幸存与否 ——泰坦尼克号沉船事件数据分析*
幸存与否
——泰坦尼克号沉船事件数据分析
铁达尼号沉船事件发生在1912年4月。铁达尼号是当时世界上最大的客运轮船,而此次航行为首次。铁达尼号从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰昆士敦,计划中的目的地为美国纽约。由于航行途中瞭望员没有及时发现前方的冰峰,最后船撞上冰峰造成船难。本次数据分析基于真实的泰坦尼克号沉船事件数据,分析幸存与否的关键。
一、描述性分析
(1)数据变量
此次分析的数据变量共有11个,分别为:
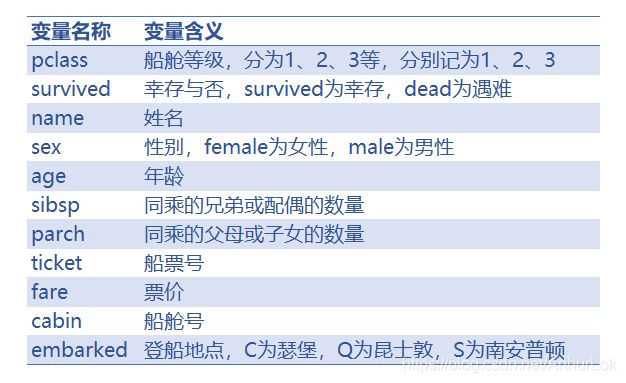
在这些数据变量中姓名(name)和船票号(ticket)显然不能为最终幸存与否带来直接关联,而船舱号(cabin)缺失值多达1014个,所以这三个变量不作分析考虑。
数据的观测数有1309对,含有缺失数据的有274对,其中年龄(age)值缺失有263个,票价(fare)缺失有18个,登船地点(embarked)缺失有2个。含有票价(fare)与登船地点(embarked)缺失值的观测数据对与其他观测数据没有太多关联信息,所以选择删除。
由于年龄(age)对数据分类影响可能比较大,所以不能删除。选择使用KNN算法,近邻数取10,来估计缺失的数据。最后可用的观测数据有1289对。
(2)变量与变量间关系
响应变量为幸存与否(survived),自变量为船舱等级(pclass)、性别(sex)、年龄(age)、同乘的兄弟或配偶数量(sibsp)、同乘的父母或子女数量(parch)、票价(fare)、登船地点(embarked)。其中年龄(age)、同乘的兄弟或配偶数量(sibsp)、同乘的父母或子女数量(parch)和票价(fare)为数值变量,幸存与否(survived)、船舱等级(pclass)、性别(sex)和登船地点(embarked)为因子变量,统计分析如下:
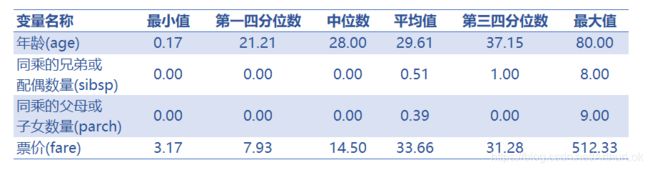
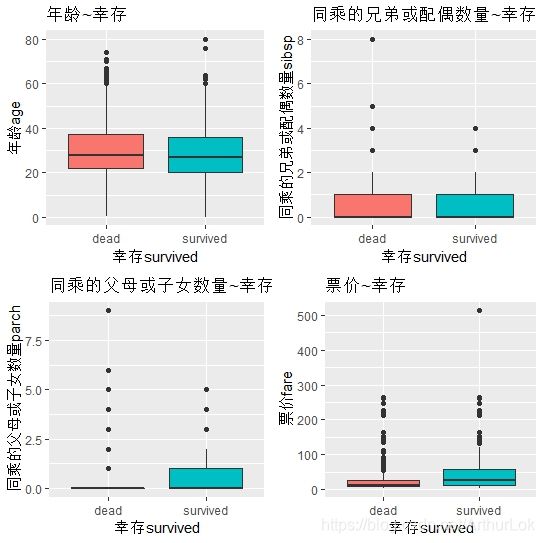
由分位数表及四张箱形图可得,1.年龄(age)的分布靠近年轻人为主,其中也不乏一部分老年人。幸存者与遇难者的年龄分布比较接近,幸存者相对年龄年轻一些。两者都有一部分离群点,可能年纪大的行动不方便以至遇难,也有可能由于年龄大,基于尊老获得一定的获救机会。2. 同乘的兄弟或配偶数量(sibsp)、同乘的父母或子女数量(parch)两个变量都存在一大部分零值,同乘的兄弟或配偶数量(sibsp),对于幸存与否在箱形图中区别不明显。而同乘的父母或子女数量(parch)却有明显差别,同乘的父母或子女数量多者更有获救可能。可能由于乘上逃生船的时候连带带上直系亲属。3. 票价(fare)而言,可以看出票价最高与最低差价悬殊。幸存者比遇难者票价分布要高。高票价者得到了一定的特殊待遇,最高票价的乘客也幸存下来。
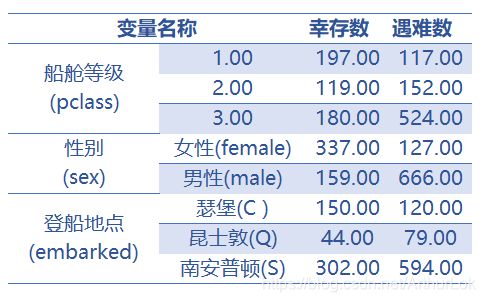
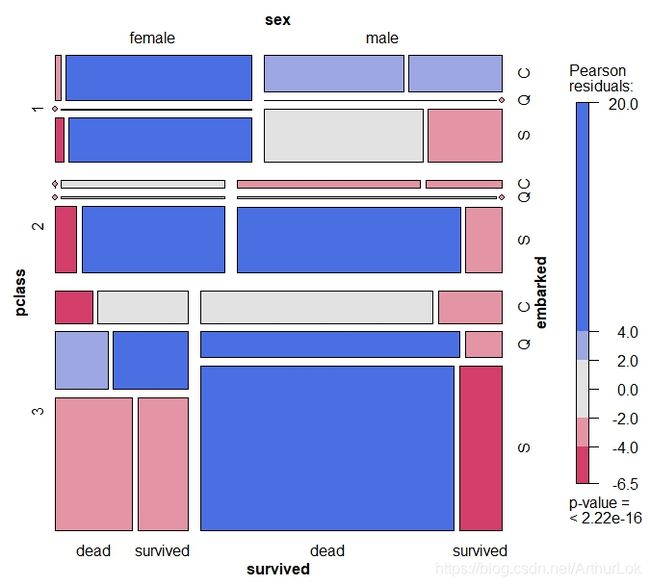
由表格数据和马赛克图可得1.幸存者人数为496人,遇难者人数为793人,遇难人数比幸存人数多。2.随着船舱等级的提高(3到1),幸存者比例也大幅提高。3.大部分乘客在南安普顿(S)登船,且大部分在南安普顿(S)登船的乘客都在等级3的船舱。其中船舱等级3在南安普顿(S)或者昆士敦(Q)登船的男性乘客,遇难比例比一般高。4.女性(female)的幸存者比例比男性(male)高,特别在等级1和等级2船舱上。可能女性逃生时也有基于妇女优先的权利。
二、训练模型
(1)随机森立模型
首先把数据集随机划分为训练集(占80%)和测试集(20%)。
利用船舱等级(pclass)、性别(sex)、年龄(age)、同乘的兄弟或配偶数量(sibsp)、同乘的父母或子女数量(parch)、票价(fare)和登船地点(embarked)变量对幸存与否(survived)变量建立随机森林模型。其中最优子树个数为68,在测试集上准确率为83.88%。其中基于基尼系数变量重要性如下图:
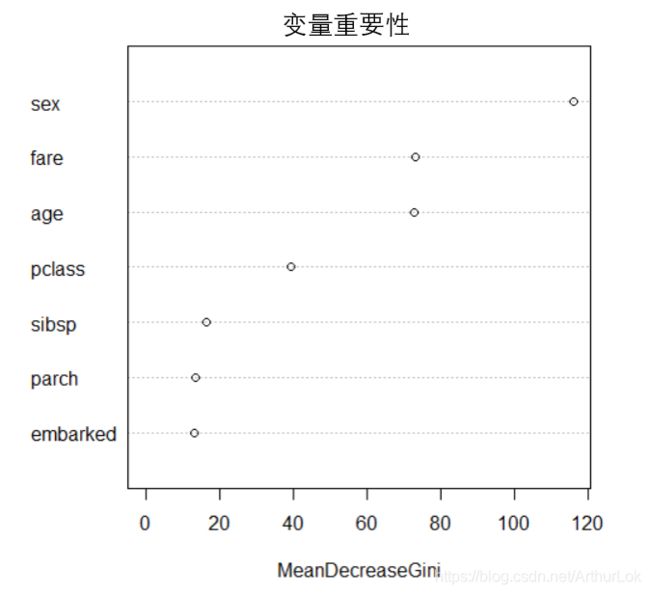
由图可得最重要的变量为性别(sex),其次是票价(fare),最不重要,对模型影响最小的为登船地点(embarked)。
保留前四个重要变量,等级(pclass)、性别(sex)、年龄(age),票价(fare)重新训练模型。其中最优子树个数为142,在测试集上准确率为81.92%,比7个变量的模型准确率要低一些。保留第一个模型。
(2)XGBoost模型
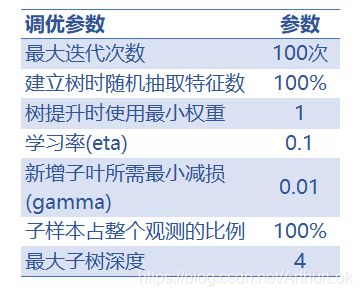
使用7个变量进行训练,一、二阶导数由logistic函数计算,经过10折交叉验证,选出最优参数如下:
变量重要性如下:
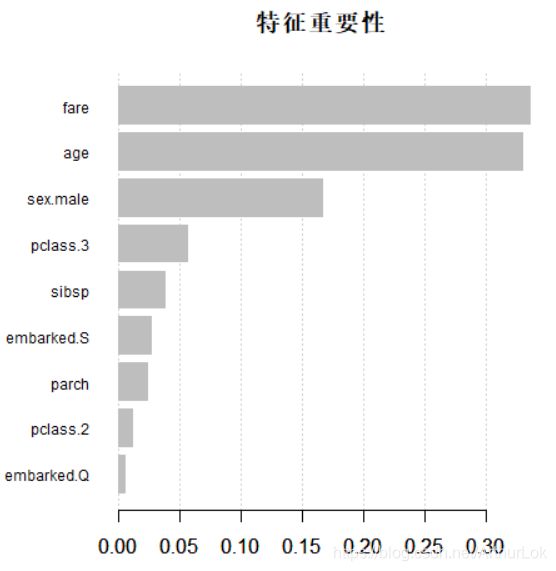
数据经过独热编码,船舱等级(pclass)编码拆分为pclass.2和pclass.3,性别(sex)编码为sex.male,登船地点(embarked) 编码拆分为embarked.S和embarked.Q。由图可得,最重要的变量为票价(fare),次重要为年龄(age),最不重要的变量为登船地点(embarked.Q )和船舱等级(pclass2)。XGBoost模型的变量重要性与随机森林模型的有差别,但最重要的前3个变量都一样。XGBoost模型在测试集上的准确率为77.31%,比不上随机森林模型。
(3)BP神经网络模型
使用独热编码的7个变量进行模型训练,隐藏层数为1,隐藏层的神经元数为2,激活函数为tanh。训练结果如下:
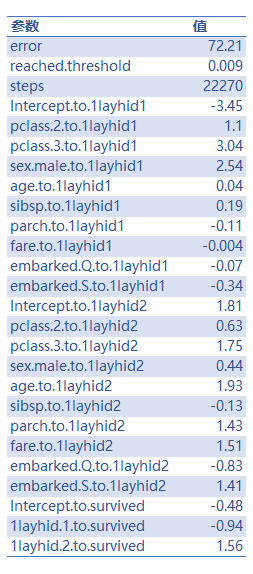
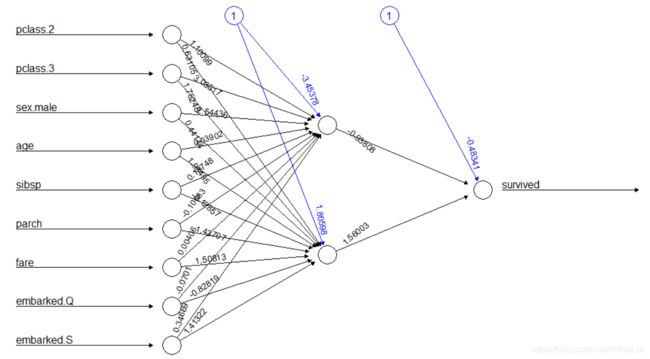
由参数图可以看出,变量中船舱等级(pclass.3.to.1layhid1)、性别(sex.male.to.1layhid1)
、年龄(age.to.1layhid2 )权重比较大。BP神经网络模型在测试集上准确率为80.99%,介于随机森林模型和XGBoost模型之间。
(4)模型间比较
首先使用ROC图对比,如下:
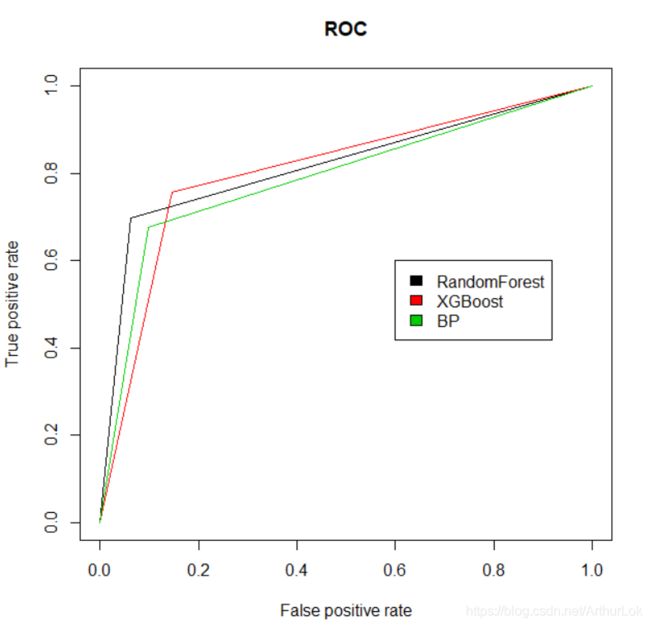
ROC图中三个模型表现难以比较。计算出三个模型的AUC值,随机森林模型为0.82,XGBoost模型为0.81,BP神经网络模型为0.79。由AUC值及测试集表现可得,随机森林模型表现最佳。三个模型都指向性别、年龄、票价这三个变量,说明这三个变量对在铁达尼灾难中是否能幸存下来起关键性作用。也如马赛可图,在船舱等级较高的女性幸存比例远高于平均,船舱等级高也意味者票价相对较高。而年轻意味着可能是弱小儿童能率先得到保护,或者是年轻人有更好的身体素质抵抗灾难。