Python数据分析与挖掘——泰坦尼克号
Python数据分析与挖掘——泰坦尼克号
本文利用已给特征属性和存活与否标签的训练集和只包含特征信息测试集数据,通过决策树等模型来预测测试集数据乘客的生存情况
#导包
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DTC #决策树
from sklearn.model_selection import GridSearchCV # 超参数自动搜索模块
from sklearn.model_selection import train_test_split #划分训练集和测试集
train=pd.read_csv('./train.csv') #加载数据
#训练集数据整体情况
train.info() #显示表格信息,判断含有缺失值和非数字的列
结果:
可以看出:
1.Name、Sex、Tocket、Cabin、Embarked是Object类型
2.可以看到Age、Cabin、Embarked是有缺失数据的
解决方法:
1.Age中的空值可用平均年龄来填充
2.Cabin有大量的缺失值,在训练集和测试集中缺失率都比较高,无法补齐
3.Embarked为登陆港口,可以根据港口属性补齐。可以看到港口为“S”类型的占比最高,可以考虑把缺失的港口用“S”港口填充
数据预处理
1.删除掉缺失值太多的列,与预测结果无关的列
train=train.drop(["Name","Cabin","Ticket","PassengerId"],axis=1)
train.info()

2.缺失值较多的列Age进行填充
train["Age"]=train["Age"].fillna(train["Age"].mean())
train.info()

3.极少缺失值的列Embarked删除有缺失值的行`
train=train.dropna(axis=0,how="any")
train.info()

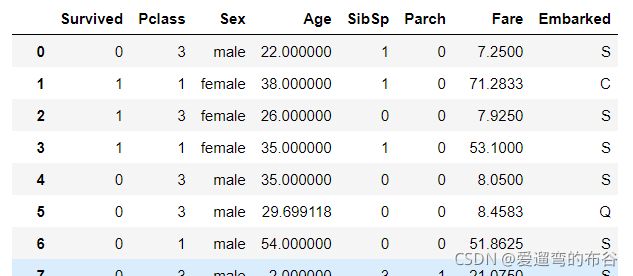
查看表的数据
train
因为我们之后要用决策树等模型来建立模型,决策树不能处理文字类型,所以我们要将ex和Embarked转为数字一一转化文字
# data["Sex"]=='male'得到的是Series类型,均为false和true
# 只有两种数据时,用布尔转化为整数的方法
train["Sex"]=(train["Sex"]=='male').astype(int) #布尔索引判断
train["Embarked"].unique()
#unique函数去除其中重复的元素,并按元素由小到大返回一个新的无元素重复的元组或者列表。
labels=train["Embarked"].unique().tolist()
# 将数据用索引数字代替,相同的数据用同一数字
train["Embarked"]=train["Embarked"].apply(lambda x:labels.index(x))
train
经过处理之后,结果展示:

模型建立
特征与标签的提取
# 前表示取所有行,后面表示取列 loc里面使用的是字符串,iloc使用的是索引
x=train.loc[:,train.columns!='Survived']
x
特征:

y=train.loc[:,train.columns=='Survived']
y
# 训练与测试数据集的区分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
#恢复索引
for i in [x_train,x_test,y_train,y_test]:
i.index=range(i.shape[0])
模型
决策树
# 建模——使用分类树建模,对训练集拟合,对测试集进行预测评分
clf=DTC(criterion='entropy') #实例化,用训练集数据训练模型
clf.fit(x_train,y_train)#拟合模型
score=clf.score(x_test,y_test)
score #0.7752808988764045
优化模型
import graphviz
from sklearn import tree
dot_data=tree.export_graphviz(clf
,class_names=["存活","死亡"]
,filled=True #树的块填充颜色
,rounded=True #块的框是方圆形
)
graph =graphviz.Source(dot_data)#画出树 ,samples 样本数 ,value根据samples 的占比分配,
[*zip(x.columns,clf.feature_importances_)] #查看特征向量的重要性
from sklearn.model_selection import GridSearchCV #网格搜索
parameters={'criterion':('gini','entropy')
,'splitter':('best','random')
,'max_depth':[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
}
Survived_model=DTC(random_state=25)
gs=GridSearchCV(Survived_model,parameters,cv=10)
gs.fit(x_train,y_train)
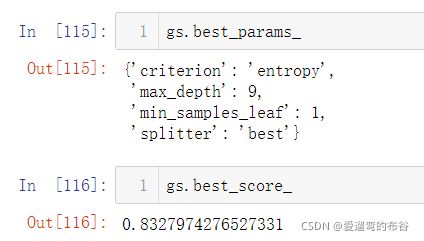
gs.best_params_ #查看最好的参数
gs.best_score_ #查看模型最好的评分
逻辑回归
from sklearn.linear_model import LogisticRegression as LR #逻辑回归
from matplotlib import pyplot as plt
from sklearn.metrics import accuracy_score # 引入比率分数,评估分类的好坏
l2=[]
l2test=[]
for i in np.arange(1,201,10): #生成一个列表
L2=LR(penalty='l2',solver='liblinear',C=0.8,max_iter=i) #最大迭代数 max_iter solver,四个参数,liblinear表示坐标下降法(l1和l2都可以用,小数据l1),sag表示随机梯度下降法(l2可以用,大于10万数据使用),newton-cg、lbfgs表示牛顿法(l2可以用)
L2=L2.fit(x_train,y_train)
l2.append(accuracy_score(L2.predict(x_train),y_train))
l2test.append(accuracy_score(L2.predict(x_test),y_test))
#评估
print(accuracy_score(L2.predict(x_train),y_train))#0.8006430868167203
print(accuracy_score(L2.predict(x_test),y_test)) #0.8014981273408239
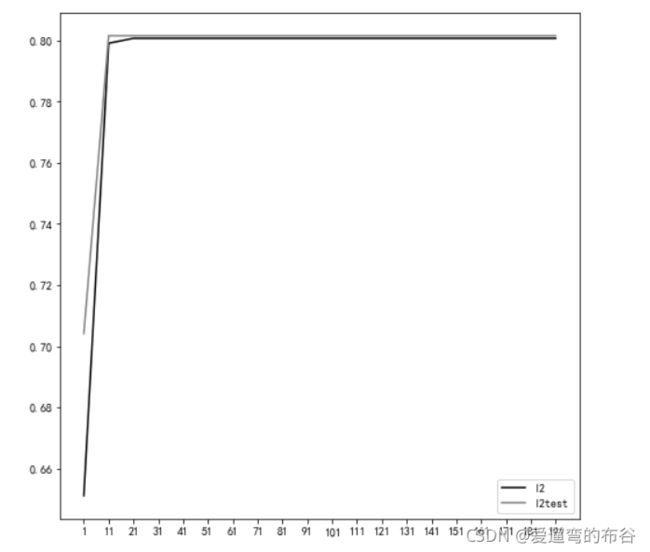
画图:
graph=[l2,l2test]
color=['black','gray']
label=['l2','l2test']
plt.figure(figsize=(8,8))
for i in range(len(graph)):
plt.plot(np.arange(1,201,10),graph[i],color[i],label=label[i])
plt.legend()
plt.xticks(np.arange(1,201,10))
plt.show() #不再变化,说明找到了最优解
人工神经网络
from sklearn.neural_network import MLPClassifier as CNN # 定义多层感知机分类算法
cnn=CNN((100,100))
cnn.fit(x_train,y_train)
print(cnn.score(x_train,y_train)) # 模型在训练集的准确率,训练好的模型在测试集上进行评分(0~1)1分代表最好
y_pre=cnn.predict(x_test)
print(accuracy_score(y_pre,y_test))#accuracy_score()分类准确率分数是指所有分类正确的百分比。模型测试集的准确率
模型评估
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
df=pd.read_csv('./gender_submission.csv',header=0)
df.head()
from sklearn.model_selection import train_test_split
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
Models=[LR,CNN,DTC]
for Model in Models:
model=Model()
model.fit(X_train,y_train)
y_pre=model.predict(X_test)
y_score=model.predict_proba(X_test)
print('score',model.score(X_test,y_test))
#print(y_score)
fpr,tpr,thr = roc_curve(y_test,y_score[:,-1])
plt.plot(fpr,tpr)
plt.show()
print('auc',roc_auc_score(y_test,y_score[:,-1]))
