目标检测经典算法和API详解(笔记)
文章目录
- 商品目标检测
- 1. 目标检测概述
-
- 1.1.项目演示介绍
-
- 学习目标
- 1.1.1 项目演示
- 1.1.2 项目结构
- 1.1.3 项目安排
- 1.2 图像识别背景
-
- 学习目标
- 1.2.1 图像识别三大任务
- 1.2.2 图像识别的发展
- 1.3 什么是目标检测
-
- 学习目标
- 1.3.2 目标检测定义
- 1.3.2 目标检测的技术发展史
- 1.4 目标检测的应用场景
- 1.5. 开发环境搭建
- 2. 目标检测算法原理
-
- 2.1 目标检测任务描述目标
-
- 2.1.1 目标检测算法分类
- 2.1.2 目标检测的任务
-
- 2.1.2.1 分类原理回顾
- 2.1.2.2 检测的任务
- 2.1.2.3 两种Bounding box名称
- 2.1.2.4 检测的评价指标
- 2.1.4 目标定位的简单实现
-
- 2.1.4.1 回归位置
- 2.1.4.2 位置数值的处理
- 2.2 R-CNN
-
- 2.2.1 目标检测-Overfeat模型
-
- 2.2.1.1 滑动窗口
- 2.2.1.2 训练数据集
- 2.2.1.3 Overfeat模型总结
- 2.2.2 目标检测-R-CNN模型
-
- 2.2.2.1 完整R-CNN结构
- 2.2.2.2 候选区域(了解)
- 2.2.2.3 Crop + Warp (了解)
- 2.2.2.4 CNN网络提取特征
- 2.2.2.5 特征向量训练分类器SVM(二分类)
- 2.2.2.6 非极大抑制(NMS)
- 2.2.2.2 修正候选区域
- 2.2.3 R-CNN训练过程
-
- 2.2.3.1 正负样本准备
- 2.2.3.2 预训练(pre-training)
- 2.2.3.3 微调(fine-tuning):等于迁移学习
- 2.2.3.4 SVM分类器
- 2.2.3.5 bbox回归器训练
- 2.2.4 R-CNN测试过程
- 2.2.5 R-CNN总结
-
- 2.2.5.2 缺点
- 2.2.6 总结与掌握
- 2.2.7 问题?
- 2.3 SPPNet
-
- 2.3.1 SPPNet
-
- 2.3.1.1 映射
- 2.3.1.2 spatial pyramid pooling
- 2.3.2 SPPNet总结
- 2.3.3 总结
- 2.3.4 问题?
- 3.4 Fast R-CNN
-
- 3.4.1 Fast R-CNN相对于R-CNN改进的部分
-
- 2.4.1.1 RoI pooling首先RoI pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。
- 2.4.1.3 End-to-End model
- 2.4.2 多任务损失-Multi-task loss
- 3.4.3 R-CNN、SPPNet、Fast R-CNN效果对比
- 2.4.4 Fast R-CNN总结
- 2.4.5 总结
- 2.5 Faster R-CNN
-
- 2.5.1 Faster R-CNN
- 2.5.2 RPN原理
-
- 2.5.2.1 anchors
- 2.5.2.2 候选区域的训练
- 2.5.3 Faster R-CNN的训练
- 2.5.4 效果对比
- 2.5.5 Faster R-CNN总结
- 2.5.7 问题?
- 2.6 YOLO(You only look once)
-
- 2.6.1 YOLO
-
- 2.6.1.1 结构
- 2.6.1.2 流程理解
- 2.6.2 单元格(grid cell)
-
- 2.6.2.1 网格输出筛选
- 2.6.3 非最大抑制(NMS)
- 2.6.4 训练
- 2.6.5 与Faster R-CNN比较
- 2.6.6 YOLO总结
- 2.7 SSD(Single Shot MultiBox Detector)
-
- 2.7.1 SSD
-
- 2.7.1.1 简介
- 2.7.1.2 结构
- 2.7.1.3 流程
- 2.7.1.4 Detector & classifier
- 2.7.1.4.1 default boxes
- 2.7.1.4.2 localization与confidence
- 2.7.2 训练与测试流程
-
- 2.7.2.1 train流程
- 2.7.2.2 test流程
- 2.7.3 比较
- 2.7.4 总结
- 2.8 TensorFlowSSD接口
-
-
- 2.8.1.1 网络配置
- 2.8.2 接口介绍
-
- 2.8.2.1 模型搭建处理:
- 2.8.2.2 定义网络的损失:
-
- 总结(树状图)
- 3.数据集处理
-
- 3.1. 目标检测数据集
-
- 3.1.1 常用目标检测数据集
- 3.1.2 pascal voc数据集介绍
- 3.1.3 XML
- 3.2 目标数据集标记
-
- 3.2.1 数据集标记工具介绍
-
- 2.2.1.1 介绍
- 3.2.1.2 安装
- 3.2.2 商品数据集标记
-
- 3.2.2.1 需求介绍
- 3.2.2.2 标记
- 3.2.3 总结
- 3.2.4 问题
- 3.3 数据集格式转换
-
- 3.3.2 TFRecords文件
- 3.3.3 案例:VOC2007数据集转换
-
- 3.3.3.1 转换效果显示
- 3.3.3.2 TensorFlow API
- 3.3.3.2 转换步骤
- 3.3.3.3 代码
- 3.3.4 总结
- 名词解释链接
商品目标检测
1. 目标检测概述
1.1.项目演示介绍
学习目标
- 了解项目的演示结果
1.1.1 项目演示
项目已经部署上线,Web端+小程序端演示
1.1.2 项目结构

1.1.3 项目安排
- 第一阶段:算法模型
。RCNN以及相关算法
。YOLO与SSD
。算法接口介绍 - 第二阶段:数据集处理
。 数据集标记格式
。 数据集存储与读取 - 第三阶段:项目实现
。 数据接口实现
。 模型接口实现
。 训练、设备部署逻辑实现
。 测试接口
。 TensorFlow serving部署模型
。 Web server+TensorFlow serving Client
。 小程序
1.2 图像识别背景
学习目标
- 目标
。了解图像识别的三大任务
。 图像识别的两种模式
1.2.1 图像识别三大任务
-
目标识别:或者说分类,定性目标,确定目标是什么(图a)
-
目标检测:
定位目标,确定目标是什么以及位置(图b) -
目标分割:像素级的对前景与背景进行分类,将背景剔除(图c,图d)
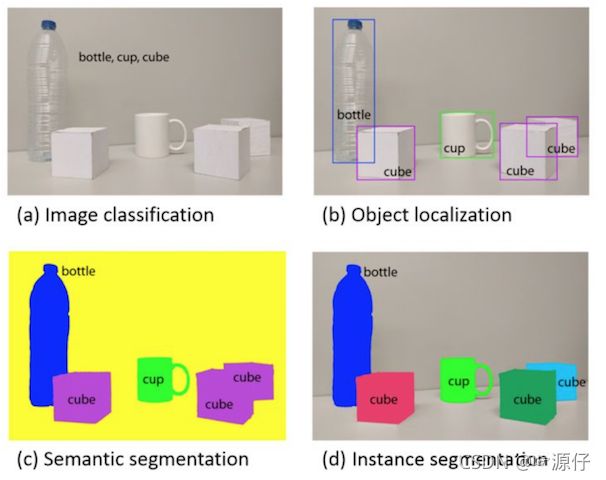
目标检测:技术成熟并且使用更多的场景
目标分割:适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
1.2.2 图像识别的发展
- 通用场景
谷歌、微软、Meta、百度、阿里巴巴在内的科技巨头都花费了大量的人力财力做研究,搭建了很多图像识别的平台。
- 垂直场景
。 医疗领域:医疗影像的检测
。 林木产业:木板树种检测识别
垂直应用场景里的行业特质挖掘和经验积累往往会被忽视,所以在垂直领域的行业中大量的公司正在开发相当多的图像应用。
1.3 什么是目标检测
学习目标
- 目标
。 知道目标检测的定义
。 了解目标检测的技术发展历史
1.3.2 目标检测定义
识别图片中有哪些物体以及物体的位置(坐标位置)

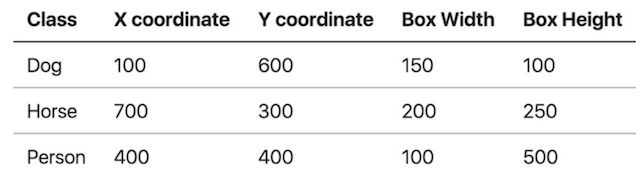
目标检测的位置信息一般由两种格式(以图片左上角为原点(0,0)):
- 极坐标表示:(xmin, ymin, xmax, ymax)
。 xmin,ymin:x,y坐标的最小值
。 xmax,ymax:x,y坐标的最大值 - 中心点坐标:(x_center, y_center, w, h)
。 x_center, y_center:目标检测框的中心点坐标
。 w,h:目标检测框的宽、高
假设这个图像是1000x800,所有这些坐标都是构建在像素层面上:

中心点坐标结果如下:
1.3.2 目标检测的技术发展史
- 传统目标检测方法(候选区域+手工特征提取+分类器)
。 HOG+SVM、DPM - region proposal+CNN提取分类的目标检测框架
。 (R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN) - 端到端(End-to-End)的目标检测框架
YOLO、SSD
1.4 目标检测的应用场景
-
公安行业的应用
公安行业用户的迫切需求是在海量的视频信息中,发现犯罪嫌疑人的线索。人工智能在视频内容的特征提取、内容理解方面有着天然的优势。可实时分析视频内容,检测运动对象,识别人、车属性信息,并通过网络传递到后端人工智能的中心数据库进行存储。 -
农作物的应用
。 农业中农作物表面的病虫害识别也需要用到目标检测技术

-
医疗影像检测
人工智能在医学中的应用目前是一个热门的话题,医学影像图像中病变部位检测和识别对于诊断的自动化,提供优质的治疗具有重要的意义。 -
电商行业的应用
电商行业中充满无数的商品,利用检测功能查询相关商品,快速找到用户需要的商品类型或者品牌类别,从而提高电商领域的用户满意度 -
道路检测

-
动物检测
-
商品检测
-
车牌检测
-
菜品检测

-
车型检测
1.5. 开发环境搭建
安装GPU版本的Tensorflow
2. 目标检测算法原理
了解目标检测算法分类
知道目标检测的常见指标IoU
了解目标定位的简单实现方式
了解Overfeat模型的移动窗口方法
说明R-CNN的完整结构过程
了解选择性搜索
了解Crop+Warp的作用
知道NMS的过程以及作用
了解候选区域修正过程
说明R-CNN的训练过程
说明R-CNN的缺点
说明SPPNet的特点
说明SPP层的作用
了解Fast R-CNN的结构特点
说明RoI的特点
了解多任务损失
了解Faster R-CNN的特点
知道RPN的原理以及作用
知道YOLO的网络结构
知道单元格的意义
知道YOLO的损失
知道SSD的结构
说明Detector & classifier的作用
说明SSD的优点
知道TensorFlow的SSD接口意义
2.1 目标检测任务描述目标
- 了解目标检测算法分类
- 知道目标检测的常见指标IoU
- 了解目标定位的简单实现方式
2.1.1 目标检测算法分类
-
两步走的目标检测:先进行区域推荐,而后进行目标分类
代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN -
端到端的目标检测:采用一个网络一步到位
代表:YOLO、SSD

2.1.2 目标检测的任务
2.1.2.1 分类原理回顾
先来回归下分类的原理,这是一个常见的CNN组成图,输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果

- 分类的损失与优化
在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失

- 常见的CNN模型

对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程: - 分类 :
是得到每个类别的概率,比较得到最大概率
。 softmax进行计算概率,交叉熵损失衡量

- 分类+定位 (只有 一个对象的时候)

- 目标检测
2.1.2.2 检测的任务
- 分类:
N个类别
输入:图片
输出:类别标签
评估指标:Accuracy

- 定位:
N个类别
输入:图片
输出:物体的位置坐标
主要评估指标:IOU

其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox).
2.1.2.3 两种Bounding box名称
在目标检测当中,对bbox主要由两种类别。
- Ground-truth bounding box:图片当中真实标记的框
- Predicted bounding box:预测的时候标记的框
一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
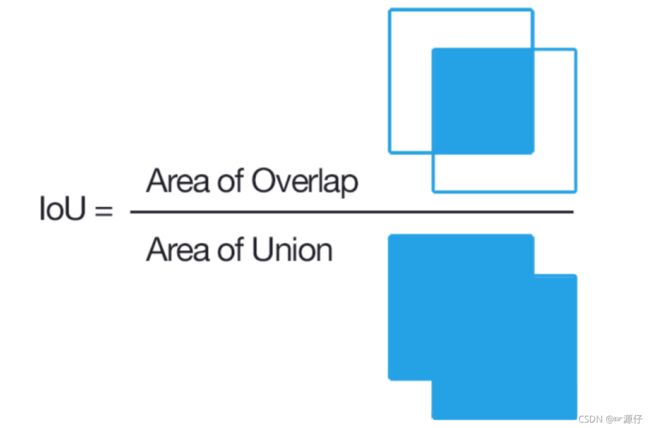
2.1.2.4 检测的评价指标
| 任务 | description | 输入 | 输出 | 评价标准 |
|---|---|---|---|---|
| Detection and Localization (检测和定位) | 在输入图片中找出存在的物体类别和位置(可能存在多种物体) | 图片(image ) | 类别标签(categories)和 位置(bbox(x,y,w,h)) | IoU (Intersection over Union) mAP (Mean Average Precision) |
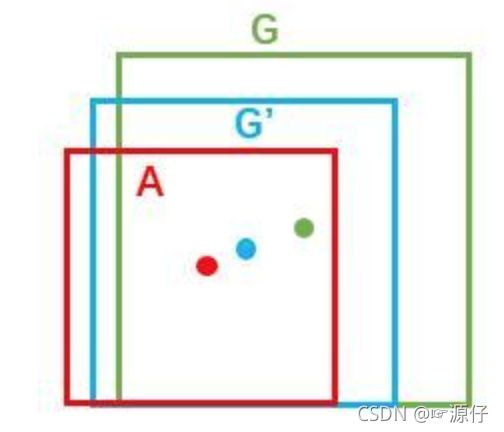
- IoU(交并比)
两个区域的重叠程度overlap:侯选区域和标定区域的IoU值
2.1.4 目标定位的简单实现
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
2.1.4.1 回归位置
增加一个全连接层,即为FC1、FC2
-
FC1:作为类别的输出
-
FC2:作为这个物体位置数值的输出
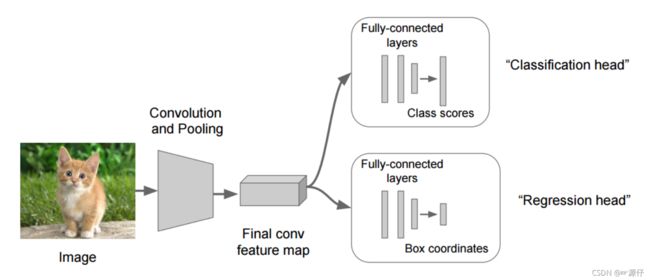
假设有10个类别,输出[p1,p2,p3,…,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失 -
对于分类的概率,还是使用交叉熵损失
-
位置信息具体的数值,可使用MSE均方误差损失(L2损失)
如下图所示:为什么输出两个全连接层?
- 让网络多输出一个全连接层。
- 第一个全连接层是输出概率值
- 第二个全连接层是输出四个位置目标(回归算法输出)
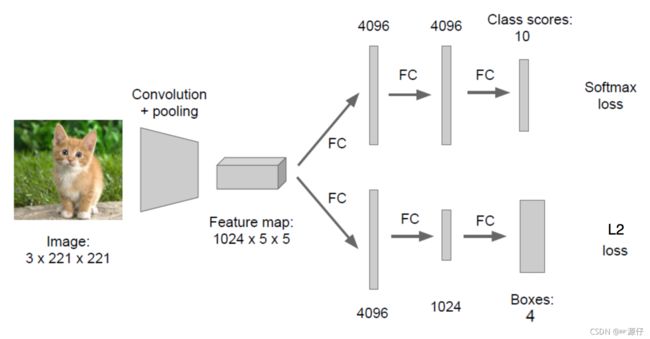
2.1.4.2 位置数值的处理
对于输出的位置信息是四个比较大的像素大小值,在回归的时候不适合。目前统一的做法是,每个位置除以图片本身像素大小。
假设以中心坐标方式,那么x = x / x_image, y / y_image, w / x_image, h / y_image,也就是这几个点最后都变成了0~1之间的值(归一化)。
2.2 R-CNN
目标:
- 了解Overfeat模型的移动窗口方法
- 说明R-CNN的完整结构过程
- 了解选择性搜索
- 了解Crop+Warp的作用
- 知道NMS的过程以及作用
- 了解候选区域修正过程
- 说明R-CNN的训练过程
- 说明R-CNN的缺点
对于一张图片当中多个目标,多个类别的时候。前面的输出结果是不定的,有可能是以下有四个类别输出这种情况。或者N个结果,这样的话,网络模型输出结构不定

所以需要一些他的方法解决目标检测(多个目标)的问题,试图将一个检测问题简化成分类问题
2.2.1 目标检测-Overfeat模型
2.2.1.1 滑动窗口
目标检测的暴力方法是从左到右、从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。如下图所示:

这样就变成每张子图片输出类别以及位置,变成分类问题。但是滑动窗口需要初始设定一个固定大小的窗口,这就遇到了一个问题,有些物体适应的框不一样,所以需要提前设定K个窗口,每个窗口滑动提取M个,总共K x M 个图片,通常会直接将图像变形转换成固定大小的图像,变形图像块被输入 CNN 分类器中,提取特征后,我们使用一些分类器识别类别和该边界框的另一个线性回归器。
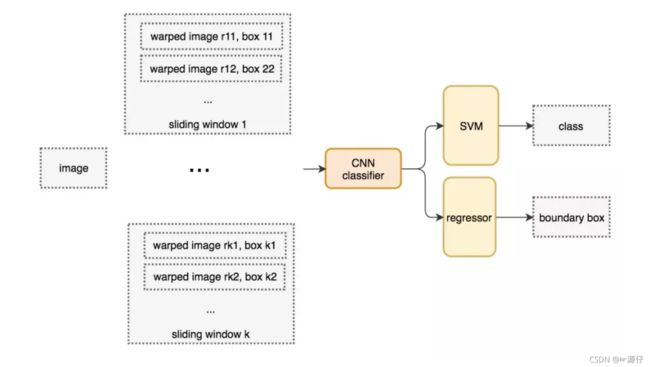
2.2.1.2 训练数据集
首先我们会准备所需要的训练集数据,每张图片的若干个子图片以及每张图片的类别位置,如下我们从某张图片中滑动出的若干的图片。

2.2.1.3 Overfeat模型总结
这种方法类似一种暴力穷举的方式,会消耗大量的计算力量,并且由于窗口大小问题可能会造成效果不准确。但是提供了一种解决目标检测问题的思路
- 滑动窗口:提供K种滑动窗口,每个滑动窗口产生M个子图。
- 再对每个子图进行分类、回归
2.2.2 目标检测-R-CNN模型
在CVPR 2014年中Ross Girshick提出R-CNN。
2.2.2.1 完整R-CNN结构
不使用暴力方法,而是用候选区域方法(region proposal method),用的是SS(选择性搜索)方法 ,创建目标检测的区域改变了图像领域实现物体检测的模型思路,R-CNN是以深度神经网络为基础的物体检测的模型 ,R-CNN在当时以优异的性能令世人瞩目,以R-CNN为基点,后续的SPPNet、Fast R-CNN、Faster R-CNN模型都是照着这个物体检测思路。
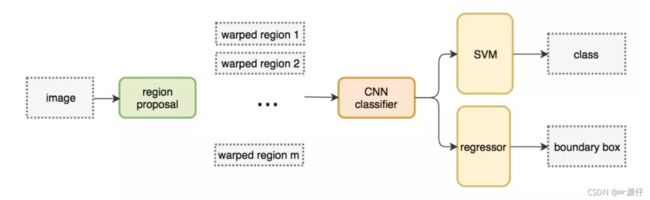
- 步骤(以AlexNet网络为基准)
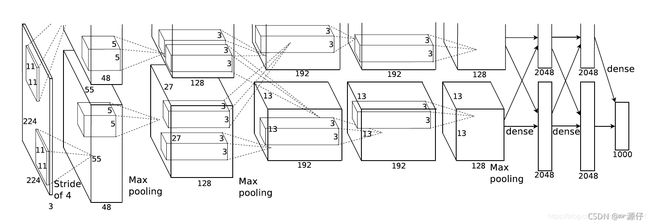
1. 找出图片中可能存在目标的侯选区域region proposal(采用选择性搜索SS的方法)
2 进行图片大小调整为了适应AlexNet网络的输入图像的大小227×227,通过CNN对候选区域提取特征向量,2000个建议框的CNN特征组合成2000×4096维矩阵
3. 将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘(20种分类,SVM是二分类器,则有20个SVM),获得2000×20维矩阵
4. 分别对2000×20维矩阵中每一列即每一类进行非极大值抑制(NMS:non-maximum suppression)剔除重叠建议框,得到该列即该类中得分最高的一些建议框
5. 修正bbox,对bbox做回归微调
2.2.2.2 候选区域(了解)

选择性搜索(SelectiveSearch,SS)中
,首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。
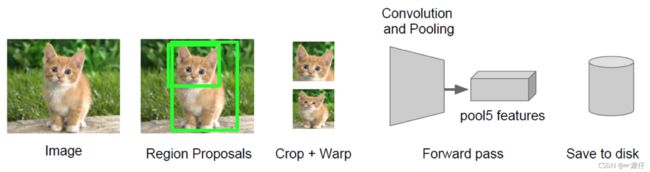
SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
2.2.2.3 Crop + Warp (了解)
传统的CNN限制了输入必须固定大小,所以在实际使用中往往需要对原图片进行crop或者warp(图片大小的调整)的操作
- crop:截取原图片的一个固定大小的patch
- warp:将原图片的ROI缩放到一个固定大小的patch
以上两个步骤可以减少图片的变形(减小市失真),并统一图片的大小
无论是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中。会使用一些方法尽量让图片保持最小的变形。
-
1.各向异性缩放:即直接缩放到指定大小,这可能会造成不必要的图像失真
-
2.各向同性缩放:在原图上出裁剪侯选区域, (采用侯选区域的像素颜色均值)填充到指定大小在边界用固定的背景颜色

2.2.2.4 CNN网络提取特征
- CNN网络提取特征,得出2000个特征向量
- 使用AlexNet结构,输入图片要去227*227
- 提取出的特征会保存在磁盘中
- 提取出(2000,4096)个特特征
在侯选区域的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步的分类器、回归的输入数据。
2.2.2.5 特征向量训练分类器SVM(二分类)
SVM分类对2000个候选区域分类,分类出的是目标和背景,两种类型 。如果第一个SVM是对猫分类,分类出要么是猫,要么是背景。得出2000*20的得分矩阵
假设一张图片的2000个侯选区域,那么提取出来的就是2000 x 4096这样的特征向量(R-CNN当中默认CNN层输出4096特征向量)。那么最后需要对这些特征进行分类,R-CNN选用SVM进行二分类。假设检测N个类别,那么会提供20个不同类别的SVM分类器,每个分类器都会对2000个候选区域的特征向量分别判断一次,这样得出[2000, 20]的得分矩阵,如下图所示

每个SVM分类器做的事情
判断2000个候选区域是某类别,还是背景
2.2.2.6 非极大抑制(NMS)
- 目的
筛选候选区域,得到最终候选区域结果 - 迭代过程
对于所有的2000个候选区域得分进行概率筛选
然后对剩余的候选框,每个类别进行IoU(交并比)>= 0.5 筛选
假设现在滑动窗口有:A、B、C、D、E 5个候选框, - 得分(score)是
指从SVM种输出的概率 - 第一轮:假设B是得分最高的,与B的IoU>0.5删除。现在与B计算IoU,DE结果>0.5,剔除DE,B作为一个预测结果
- 第二轮:AC中,A的得分最高,与A计算IoU,C的结果>0.5,剔除C,A作为一个结果
最终结果为在这个5个中检测出了两个目标为A和B
2.2.2.2 修正候选区域
- 通过线性回归,特征值是候选区域,目标是对应的Ground-Truth。
- 建立回归方程修正参数
那么通过 NMS 筛选出来的候选框不一定就非常准确怎么办?R-CNN提供了这样的方法,建立一个bbox regressor - 回归用于修正筛选后的候选区域,使之回归于ground-truth,默认认为这两个框之间是线性关系,因为在最后筛选出来的候选区域和ground-truth很接近了
修正过程(线性回归)

- 给定:anchor A=(A_{x}, A_{y}, A_{w}, A_{h}) 和 GT=[G_{x}, G_{y}, G_{w}, G_{h}]
- 寻找一种变换F,使得:
 ,其中
,其中

2.2.3 R-CNN训练过程
R-CNN的训练过程这些部分,正负样本准备+预训练+微调网络+训练SVM+训练边框回归器
2.2.3.1 正负样本准备
对于训练集中的所有图像,采用selective search方式来获取,最后每个图像得到2000个region proposal。但是每个图像不是所有的候选区域都会拿去训练。保证正负样本比例1:3.
| 样本 | 描述 |
|---|---|
| 正样本 | 某个region proposal和当前图像上的所有ground truth中重叠面积最大的那个的IOU大于等于0.5,则该region proposal作为这个ground truth类别的正样本 |
| 负样本 | 某个region proposal和当前图像上的所有ground truth中重叠面积最大的那个的IOU都小于0.5,则该region proposal作为这个ground truth类别的负样本 |
这样得出若干个候选区域以及对应的标记结果。
2.2.3.2 预训练(pre-training)
CNN模型层数多,模型的容量大,通常会采用2012年的著名网络AlexNet来学习特征,包含5个卷积层和2个全连接层,利用大数据集训练一个分类器,比如著名的ImageNet比赛的数据集,来训练AlexNet,保存其中的模型参数。
2.2.3.3 微调(fine-tuning):等于迁移学习
AlexNet是针对ImageNet训练出来的模型,卷积部分可以作为一个好的特征提取器,后面的全连接层可以理解为一个好的分类器。R-CNN需要在现有的模型上微调卷积参数。
- 将第一步中得到的样本进行尺寸变换,使得大小一致,然后作为预训练好的网络的输入,继续训练网络(迁移学习)
2.2.3.4 SVM分类器
**针对每个类别训练一个SVM的二分类器。**举例:猫的SVM分类器,输入维度是2000 4096,目标还是之前第一步标记是否属于该类别猫,训练结果是得到SVM的权重矩阵W,W的维度是4096 * 20。
2.2.3.5 bbox回归器训练
只对那些跟ground truth的IoU超过某个阈值且IOU最大的region proposal回归,其余的region proposal不参与。
2.2.4 R-CNN测试过程
输入一张图像,利用selective search得到2000个region proposal。
-
对所有region proposal变换到固定尺寸并作为已训练好的CNN网络的输入,每个候选框得到的4096维特征
-
采用已训练好的每个类别的svm分类器对提取到的特征打分,所以SVM的weight matrix是4096 * N,N是类别数,这里一共有20个SVM, 得分矩阵是2000 * 20
-
采用non-maximun suppression(NMS)去掉候选框
-
第上一步得到region proposal进行回归。
2.2.5 R-CNN总结



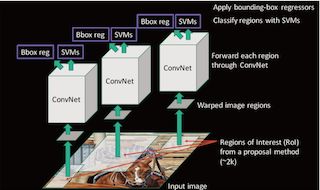
- 表现
在VOC2007数据集上的平均精确度达到66%
2.2.5.2 缺点
-
1、训练阶段多:步骤繁琐: 微调网络+训练SVM+训练边框回归器。
-
2、训练耗时:占用磁盘空间大:5000张图像产生几百G的特征文件。(VOC数据集的检测结果,因为SVM的存在)
-
3、处理速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
-
4、图片形状变化:候选区域要经过crop/warp进行固定大小,无法保证图片不变形
2.2.6 总结与掌握
- 掌握Overfeat模型思路
滑动窗口 - 掌握R-CNN的流程
- 掌握训练过程
预训练
微调
SVM+bbox regressor训练 - R-CNN的缺点
- 占用磁盘空间大
- 训练耗时
- 训练阶段多
- 处理速度慢
- 图片变形问题
- R-CNN的问题解决思路:
- SPPNet:只对一张图片进行全部卷积计算,并且去除Crop和Wrap操作。
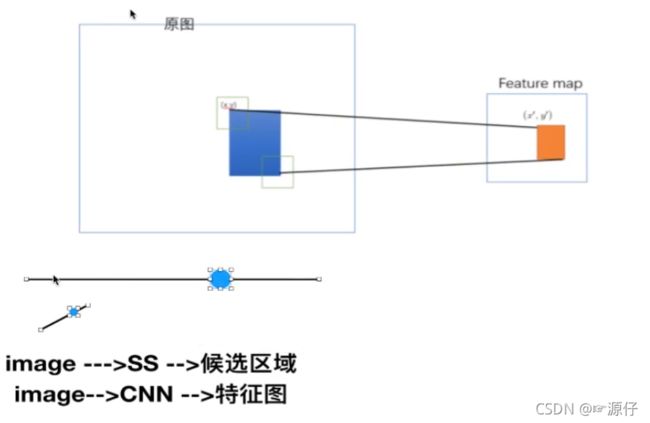
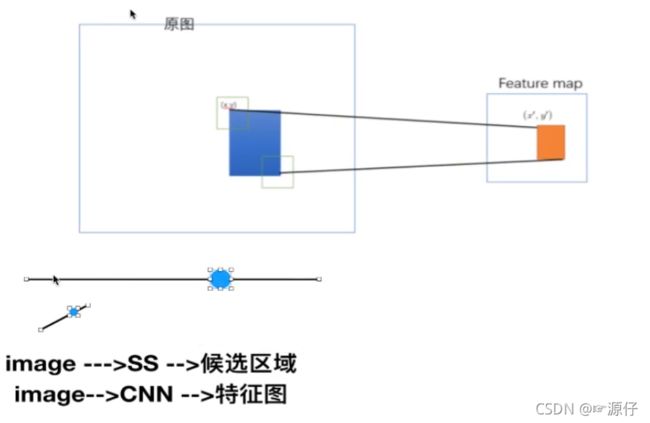
- 映射
image —>SS —> 候选区域
image —>CNN —> 特征图
将候选区域映射到特征图中,得出每个候选区域的特征向量
- SPP层(又叫金字塔层)
对M个候选区域,每个都要经过SPP层进行变换
把每个候选区域进行分块:4 * 4 ;2 * 2 ;1 * 1;
输出: 每个候选区域的特征向量 都为21 * 256 (不同网络卷积输出的通道数可能不一样)
这样长度固定了,特征向量也有了

2.2.7 问题?
1、R-CNN实现候选区域的有效算法是?
2、R-CNN算法中如果有得出了2000个候选框,总共有120种类别,请问特征提取之后的SVM分类器应该为多少个?
3、NMS的过程描述?以及作用?
4、请说明候选框的修正过程?
5、请描述微调过程的样本比例选择?
6、请描述R-CNN的训练和测试过程?
2.3 SPPNet
学习目标:
- 说明SPPNet的特点
- 说明SPP层的作用
R-CNN的速度慢在哪?
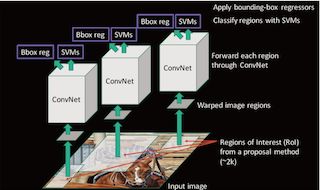
每个候选区域都进行了卷积操作提取特征。
2.3.1 SPPNet
SPPNet主要存在两点改进地方,提出了SPP层
- 减少卷积计算
- 防止图片内容变形

| R-CNN模型 | SPPNet模型 |
|---|---|
| 1、R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2、固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 | 1、SPPNet把全图塞给CNN得到全图的feature map 2、让候选区域与feature map直接映射,得到候选区域的映射特征向量 3、映射过来的特征向量大小不固定,这些特征向量塞给SPP层(空间金字塔变换层),SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层 |
2.3.1.1 映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域,现在需要将基于原始图片的候选区域映射到feature map中的特征向量。映射过程图参考如下:
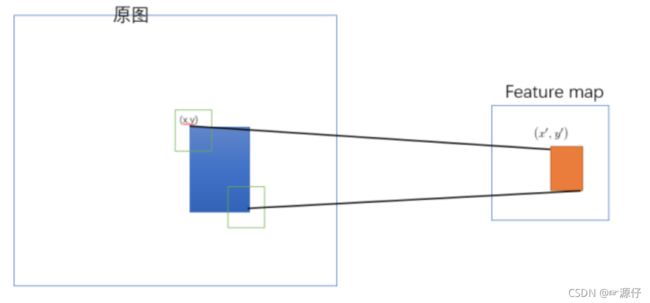
整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:(x,y)=(S∗x′,S∗y′),即
- 左上角的点:
x′=[x/S]+1 - 右下角的点:
x′=[x/S]−1
其中 SS 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为=16
拓展:如果关注这个公式怎么计算出来,请参考:
2.3.1.2 spatial pyramid pooling
通过spatial pyramid pooling 将任意大小的特征图转换成固定大小的特征向量
示例:假设原图输入是224x224,对于conv出来后的输出是13x13x256的,可以理解成有256个这样的Filter,每个Filter对应一张13x13的feature map。接着在这个特征图中找到每一个候选区域映射的区域,spp layer会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,得出的特征再连接到一起,就是(16+4+1)x256的特征向量,接着给全连接层做进一步处理,如下图:
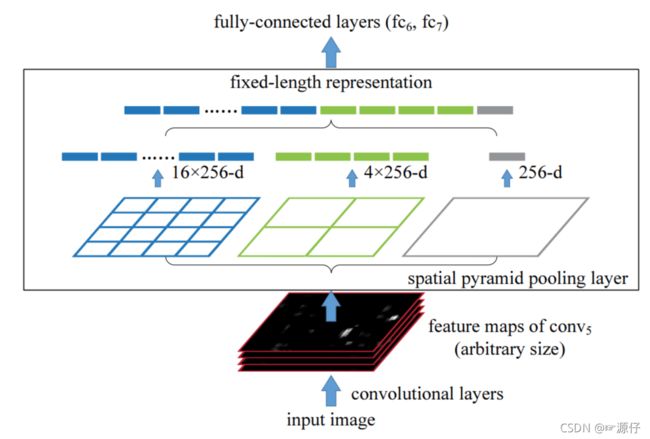
2.3.2 SPPNet总结
来看下SPPNet的完整结构

- 优点
SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间, 后面的Fast R-CNN等也是受SPPNet的启发 - 缺点
训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPP-Net在fine-tuning阶段无法使用反向传播微调SPP-Net前面的Conv层
2.3.3 总结
- 掌握SPP的池化作用
- 掌握SPP的优缺点
2.3.4 问题?
1、SPPNet的映射过程描述?公式?
2、spatial pyramid pooling的过程?
3、SPPNet相对于R-CNN的改进地方?
3.4 Fast R-CNN
- 目标
了解Fast R-CNN的结构特点
说明RoI pooling的特点
了解多任务损失
SPPNet的性能已经得到很大的改善,但是由于网络之间不统一训练,造成很大的麻烦,所以接下来的Fast R-CNN就是为了解决这样的问题
3.4.1 Fast R-CNN相对于R-CNN改进的部分
- 改进的地方:
提出一个RoI pooling,然后整合整个模型,把CNN、SPP变换层、分类器、bbox回归几个模块一起训练

- 步骤
- 首先将整个图片输入到一个基础卷积网络,得到整张图的feature map
- 将region proposal(RoI)映射到feature map中
- RoI pooling layer提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个RoI特征向量(此步骤是对每一个候选区域都会进行同样的操作)
-
- 其中一个是传统softmax层进行分类,输出类别有K个类别加上”背景”类
-
- 另一个是bounding box regressor
2.4.1.1 RoI pooling首先RoI pooling只是一个简单版本的SPP,目的是为了减少计算时间并且得出固定长度的向量。
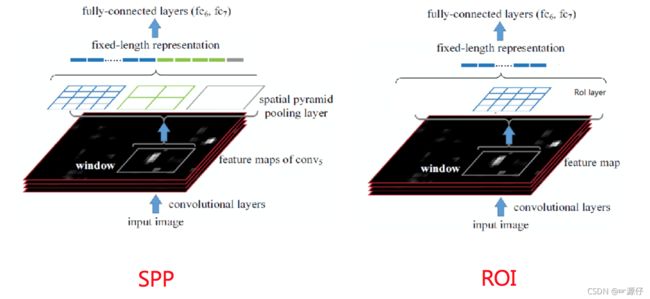
-
RoI池层使用最大池化将任何有效的RoI区域内的特征转换成具有H×W的固定空间范围的小feature map,其中H和W是超参数 它们独立于任何特定的RoI。
例如:VGG16 的第一个 FC 层的输入是 7 x 7 x 512,其中 512 表示 feature map 的层数。在经过 pooling 操作后,其特征输出维度满足 H x W。假设输出的结果与FC层要求大小不一致,对原本 max pooling 的单位网格进行调整,使得 pooling 的每个网格大小动态调整为 h/H,w/W, 最终得到的特征维度都是 HxWxD。
它要求 Pooling 后的特征为 7 x 7 x512,如果碰巧 ROI 区域只有 6 x 6 大小怎么办?每个网格的大小取 6/7=0.85 , 6/7=0.85,以长宽为例,按照这样的间隔取网格:[0,0.85,1.7,2.55,3.4,4.25,5.1,5.95],取整后,每个网格对应的起始坐标为:[0,1,2,3,3,4,5]
为什么要设计单个尺度呢?这要涉及到single scale与multi scale两者的优缺点 -
single scale,直接将image定为某种scale,直接输入网络来训练即可。(Fast R-CNN) -
multi scal,也就是要生成一个金字塔,然后对于object,在金字塔上找到一个大小比较接近227x227的投影版本
后者比前者更加准确些,没有突更多,但是第一种时间要省很多,所以实际采用的是第一个策略,因此Fast R-CNN要比SPPNet快很多也是因为这里的原因。
2.4.1.3 End-to-End model
从输入端到输出端直接用一个神经网络相连,整体优化目标函数。
接着我们来看为什么后面的整个网络能进行统一训练?
特征提取CNN的训练和SVM分类器的训练在时间上是先后顺序,两者的训练方式独立,因此SVMs的训练Loss无法更新SPP-Layer之前的卷积层参数,去掉了SVM分类这一过程,所有特征都存储在内存中,不占用硬盘空间,形成了End-to-End模型(proposal除外,end-to-end在Faster-RCNN中得以完善)
- 使用了softmax分类
RoI pooling能进行反向传播,SPP层不适合(关于感受野的东西,可以自己去了解)
2.4.2 多任务损失-Multi-task loss
两个loss,分别是:
- 对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景(region proposal 会被标记为0, 什么都没有),使用交叉熵损失
- 对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,使用平均绝对误差(MAE)损失即L1损失
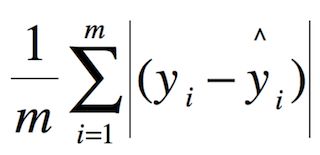
- fine-tuning训练:
在微调时,调整 CNN+RoI pooling+softmax+bbox regressor网络当中的参数,除了region proposal(采用的还是SS)不能一起训练。
3.4.3 R-CNN、SPPNet、Fast R-CNN效果对比
| 参数 | R-CNN | SPPNet | Fast R-CNN |
|---|---|---|---|
| 训练时间(h) | 84 | 25 | 9.5 |
| 测试时间/图片 | 47.0s | 2.3s | 0.32s |
| mAP | 66.0 | 63.1 | 66.9 |
其中有一项指标为mAP,这是一个对算法评估准确率的指标,mAP衡量的是学出的模型在所有类别上的好坏
2.4.4 Fast R-CNN总结
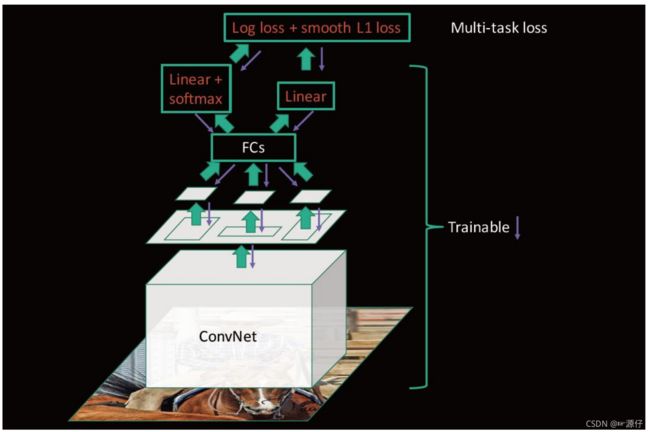
- 缺点
使用Selective Search提取Region Proposals,没有实现真正意义上的端对端,操作也十分耗时
2.4.5 总结
- 掌握Fast R-CNN的改进
- 修改SVM分类为softmax分类,输出N个分类和一个背景
- softmax + Rol-Pooling一起训练
- 掌握RoI pooling的作用
- 掌握多任务损失结构
1、详细说明RoI pooling过程?
2、Fast R-CNN的损失是怎么样的?
2.5 Faster R-CNN
结构:
- 区域生成网络(RPN)+ FastRCNN网络
- 步骤
- 输入任意大小的图片,经过CNN网络输出特征图,特征图共享于后面两个步骤
- 特征图经过 PRN 生成候选区域
- 候选区域于特征图共同输入到Rol pooling ,得到每个候选区域的特征图,然后进行softmax分类和bbox预测
- RPN网络是什么?生成候选区域是什么?
- 3*3的滑动窗口,每个中心会得到9个anchor box 长宽通过尺度和长宽比进行一一对应计算, 得到最原始的anchor box (候选区域)
- 需要一个候选区域的校正过程
- 即RPN网络训练
- 训练样本标记:每个ground-truth box有着最高的IoU的anchor标记为正样本
- 剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 剩下的样本全部忽略(有一些生成的anchor太差了)
- 正负样本比例为1:3
-
RPN当中的分类属于二分类
-
RPN Regression修正Bbox的坐标
-
训练好的网络用于海选Anchor Bbox
-
学习目标
- 了解Faster R-CNN的特点
- 知道RPN的原理以及作用
在Fast R-CNN还存在着瓶颈问题:Selective Search(选择性搜索)。要找出所有的候选框,这个也非常耗时。那我们有没有一个更加高效的方法来求出这些候选框呢?
2.5.1 Faster R-CNN
在Faster R-CNN中加入一个提取边缘的神经网络,也就说找候选框的工作也交给神经网络来做了。这样,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。

Faster R-CNN可以简单地看成是区域生成网络+Fast R-CNN的模型,用区域生成网络(Region Proposal Network,简称RPN)来代替Fast R-CNN中的选择性搜索方法,结构如下: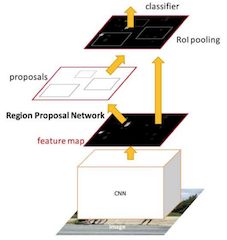
- 1、首先向CNN网络(VGG-16)输入任意大小图片
- 2、Faster RCNN使用一组基础的conv+relu+pooling层提取feature map。该feature map被共享用于后续RPN层和全连接层。
- 3、Region Proposal Networks。RPN网络用于生成region proposals,该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals,输出其Top-N(默认为300)的区域给RoI pooling
- 生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
- 4、第2步得到的高维特征图和第3步输出的区域建合并输入RoI池化层(类), 该输出到全连接层判定目标类别。
- 5、利用proposal feature maps计算每个proposal的不同类别概率,同时bounding box regression获得检测框最终的精确位置

2.5.2 RPN原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
用n×n(默认3×3=9)的大小窗口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)- 低维特征向量输入两个并行连接的1 x 1卷积层然后得出两个部分:reg窗口回归层(用于修正位置)和cls窗口分类层(是否为前景或背景概率)
2.5.2.1 anchors
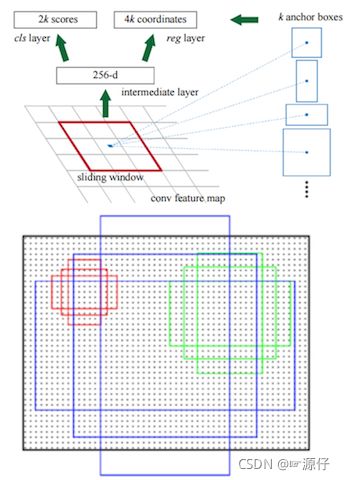
- 3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors,三种尺度{ 128,256,512 }, 三种长宽比{1:1,1:2,2:1}
举个例子:
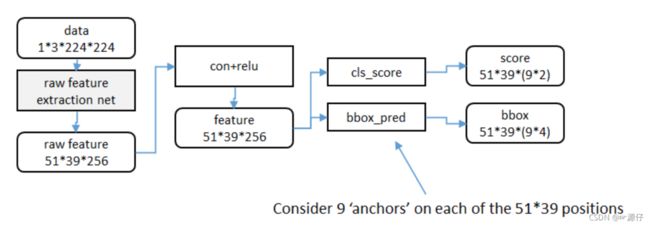
2.5.2.2 候选区域的训练
- 训练样本anchor标记
- 每个ground-truth box有着最高的IoU的anchor标记为正样本
- 剩下的anchor/anchors与任何ground-truth box的IoU大于0.7记为正样本,IoU小于0.3,记为负样本
- 剩下的样本全部忽略
- 正负样本比例为1:3
- 训练损失
- RPN classification (anchor good / bad) ,二分类,是否有物体,是、否
- RPN regression (anchor -> proposal) ,回归
- 注:这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价
候选区域的训练是为了让得出来的 正确的候选区域, 并且候选区域经过了回归微调。
在这基础之上做Fast RCNN训练是得到特征向量做分类预测和回归预测。
2.5.3 Faster R-CNN的训练
Faster R-CNN的训练分为两部分,即两个网络的训练。前面已经说明了RPN的训练损失,这里输出结果部分的的损失(这两个网络的损失合并一起训练):
-
Fast R-CNN classification (over classes) ,所有类别分类N+1
-
Fast R-CNN regression (bbox regression)
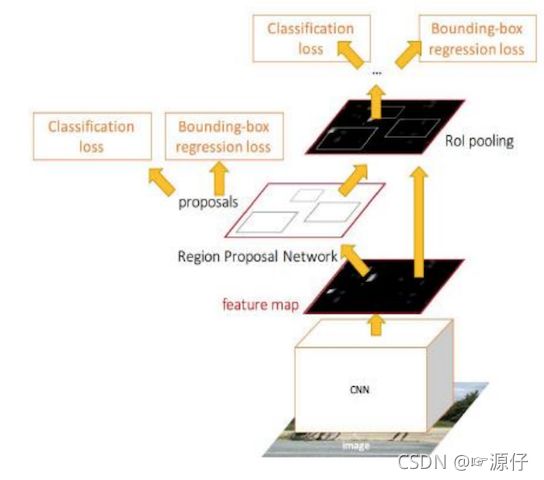
2.5.4 效果对比
| R-CNN | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|
| Test time/image | 50.0s | 2.0s | 0.2s |
| mAP(VOC2007) | 66.0 | 66.9 | 66.9 |
2.5.5 Faster R-CNN总结
- 优点
- 提出RPN网络
- 端到端网络模型
- 缺点
- 训练参数过大
- 对于真实训练使用来说还是依然过于耗时
可以改进的需求:
- RPN(Region Proposal Networks) 改进 对于小目标选择利用多尺度特征信息进行RPN
- 速度提升 如YOLO系列算法,删去了RPN,直接对proposal进行分类回归,极大的提升了网络的速度
2.5.7 问题?
1、Faster RCNN改进之处?
2、如何得到RPN的 anchors?
2.6 YOLO(You only look once)
- 目标
- 知道YOLO的网络结构
- 知道单元格的意义
- 知道YOLO的损失
在正式介绍YOLO之前,我们来看一张图:

可以看出YOLO的最大特点是速度快。
2.6.1 YOLO
- YOLO 的改进

2.6.1.1 结构
一个网络搞定一切,GoogleNet + 4个卷积+2个全连接层
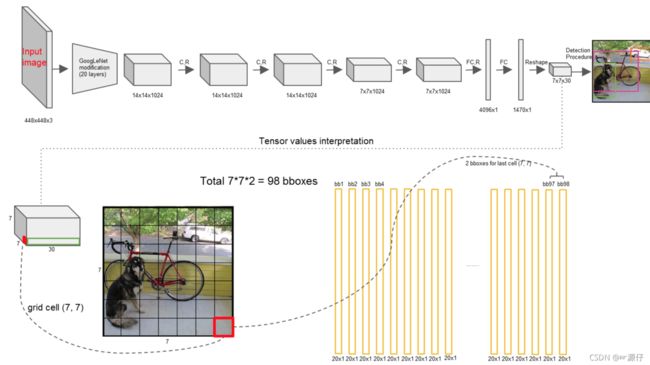
2.6.1.2 流程理解
- 1、原始图片resize到448x448,经过前面卷积网络之后,将图片输出成了一个7 7 30的结构
以图示的方式演示
2、默认7 7个单元格,这里用3 3的单元格图演示

3、每个单元格预测两个bbox框

4、进行NMS筛选,筛选概率以及IoU


这些候选框与我们前面R-CNN系列算法中有哪些不同?
2.6.2 单元格(grid cell)
最后网络输出的7* 7 *30的特征图怎么理解?7 * 7=49个像素值,理解成49个单元格,每个单元格可以代表原图的一个方块。单元格需要做的两件事:
-
1.每个单元格负责预测一个物体类别,并且直接预测物体的概率值
-
2.每个单元格预测两个(默认)bbox位置,两个bbox置信度(confidence)772=98个bbox
30=(4+1+4+1+20), 4个坐标信息,1个置信度(confidence)代表一个bbox的结果, 20代表 20类的预测概率结果
理解Confidence
(1)在YOLO中置信度confidence指的是一个边界框包含某个物体的可能性大小以及位置的准确性(即是否恰好包裹这个物体),用公式表达就是 。那么confidence的真实值是1,即包含物体的概率为1,IOU值也为1,这样我们训练时才可以让预测的边界框尽量接近真实框(不过YOLO里面有一个控制参数,resocre,当其为1时,IOU不取1,而是取预测框与ground truth的真实IOU,默认情况下rescore为1。但是我个人觉得iou直接取1并无不当之处吧)。但是在预测时,其实就是一个预测值,它只是表征了上述含义,通过计算loss不断使模型可以准确预测。
(2)在YOLO中,由于多了confidence这个东西,所以预测的类别其实只是一个条件概率值,就是在置信度下的类别概率,需要两者相乘才得到最终的scores。这点也与SSD和RCNN模型区别,因为它们没有confidence这个东东,只是把背景作为一个特殊的类别来处理(但是YOLO就没有背景这个类别,confidence其实起到了背景框的筛选作用,殊途同归吧)。
(3)不只两个哦,只不过YOLO中设置了两个,其实我可以预测更多啊,只不过每个cell的类别概率是共享的,但是confidence与coordinate是不一样的,每个cell可以预测很多边界框,这可能对密集的小物体有效吧,但是YOLO有个致命缺点,每个cell预测的边界框w和h都是相对于图片大小的,对于不同比例的物体训练难度大。所以,后面的模型都采用了先验框,prior boxes, anchors.
2.6.2.1 网格输出筛选
一个网格预测多个Bbox,在训练时我们只有一个Bbox专门负责(一个Object 一个Bbox)
怎么进行筛选?
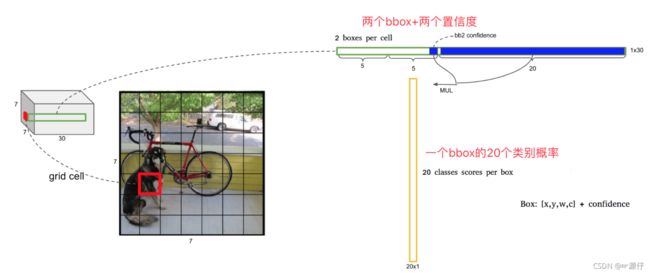
- 通过置信度大小比较
每个bounding box都对应一个confidence score,如果grid cell里面没有object,confidence就是0,如果有,则confidence score等于预测的box和ground truth的IOU值
所以如何判断一个grid cell中是否包含object呢?如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
- 如何理解概率?
这个概率可以理解为不属于任何一个bbox,而是属于这个单元格所预测的类别。
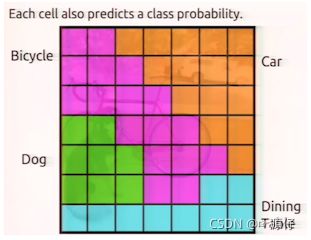
- 输出位置结果理解
其中(x,y,w,h):x,y为为中心相对于单元格的offset,w,h为bbox的宽高相对整张图片的占比


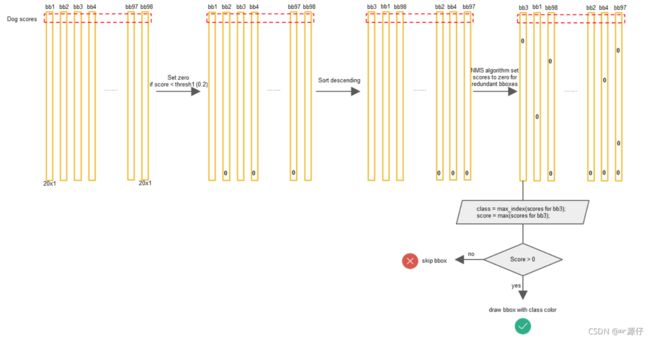
2.6.3 非最大抑制(NMS)
每个Bbox的Class-Specific Confidence Score以后,设置阈值,滤掉概率的低的bbox,对每个类别过滤IoU,就得到最终的检测结果
2.6.4 训练
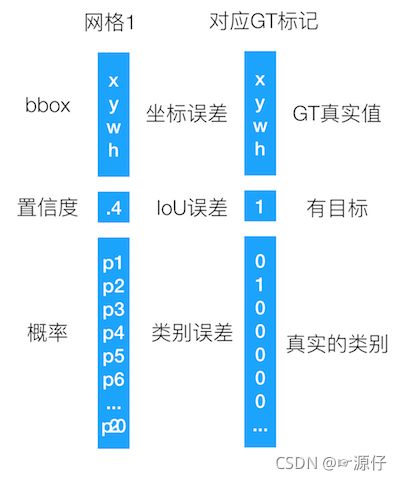
- 预测框对应的目标值标记
- confidence:格子内是否有目标
- 20类概率:标记每个单元格的目标类别
怎么理解这个过程?同样以分类那种形式来对应,假设以一个单元格的预测值为结果,如下图
- 损失
三部分损失 bbox损失+confidence损失+classfication损失
2.6.5 与Faster R-CNN比较
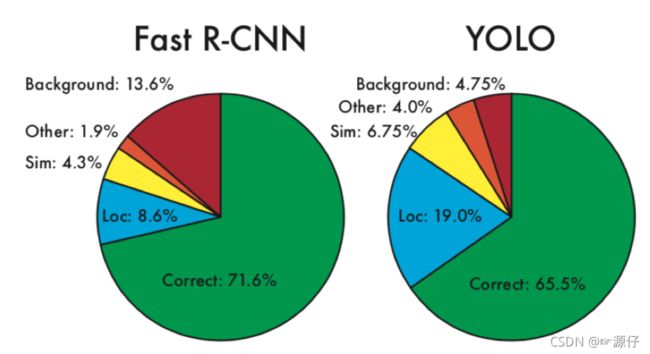
Faster R-CNN利用RPN网络与真实值调整了候选区域,然后再进行候选区域和卷积特征结果映射的特征向量的处理来通过与真实值优化网络预测结果。而这两步在YOLO当中合并成了一个步骤,直接网络输出预测结果进行优化。
所以经常也会称之为YOLO算法为直接回归法代表。YOLO的特点就是快
2.6.6 YOLO总结
- 优点
速度快 - 缺点
准确率会打折扣
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框
2.7 SSD(Single Shot MultiBox Detector)
- 目标
知道SSD的结构
说明Detector & classifier的作用
说明SSD的优点
2.7.1 SSD
2.7.1.1 简介
SSD算法源于2016年发表的算法论文,论文网址:
SSD的特点在于:
-
SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
-
SSD的核心是在不同尺度的特征特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。
2.7.1.2 结构
以VGG-16为基础,使用VGG的前五个卷积,后面增加从CONV6开始的5个卷积结构,输入图片要求300*300。
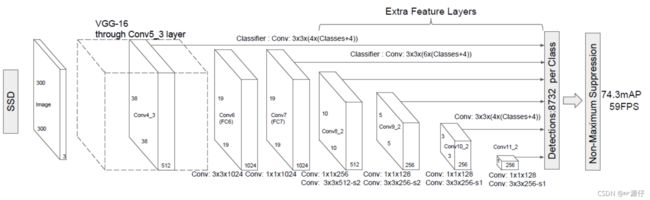
2.7.1.3 流程
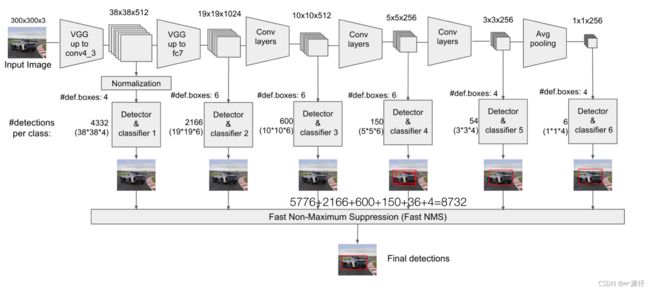
SSD中引入了Defalut Box,实际上与Faster R-CNN的anchor box机制类似,就是预设一些目标预选框,不同的是在不同尺度feature map所有特征点上是使用不同的prior boxes
2.7.1.4 Detector & classifier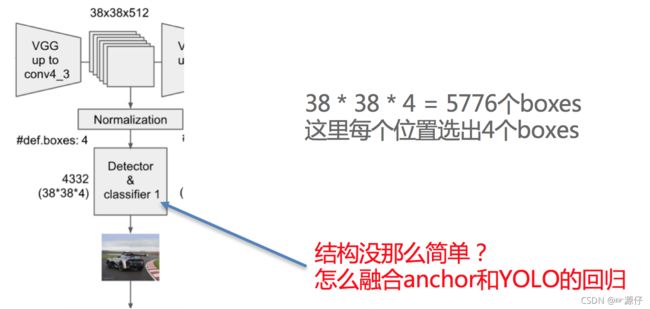
- Detector & classifier的三个部分:
- default boxes: 默认候选框
- localization:4个位置偏移
- confidence:21个类别置信度(要区分出背景)

2.7.1.4.1 default boxes
default boxex类似于RPN当中的滑动窗口生成的候选框,SSD中也是对特征图中的每一个像素生成若干个框。
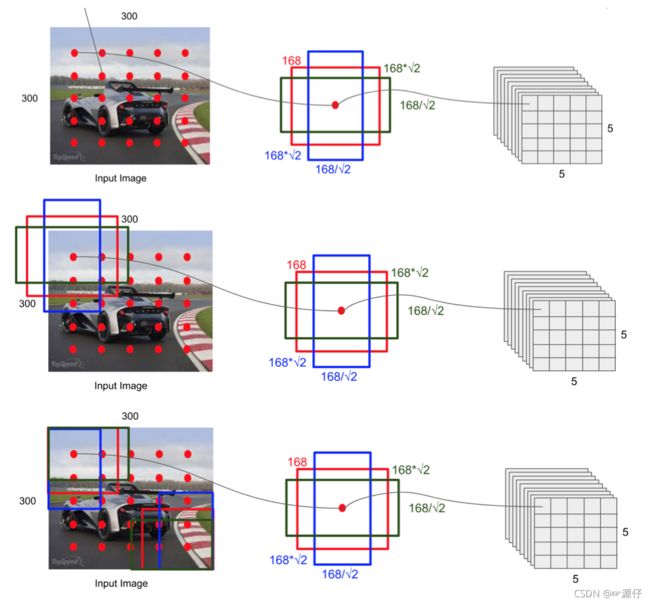
只不过SSD当中的默认框有生成的公式:
以下为了解内容,记住几个参数即可:
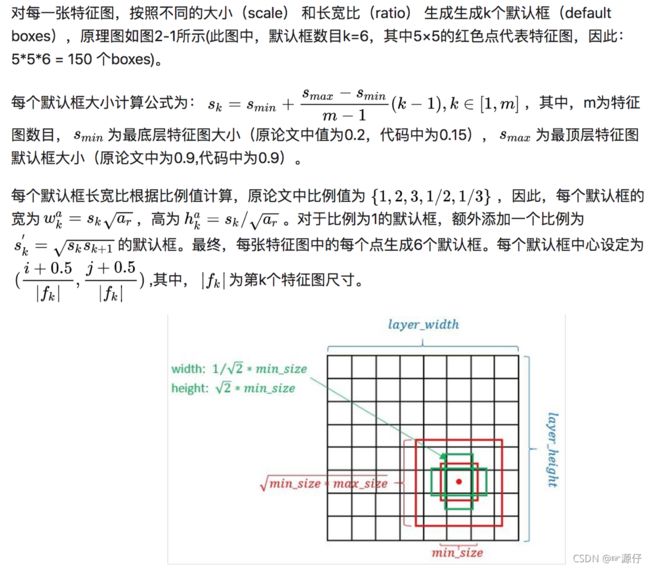
- ratio:长宽比
- 默认框的大小计算参数:s_min:最底层的特征图计算参数,s_max最顶层的特征图计算参数
2.7.1.4.2 localization与confidence
这两者的意义如下,主要作用用来过滤,训练

经过这一次过滤操作,会将候选框筛选出数量较少的prior boxes。
关于三种boxes的解释区别:
- gournd truth boxes:训练集中,标注好的待检测类别的的位置,即真实的位置,目标的左下角和右上角坐标
- default boxes:在feature map上每一个点上生成的某一类别图片的位置。feature map每个点生成4或6个box(数量是事先指定的),格式为转换过后的(x, y, w, h)
- prior boxes:经过置信度阈值筛选后,剩下的可能性高的boxes。这个box才是会被真正去做回归
也就是说SSD中提供事先计算好的候选框这样的机制,只不过不需要再像RPN那种筛选调整,而是直接经过prior boxes之后做回归操作(因为confidence中提供了21个类别概率可以筛选出背景)
问题:SSD中的多个Detector & classifier有什么作用?
SSD的核心是在不同尺度的特征图上来进行Detector & classifier 容易使得SSD观察到更小的物体
2.7.2 训练与测试流程
2.7.2.1 train流程
- 输入->输出->结果与ground truth标记样本回归损失计算->反向传播, 更新权值
1. 样本标记:
利用anchor与对应的ground truth进行标记正负样本,每次并不训练8732张计算好的default boxes, 先进行置信度筛选,并且训练指定的正样本和负样本, 如下规则
-
正样本
1.与GT重合最高的boxes, 其输出对应label设为对应物体.
2.物体GT与anchor iou满足大于0.5 -
负样本:其它的样本标记为负样本
在训练时, default boxes按照正负样本控制positive:negative=1:3
3. 损失
网络输出预测的predict box与ground truth回归变换之间的损失计算, 置信度是采用 Softmax Loss(Faster R-CNN是log loss),位置回归则是采用 Smooth L1 loss (与Faster R-CNN一样)
2.7.2.2 test流程
- 输入->输出->nms->输出
2.7.3 比较

从图中看出SSD算法有较高的准确率和性能,兼顾了速度和精度
2.7.4 总结
- SSD的结构
- Detector & classifier的组成部分以及作用
- SSD的训练样本标记
- GT与default boxes的格式转换过程
2.8 TensorFlowSSD接口
- 目标
知道TensorFlow的SSD接口意义
TensorFlow在github上面已经做了接口的封装,只不过过没有提供在官网的接口当中,是官方案例当中提供的Python文件,需要自行去下载,参考:
https://github.com/tensorflow/models/tree/master/research/object_detection
我们下载到项目当中如下:
2.8.1.1 网络配置

2.8.2 接口介绍
2.8.2.1 模型搭建处理:
- ssd_net.net:网络结构定义函数
- 输出:predictions, localisations, logits, end_points,分别表示bbox分类预测值(经过softmax)、bbox位移预测值、bbox分类预测值(未经过softmax)、模型节点
- 获取默认anchor:
- ssd_net.anchors:所有阶段特征图的default boxes生成, 得到每层特征图的预设框(x, y, w, h)(公式计算得来)
- Default boxes的对应Ground Truth标记处理:使 Ground Truth 数量与预测结果一一对应
- ssd_net.bboxes_encode(glabels, gbboxes, ssd_anchors),grounding truth处理函数,利用gt与每层生成的anchor进行标记得分,返回gclasses, glocalisations, gscores
2.8.2.2 定义网络的损失:
- ssd_net.losses:
- 网络的输出预测结果与Ground Truth之间损失计算
总结(树状图)
3.数据集处理
了解常用目标检测数据集
了解数据集构成
了解数据集标记的需求
知道labelimg的标记使用
应用TensorFlow完成pascalvoc2007数据集的转换
了解TensorFlow slim库
了解TFRecords文件的作用
了解slim读取数据流程
应用TF-slim的data模块完成VOC2007TFRecord文件的读取
3.1. 目标检测数据集
- 了解常用目标检测数据集
- 了解数据集结构
3.1.1 常用目标检测数据集

VOC数据集是目标检测经常用的一个数据集,从05年到12年都会举办比赛(比赛有task: Classification、Detection、Segmentation、PersonLayout),主要由VOC2007和VOC2012两个数据集

注意:
官网地址:http://host.robots.ox.ac.uk/pascal/VOC/
下载地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
- Open Images Dataset V4

2018年发布了包含在 190 万张图片上针对 600 个类别的 1540 万个边框盒,这也是现有最大的具有对象位置注释的数据集。这些边框盒大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。
谷歌的数据集类目较多涵盖范围广,但是文件过多,处理起来比较麻烦,所以选择目前使用较多并且已经成熟的pascavoc数据集
3.1.2 pascal voc数据集介绍
通常使用较多的为VOC2007数据集,总共9963张图片,需要判定的总物体类别数量为20个对象类别是:
- 人:人
- 动物:鸟,猫,牛,狗,马,羊
- 车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车
- 室内:瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
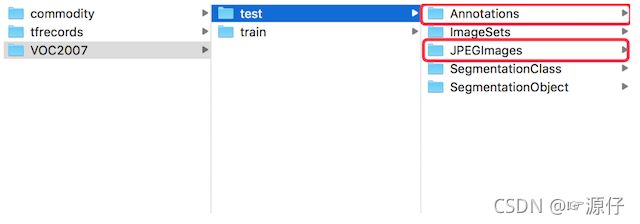
- 文件结构
- 文件内容
- Annotations: 图像中的目标标注信息xml格式
- JPEGImages:所有图片(VOC2007中总共有9963张,训练有5011张,测试有4952张)

3.1.3 XML
以下是一个标准的物体检测标记结果格式,这就是用于训练的物体标记结果。其中有几个重点内容是后续在处理图像标记结果需要关注的。
- size:
- 图片尺寸大小,宽、高、通道数
- object:
- name:被标记物体的名称
- bndbox:标记物体的框大小
如下例子:为000001.jpg这张图片,其中有两个物体被标记

<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename># 文件名
<source># 文件来源
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size># 文件尺寸,包括宽、高、通道数
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented># 是否用于目标分割
<object># 真实标记的物体
<name>dog</name># 目标类别名称
<pose>Left</pose>
<truncated>1</truncated># 是否截断,这个目标因为各种原因没有被框完整(被截断了),比如说一辆车有一部分在画外面
<difficult>0</difficult># 表明这个待检测目标很难识别,有可能是虽然视觉上很清楚,但是没有上下文的话还是很难确认它属于哪个分类,标为difficult的目标在测试评估中一般会被忽略
<bndbox># bounding-box
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object># 真实标记的第二个物体
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
3.2 目标数据集标记
学习目标
- 了解数据集标记的需求
- 知道labelimg的标记使用
- 应用labelimg完成商品数据集的标记
为什么要进行数据集标记呢?
1、提供给训练的数据样本,图片和目标真是实结果
2、特定的场景都会缺少标记图片
3.2.1 数据集标记工具介绍
2.2.1.1 介绍
LabelImg是一个图形图像注释工具。它是用Python编写的,并使用Qt作为其图形界面。注释以PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。
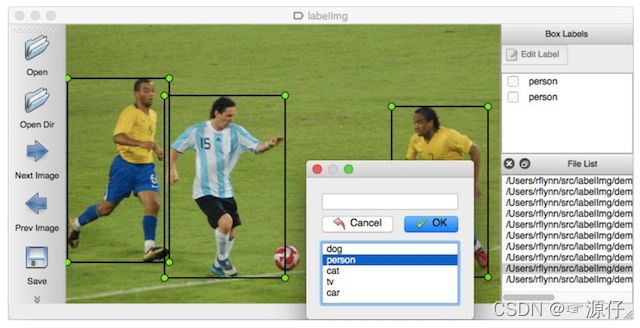
官网:https://github.com/tzutalin/labelImg
3.2.1.2 安装
官网给出了不同平台的安装教程,由于教程过于粗略。安装细节参考安装教程本地文件
其实现在window安装和Linux没太多区别,直接pip就可以了。如下:
# 可以不用镜像源,没什么区别
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple/(后面这行是国内的清华镜像源,下载速度才会比较快)
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple/ (Img中的I要大写,注意)
3.2.2 商品数据集标记
在这里我们只是体验标记的过程,那么对于标记这个费时费力的工作,一般会有专门的数据标记团队去做,也称之为打标签,标记师。特别是缺乏具体应用场景的训练数据的时候。
3.2.2.1 需求介绍
首先在确定标记之前的需求,本项目以商品数据为例,需要明确的有
- 1、商品图片
- 2、需要被标记物体有哪些
我们确定了8种类别的商品(如需更细致,可将类别商品扩大),如下图

3.2.2.2 标记
使用lableimg进行商品数据集标记
- 运行labelimg
# 在命令窗口输入
labelImg
打开如下结果:
- 对图片中的物体进行标记
标记原则为图片中所出现的物体与我们确定的8个类别物体相匹配即可
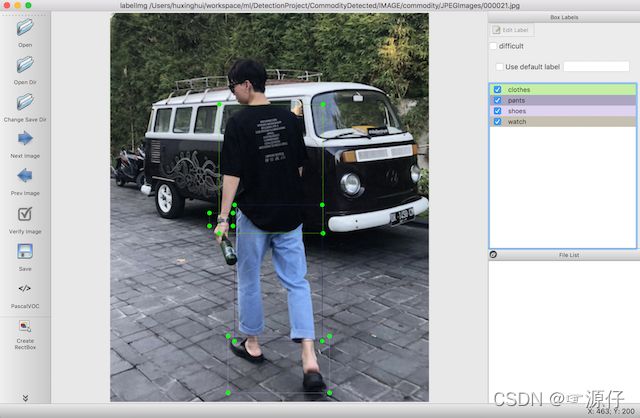
- 按下ctrl+s键保存,软件将会保存为默认XML文件格式**(XML文件名与图片文件名保持一致方便后续处理)**
在这里插入图片描述
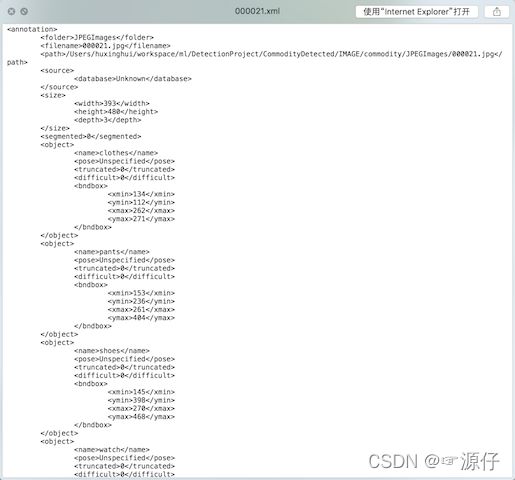
其中关于(xmin,ymin,xmax,ymax)我们已经解释过,可通过软件标记的时候观察是否一致
3.2.3 总结
- 掌握labelimg的标注使用
3.2.4 问题
通过这样标记数据,假设你想做一个潮流商品品牌(Nike、H&M等)或者其他具体某个子领域的大部分商品的识别模型,你的数据集怎么准备?
3.3 数据集格式转换
学习目标
- 了解TFRecords文件的作用
- 应用TensorFlow完成pascalvoc2007数据集的转换
首先来看下转换的效果:

为什么要进行格式转换?
数据集的图片以及标记文件分布在不同的文件当中,并且图片与标签没有一一对应。在后续项目当中不方便处理,也不方便项目的解耦合,需要将数据集转换成一个标准、统一使用、方便赋值移动到其他模块当中。
3.3.2 TFRecords文件
TensorFlow提供了TFRecord的格式来统一存储数据,TFRecord格式是一种将图像数据和各种标签放在一起的二进制文件,在tensorflow中快速的复制、移动、读取、存储。特点:
- 文件格式:.tfrecord or .tfrecords
- 写入文件内容:使用Example将数据封装成protobuffer协议格式
- 体积小:消息大小只需要xml的1/10~1/3
- 解析速度快:解析速度比xml快20~100倍
- 每个example对应一张图片,其中包括图片的各种信息
3.3.3 案例:VOC2007数据集转换
3.3.3.1 转换效果显示
3.3.3.2 TensorFlow API
gfile读取模块
- tf.gfile.MakeDirs(dirname):
以递归方式建立父目录及其子目录,如果目录已存在且是可覆盖则会创建成功,否则报错,无返回 - tf.gfile.Exists(filename):
判断目录或文件是否存在,filename可为目录路径或带文件名的路径,有该目录则返回True,否则False - tf.gfile.FastGFile(filename, mode):
该函数与tf.gfile.GFile的差别仅仅在于“无阻塞”,即该函数会无阻赛以较快的方式获取文本操作句柄
建立TFRecord存储器
- tf.python_io.TFRecordWriter(path)
- 写入tfrecords文件
- path: TFRecords文件的路径
- return:写文件
- method
++ write(record):向文件中写入一个example
++ close():关闭文件写入器
注:字符串为一个序列化的Example,Example.SerializeToString()
构造每个样本的Example协议块
- tf.train.Example(features=None)
写入tfrecords文件
features:tf.train.Features类型的特征实例
return:example格式协议块 - tf.train.Features(feature=None)
构建每个样本的信息键值对
feature:字典数据,key为要保存的名字,value为tf.train.Feature实例
return:Features类型 - tf.train.Feature(**options)
**options:例如
bytes_list=tf.train. BytesList(value=[Bytes])
int64_list=tf.train. Int64List(value=[Value])
处理XML库
- import xml.etree.ElementTree as ET
tree = et.parse(filename):形成树状结构
tree.getroot():获取树结构的根部分
root.find与findall()进行查询XML每个标签的内容.text
3.3.3.2 转换步骤
- 1、存入多个tfrecord文件,每个文件固定N个样本
- 2、读取每张图片内容以及XML文件
- 3、将每次读取内容写入tfrecord文件
3.3.3.3 代码
首先导入需要用到的库以及相关设置
import os
import tensorflow as tf
import xml.etree.ElementTree as ET
from datasets.utils.dataset_utils import int64_feature, float_feature, bytes_feature
from datasets.dataset_config import DIRECTORY_ANNOTATIONS, SAMPLES_PER_FILES, DIRECTORY_IMAGES, VOC_LABELS
代码结构按照如下目录结构
dataset_utils当中存放常用代码,dataset_config存放一些配置,先看配置
# 原始图片的XML和JPG的文件名
DIRECTORY_ANNOTATIONS = "Annotations/"
DIRECTORY_IMAGES = "JPEGImages/"
# 每个TFRecords文件的example个数
SAMPLES_PER_FILES = 200
- 1、存入多个tfrecord文件,每个文件固定N个样本
def run(dataset_dir, output_dir, name="data"):
"""
存入多个tfrecords文件,每个文件通常会固定样本的数量
:param dataset_dir: 数据集目录
:param output_dir: tfrecord输出目录
:param name: 数据集名字
:return:
"""
# 1、判断数据集的路径是否存在,如果不存在新建一个文件夹
if tf.gfile.Exists(dataset_dir):
tf.gfile.MakeDirs(dataset_dir)
# 2、去Annotations读取所有的文件名字列表,与JPEGImages一样的数据量
# 构造文件的完整路径
path = os.path.join(dataset_dir, DIRECTORY_ANNOTATIONS)
# 排序操作,因为会打乱文件名的前后顺序
filenames = sorted(os.listdir(path))
# 3、循环列表中的每个文件
# 建立一个tf.python_io.TFRecordWriter(path)存储器
# 标记每个TFRecords存储200个图片和相关XML信息
# 所有的样本标号
i = 0
# 记录存储的文件标号
fidx = 0
while i < len(filenames):
# 新建一个tfrecords文件
# 构造一个文件名字
tf_filename = _get_output_filename(output_dir, name, fidx)
with tf.python_io.TFRecordWriter(tf_filename) as tfrecord_writer:
j = 0
# 处理200个图片文件和XML
while i < len(filenames) and j < SAMPLES_PER_FILES:
print("转换图片进度 %d/%d" % (i+1, len(filenames)))
# 处理图片,读取的此操作
# 处理每张图片的逻辑
# 1、读取图片内容以及图片相对应的XML文件
# 2、读取的内容封装成example, 写入指定tfrecord文件
filename = filenames[i]
img_name = filename[:-4]
_add_to_tfrecord(dataset_dir, img_name, tfrecord_writer)
i += 1
j += 1
# 当前TFRecords处理结束
fidx += 1
print("完成数据集 %s 所有的样本处理" % name)
- 存入的逻辑,给文件名字进行format
def _get_output_filename(output_dir, name, number):
return "%s/%s_%03d.tfrecord" % (output_dir, name, number)
def _add_to_tfrecord(dataset_dir, img_name, tfrecord_writer):
"""
# 1、读取图片内容以及图片相对应的XML文件
# 2、读取的内容封装成example, 写入指定tfrecord文件
:param dataset_dir: 数据集目录
:param img_name: 该图片名字
:param tfrecord_writer: tfrecord文件的符号
:return:
"""
# 1、读取图片内容以及图片相对应的XML文件
image_data, shape, bboxes, difficult, truncated, labels, labels_text = \
_process_image(dataset_dir, img_name)
# 2、读取的内容封装成example
example = _convert_to_example(image_data, shape, bboxes, difficult, truncated, labels, labels_text)
# 3、exmaple 写入指定tfrecord文件
tfrecord_writer.write(example.SerializeToString())
return None
- 2、读取每张图片内容以及XML文件
-
哪些信息需要存入tfrecord?
-
处理原则,详细的信息都可以存入,方便后来人读取相应需要的结果(可以加入更多的信息,自行加入)
'image/height': int64_feature(shape[0]),# 高
'image/width': int64_feature(shape[1]),# 宽
'image/channels': int64_feature(shape[2]),# 通道数
'image/shape': int64_feature(shape),# 形状维度
'image/object/bbox/xmin': float_feature(xmin),# 极坐标X最小值
'image/object/bbox/xmax': float_feature(xmax),# 极坐标x最大值
'image/object/bbox/ymin': float_feature(ymin),# 极坐标y最小值
'image/object/bbox/ymax': float_feature(ymax),# 极坐标y最大值
'image/object/bbox/label': int64_feature(labels),# 该图片所包含类别数字列表
'image/object/bbox/label_text': bytes_feature(labels_text),# 该图片所包含类别名称字符串
'image/object/bbox/difficult': int64_feature(difficult),# 可选
'image/object/bbox/truncated': int64_feature(truncated),# 可选
'image/format': bytes_feature(image_format),# 图片格式
'image/encoded': bytes_feature(image_data)# 图片像素编码值
- 这些信息进行什么样的处理?
为了进行后续的算法模型处理,在这里xmin,ymin,xmax,ymax需要进行与图片宽、高的标准化,使之范围0~1之间
float(bbox.find('ymin').text) / shape[0]
float(bbox.find('xmin').text) / shape[1]
float(bbox.find('ymax').text) / shape[0]
float(bbox.find('xmax').text) / shape[1]
完整代码:
def _process_image(dataset_dir, img_name):
"""
处理一张图片的逻辑
:param dataset_dir:
:param img_name:
:return:
"""
# 处理图片
# 该图片的文件名字
filename = dataset_dir + DIRECTORY_IMAGES + img_name + '.jpg'
print(filename)
print("--------")
# 读取图片
image_data = tf.gfile.FastGFile(filename, 'rb').read()
# 处理xml
filename_xml = dataset_dir + DIRECTORY_ANNOTATIONS + img_name + ".xml"
# 用ET读取
tree = ET.parse(filename_xml)
root = tree.getroot()
# 处理每一个标签
# size:height, width, depth
# 一张图片只有这三个属性
size = root.find('size')
shape = [int(size.find('height').text),
int(size.find('width').text),
int(size.find('depth').text)]
# object:name, truncated, difficult, bndbox(xmin,ymin,xmax,ymax)
# 定义每个属性的列表,装有不同对象
# 一张图片会有多个对象findall
bboxes = []
difficult = []
truncated = []
# 装有所有对象名字
# 对象的名字怎么存储???
labels = []
labels_text = []
for obj in root.findall('object'):
# name
label = obj.find('name').text
# 存进对象对应的物体类别数据
labels.append(int(VOC_LABELS[label][0]))
labels_text.append(label.encode('ascii'))
# difficult
if obj.find('difficult'):
difficult.append(int(obj.find('difficult').text))
else:
difficult.append(0)
# truncated
if obj.find('truncated'):
truncated.append(int(obj.find('truncated').text))
else:
truncated.append(0)
# bndbox [[12,23,34,45], [56,23,76,9]]
bbox = obj.find('bndbox')
# xmin,ymin,xmax,ymax都要进行除以原图片的长宽
bboxes.append((float(bbox.find('ymin').text) / shape[0],
float(bbox.find('xmin').text) / shape[1],
float(bbox.find('ymax').text) / shape[0],
float(bbox.find('xmax').text) / shape[1]))
return image_data, shape, bboxes, difficult, truncated, labels, labels_text
用到的配置文件
# VOC 2007物体类别
VOC_LABELS = {
'none': (0, 'Background'),
'aeroplane': (1, 'Vehicle'),
'bicycle': (2, 'Vehicle'),
'bird': (3, 'Animal'),
'boat': (4, 'Vehicle'),
'bottle': (5, 'Indoor'),
'bus': (6, 'Vehicle'),
'car': (7, 'Vehicle'),
'cat': (8, 'Animal'),
'chair': (9, 'Indoor'),
'cow': (10, 'Animal'),
'diningtable': (11, 'Indoor'),
'dog': (12, 'Animal'),
'horse': (13, 'Animal'),
'motorbike': (14, 'Vehicle'),
'person': (15, 'Person'),
'pottedplant': (16, 'Indoor'),
'sheep': (17, 'Animal'),
'sofa': (18, 'Indoor'),
'train': (19, 'Vehicle'),
'tvmonitor': (20, 'Indoor'),
}
- 3、将每次读取内容存入TFRecord文件
对每个图片构造example
def _convert_to_example(image_data, shape, bboxes, difficult,
truncated, labels, labels_text):
"""
图片数据封装成example protobufer
:param image_data: 图片内容
:param shape: 图片形状
:param bboxes: 每一个目标的四个位置值
:param difficult: 默认0
:param truncated: 默认0
:param labels: 目标代号
:param labels_text: 目标名称
:return:
"""
# [[12,23,34,45], [56,23,76,9]] --->ymin [12, 56], xmin [23, 23], ymax [34, 76], xmax [45, 9]
# bboxes的格式转换
ymin = []
xmin = []
ymax = []
xmax = []
for b in bboxes:
ymin.append(b[0])
xmin.append(b[1])
ymax.append(b[2])
xmax.append(b[3])
image_format = b'JPEG'
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': int64_feature(shape[0]),
'image/width': int64_feature(shape[1]),
'image/channels': int64_feature(shape[2]),
'image/shape': int64_feature(shape),
'image/object/bbox/xmin': float_feature(xmin),
'image/object/bbox/xmax': float_feature(xmax),
'image/object/bbox/ymin': float_feature(ymin),
'image/object/bbox/ymax': float_feature(ymax),
'image/object/bbox/label': int64_feature(labels),
'image/object/bbox/label_text': bytes_feature(labels_text),
'image/object/bbox/difficult': int64_feature(difficult),
'image/object/bbox/truncated': int64_feature(truncated),
'image/format': bytes_feature(image_format),
'image/encoded': bytes_feature(image_data)}))
return example
这里需要用到常用TF进行封装Example的接口,所以统一放在一起,放在dataset_utils文件夹下
import tensorflow as tf
def int64_feature(value):
"""包裹int64型特征到Example
"""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def float_feature(value):
"""包裹浮点型特征到Example
"""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def bytes_feature(value):
"""包裹字节类型特征到Example
"""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
3.3.4 总结
- 掌握XML文件内容的读取
- 掌握Example的构造
名词解释链接
Anchor机制是什么?
目标检测|YOLO原理与实现
目标检测|SDD原理与实现