【LeNet5】简单车牌识别(动态图版)
文章目录
- 问题导入
- 一、基本概念
-
- 1. 动态图DyGraph
- 2. LeNet5模型
- 二、实验数据集
- 三、实验步骤
-
- 0. 导入模块
- 1. 数据准备
- 2. 网络配置
- 3. 模型训练
- 4. 模型评估
- 5. 模型预测
- 写在最后
问题导入
本次实践是一个多分类任务,需要将照片中的每个字符分别进行识别,故我们将借助CV2模块完成对车牌图像逐字符划分,然后训练卷积神经网络模型LeNet5完成对车牌的识别。

一、基本概念
1. 动态图DyGraph
(1)PaddlePaddle动态图:
PaddlePaddle的 动态图DyGraph模式 是一个更加灵活易用的模式,是一种动态的图执行机制,可以立即执行结果,无需构建整个图。PaddlePaddle DyGraph可以提供:
- 更加灵活便捷的代码组织结构:使用python的执行控制流程和面向对象的模型设计
- 更加便捷的调试功能:直接使用python的打印方法即时打印所需要的结果,从而检查正在运行的模型结果便于测试更改
- 和静态执行图通用的模型代码:同样的模型代码可以使用更加便捷的DyGraph调试,执行,同时也支持使用原有的静态图模式执行
(2)动态图机制的优点:
动态图机制不同于以往的静态图,无需构建整个图就可以立即执行结果。这使得我们在编写代码以及调试代码时更加直观、方便,我们无需编写静态图框架,这省去了我们大量的时间成本。利用动态图机制,我们能够更加快捷、直观地构建我们的深度学习网络。
本项目采用的是动态图机制,动态图机制的使用方法请参考:
- 动态图机制-DyGraph - PaddlePaddle文档
- 还不懂动态图吗?一文带你了解飞桨动态图 - CSDN
2. LeNet5模型
LeNet-5 源自Yann LeCun的论文 “Gradient-Based Learning Applied to Document Recognition”,是一种用于手写体字符识别的、结构简单、非常高效的卷积神经网络。

二、实验数据集
实验数据集中有65个文件夹,包含数字 (0-9)、大写字母 (A-Z) 以及各省简称,每个文件夹存放一类图片,所有的图片均为120 * 120像素的灰度图像。

这是数据集的下载链接:车牌识别数据集 - Baidu AI Studio
三、实验步骤

0. 导入模块
import os
import cv2 # 在本项目中,它主要用来分割图像
import shutil
import random
import zipfile
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from multiprocessing import cpu_count
import paddle
from paddle import fluid
from paddle.fluid.dygraph import Conv2D, Pool2D, Linear
1. 数据准备
- 数据预处理
训练/测试数据集包含车牌中出现的所有字符的图片,本次实验将取其中的90%作为训练集,剩下的10%作为测试集。数据预处理的流程如下:
(1)由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
(2)接着,我们需要按1:9比例划分测试集和训练集,分别生成包含数据地址的两个列表。
(3)然后,我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
def unzip_data(target_path): # 将原数据集解压至指定路径
src_path = "./data/data23617/characterData.zip"
if not os.path.isdir(target_path):
z = zipfile.ZipFile(src_path, 'r') # 打开Zip文件,创建Zip对象
z.extractall(path=target_path) # 解压Zip文件至target_path
shutil.rmtree("./data/dataset/__MACOSX") # 删除无关文件
z.close()
print("数据集解压完成!")
def data_mapper(sample): # 对图片进行预处理
img_path, label = sample
img = Image.open(img_path).convert("L") # 将图像打开并转为灰度图
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).reshape(1, 1, 32, 32)\
.astype('float32') # 把图像变成numpy数组以匹配数据馈送格式
img = img / 255.0 * 2.0 - 1.0 # 将数据归一化到[-1, 1]之间
return img, label
def data_reader(data_list): # 按批量读取图片
def reader():
for data in data_list:
img_path, label = data[0], data[1]
yield img_path, int(label) # 返回图像路径和标签(for循环结束前程序不会停止)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# ------ 1.1.解压数据集 ------
data_path = "./data/dataset" # 数据集路径
unzip_data(data_path) # 解压原数据集至指定路径
file_folders = os.listdir(data_path) # data_path路径下的文件夹
# ------ 1.2.划分数据集 ------
train_list, test_list = [], [] # 存放训练集和数据集的位置以及类别
char_num, label_dict = 0, {} # 方便字符在整型和字符型之间转换
for folder in file_folders:
label_dict[str(char_num)] = folder # 记录标签和代号的对应关系
images = os.listdir(os.path.join(data_path, folder))
for idx, img in enumerate(images):
img_path = os.path.join(data_path, folder, img)
value = [img_path, char_num]
if idx % 10 == 0: # 按照1:9的比例划分数据集
test_list.append(value)
else:
train_list.append(value)
char_num += 1
random.shuffle(train_list) # 打乱训练集数据
random.shuffle(test_list) # 打乱测试集数据
# ------ 1.3.准备训练数据集 ------
BUF_SIZE, BATCH_SIZE = 512, 128
train_reader = paddle.batch(
paddle.reader.shuffle(
data_reader(train_list), buf_size=BUF_SIZE
), # 每次缓存BUF_SIZE个训练数据项,并打乱
batch_size=BATCH_SIZE
) # 按批次读取乱序后的训练数据,批次大小为BATCH_SIZE
# ------ 1.4.准备测试数据集 ------
test_reader = paddle.batch(
data_reader(test_list), batch_size=BATCH_SIZE
) # 按批次读取测试数据,批次大小为BATCH_SIZE
2. 网络配置
class MyLeNet(fluid.dygraph.Layer): # 构建CNN模型类
def __init__(self):
super(MyLeNet, self).__init__()
self.c1 = Conv2D( # 定义一个卷积层
num_channels=1, # 输入的通道数
num_filters=6, # 卷积核的个数
filter_size=5, # 卷积核的大小
stride=1 # 卷积层的步长
)
self.s2 = Pool2D( # 定义一个池化层
pool_size=2, # 池化核的大小
pool_type="max", # 池化类型:“max” or “avg”
pool_stride=2 # 池化层的步长
)
self.c3 = Conv2D(6, 16, 5, 1)
self.s4 = Pool2D(2, "max", 2)
self.c5 = Conv2D(16, 120, 5, 1)
self.f6 = Linear(120, 84, act="relu")
self.output = Linear(84, char_num, act="softmax")
def forward(self, input):
x = self.c1(input) # 输出维度为28*28*6
x = self.s2(x) # 输出维度为14*14*6
x = self.c3(x) # 输出维度为10*10*6
x = self.s4(x) # 输出维度为5*5*16
x = self.c5(x) # 输出维度为120
x = fluid.layers.reshape(x, shape=[-1, 120])
x = self.f6(x) # 输出维度为84
y = self.output(x) # 输出维度为10
return y
3. 模型训练
EPOCH_NUM, train_iter = 25, 0
train_iters, train_costs, train_accs = [], [], []
def draw_training_loss(iters, costs): # 绘制训练误差图像
plt.figure(figsize=[10, 5])
plt.title("Training Loss", fontsize=25)
plt.xlabel("iter", fontsize=18)
plt.ylabel("loss", fontsize=18)
plt.plot(iters, costs, color="r")
plt.grid()
plt.show()
def draw_training_acc(iters, accs): # 绘制训练准确率图像
plt.figure(figsize=[10, 5])
plt.title("Training Accuracy", fontsize=25)
plt.xlabel("iter", fontsize=18)
plt.ylabel("accuracy", fontsize=18)
plt.plot(iters, accs, color="g")
plt.grid()
plt.show()
with fluid.dygraph.guard(): # 使用动态图进行模型训练
model = MyLeNet() # 模型实例化
model.train() # 开启训练模式
opt = fluid.optimizer.AdamOptimizer(
learning_rate=fluid.dygraph.ExponentialDecay(
learning_rate=0.001, # 初始学习率
decay_steps=750, # 学习率衰减步长
decay_rate=0.25, # 学习率衰减率
staircase=True # 每decay_steps步学习率衰减为原来的decay_rate
), # 学习率呈现指数衰减
parameter_list=model.parameters()
) # 定义优化器,采用Adam优化算法
for pass_id in range(EPOCH_NUM): # 训练EPOCH_NUM轮
for batch_id, data in enumerate(train_reader()):
# 将数据集中的图像、标签数据转化为numpy.array格式的数据:
image = np.array([x[0].reshape(1, 32, 32) for x in data], np.float32)
label = np.array([x[1] for x in data]).astype("int64")
label = label[:, np.newaxis] # 在label中增加一维维度
# 将数据转化为fluid.dygraph能够接受的Variable类型的对象:
image = fluid.dygraph.to_variable(image)
label = fluid.dygraph.to_variable(label)
predict = model(image) # 训练模型
train_loss = fluid.layers.cross_entropy(predict, label) # 计算交叉熵
avg_loss = fluid.layers.mean(train_loss) # 求平均损失值
train_acc = fluid.layers.accuracy(predict, label) # 计算准确率
train_iter += BATCH_SIZE
train_iters.append(train_iter) # 迭代次数
train_costs.append(avg_loss.numpy()[0]) # 训练误差
train_accs.append(train_acc.numpy()[0]) # 训练准确率
if batch_id != 0 and batch_id % 110 == 0:
print("Pass:%3d;Batch:%2d;Loss:%.5f;Accuracy:%.5f" %
(pass_id, batch_id, train_costs[-1], train_accs[-1]))
avg_loss.backward() # 执行反向传播算法
opt.minimize(avg_loss) # 调用优化器中的minimize()方法更新参数
model.clear_gradients() # 每轮参数更新后需重置梯度,以确保下轮的正确性
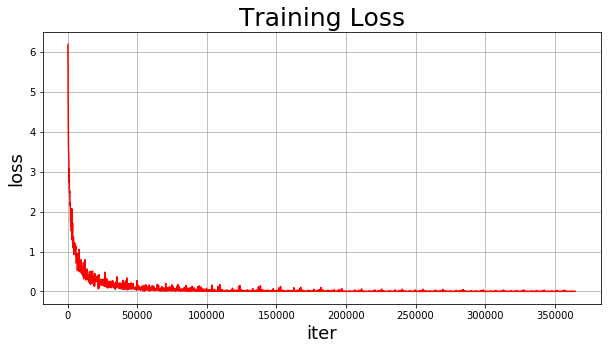
draw_training_loss(train_iters, train_costs) # 绘制训练损失值图像
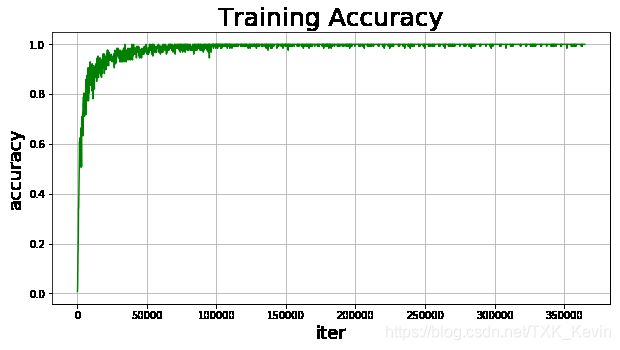
draw_training_acc(train_iters, train_accs) # 绘制训练准确率图像
fluid.save_dygraph(model.state_dict(), "MyLeNet") # 保存训练好的模型
模型训练结果如下:
Pass: 0;Batch:110;Loss:0.34848;Accuracy:0.89844
Pass: 1;Batch:110;Loss:0.13844;Accuracy:0.96875
Pass: 2;Batch:110;Loss:0.08487;Accuracy:0.96875
Pass: 3;Batch:110;Loss:0.07444;Accuracy:0.98438
Pass: 4;Batch:110;Loss:0.05620;Accuracy:0.99219
Pass: 5;Batch:110;Loss:0.07430;Accuracy:0.98438
Pass: 6;Batch:110;Loss:0.03116;Accuracy:0.99219
Pass: 7;Batch:110;Loss:0.01135;Accuracy:1.00000
Pass: 8;Batch:110;Loss:0.00264;Accuracy:1.00000
Pass: 9;Batch:110;Loss:0.00669;Accuracy:1.00000
Pass: 10;Batch:110;Loss:0.00272;Accuracy:1.00000
Pass: 11;Batch:110;Loss:0.00407;Accuracy:1.00000
Pass: 12;Batch:110;Loss:0.01096;Accuracy:1.00000
Pass: 13;Batch:110;Loss:0.00288;Accuracy:1.00000
Pass: 14;Batch:110;Loss:0.00631;Accuracy:1.00000
Pass: 15;Batch:110;Loss:0.00285;Accuracy:1.00000
Pass: 16;Batch:110;Loss:0.00256;Accuracy:1.00000
Pass: 17;Batch:110;Loss:0.00322;Accuracy:1.00000
Pass: 18;Batch:110;Loss:0.00195;Accuracy:1.00000
Pass: 19;Batch:110;Loss:0.00297;Accuracy:1.00000
Pass: 20;Batch:110;Loss:0.00217;Accuracy:1.00000
Pass: 21;Batch:110;Loss:0.00373;Accuracy:1.00000
Pass: 22;Batch:110;Loss:0.00482;Accuracy:1.00000
Pass: 23;Batch:110;Loss:0.00120;Accuracy:1.00000
Pass: 24;Batch:110;Loss:0.00188;Accuracy:1.00000
4. 模型评估
with fluid.dygraph.guard(): # 使用动态图进行模型测试
test_costs, test_accs = [], []
model = MyLeNet() # 模型实例化
model_dict, _ = fluid.load_dygraph("MyLeNet") # 加载模型参数
model.load_dict(model_dict) # 将模型参数载入到新模型中
model.eval() # 开启评估模式
for batch_id, data in enumerate(test_reader()):
# 将数据集中的图像、标签数据转化为特定numpy数组格式的数据:
image = np.array([x[0].reshape(1, 32, 32) for x in data], np.float32)
label = np.array([x[1] for x in data]).astype("int64")[:, np.newaxis]
# 将数据转化为fluid.dygraph能够接受的Variable类型的对象:
image = fluid.dygraph.to_variable(image)
label = fluid.dygraph.to_variable(label)
predict = model(image) # 模型测试
test_loss = fluid.layers.cross_entropy(predict, label) # 计算交叉熵
avg_loss = fluid.layers.mean(test_loss) # 计算平均损失值
test_costs.append(avg_loss.numpy()[0])
test_acc = fluid.layers.accuracy(predict, label) # 计算准确率
test_accs.append(test_acc.numpy()[0])
test_loss = np.mean(test_costs) # 计算平均损失值
test_acc = np.mean(test_accs) # 计算平均准确率
print("Eval \t Avg_Loss:%.5f;Accuracy:%.5f" % (test_loss, test_acc))
模型评估结果如下:
Eval Avg_Loss:0.12136;Accuracy:0.98006
5. 模型预测
- 预测图片预处理
由于车牌图片是由多个字符构成的RGB模式的图片,因此在进行预测之前需要将车牌图片转化为灰度图并按字符划分子图像,以便于模型逐字符进行预测。
def load_image(path): # 图像整体预处理
img = Image.open(path).convert("L") # 将图像打开并转为灰度图
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).reshape(1, 1, 32, 32)\
.astype('float32') # 把图像变成numpy数组以匹配数据馈送格式
img = img / 255.0 * 2.0 - 1.0 # 将数据归一化到[-1, 1]之间
return img
def divide_picture(path): # 分割出车牌图像中的每一个字符并保存
# (1) 图片灰度化处理:
license = cv2.imread(path)
gray_img = cv2.cvtColor(license, cv2.COLOR_RGB2GRAY) # 将车牌转化为灰度图
retval, bin_img = cv2.threshold( # 进行图像二值化操作
gray_img, 100, 255, cv2.THRESH_BINARY # 源图片、起始阈值、最大阈值、阈值类型
) # 函数返回值:retval是阈值;bin_img是根据阈值处理后的图像
# (2) 按列统计像素分布:
result = []
for col in range(bin_img.shape[1]):
result.append(0)
for row in range(bin_img.shape[0]):
result[col] += bin_img[row][col] / 255.0 # 统计归一化后的像素分布
# (3) 记录车牌中的字符的位置:
place_dict, num, i = {}, 0, 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
place_dict[num] = [i, index-1]
num += 1
i = index
# (4) 将每个字符填充并存储:
characters = []
for i in range(8):
if i == 2: # 跳过蓝牌中的“•”号
continue
padding = (170 - (place_dict[i][1] - place_dict[i][0])) / 2
ndarray = np.pad( # 将单个字符图像填充为170*170
bin_img[:, place_dict[i][0]: place_dict[i][1]],
((0, 0), (int(padding), int(padding))),
"constant",
constant_values=(0, 0)
)
ndarray = cv2.resize(ndarray, (20, 20))
cv2.imwrite("./data/%d.png" % i, ndarray) # 保存划分后的单字符图片
characters.append(ndarray)
def match_labels(label_dict): # 返回将标签进行转换的字典
temp = {'A': 'A', 'B': 'B', 'C': 'C', 'D': 'D', 'E': 'E', 'F': 'F', 'G': 'G',
'H': 'H', 'I': 'I', 'J': 'J', 'K': 'K', 'L': 'L', 'M': 'M', 'N': 'N',
'O': 'O', 'P': 'P', 'Q': 'Q', 'R': 'R', 'S': 'S', 'T': 'T', 'U': 'U',
'V': 'V', 'W': 'W', 'X': 'X', 'Y': 'Y', 'Z': 'Z', '0': '0', '1': '1',
'2': '2', '3': '3', '4': '4', '5': '5', '6': '6', '7': '7', '8': '8',
'9': '9', 'yun': '云', 'cuan': '川', 'hei': '黑', 'zhe': '浙',
'ning': '宁', 'jin': '津', 'gan': '赣', 'hu': '沪', 'liao': '辽',
'jl': '吉', 'qing': '青', 'zang': '藏', 'e1': '鄂', 'meng': '蒙',
'gan1': '甘', 'qiong': '琼', 'shan': '陕', 'min': '闽', 'su': '苏',
'xin': '新', 'wan': '皖', 'jing': '京', 'xiang': '湘', 'gui': '贵',
'yu1': '渝', 'yu': '豫', 'ji': '冀', 'yue': '粤', 'gui1': '桂',
'sx': '晋', 'lu': '鲁'} # 本次转换的目的是转换字母和汉字
name_dict = {}
for key, val in label_dict.items():
name_dict[key] = temp[val]
return name_dict
with fluid.dygraph.guard():
model = MyLeNet() # 实例化模型
model_dict, _ = fluid.load_dygraph("MyLeNet") # 加载模型参数
model.load_dict(model_dict) # 将模型参数载入到新模型中
model.eval() # 开启评估模式
infer_label = "" # 存储预测结果
infer_path = "./work/infer_license.png" # 预测图片的路径
divide_picture(infer_path) # 按车牌字符划分图片
name_dict = match_labels(label_dict) # 获取转换标签的字典
for i in range(8):
if i == 2: # 跳过蓝牌中的“•”号
infer_label += "•"
continue
char_img = load_image("./data/%d.png" % i)
# 将数据转化为fluid.dygraph能够接受的Variable类型的对象:
char_img = fluid.dygraph.to_variable(char_img)
result = model(char_img) # 模型预测,返回一个概率数组
lab = np.argmax(result.numpy()) # 返回数组result中的最大值的索引值
infer_label += name_dict[str(lab)] # 将字符的预测结果加入到总结果中
display(Image.open(infer_path)) # 展示预测车牌
print("\n该车牌的预测结果为:", infer_label) # 展示预测结果
模型预测结果如下:
该车牌的预测结果为: 苏A•UP678

写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - Baidu AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - Baidu AI Studio,来AI Studio互粉吧,等你哦~