tensorflow基于BERT训练文本分类模型保存为PB(saved model)并部署
扫码关注“自然语言处理与算法”,讨论交流、顶会论文解读~

背景
基于BERT构建了文本分类任务,由于需要将模型部署至服务器,所以将模型保存为pb形式。
模型架构:BERT+softmax
模型保存策略:先将模型保存为ckpt形式然后转换为pb形式。
转换为pb形式时需要指定模型的输入节点,代码如下:
def serving_input_fn():
# 保存模型为SaveModel格式
# 采用最原始的feature方式,输入是feature Tensors。
# 如果采用build_parsing_serving_input_receiver_fn,则输入是tf.Examples
label_ids = tf.placeholder(tf.int32, [None, 3], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, 200], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, 200], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, 200], name='segment_ids')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
})()
return input_fn
将ckpt转换为pb形式的代码,这里是在do_eval的时候:
if FLAGS.do_eval:
# trans_model_dir模型转换后输出目录
estimator._export_to_tpu = False
estimator.export_savedmodel(FLAGS.trans_model_dir, serving_input_fn)
生成的SaveModel:

variables文件下:

检查模型(命令行输入):
saved_model_cli show --dir save_model/output --all
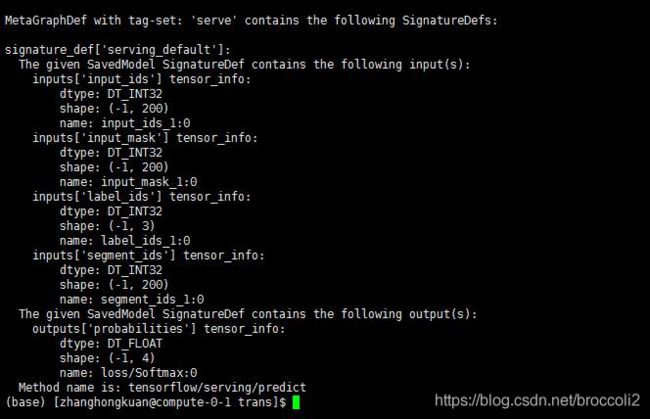
上图中有输入节点input_ids、input_mask、segment_ids、label_ids,以及输出节点probabilities。将测试数据对应的tensor输入到对应的输入节点即可调用训练好的模型进行计算,然后调用输出节点probabilities即可得到对应的值,这里得到的是概率值,是一个list列表,使用numpy中的argmax即可得到对应的label。这个地方回头会单独发一篇博客。
BERT文本分类完整源码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import csv
import os
from bert import tokenization, modeling, optimization
import tensorflow as tf
import pickle
flags = tf.flags
FLAGS = flags.FLAGS
## Required parameters
flags.DEFINE_string(
"data_dir", None,
"The input data dir. Should contain the .tsv files (or other data files) "
"for the task.")
flags.DEFINE_string(
"bert_config_file", None,
"The config json file corresponding to the pre-trained BERT model. "
"This specifies the model architecture.")
flags.DEFINE_string("task_name", None, "The name of the task to train.")
flags.DEFINE_string("vocab_file", None,
"The vocabulary file that the BERT model was trained on.")
flags.DEFINE_string(
"output_dir", None,
"The output directory where the model checkpoints will be written.")
flags.DEFINE_string(
"trans_model_dir", None,
"The trans_model_dir directory where the model will be written.")
## Other parameters
flags.DEFINE_string(
"init_checkpoint", None,
"Initial checkpoint (usually from a pre-trained BERT model).")
flags.DEFINE_bool(
"do_lower_case", True,
"Whether to lower case the input text. Should be True for uncased "
"models and False for cased models.")
flags.DEFINE_integer(
"max_seq_length", 200,
"The maximum total input sequence length after WordPiece tokenization. "
"Sequences longer than this will be truncated, and sequences shorter "
"than this will be padded.")
flags.DEFINE_bool("do_train", False, "Whether to run training.")
flags.DEFINE_bool("do_eval", False, "Whether to run eval on the dev set.")
flags.DEFINE_bool(
"do_predict", False,
"Whether to run the model in inference mode on the test set.")
flags.DEFINE_integer("train_batch_size", 32, "Total batch size for training.")
flags.DEFINE_integer("eval_batch_size", 8, "Total batch size for eval.")
flags.DEFINE_integer("predict_batch_size", 8, "Total batch size for predict.")
flags.DEFINE_float("learning_rate", 5e-5, "The initial learning rate for Adam.")
flags.DEFINE_float("num_train_epochs", 3.0,
"Total number of training epochs to perform.")
flags.DEFINE_float(
"warmup_proportion", 0.1,
"Proportion of training to perform linear learning rate warmup for. "
"E.g., 0.1 = 10% of training.")
flags.DEFINE_integer("save_checkpoints_steps", 1000,
"How often to save the model checkpoint.")
flags.DEFINE_integer("iterations_per_loop", 1000,
"How many steps to make in each estimator call.")
flags.DEFINE_bool("use_tpu", False, "Whether to use TPU or GPU/CPU.")
tf.flags.DEFINE_string(
"tpu_name", None,
"The Cloud TPU to use for training. This should be either the name "
"used when creating the Cloud TPU, or a grpc://ip.address.of.tpu:8470 "
"url.")
tf.flags.DEFINE_string(
"tpu_zone", None,
"[Optional] GCE zone where the Cloud TPU is located in. If not "
"specified, we will attempt to automatically detect the GCE project from "
"metadata.")
tf.flags.DEFINE_string(
"gcp_project", None,
"[Optional] Project name for the Cloud TPU-enabled project. If not "
"specified, we will attempt to automatically detect the GCE project from "
"metadata.")
tf.flags.DEFINE_string("master", None, "[Optional] TensorFlow master URL.")
flags.DEFINE_integer(
"num_tpu_cores", 8,
"Only used if `use_tpu` is True. Total number of TPU cores to use.")
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
class PaddingInputExample(object):
"""Fake example so the num input examples is a multiple of the batch size.
When running eval/predict on the TPU, we need to pad the number of examples
to be a multiple of the batch size, because the TPU requires a fixed batch
size. The alternative is to drop the last batch, which is bad because it means
the entire output data won't be generated.
We use this class instead of `None` because treating `None` as padding
battches could cause silent errors.
"""
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
input_ids,
input_mask,
segment_ids,
label_id,
is_real_example=True):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
self.is_real_example = is_real_example
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.gfile.Open(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
'''自定义的processor'''
from sklearn.utils import shuffle
import pandas as pd
class MyProcessor(DataProcessor):
# 读取文件
def read_txt(self, filepath, type):
df = pd.read_csv(filepath + '/' + type + '.csv', delimiter=",", names=['labels', 'text'], header=None, engine='python')
df = shuffle(df) # shuffle数据
lines = []
for data in df.iloc[:].itertuples():
content = str(data.labels) + "\t" + str(data.text)
lines.append(content)
return lines
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self.read_txt(data_dir, 'train'), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self.read_txt(data_dir, 'dev'), "dev")
# def get_test_examples(self, data_dir):
# """See base class."""
# return self._create_examples(
# self.read_txt(os.path.join(data_dir, "cnews.test.txt"), "test"), "test")
def get_labels(self):
"""See base class."""
df = pd.read_csv(FLAGS.data_dir + '/dev.csv', delimiter=",", names=['labels', 'text'], header=None)
labels_df = df[['labels']]
labels_df = labels_df.drop_duplicates()
labels = []
for data in labels_df.iloc[:].itertuples():
labels.append(data.labels)
# with open('./labels.txt', 'w', encoding='utf-8')as f4:
# f4.write(str(labels))
#labels = ['0','1','2']
return labels
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
split_line = line.strip().split("\t")
text_a = tokenization.convert_to_unicode(split_line[1])
text_b = None
if set_type == "test":
label = "6efaa392"
else:
label = tokenization.convert_to_unicode(split_line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def serving_input_fn():
'''
指定输入结点,测试时通过name属性传值,在模型进行do_eval时将此函数转入estimator.export_savedmodel(FLAGS.trans_model_dir, serving_input_fn)
保存模型为SaveModel格式
采用最原始的feature方式,输入是feature Tensors。
如果采用build_parsing_serving_input_receiver_fn,则输入是tf.Examples
'''
label_ids = tf.placeholder(tf.int32, [None, 3], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, 200], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, 200], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, 200], name='segment_ids')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
})()
return input_fn
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
if isinstance(example, PaddingInputExample):
return InputFeatures(
input_ids=[0] * max_seq_length,
input_mask=[0] * max_seq_length,
segment_ids=[0] * max_seq_length,
label_id=0,
is_real_example=False)
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
# 保存标签信息和枚举的映射关系 并写入label2id.pkl 该文件会一起输出到trans_model_dir文件夹下
output_label2id_file = os.path.join(FLAGS.trans_model_dir, "label2id.pkl")
if not os.path.exists(output_label2id_file):
with open(output_label2id_file, 'wb') as w:
pickle.dump(label_map, w)
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: %s (id = %d)" % (example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id,
is_real_example=True)
return feature
def file_based_convert_examples_to_features(
examples, label_list, max_seq_length, tokenizer, output_file):
"""Convert a set of `InputExample`s to a TFRecord file."""
writer = tf.python_io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
features["is_real_example"] = create_int_feature(
[int(feature.is_real_example)])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
writer.close()
def file_based_input_fn_builder(input_file, seq_length, is_training,
drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
name_to_features = {
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
"label_ids": tf.FixedLenFeature([], tf.int64),
"is_real_example": tf.FixedLenFeature([], tf.int64),
}
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
example = tf.parse_single_example(record, name_to_features)
# tf.Example only supports tf.int64, but the TPU only supports tf.int32.
# So cast all int64 to int32.
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.to_int32(t)
example[name] = t
return example
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
# For training, we want a lot of parallel reading and shuffling.
# For eval, we want no shuffling and parallel reading doesn't matter.
d = tf.data.TFRecordDataset(input_file)
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# In the demo, we are doing a simple classification task on the entire
# segment.
#
# If you want to use the token-level output, use model.get_sequence_output()
# instead.
output_layer = model.get_pooled_output()
hidden_size = output_layer.shape[-1].value
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# I.e., 0.1 dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
probabilities = tf.nn.softmax(logits, axis=-1)
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
label_ids = features["label_ids"]
is_real_example = None
if "is_real_example" in features:
is_real_example = tf.cast(features["is_real_example"], dtype=tf.float32)
else:
is_real_example = tf.ones(tf.shape(label_ids), dtype=tf.float32)
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
(total_loss, per_example_loss, logits, probabilities) = create_model(
bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL:
def metric_fn(per_example_loss, label_ids, logits, is_real_example):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(
labels=label_ids, predictions=predictions, weights=is_real_example)
loss = tf.metrics.mean(values=per_example_loss, weights=is_real_example)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
eval_metrics = (metric_fn,
[per_example_loss, label_ids, logits, is_real_example])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
predictions={"probabilities": probabilities},
scaffold_fn=scaffold_fn)
return output_spec
return model_fn
# This function is not used by this file but is still used by the Colab and
# people who depend on it.
def input_fn_builder(features, seq_length, is_training, drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
all_input_ids = []
all_input_mask = []
all_segment_ids = []
all_label_ids = []
for feature in features:
all_input_ids.append(feature.input_ids)
all_input_mask.append(feature.input_mask)
all_segment_ids.append(feature.segment_ids)
all_label_ids.append(feature.label_id)
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
num_examples = len(features)
# This is for demo purposes and does NOT scale to large data sets. We do
# not use Dataset.from_generator() because that uses tf.py_func which is
# not TPU compatible. The right way to load data is with TFRecordReader.
d = tf.data.Dataset.from_tensor_slices({
"input_ids":
tf.constant(
all_input_ids, shape=[num_examples, seq_length],
dtype=tf.int32),
"input_mask":
tf.constant(
all_input_mask,
shape=[num_examples, seq_length],
dtype=tf.int32),
"segment_ids":
tf.constant(
all_segment_ids,
shape=[num_examples, seq_length],
dtype=tf.int32),
"label_ids":
tf.constant(all_label_ids, shape=[num_examples], dtype=tf.int32),
})
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.batch(batch_size=batch_size, drop_remainder=drop_remainder)
return d
return input_fn
# This function is not used by this file but is still used by the Colab and
# people who depend on it.
def convert_examples_to_features(examples, label_list, max_seq_length,
tokenizer):
"""Convert a set of `InputExample`s to a list of `InputFeatures`."""
features = []
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
features.append(feature)
return features
def main(*argv):
base_dir = '/home/zhanghongkuan/BERT-NER-CRF/'
pretrain_dir = base_dir + 'chinese_L-12_H-768_A-12'
output_dir = base_dir + 'output_cls'
trans_model_dir = base_dir + 'output_cls/trans'
task_name = 'cls'
vocab_file = pretrain_dir + '/vocab.txt'
bert_config_file = pretrain_dir + '/bert_config.json'
init_checkpoint = pretrain_dir + '/bert_model.ckpt'
mkdir_dir = lambda x: os.makedirs(x) if not os.path.exists(x) else True # 目录是否存在,不存在则创建
mkdir_dir(trans_model_dir)
FLAGS.task_name = task_name
FLAGS.data_dir = '/home/zhanghongkuan/BERT-NER-CRF/data'
FLAGS.vocab_file = vocab_file
FLAGS.bert_config_file = bert_config_file
FLAGS.output_dir = output_dir
FLAGS.trans_model_dir = trans_model_dir
FLAGS.init_checkpoint = init_checkpoint
FLAGS.do_train = True
FLAGS.do_eval = True
FLAGS.train_batch_size = 16
FLAGS.max_seq_length = 200
FLAGS.num_train_epochs = 5
FLAGS.learning_rate = 1e-5
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"cls": MyProcessor
}
tokenization.validate_case_matches_checkpoint(FLAGS.do_lower_case,
FLAGS.init_checkpoint)
if not FLAGS.do_train and not FLAGS.do_eval and not FLAGS.do_predict:
raise ValueError(
"At least one of `do_train`, `do_eval` or `do_predict' must be True.")
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file)
if FLAGS.max_seq_length > bert_config.max_position_embeddings:
raise ValueError(
"Cannot use sequence length %d because the BERT model "
"was only trained up to sequence length %d" %
(FLAGS.max_seq_length, bert_config.max_position_embeddings))
tf.gfile.MakeDirs(FLAGS.output_dir)
task_name = FLAGS.task_name.lower()
if task_name not in processors:
raise ValueError("Task not found: %s" % (task_name))
processor = processors[task_name]()
label_list = processor.get_labels()
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
tpu_cluster_resolver = None
if FLAGS.use_tpu and FLAGS.tpu_name:
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(
FLAGS.tpu_name, zone=FLAGS.tpu_zone, project=FLAGS.gcp_project)
is_per_host = tf.contrib.tpu.InputPipelineConfig.PER_HOST_V2
run_config = tf.contrib.tpu.RunConfig(
cluster=tpu_cluster_resolver,
master=FLAGS.master,
model_dir=FLAGS.output_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=FLAGS.iterations_per_loop,
num_shards=FLAGS.num_tpu_cores,
per_host_input_for_training=is_per_host))
train_examples = None
num_train_steps = None
num_warmup_steps = None
if FLAGS.do_train:
train_examples = processor.get_train_examples(FLAGS.data_dir)
num_train_steps = int(
len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs)
num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion)
model_fn = model_fn_builder(
bert_config=bert_config,
num_labels=len(label_list),
init_checkpoint=FLAGS.init_checkpoint,
learning_rate=FLAGS.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
use_tpu=FLAGS.use_tpu,
use_one_hot_embeddings=FLAGS.use_tpu)
# If TPU is not available, this will fall back to normal Estimator on CPU
# or GPU.
estimator = tf.contrib.tpu.TPUEstimator(
use_tpu=FLAGS.use_tpu,
model_fn=model_fn,
config=run_config,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=FLAGS.eval_batch_size,
predict_batch_size=FLAGS.predict_batch_size)
if FLAGS.do_train:
train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
tf.logging.info("***** Running training *****")
tf.logging.info(" Num examples = %d", len(train_examples))
tf.logging.info(" Batch size = %d", FLAGS.train_batch_size)
tf.logging.info(" Num steps = %d", num_train_steps)
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
if FLAGS.do_eval:
eval_examples = processor.get_dev_examples(FLAGS.data_dir)
num_actual_eval_examples = len(eval_examples)
if FLAGS.use_tpu:
# TPU requires a fixed batch size for all batches, therefore the number
# of examples must be a multiple of the batch size, or else examples
# will get dropped. So we pad with fake examples which are ignored
# later on. These do NOT count towards the metric (all tf.metrics
# support a per-instance weight, and these get a weight of 0.0).
while len(eval_examples) % FLAGS.eval_batch_size != 0:
eval_examples.append(PaddingInputExample())
eval_file = os.path.join(FLAGS.output_dir, "eval.tf_record")
file_based_convert_examples_to_features(
eval_examples, label_list, FLAGS.max_seq_length, tokenizer, eval_file)
tf.logging.info("***** Running evaluation *****")
tf.logging.info(" Num examples = %d (%d actual, %d padding)",
len(eval_examples), num_actual_eval_examples,
len(eval_examples) - num_actual_eval_examples)
tf.logging.info(" Batch size = %d", FLAGS.eval_batch_size)
# This tells the estimator to run through the entire set.
eval_steps = None
# However, if running eval on the TPU, you will need to specify the
# number of steps.
if FLAGS.use_tpu:
assert len(eval_examples) % FLAGS.eval_batch_size == 0
eval_steps = int(len(eval_examples) // FLAGS.eval_batch_size)
eval_drop_remainder = True if FLAGS.use_tpu else False
eval_input_fn = file_based_input_fn_builder(
input_file=eval_file,
seq_length=FLAGS.max_seq_length,
is_training=False,
drop_remainder=eval_drop_remainder)
result = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps)
'''trans_model_dir模型转换后输出目录,将模型转换为saved model'''
estimator._export_to_tpu = False
estimator.export_savedmodel(FLAGS.trans_model_dir, serving_input_fn)
output_eval_file = os.path.join(FLAGS.output_dir, "eval_results.txt")
with tf.gfile.GFile(output_eval_file, "w") as writer:
tf.logging.info("***** Eval results *****")
for key in sorted(result.keys()):
tf.logging.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
if FLAGS.do_predict:
predict_examples = processor.get_test_examples(FLAGS.data_dir)
num_actual_predict_examples = len(predict_examples)
if FLAGS.use_tpu:
# TPU requires a fixed batch size for all batches, therefore the number
# of examples must be a multiple of the batch size, or else examples
# will get dropped. So we pad with fake examples which are ignored
# later on.
while len(predict_examples) % FLAGS.predict_batch_size != 0:
predict_examples.append(PaddingInputExample())
predict_file = os.path.join(FLAGS.output_dir, "predict.tf_record")
file_based_convert_examples_to_features(predict_examples, label_list,
FLAGS.max_seq_length, tokenizer,
predict_file)
tf.logging.info("***** Running prediction*****")
tf.logging.info(" Num examples = %d (%d actual, %d padding)",
len(predict_examples), num_actual_predict_examples,
len(predict_examples) - num_actual_predict_examples)
tf.logging.info(" Batch size = %d", FLAGS.predict_batch_size)
predict_drop_remainder = True if FLAGS.use_tpu else False
predict_input_fn = file_based_input_fn_builder(
input_file=predict_file,
seq_length=FLAGS.max_seq_length,
is_training=False,
drop_remainder=predict_drop_remainder)
result = estimator.predict(input_fn=predict_input_fn)
output_predict_file = os.path.join(FLAGS.output_dir, "test_results.tsv")
with tf.gfile.GFile(output_predict_file, "w") as writer:
num_written_lines = 0
tf.logging.info("***** Predict results *****")
for (i, prediction) in enumerate(result):
probabilities = prediction["probabilities"]
if i >= num_actual_predict_examples:
break
output_line = "\t".join(
str(class_probability)
for class_probability in probabilities) + "\n"
writer.write(output_line)
num_written_lines += 1
assert num_written_lines == num_actual_predict_examples
if __name__ == "__main__":
# flags.mark_flag_as_required("data_dir")
# flags.mark_flag_as_required("task_name")
# flags.mark_flag_as_required("vocab_file")
# flags.mark_flag_as_required("bert_config_file")
# flags.mark_flag_as_required("output_dir")
# tf.app.run()
main()
调用模型进行预测之前需要先把输入数据转换为BERT要求的input_ids、input_mask、segment_ids
请转向我的另一篇博客中文文本转换为bert输入的input_ids、input_mask、segment_ids
参考:
BERT-Tensorflow模型部署(CPU版和GPU版)