数内存在共享内容,一般都是不可重入的。
2)线程控制
线程控制:创建,终止,等待,分离
前提:线程控制当中的接口都是库函数,所以线程控制的接口需要链接线程库,线程库的名称叫pthread,链接的时候增加lpthread,且大多函数都以pthread开头。
一、线程创建:
int pthread_creat(pthread_t* thread,const pthread_attr, void* (* thread_start) (void * ) , void* arg);
用例:pthread_creat(&tid,NULL,func,NULL);
thread:线程标识符pthread_t,是一个出参。
attr:线程属性,NULL是默认属性,一般都是用NULL
thread_start:线程入口函数,接收一个函数地址,这个函数的返回值是void*,参数也是void*
arg:给线程入口函数传递的参数的值,类型是void* ,一般这个参数也是传的NULL
返回值:==0创建成功,<0创建失败
下面看一段代码:arg接收临时变量i的地址
void* thread_start(void* arg) //自定义的线程入口函数
{
int* ti=(int*)arg; //创建一个int*接收强转后的arg
while(1)
{
printf("i am new thread!%d\n",*ti); //这里使用的是临时变量,在主线程中循环结束之后i被释放,访问的就是非法地址,没有崩溃是因为这段空间还没有被重新开辟。
sleep(1);
}
return NULL;
}
int main()
{
pthread_t tid; //线程标识符
for(int i=0;i<4;i++) //创建4个线程
{
int ret=pthread_create(&tid,NULL,thread_start,(void*)&i); //创建线程,传入临时变量i
if(ret<0)
{
perror("pthread_create");
return -1;
}
}
while(1)
{
printf("i am main thread\n");
sleep(1);
}
return 0;
}
运行结果:
i am new thread!2
i am new thread!3
i am new thread!4
i am new thread!3
i am main thread
i am new thread!4
i am main thread
^C
这段代码有两个问题:
- 临时变量:传入临时变量i,i在出了循环之后就被释放掉,这时线程访问的是非法空间,没有崩溃是因为这段空间还没有被重新开辟。
- 线程安全:运行结果并不是我们想象中的:0号、1号、2号、3号,4个线程,而是3出现了两次,造成程序运行二义性。其实多次运行,每次的结果都不相同,这就是之后讲的线程不安全
总结:
- pthread_t和线程ID并不是一回事,pthread_t是线程标识符,本质就是线程在共享区独有空间的首地址,通过这个标识符可以对当前线程进行操作。而线程ID是tid,具体见 - 线程ID、进程ID和LWP
- void* arg 不能接收临时变量的地址,这是因为主线程和线程是并行式运行,而临时变量在出了主线程的作用域,就会在栈帧上被释放资源,此时线程入口函数中使用的就是一块非法的地址,可能造成程序崩溃。
- void* arg可以接收堆上开辟的,如结构体指针,this指针。因为堆上动态开辟的资源需要手动释放,不要忘记在线程退出之前释放掉堆上的资源,防止内存泄露。
二、线程终止的方式:
- 线程入口函数的return返回,在主线程中调用return的效果相当于调用_exit(),整个进程都会退出
- pthread_exit(void* retval):谁调用谁退出
retval:当前线程退出信息,可以是NULL - pthread_cancel(pthread_t thread):结束指定的线程,pthread_self()获取当前线程的标识符
thread:线程的标识符
注意:
- pthread_cancel()并不是立即退出,要等待一小会,会看到打印了一行,这个等待时间不会超过1s
- 当主线程(也就是main函数的线程),调用pthread_exit()和pthread_cancel()退出的时候,进程并不会退出,因此主线程变成了"僵尸线程",而工作线程的状态还是R或者S
- 线程在默认创建的时候,默认属性当中认为线程是joinable的。joinable属性:当线程在退出的时候,需要其他线程来回收该线程的退出信息(资源),如果没有任何线程去回收,则共享区中对于退出线程的空间还是保留的,退出资源没有完全释放而造成内存泄露。(类似僵尸进程)
三、线程等待:为了释放线程退出资源,防止内存泄露
pthread_join(pthread_t,void ** ) 这是一个阻塞接口
pthread_t:线程标识符
void ** :获取线程退出的什么东西,线程不同的退出方式会收到不同的值,一般是传NULL
return:接收入口函数return返回的内容,
pthread_exit:获取pthread_exit(void*)的参数
pthread_cancel:获取到一个常数,
PTHERAD_CANCELED:#define PTHERAD_CANCELED (void*)(-1)
工作线程的资源可以由主线程来回收,主线程(进程)的资源由它的父进程bash(1号进程)来回收。
这样引起了一个问题:
1.若不等待处理线程退出,会造成内存泄露
2.若等待处理线程,因为是阻塞接口,则必须另一个线程专门等待他退出并回收资源,则线程并没有实质性提高效率
四、线程分离:改变线程的joinable属性,变成detach,从而使该线程退出时不需要其他线程来回收该线程的资源,可以被操作系统来回收
pthread_detach(pthread_t tid); detach(分离)
tid:线程标识符,设置tid为detach属性
1.分离的本质是给线程设置了一个属性
2.分离可以线程自己分离,也可以是组内其他线程通过获取到线程标识符去分离
五、线程ID、进程ID和LWP
在bash中查看一个进程的调用栈:pstack+pid
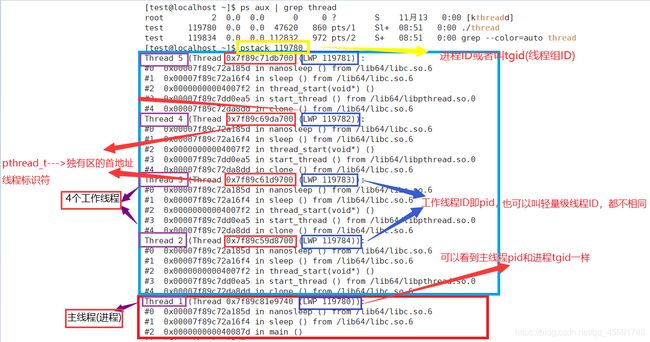
进程ID: 即tgid(thread group ID),也可以叫线程组ID。主线程的tid==tgid,工作线程的tid都不相同,但是tgid都指的是进程ID。在工作线程和主线程中使用getpid()接口,返回的都是进程ID。
线程ID: 即tid(thread ID),可以看到每一个在进程中被创建出来的线程,其线程ID都不相同。用syscall(SYS_gettid)接口,返回线程ID,或者在bash中输入top -H -p+进程ID查看
LWP: 轻量级线程,它在内核中是一块PCB,通过内核对PCB的调度,实现对线程的切换。
总结:
- 线程就是进程中的执行流,可以并发的运行,即在同一时刻占用不同的CPU进行运算,因此程序运行效率可以大大提升。
- 线程是操作系统调度的最小单位(调度PCB),进程是操作系统分配资源的最小单位(通过虚拟内存地址页表映射)。
- pthread_t是线程标识符,在内核的本质就是线程独有空间的首地址!用pstack+pid,可以看到LWP前面那一串就是线程标识符。
- getpid()获取的是进程ID即tgid,不管是在工作线程还是在主线程。gettid()获取的是线程ID即pid,可以用#include
; pid_t tid = syscall(SYS_gettid);来获取线程ID - pthread_creat是C库中函数,在用户态运行创建出来一个用户线程,这个线程在内核中通过PCB进行调度
- 为了避免越界访问,只能给arg传堆上开辟的空间。
- 轻量级进程在内核中就是一个PCB,内核通过对PCB的调度实现了对线程的调度。轻量级进程ID即pid,每一个pid都是不相同的,但是他们的进程组ID即tgid是一样的,也可以叫主线程ID或者进程ID。
下面模拟一个黄牛抢票的场景:
#define SCALS 4 //模拟四个黄牛抢票
int g_val=100;
void* thread_start(void* arg)
{
(void)arg; //不使用这个arg时把他void一下就行,防止报警告
while(g_val>0) //只要有票黄牛就一直抢票
{
printf("i am scaplers:%p,i get tickes:%d\n",pthread_self(),g_val);
g_val--; //抢到票则g_val--
}
return NULL;
}
int main()
{
pthread_t tid[SCALS];
for(int i=0;i<4;i++)
{
int ret=pthread_create(&tid[i],NULL,thread_start,NULL);
if(ret<0)
{
perror("pthread_create");
return -1;
}
}
for(int i=0;i<4;i++)
{
pthread_join(tid[i],NULL); //回收线程并清理线程退出资源
}
return 0;
}
运行结果:
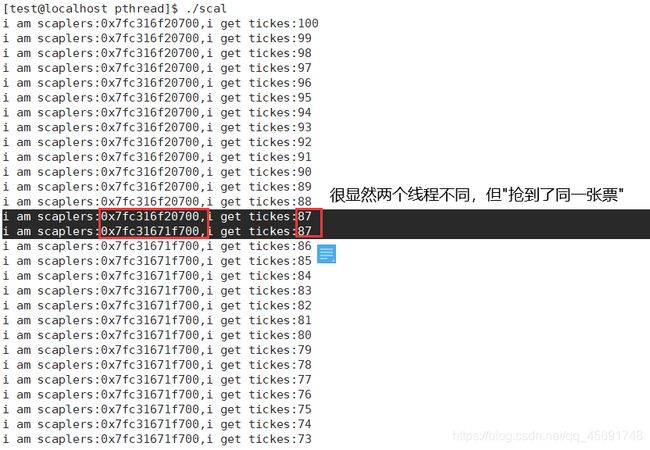
问题:
这里出现了一张票被不同黄牛,抢到多次的情况,很显然是不能存在的。这种情况就是我们所说的线程不安全,下面介绍如何保证线程安全。
3)重入和线程安全
重入概念: 同一个函数被不同执行流调用(线程入口函数),当一个执行流还没执行完,另一个执行流再次进入函数,就叫重入。
函数可重入:多个执行流同时调用同一函数,不会对运行结果产生影响则为可重入
函数不可重入:运行结果产生了二义性
常见不可重入:
- 函数在堆上申请了空间(malloc,new),堆是所有线程共享的
- 函数调用了I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构,并且文件描述符是共享的
- 使用静态或全局数据
注意:
1.函数可重入!=线程安全
2.函数可重入则一定线程安全,而线程安全不一定可重入,即可重入函数是线程安全函数的一种
线程安全: 多个线程并发的访问临界资源,而不会导致程序的结果产生二义性,则称线程安全。
前提:
- 线程对临界资源的访问方式:是非原子性操作,也就是可能在中途会被打断,并保存当前上下文数据和程序计数器,等待下次处理
- 临界资源:多个执行流共享的资源,同一时刻只能有一个执行流访问,若多个线程同时访问可能造成二义性
- 临界区:访问临界资源的代码就叫临界区
- 原子性操作:操作是一步完成的,意思就是:执行中没有被打断,完整的执行了一个运算并回写到内存中。例如++或者–等操作
下面看一下黄牛抢票程序中g_val- -操作的流程:
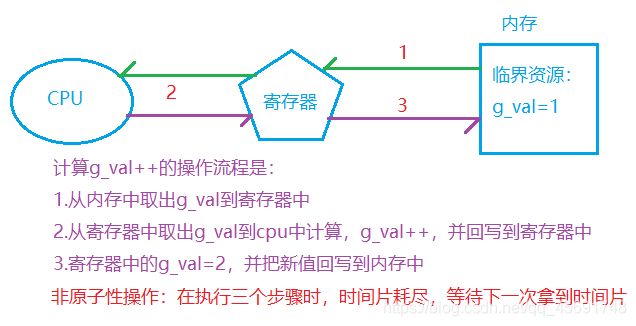
完整解释为什么会出现一张票被抢多次原因:
- 执行流A在执行–操作时(g_val==100),还没执行完毕,时间片耗尽,被迫让出CPU资源。程序计数器保存下一条将执行的指令,上下文信息保存寄存器中的g_val值(g_val ==100),等待下次拿到时间片
- 执行流B也去执行g_val的–操作,从内存中拿到100,完整的执行了整个–操作,并把g_val==99的值回写到了内存中
- 执行流A再次拿到时间片,恢复现场。上下文信息g_val==100,执行未处理完成的指令。把100减了一次,回写到内存的又是99。理论上两个线程分别执行–之后是98,因此造成程序运行结果二义性,也就是线程不安全。
拓展:对应汇编指令–>1.load:从内存加载到寄存器 。2.updata:更新寄存器中的值进行-- 。3.store:将寄存器中的值回写到内存中
这是三个指令操作,因此每个要执行时都可能被打断。
那如何保证线程的安全性呢?
1.互斥:互斥锁,在同一时刻只能有一个执行流访问临界资源
2.同步:条件变量,程序对临界资源的合理访问,也就是不同类型的线程顺序访问,一个类型的执行流访问完成就切换,这里切换是操作系统调度的,抢占式执行
互斥锁能保证互斥属性的原理:
互斥锁是一个阻塞接口,使用互斥锁来保证互斥属性,底层是互斥量,互斥量的本质是一个计数器,有0和1
计数器的值为:
0:无法获取互斥锁,即临界资源无法访问,并阻塞在加锁操作
1:可以获取互斥锁,互斥锁成功返回,并访问临界资源
加锁操作:对互斥锁中的互斥量计数器-1,实现本质是交换寄存器中的1和内存中的0
解锁操作:对互斥锁中的互斥量计数器+1
那么引出一个问题:互斥量计数器本身也是一个变量,那这个变量的取值进行++、–时,会是原子性的操作吗?
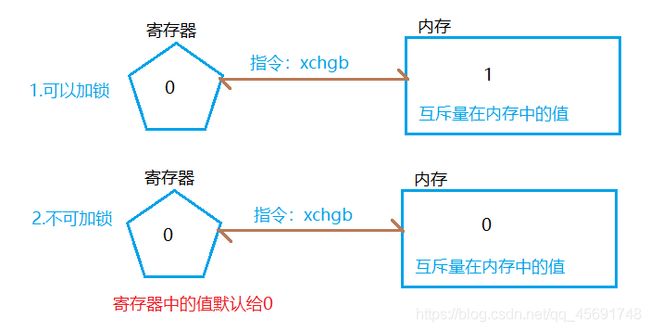
寄存器中的值(默认给0)和内存中互斥量计数器的值进行交换,这个操作在汇编中的指令是xchgb,把寄存器和内存中的值进行交换,由于只有一条指令,因此保证了原子性
加锁流程:
- 当计数器中的值为1时,表示可以加锁。寄存器中的0和内存中计数器的1交换,相当于给寄存器++了
- 当计数器中的值为0时。表示不能加锁。寄存器中的0和内存中计数器的0交换,没有对寄存器的值做到修改,因此请求加锁的执行流阻塞等待,直到计数器为1
- volatile无法解决这里的问题,这里是从内存中取出数据之后,线程运行时间耗尽导致。而volatile是拿数据的时候从内存中取。
总结:
1.对临界资源的访问时非原子性,因此导致程序运行可能产生二义性
2.互斥锁在同一时刻只能有一个执行流获取,且互斥量的操作是原子性的,因此可以保证互斥属性
4)互斥锁
互斥锁使用流程:
1.定义互斥锁
pthread_mutex_t:互斥锁变量类型,mutex(互斥锁),在内核中是一个结构体
用例:pthread_mutex_t lock;
2.初始化互斥量
动态初始化:
int pthread_mutex_init(pthread_mutex_t* mutex,const pthread_mutexattr_t* attr)
用例:pthread_mutex_init(&lock,NULL);
mutex:互斥锁变量,传参的时候传入互斥锁变量的地址
attr:互斥锁的属性,一般用NULL
静态初始化:pthread_mutex_t lock=PTHREAD_MUTEX_INITIALIZER;
PTHREAD_MUTEX_INITIALIZER :宏定义了结构体pthread_mutex_t(互斥锁)的值
3.加锁
1.int pthread_mutex_lock(pthread_mutex_t* mutex); 这是一个阻塞接口
用例:pthread_mutex_lock(&lock);
mutex:传阻塞变量的地址,&lock
注意:该加锁方式是阻塞接口
若计数器为1,则上锁,计数器清0,并执行之后代码
若计数器为0,则不可上锁,阻塞等待直到解锁,不能执行下面代码
2.int pthread_mutex_trylock(pthread_mutex_t* mutex);非阻塞加锁,不会阻塞等待(直接返回EBUSY),一般要循环等待解锁,不然线程会直接往下执行会访问到临界资源,造成二义性
mutex:传阻塞变量的地址,&lock
注意:该加锁方式是非阻塞
若计数器为1,则加锁,计数器清0,并执行之后代码
若计数器为0,则不可加锁,接口返回EBUSY(拿不到互斥锁),要循环进行加锁操作,防止该执行流返回EBUSY之后,直接往下执行代码,造成二义性的结果
3.int pthread_mutex_timedlock(pthread_mutex_t* mutex,const struct timespec* abs_timeout);阻塞等待一定时间之后,若还没获取互斥锁,则报错返回ETIMEOUT
mutex:传阻塞变量的地址,&lock
abs_timeout:加锁时的最长等待时间,超过时间还未加锁报错返回,有两个变量:一个是秒,一个是纳秒
4.解锁
int pthread_mutex_unlock(pthread_mutex_t* mutex);
三种加锁方式都可以解锁(万能钥匙),
注意:要在所有可能退出获得互斥锁线程的地方都加上解锁!!!!非常重要,一旦上锁的线程没解锁就退出,其它线程会一直阻塞。
锁子只有一个!!!
5.销毁互斥锁
int pthread_mutex_destroy(pthread_mutex_t* mutex);
互斥锁销毁,若使用完成后不进行销毁,造成内存泄露
使用互斥锁需要注意:
- 定义位置:C语言需要在不同函数中使用互斥锁,因此定义为全局变量,C++通常定义为类的成员变量,在类中使用
- 初始化位置:在创建线程之前
- 销毁位置:必须在线程退出之后,进行销毁互斥锁变量,防止内存泄露
- 在哪加锁:所有访问临界资源的位置之前都应该加锁
- 在哪解锁:在所有可能退出线程的地方都要解锁。否则可能会造成死锁的现象。
死锁:
- 什么死锁:一个执行流拿到锁资源,但没有释放就退出,会导致其它想要获取该互斥锁的执行流陷入阻塞等待,这种情况称为死锁。
- 死锁的4个必要条件(形成死锁的4个原因):
不可剥夺:只有当前获取互斥锁的线程可以进行解锁
互斥:一把锁同一时刻只能被一个执行流所占用(4个线程最后剩3个(有一个退出),且程序卡住)
请求与保持:当期执行流已经占用了一个互斥锁1,还申请新的互斥锁2,被阻塞,并且互斥锁1是无法解锁的(环型死锁)
循环等待:若干执行流在请求锁资源的情况下,形成了一种头尾衔接的循环等待资源(输出100后卡住,未解锁又去循环请求加锁了) - 避免死锁的方法
1.破坏必要条件
2.加锁顺序一致
3.不要忘记解锁:线程可能退出的地方都要进行解锁
4.一次性分配资源:执行流在完成某件事时,一次性把需要的锁资源都拿过来(拿过来之前已经被解锁),用完再全部解锁
总结:
1.在访问临界资源之前都应该进行加锁操作,
2.在所有退出的地方都应该进行解锁操作
3.加锁操作有点像,我们去某个地方设置一个门卫,门里有人则不放行
4.用continue实现同步,疯狂判断,浪费CPU资源,入等待队列之后,挂起等待,因此不会浪费CPU资源
下面是黄牛改进代码:
#define SCALS 4 //四个黄牛
int g_val=100; //100张票
pthread_mutex_t lock; //互斥锁
void* thread_start(void* arg) //抢票程序
{
(void)arg; //不使用这个arg时把他void一下就行,避免报警告
while(1)
{
pthread_mutex_lock(&lock); //加锁
if(g_val>0)
{
printf("i am scaplers:%p,i get tickes:%d\n",pthread_self(),g_val);
g_val--; //抢到票则g_val--
}
else
{
//pthread_mutex_unlock(&lock); //这个位置和return NULL位置解锁的效果是一样的
break;
}
pthread_mutex_unlock(&lock); //这里不解锁的话,拿到第100张票之后会继续循环,自己卡住了自己,死锁!
}
pthread_mutex_unlock(&lock); //这里不解锁的话,最后一次拿到锁的线程直接退出,会造成其它3个线程一直卡在pthread_mutex_lock处,无法加锁。
return NULL;
}
int main()
{
pthread_mutex_init(&lock,NULL);
pthread_t tid[SCALS];
for(int i=0;i<4;i++)
{
int ret=pthread_create(&tid[i],NULL,thread_start,NULL);
if(ret<0)
{
perror("pthread_create");
return -1;
}
}
for(int i=0;i<4;i++)
pthread_join(tid[i],NULL); //回收线程并清理线程退出资源
pthread_mutex_destroy(&lock); //如果使用完毕不销毁锁,会造成内存泄露
return 0;
}
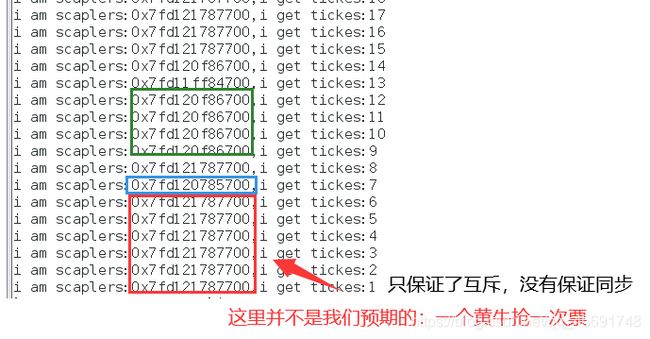
问题:
这里100张票是成功被抢光,且程序正常退出了,但有一个问题:没有保证同步—>每个黄牛各抢一次票然后切换,下面介绍条件变量来保证同步。
5)同步
概念: 同步保证了各个执行流对临界资源访问的合理性,通俗来讲:也就是一个执行流访问一次,就切换另一个执行流访问。通常我们用条件变量来保证同步属性。
什么是条件变量?
本质:PCB等待队列+两个接口(等待接口+唤醒接口)
条件变量接口:
1.定义条件变量:
pthread_cond_t 条件变量类型
用例:pthread_cond_t cond;
cond:条件变量类型的变量
2.初始化条件变量:
动态:使用完毕需要调用pthread_cond_destroy()销毁
pthread_cond_init(pthread_cond_t* cond,pthread_condattr_t* attr);attrutibe:属性
pthread_cond_t*:条件变量类型变量的地址
pthread_condattr_t*:条件变量的属性,一般传NULL,默认属性
静态:使用完毕不用销毁
pthread_cond_t cond=PTHREAD_COND_INITIALIZER; (initialize:初始化)
3.等待接口:将调用该等待接口的执行流放到PCB等待队列当中去,进行等待
int pthread_cond_wait(pthread_cond_t* cond,pthread_mutex_t* mutex)
pthread_cond_t*:传入条件变量类型变量的地址
pthread_mutex_t*:传入互斥锁变量的地址
4.唤醒接口:唤醒PCB等待队列当中的执行流进行出队
int pthread_cond_signal(pthread_cond_t* cond)
唤醒至少一个PCB等待队列当中的线程
int pthread_cond_broadcast(pthread_cond_t* cond)
唤醒所有PCB等待队列当中的线程(抢占式执行)
5.销毁:释放动态初始化的条件变量所占用的内存
int pthread_cond_destroy(pthread_cond_t* cond);
这里需要重点介绍等待接口:pthread_cond_wait(&cond,&lock);
- 为什么需要传入互斥锁?(保证互斥)
—简要说:条件变量只保证了各个执行流对临界资源访问的合理性,而并没有保证对临界资源的互斥属性,因此需要和互斥锁进行配合,完成各个执行流对临界资源访问的同步和互斥属性。
—内部流程:先把调用接口的线程加入PCB等待队列,再解锁互斥锁。等待,在收到信号唤醒时,出队,继续抢锁,成功抢锁则,访问临界资源。这个函数内部封装了加锁和解锁的操作。 - 为什么先入队,再释放锁资源?(防止通知空队列)
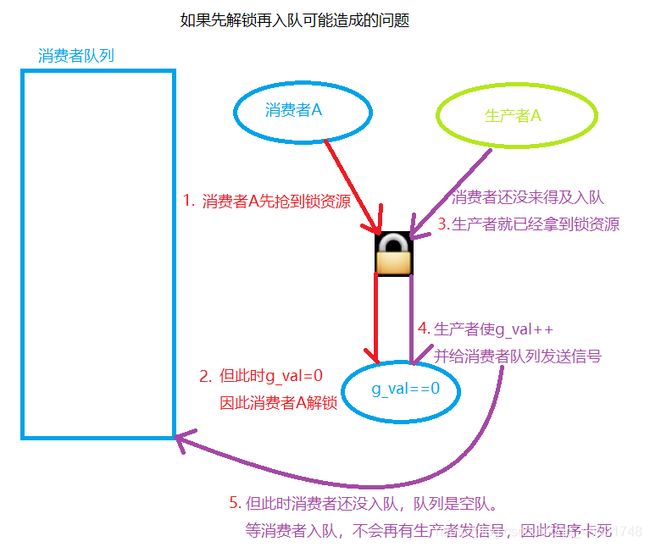
1)如果先释放锁资源再入队可能造成的问题:消费者加锁,当g_val= =0时消费者调用wait接口释放锁,还没等消费者入队。这时生产者已经拿到锁资源并执行g_val + +并发送信号了,但这时队列是空队。
2)然后消费者入队,生产者再次拿到锁(因为只有它一个),判断g_val==1因此又释放锁并入队,造成消费生产都卡死。 - 该接口的内部实现逻辑是什么样的?(做3件事)
1)将调用pthread_cond_wait的执行流放入PCB等待队列
2)解互斥锁
3)等待被唤醒 - 唤醒之后,会做哪些事?(做两件事)
1)从PCB队列中移除出来
2)抢占互斥锁资源
1_拿到互斥锁,pthread_cond_wait函数返回,接着执行下面的代码
2_没拿到,阻塞在pthread_cond_wait函数内部抢锁的逻辑当中
1.一直抢直到时间片耗尽,这个执行流就被切换,程序计数器中就保存抢锁指令,上下文数据当中保存的就是寄存器中的0(还没抢到锁默认给0)。
2.当再次拿到时间片,从程序计数器和上下文信息当中恢复抢锁的逻辑,继续去抢锁。
下面模拟一下吃面和做面:
pthread_mutex_t lock; //定义一个锁资源
pthread_cond_t cond; //定义一个条件变量
int noodles=0; //临界资源
void* thread_a(void* arg) //顾客线程
{
(void)arg;
while(1) //循环吃面
{
pthread_mutex_lock(&lock); //加锁
if(noodles==0){
pthread_cond_wait(&cond,&lock); //如果没有面,则调用wait接口阻塞并入队,等待厨子做面。注意这里传了lock的地址,接口底层封装了解锁(phtread_mutex_unlock)和被唤醒时加锁(pthread_mutex_lock)的代码。
}
noodles--;
sleep(1);
printf("i am consumer,i ate noodles:%d\n",noodles);
pthread_mutex_unlock(&lock);
pthread_cond_signal(&cond); //已经吃完面了,给厨子发送一个做面信号,唤醒厨子做面
}
return NULL;
}
void* thread_b(void* arg) //厨子
{
(void)arg;
while(1)
{
pthread_mutex_lock(&lock); //加锁
if(noodles==1){
pthread_cond_wait(&cond,&lock); //如果有面,则入队等待顾客吃面。
}
noodles++;
sleep(1);
printf("i am cooker,i made noodles:%d\n",noodles);
pthread_mutex_unlock(&lock);
pthread_cond_signal(&cond); //已经做好面了,给顾客发送信号,唤醒顾客吃面。
}
return NULL;
}
int main()
{
pthread_t tid[2]; //定义两个线程标识符
pthread_mutex_init(&lock,NULL); //初始化锁资源
pthread_cond_init(&cond,NULL); //初始化条件变量
if(pthread_create(&tid[0],NULL,thread_a,NULL)<0){
perror("pthread_create");
return -1;
}
if(pthread_create(&tid[1],NULL,thread_b,NULL)<0){
perror("pthread_create");
return -1;
}
for(int i=0;i<2;i++)
pthread_join(tid[i],NULL);
pthread_mutex_destroy(&lock);
pthread_mutex_destroy(&lock);
return 0;
}
运行结果:
[test@localhost cond]$ ./noodles
i am cooker,i made noodles:1
i am consumer,i ate noodles:0
i am cooker,i made noodles:1
^C
这段代码还是有问题:
如果有多个消费者和多个生产者,那么程序会执行一段之后卡住
原因:
生产者和消费者用了同一个PCB等待队列,如果消费者A访问完临界资源使,g_val==0,并调用pthread_cond_signal接口通知PCB等待队列。唤醒的还是一个消费者B,那么消费者B会直接入队,就再也没有通知PCB等待队列的了,因此程序运行一段之后都会卡死!!
解决:
1.用pthread_cond_boardcast接口唤醒PCB等待队列的所有线程(不建议,唤醒还是抢占式执行效率低)
2.生产者和消费者分别用一个PCB队列进行管理,消费者完成消费通知生产者队列,生产者完成生产通知生产者队列。
模板:
消费者:
pthread_mutex_lock(&lock); //加锁
while(如果临界资源不可用)
{
pthread_cond_wait(&consumer_cond,&lock);//入消费者队列
}
g_val--; //操作临界资源
pthread_mutex_unlock(&lock); //解锁
pthread_cond_signal(&producter_cond); //通知生产者队列
生产者:
pthread_mutex_lock(&lock); //加锁
while(如果临界资源不可用)
{
pthread_cond_wait(&producter_cond,&lock);//入生产者队列
}
g_val--; //操作临界资源
pthread_mutex_unlock(&lock); //解锁
pthread_cond_signal(&consumer_cond); //通知生产者队列
总结:
- 从PCB等待队列当中唤醒的线程,需要循环去判断当前资源数量是否可用(这样判断是程序员自己定义的)
- 对于不同角色的执行流,应该使用不同的条件变量,在调用wait接口时被放到不同的PCB等待队列中去
6)生产者与消费者模型
123规则:1个场景(队列)+两种角色(消费者与生产者)+3种关系(消费者与消费者互斥+生产者与生产互斥+消费者和生产者同步加互斥)
生产者与消费者模型的优点:
可以解耦合:生产者只负责生产,消费者只负责消费,生产者和消费者都是通过队列进行交互。
支持忙闲不均:队列起到了缓冲作用,只要队列不满,生产者可以一直往队列中插入数据,消费者也是同样道理。
支持并发:消费者只关心队列中是否有数据可以进行消费,生产者只关心队列中是否有空闲的节点进行生产
如何实现生产者与消费者模型
1.队列,借助STL中的queue,队列属性:先进先出,所有满足先进先出特性的数据结构都可称为队列。
2.线程安全的队列
queue 为了高效率,STL中的queue并不是线程安全的
互斥:使用互斥锁
同步:使用条件变量
3.两种角色的线程
生产者线程:负责往队列插入数据
消费者线程:负责从队列里取数据
push:生产者 pop:消费者
队列指针要在线程退出之后,释放堆空间
现象:消费者先于生产者打印一条,原因:已经生产后,将打印时,时间片耗尽,被切换。
只保证了插入和取出的顺序,但不能保证打印顺序
下面模拟一下生产者和消费者模型:
#include