linux进程管理
Linux kernel 进程管理
1 进程描述符和task结构体
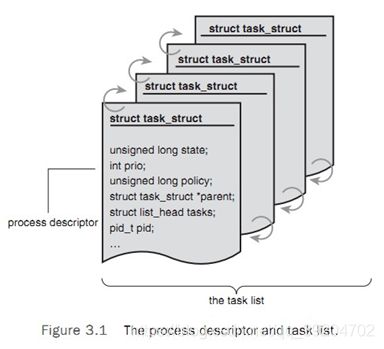
内核把进程列表存储在一个双向循环链表中 task list;task list中的每个元素都是struct task_struct的一个进程描述符,defined in
① 分配进程描述符
Task_struct结构体通过slab分配器分配(它提供了对象的重利用和cache的染色);在2.6版本的内和之前,task_struct结构体存储在每个进程中kernel stack的末尾。这允许一些架构(比如说X86)可以利用少数的寄存器来计算进程描述符的位置,通过stack指针而不需要利用额外的寄存器存储这个位置。随着进程描述符可以利用slab分配器动态创建,一个新的数据结构struct thread_info被创建了,或者存在与stack底部(stack向下生长),或者存在于stack顶部(stack向上生长)。Figure3-2展示了这种结构;
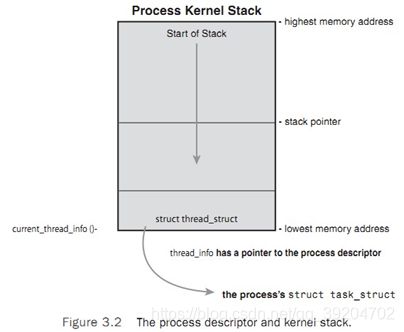
Struct thread_info结构体在X86结构中的定义在中;
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
}
每个任务的thread_info结构体被分配在stack的结尾部分。这个结构体重的task元素是一个指向实际task_struct结构体的指针。
② 存储进程描述符
系统通过唯一的PID来识别进程;PID是一种数字参数,它使用不透明的pid_t类型来表示,但它通常是int类型。由于兼容早些Linux版本的原因,默认的最大参数为32768(that is a short int),但是这项参数是可以在正确的范围内增加的。Kernel把这项参数作为pid存储在每一个进程描述符中。
这项参数是很重要的,因为这预示着系统同时运行的最大进程数。虽然32768对于桌面系统来说足够使用了,更大的服务器可能需要更多的进程。这项参数越小,这项参数的遍历越快。如果系统想要打破旧的应用的兼容性的话,管理员需要增加最大值,通过/proc/sys/kernel/pid_max来设置。
在内核当中,任务通常由指向其任务结构的指针直接引用。实际上在大多数处理进程的内核code中,都是直接使用task_struct的。因此,快速找到当前运行任务的进程描述符就变得非常重要,这可以通过current宏来实现;current宏根据不同硬件架构的不一致,他的实现方式各异。有些架构保存一个指针,指向当前运行进程的task_struct,这就是这种访问很高效。其他的架构,比如说X86(which has a few register to waste),采用了这样一种方式:把struct thread_info存储在kernel stack去计算thread_info的位置,因此就可以获知task_struct。
③ 进程状态
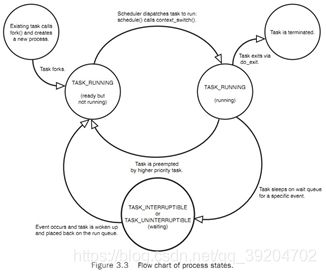
进程描述符的state field描述了进程的当前状态(see figure3.3).Each process都处于五种状态中的一种。如下参数的值代表了五种状态:
TASK_RUNNING:
该任务正在运行或者在等待运行的任务队列中.
TASK_INTERRUPTIBLE:
该任务处于睡眠状态,等待某一个条件或信号来唤醒进TASK_RUNNING状态.
TASK_UNINTERRUPTBLE:
该状态和TASK_INTERRUPTIBLE一样,区别在于接收到信号后并不被唤醒.使用要比TASK_INTERRUPTIBLE少.
TASK_ZOMBIE:
进程被终止,但是他的父进程还没有执行wait4()系统调用;
TASK_STOPPED:
程序执行被停止,将不会运行或者有资格运行.当任务接收到 SIGSTOP,SIGSTP,SIGTTIN,SIGTTOU或者在调试时接收到任何其他信号.
④ 更改当前进程状态
Kernel代码有时候需要更改进程的运行状态;优先推荐的办法是使用set_task_state(task,state);这个函数设置task到指定的状态。如果是可用的话,他也会提供一种内存屏障去强制在其他处理器上排序(这仅仅是SMP系统所需要的)。
当然,这也等于如下机制:task->state = state;set_current_state(state)等同于set_task_state(current,state);
⑤ 进程上下文
进程中的最重要的部分之一是正在执行程序的code。这code是从可执行文件中读取而来,在程序的地址空间运行。通常的程序执行是发生在用户空间的。当程序运行系统调用的时候或者触发了exception的时候,他就进入了内和空间。基于这种观点,当kernel在代表进程在运行的时候,它在进程上下文。当处于进程上下文中的时候,current宏是有效的。退出内核后,进程会恢复在用户空间的执行;如果在退出内核后,有更高优先级的任务变得runnable的话,调度器会选择更高优先级的任务去执行。
系统调用和exception handler在内核中是定义好接口的;进程只可以通过这些接口在内核空间中开始执行,ps:所有访问内核的通道都是通过这些接口。
⑥ 进程的Family tree
在Linux和Unix系统中的进程之间存在着明确的层级关系;所有的进程都是Init进程的子进程(他的pid为1)。内核在boot阶段的最后阶段开启init进程。Init进程读取系统初始化脚本和执行其他更多的程序,最终完成Boot的过程。
系统中的每一个进程都有一个明确的父进程;类似的,每个进程都有一个或者0个子进程。拥有同一个父进程的所有子进程叫做兄弟姐妹进程。进程之间的关系存储在进程描述符中。每一个stcuct task_struct都有一个指针指向父进程的task_struct,叫做parent,以及a list of children,叫做children。因此,给出当前进程的信息,可以获取到他的父进程的描述符,使用如下的办法:
Struct task_struct *my_parent = current->parent;
相同地,你也可以获取到他的子进程,使用如下的办法:
struct task_struct *task;
struct list_head *list;
list_for_each(list, ¤t->children) {
task = list_entry(list, struct task_struct, sibling);
/* task now points to one of current’s children */
}
Init进程描述符是静态分配的,named init_task;所有进程之间的关系的良好举例就是如下代码可以成功运行:
struct task_struct *task;
for (task = current; task != &init_task; task = task->parent)
;
/* task now points to init */
事实上,你也可以通过进程之间的层级关系来获知其他进程。但是通常情况下,在系统中递归全部进程是相当简单的办法,原因是task list是一个双向的循环链表;为了获取下一个task,给出一个有效的task,使用如下的办法即可:
list_entry(task->tasks.next, struct task_struct, tasks)
获取上一个的办法也是类似的:
list_entry(task->tasks.prev, struct task_struct, tasks)
上述两种办法你也可以通过宏next_task(task)和prev_task(task)来实现;在每一个递归中,task指向list中的下一个task:
struct task_struct *task;
for_each_process(task) {
/* this pointlessly prints the name and PID of each task */
printk(“%s[%d]\n”, task->comm, task->pid);
}
Note:在一个多进程的系统中,递归查找每一个task可能是付出很高的时间代价的;在做类似的code的时候需要深思熟虑,并且有合理的原因。
2、进程创建
大多数操作系统通过实现spawn的机制,在新的地址空间创建新的进程、在可执行文件中读取code、开始执行;Unix把这些步骤分开为两个函数:fork()和exec();frok()通过复制当前进程创建子进程;子进程和父进程的区别在于不同的PID(which is unique)和PPID(parent’s pid)、和一些资源,比如说信号(这些是不继承的);exec()加载可执行代码到地址空间并开始执行。通过fork()和exec()实现的机制和大多数操作系统是类似的。
① copy-on-Write
通常情况下,在fork()之后,所有父进程拥有的资源都会被复制,并拷贝给子进程;如果拷贝了大量数据(might be shared),这种办法是非常低效的;更糟糕的是,如果新进程去执行新的镜像文件,所有拷贝的数据就浪费掉了。在Linux中,fork()是通过一种copy-on-write的机制来实现的;copy-on-write(COW)是一种可以延迟或者阻止拷贝数据的技术。除了拷贝进程地址空间,父进程和子进程可以共享一份拷贝。但是数据部分的话,会被标记一种方式:如果需要写入的话,开始复制数据并且每个进程都会接收到一份独有的拷贝。因此,资源的复制动作仅仅在当需要写入动作的时候才会发生。到写入动作之前,他们仅仅通过只读的方式共享。这项技术延迟了每一页的拷贝操作,除非他真正开始写入的动作。在pages从来不会被改写的情况下,他们从来不会被拷贝。Fork()唯一的消耗就是父进程页表的复制和子进程独有描述符的创建。
通常情况下,进程fork()之后,立即开始执行新的可执行镜像,COW的优化阻止了拷贝大量数据的浪费动作(在地址空间内,很容易达到几十兆bytes)。这项优化很重要,因为Unix的哲学鼓励进程快速执行。
② fork()
Linux通过clone()系统调用完成fork();this call可以输入多个flag:这些flag指定了父进程和子进程之间需要共享的资源类型。Fork()、vfork()、_clone()等都需要调用clone()系统调用,clone()可以输入多个flags。接下来clone()调用do_fork()。
Fork的大量工作实际上是由do_fork完成的(which is defined in kernel/fork.c)。这个函数调用copy_process(),然后开始运进程。Copy_process()完成的工作如下:
a) It调用dup_task_struct(),它为新的线程创建新的内核stack、thread_info结构体和task_struct;这些新的参数对于当前任务而言是独有的。给予这种策略,父进程和子进程的描述符是独有的。
b) 然后,It检查新的子进程是不是超过了当前用户的进程数目限制。
c) 现在,子进程需要将自己和父进程进行区分。进程描述符中的各种成员变量都被清除了或者设置为初始值。没有被继承的进程描述符的成员变量保持原来的信息。进程描述符中的大量data是共享的。
d) 接下来,子进程的状态设置为TASK_UNINTERRUPTBLE,来确保它不会运行。
e) 现在,copy_process()调用copy_flags()去更新task_struct成员中的flags变量。清除PF_SUPERPRIV flag,该变量用来指出a task是否使用super-user privilege。设置PF_FORKNOEXEC flag,该变量用来指出a process还没有调用exec()。
f) 接下来,调用get_pid(),分配一个可用的pid给新的task。
g) 取决于传递给clone()的flags,copy_process()复制或者共享打开的文件、文件系统信息、信号处理函数、进程地址空间和name space;否则的话,他们是独有的,并拷贝到这里。
h) 接下来,remaining的时间片(between parent and child)被一分为2;
i) 最终,copy_process() cleans up并返回指向新的进程的指针。
返回到do_fork(),如果copy_process返回成功,新的子进程将会唤醒并运行。因此,内核会先运行子进程。在通常情况下,子进程立刻调用exec(),这就去除了copy-on-write的负载;相反,如果先运行父进程并开始写入地址空间的话,将会产生一定的overhead。
③ vfork()
Vfork()和fork()两个系统调用的作用基本是相同的,但是vfork是不复制父进程的页表的。Instead,子进程是作为单一线程在父进程的地址空间执行的,在子进程调用exec()或者退出之前,父进程都是blocked。子进程是不允许向地址空间写入的。This is a welcome 优化机制 in the old days of 3BSD when the call is introduced,因为在那个时候,copy-on-write的pages还不是用来完成fork()。今天,随着copy-on-write和子进程优先运行机制的出现,vfork的唯一优势就是不拷贝父进程的页表。如果有一天Linux增加了copy-on-write页表,vfork就没有任何优势了。
由于vfork()的机制是有风险的,所以说如果vfork died很慢很痛苦就好了;vfork系统调用是通过一些特殊的flag给clone系统调用实现的。
a) 在copy_process中,task_struct结构体成员vfork_done被设置为NULL;
b) 在do_fork中,如果设置了特定的flag,vfork_done会被指向特定的地址空间;
c) 子进程运行之后,父进程等待子进程的信号,这个信号通过vfork_done指针实现;
d) 在mm_realease()函数中(当任务退出内存空间的时候,他会被使用到),vfork_done被检查是否为空。如果他不为空的话,parent会被signal到;
e) 返回到do_fork,父进程被唤醒并返回;
如果上述过程按计划完成了的话,子进程现在在新的地址空间执行,父进程在原来的地址空间又一次执行。这样的overhead是比较低的,但是设计的话不是很好。
3、 Linux线程的实现机制
Threads are a popular moden programming abstraction.使用同一个program在共享内存的地址空间实现多个线程;他们还可以共享打开的文件和其他的资源;线程是允许并发programming的,并且在多处理器系统中,可以实现真正的并发;
Linux实现线程(thread)的机制是独特的;对于Linux kernel而言,没有线程的概念;Linux完成所有的线程都是按照标准进程来实现的;Linux kernel也不会提供特殊的调度机制或者数据结构给线程;Instead,threads几乎就是一个进程(which和其他进程共享一些资源);每个thread都拥有一个独有的task_struct结构体,内核视他为一个normal进程。
① 内核线程
内核线程是仅仅存在于内核地址空间的标准进程;内核线程和通常的进程的最显著的区别就是内核进程没有地址空间(也就是说mm指针是NULL的)。它仅仅在内核空间中运行,并且不会切换到用户空间。但是内核线程和通常的进程一样是可调度、可抢占的;
Linux分配了一些任务给内核线程,比如说pdflush和ksoftirq等;这些线程是其他进程在内核启动的时候创建的;事实上,内核线程仅能由其他的进程创建;创建新的内核线程的接口是这样的:
Int kernel_thread(int (* fn)( void *), void *arg, unsigned long flags);
新的任务是通过clone系统调用(结合一些特定的flags)来创建的;on return,父进程退出with a pointer指向子进程的task_struct。子进程执行的函数是由函数指针fn提供的。一个特殊的flag,CLONE_KERNEL指出了是为kernel线程使用的:CLONE_FS,CLONE_FILES,CLONE_SIGHAND.大多数的内核线程都是传递这个flags。
通常情况下,内核线程会一直执行他的initial函数。这个initial函数通常是实现一个循环,在这个循环中内核线程在需要的时候会被唤醒,执行特定的任务,然后再睡眠。
4、 进程的终止
进程结束的时候,内核释放相关的资源并通知子进程,父进程已经结束了;当进程接收到exit()的系统调用后,进程结束(这通常是他准备结束了或者main()返回后,放置exit());进程还可能是involuntarily的方式结束,比如说:接收到了结束信号、出现了不能处理的exception;无论进程是以哪种方式结束的,exit的工作有do_exit()完成,实现的工作内容如下(具体在文章中已经详细列出,the linux kernel development 3.rd);
do_exit()的code在kernel/exit.c中实现;执行完do_exit后,跟该task相关的资源已经全部释放;the task不再运行,处于TASK_ZOMBIE状态;the task占用的唯一内存只是在kernel stack,包括thread info和task struct。The task exists solely to provide info to its parent.Parent获取到信息后或者通知内核the task is uninterested,the process剩下的内存将会释放并返回给系统使用;
① 移除进程描述符
After do_exit,结束的进程的进程描述符依然存在,但是他已经是僵尸态了不能运行。As discussed,这可以是系统获取他的子进程的信息,即使这个进程已经结束了。因此after a process的清理工作和移除进程描述符的工作是分开的。在parent已经在终止的子进程上获取到了信息或者通知内核is doesn’t care,子进程的task_struct就可以重新分配了。
The wait系列的函数是通过一个简单的系统调用实现的,wait4();标准做法是在他的子进程中的其中一个退出后暂停当前的task,在这个时候,the function返回了退出的子进程的PID。除此之外,还提供给这个函数一个指针,用来存储终止的子进程的退出处理代码。
当重新分配进程描述符的时候,涉及到release_task();他会执行如下的工作:
First:调用free_uid,减少process的用户计数;Linux给每个用户分配了一定的cache用来统计信息,这些信息包括每 个用户打开的进程数量、打开的文件数量。如果这项计数减到0的话,the user就没有打开的文件和进程了,the cache就会被释放掉。
Second:release_task调用unhash_process将进程从pidhash中移除,从task list中移除;
Third:如果task是有被继承关系的,release_task把子进程重定向到他的父进程并把它从ptrace list中移除;
Finally:release_task调用put_call_struct来释放pages(这pages包含进程的内核堆栈信息和thread info结构体),重新分配slab cache(包含task struct);
在这之后,进程描述符和跟进程相关的所有资源都已经被释放了。
② Parentless task的处理
如果父进程在子进程之前退出,必须有一些机制来保证重新分配新的父进程给子进程,否则的话,没有父进程终止的进程将会一直保持僵尸态,浪费系统资源。这种机制就是把子进程重新分配给当前thread group的其他进程,如果是失败的话,就重定向给Init进程。在do_exit中,notify_parent()涉及到相关的工作,它调用forget_original_parent()来执行相关动作;这包括,设置reaper给同一个thread group的另一个任务;如果当前thread group没有其他的任务,就会设置给Init process;
通过这种机制的实现,就可以避免僵尸进程的出现;init进程通常对其子进程调用wait(),清除分配给它的任何僵尸。
最近在阅读linux kernel developement 3.rd,上传一部分作为自己的阅读笔记;