PyTorch 1.7来了!支持Windows上的分布式训练,还有大波API袭来
据Facebook 官方博客公告,PyTorch1.7版本已经于前日正式发布,相比于以往的 PyTorch 版本,此次更新除了增加了更多的API,还能够支持 NumPy兼容下的傅里叶变换、性能分析工具,以及对基于分布式数据并行(DDP)和远程过程调用(RPC)的分布式训练。
此外,原有的一些功能也转移到了稳定版,包括自定义C++ -> 类(Classes)、内存分析器、通过自定义张量类对象进行的扩展、RPC中的用户异步功能以及Torch.Distributed中的许多其他功能,如Per-RPC超时、DDP动态分组(bucketing)和RRef助手。
其中一些亮点包括:
1、PyTorch.org上提供的二进制文件现在正式支持CUDA 11
2、对Autograd分析器中的RPC、TorchScript和堆栈跟踪的分析和性能进行了更新和添加。
3、(测试版)通过torch.fft支持NumPy兼容的快速傅立叶变换(FFT)。
4、(原型)支持NVIDIA A100 GPU和本地的TF32格式。
5、(原型)支持Windows上的分布式训练
6、torchvision
- (稳定)变换现在支持张量输入、批处理计算、GPU和TorchScript
- (稳定)JPEG和PNG格式的本机映像I/O
- (测试版)新的视频阅读器API
7、torchaudio
- (稳定)增加了对语音录制(Wav2Letter)、文本到语音(WaveRNN)和源分离(ConvTasNet)的支持。
注:从Pytorch1.6版本开始,PyTorch 的特性将分为 Stable(稳定版)、Beta(测试版)和 Prototype(原型版)
1 前端接口
[测试版]与Numpy兼容的TORCH.FFT模块
与FFT相关的功能通常用于各种科学领域,如信号处理。虽然PyTorch过去一直支持一些与FFT相关的函数,但1.7版本添加了一个新的torch.fft模块,该模块使用与NumPy相同的API实现与FFT相关的函数。此新模块必须导入才能在1.7版本中使用,因为它的名称与之前(现已弃用)的torch.fft函数冲突。
示例:

[测试版]对转换器NN模块的C++支持
从PyTorch1.5开始,就继续保持了Python和C++前端API之间的一致性。这次更新能够让开发人员使用C++前端的nn.former模块。此外,开发人员不再需要将模块从python/JIT保存并加载到C++中,因为它现在可以在C++中直接使用。
[测试版]TORCH.SET_DESITIAL
再现性(逐位确定性)可能有助于在调试或测试程序时识别错误。为了便于实现重现性,PyTorch 1.7添加了torch.set_defiristic(Bool)函数,该函数可以指导PyTorch操作符选择确定性算法(如果可用),并在操作可能导致不确定性行为时给出运行时错误的标识。
默认情况下,此函数控制的标志为false,这意味着在默认情况下,PyTorch可能无法确定地实现操作。
更准确地说,当此标志为 true时:
1、已知没有确定性实现的操作给出运行时错误;
2、具有确定性变体( variants)的操作使用这些变体(与非确定性版本相比,通常会降低性能);
3、设置:torch.backends.cudnn.deterministic = True .
请注意,对于PyTorch程序的单次运行中的确定性而言,这属于非充分必要条件。还有其他随机性来源也可能导致不确定性行为,例如随机数生成器、未知操作、异步或分布式计算。
2 性能与性能分析
[测试版]在配置文件中添加了堆栈轨迹追踪。
用户现在不仅可以看到分析器输出表中的操作员名称/输入,还可以看到操作员在代码中的位置。在具体工作流程中,只需极少的更改即可利用此功能。
用户像以前一样使用自动评分检测器,但带有可选的新参数:WITH_STACK和GROUP_BY_STACK_n。注意:常规分析运行不应使用此功能,因为它会增加大量成本。
3 分布式训练和RPC
[稳定]TORCHELASTIC现在绑定到PYTORCH DOCKER镜像
Torchelastic提供了一个当前Torch.Distributed的严格superset,启动CLI时增加了容错和弹性功能。如果用户对容错不感兴趣,可以通过设置max_restarts=0获得更加精确的指定。另外,还增加了自动分配RANK和MASTER_ADDR|PORT的便利性。
通过将Torchelastic捆绑在与PyTorch相同的镜像中,用户可以立即开始尝试使用TorchElastic,而不必单独安装Torchelastic。除了方便之外,当在现有Kubeflow的分布式PyTorch操作符中添加对弹性参数的支持时,这项工作也是非常有用的。
[测试版]支持DDP中不均匀的数据集输入
PyTorch1.7引入了一个新的上下文管理器,该管理器将与使用torch.nn.parallel.DistributedDataParallel 训练的模型结合使用,以支持跨进程使用不均匀的数据集进行训练。
此功能在使用DDP时提供了更大的灵活性,用户不用“手动”,就能保证数据集大小相同。使用此上下文管理器,DDP将自动处理不均匀的数据集大小,这可以防止训练结束时出现错误。
[测试版]NCCL可靠性-ASYNC错误/超时处理
在过去,NCCL的训练运行会因为集体卡住而无限期地挂起(hang),使得用户体验非常糟糕。如果检测到潜在的挂起(hang),此功能会给出异常/使进程崩溃的警告。当与torchelastic(它可以恢复“最近”的训练过程)之类的东西一起使用时,分布式训练将更加可靠。
此功能并不强制,属于可选性操作,并且位于需要显式设置才能启用此功能。
[测试版]TORCHSCRIPT RPC_REMOTE和RPC_SYNC
在早期版本中,Torch.Distributed.rpc.rpc_async已在TorchScript中提供。对于PyTorch1.7,此功能将扩展到剩下的两个核心RPCAPI:torch.Distributed.rpc.rpc_sync和torch.Distributed.rpc.remote。
这将完成计划在TorchScript中支持的主要RPC API,它允许用户在TorchScript中使用现有的python RPC API,并可能提高多线程环境中的应用程序性能。
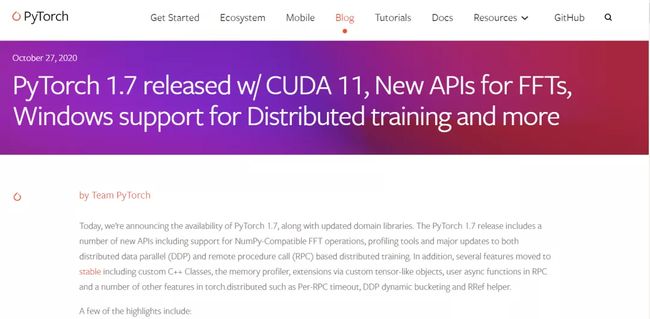
[测试版]支持TORCHSCRIPT的分布式优化器
PyTorch提供了一系列用于训练算法的优化器,这些优化器已作为python API的一部分。
然而,用户通常希望使用多线程训练而不是多进程训练,因为多线程训练在大规模分布式训练中提供了更好的资源利用率和效率。
以前的分布式优化器没有此效率,因为需要摆脱python全局解释器锁(GIL)的限制才能实现这一点。在PyTorch1.7中,启用了分布式优化器中的TorchScript支持来删除GIL,并使优化器能够在多线程应用程序中运行。
新的分布式优化器具有与以前完全相同的接口,但是它会自动将每个Worker中的优化器转换为TorchScript,从而使每个GIL空闲。
示例:
[测试版]对基于RPC的评测的增强
PyTorch 1.6首次引入了对结合使用PyTorch分析器和RPC框架的支持。在PyTorch 1.7中,进行了以下增强:
1、’实现了对通过RPC分析TorchScript函数的更好支持。
2、在使用RPC的分析器功能方面实现了奇偶校验。
3、增加了对服务器端异步RPC函数的支持(使用rpc.functions.async_Execution)。
用户现在可以使用熟悉的性能分析工具,比如torch.autograd.profiler.profile()和torch.autograd.profiler.record_function,这可以与RPC框架配合使用,这些RPC框架具有:全功能支持、配置文件异步函数和TorchScript函数。
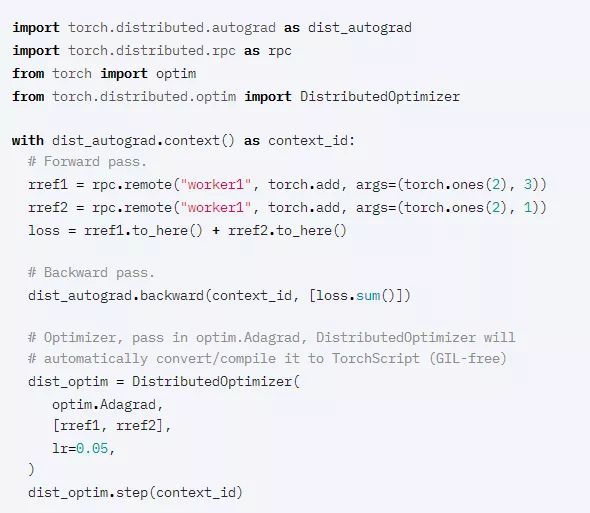
[原型]Windows对分布式训练的支持
PyTorch1.7为Windows平台上的DistributedDataParallel和集合通信提供了原型支持。在此版本中,仅支持基于Gloo的ProcessGroup和FileStore。
如果要跨多台计算机使用此功能,可以在init_process_group中提供来自共享文件系统的文件。
示例:
4 Mobile
PyTorch Mobile支持iOS和Android,CocoaPods和JCenter,并分别提供了二进制软件包。
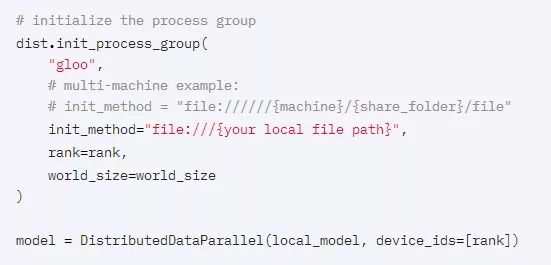
[测试版]PYTORCH移动缓存分配器可提高性能
在一些移动平台上,比如Pixel,内存归还给系统过于频繁的时候,会导致页面错误。原因是作为功能框架的PyTorch不维护操作符的状态。
因此,对于大多数操作,每次执行操作时都会动态分配输出。为了改善由此造成的性能损失,PyTorch1.7为CPU提供了一个简单的缓存分配器。分配器按张量大小缓存分配,目前只能通过PyTorch C++API使用。
缓存分配器本身归客户端所有,客户端拥有的缓存分配器然后可以与c10::WithCPUCachingAllocatorGuard 一起使用,以允许在该作用域内使用缓存分配。
示例用法:
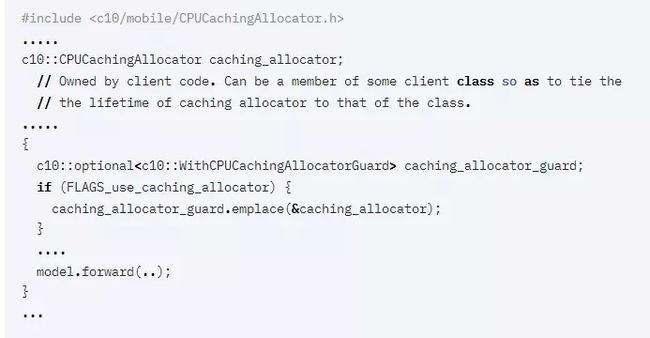
注意:
缓存分配器仅在移动版本上可用,因此在移动版本之外使用缓存分配器将会失效。
5 torchvision
[稳定]TRANSFORMS现在支持张量输入、批处理计算、GPU和TORCHSCRIPT
Torchvision transforms 现在继承自 nn.Module,并且可以编写TorchScript脚本并将其应用于 torch Tensor 输入以及PIL图像。它们还支持具有批处理维度的张量,并可在CPU/GPU设备上无缝工作:

这些改进实现了以下新功能:
1、支持GPU加速。
2、批量转换,例如根据视频的需要。
3、变换多波段torch张量图像(3-4个以上通道)
TorchScript transforms 与模型一起部署时请注意:TorchScript支持的例外包括Compose、RandomChoice、RandomOrder、Lambda等等
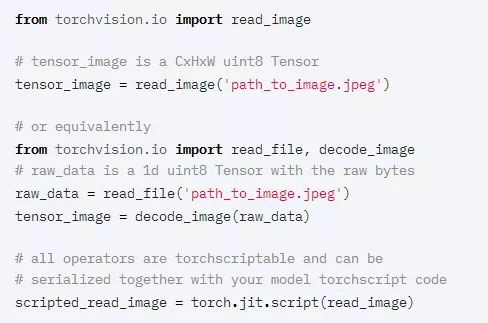
[稳定]JPEG和PNG格式的本地图像IO
Torchvision 0.8.0引入了JPEG和PNG格式的本地图像读写操作。这些操作符支持TorchScript并以uint8格式返回CxHxW tensors,因此现在可以成为在C++环境中部署的模型的一部分。
[稳定]RETINANET检测模型
此版本为Retinanet添加了预先训练的模型,该模型具有ResNet50主干,可用于物体检测。
[测试版]新的视频阅读器API
此版本引入了一个新的视频阅读API,可以更细粒度地控制视频的更新迭代。它支持图像和音频,并实现了迭代器接口,因此可以与其他python库(如itertools)交互操作。
示例:

注意:
1、要使用Video Reader API测试版,必须使用源编译torchvision,并在系统中安装ffmpeg。
2、VideoReader接口目前为测试版。
6 torchaudio
通过这个版本,torchaudio正在扩展对模型和端到端应用,增加了wav2letter训练管道和端到端文本到语音以及源分离管道
[稳定]语音识别
在上一个版本中添加了用于语音识别的Wave2Letter模型的基础上,现在使用LibriSpeech数据集添加了一个Wave2Letter训练管道。.
[稳定]文本到语音转换
为了支持文本到语音的应用程序,在此存储库的实现的基础上,添加了一个基于WaveRNN模型的声码器。
另外,还提供了一个示例:WaveRNN训练管道,该管道使用在pytorch 1.7版本中添加到torchaudio中的LibriTTS数据集。
[稳定]源分离
随着ConvTasNet模型的加入,基于“Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,””一文,Torchaudio现在也支持源分离。WSJ-MIX数据集提供了一个示例:ConvTasNet训练管道。
原文链接:https://pytorch.org/blog/pytorch-1.7-released/
接下来,给大家介绍一下租用GPU做实验的方法,我们是在智星云租用的GPU,使用体验很好。具体大家可以参考:智星云官网: http://www.ai-galaxy.cn/,淘宝店:https://shop36573300.taobao.com/公众号: 智星AI
