OrionX(猎户座)AI加速器资源池化软件赋能深度学习分布式训练
目录
什么是分布式训练
为什么要分布式训练
如何做分布式训练
OrionX 如何支持分布式训练
什么是分布式训练
对于机器学习/深度学习中的模型训练任务来说,算力的需求与日俱增。分布式训练采用多个计算节点,利用分布式编程的技术实现远超于单机的计算算力。
在回答这个问题之前,咱们先看一下深度学习模型常见的训练方式:
1、单机单卡训练,单GPU方式,这种训练方式常见于个人开发者自己的笔记本/工作站上,或者计算量需求相对较小的训练任务上。
2、单机多卡训练,仍然是以单机形式,常见于单台企业级服务器里面配置多张GPU卡并行训练。比如我们在一台机器上安装8张GPU卡,都跑一次BP算法计算出梯度,把所有GPU上计算出梯度进行平均,然后更新参数。这样的话,以前一次BP只能喂1个batch的数据,现在就是8个batch。理论上来说,速度提升了8倍(除去GPU通信的时间等等)。这也是分布式训练提升速度的基本原理。
3、多机多卡训练,对于上述两种单机训练来说,随着数据集的增加以及模型参数量的提升,单机模型训练始终会陷入算力瓶颈。所以对于模型训练,不少企业开始尝试多机多卡分布式训练。相对于上述两种训练方式,多机多卡训练顾名思义就是使用很多台机器,每台机器上都有多张GPU卡,模型跑在所有机器的GPU上以加快训练速度。
因此,我们总结出分布式训练的基本定义:对于机器学习/深度学习中的模型训练任务,采用多个计算节点,利用分布式编程的技术实现远超于单机的计算算力。
目前深度学习主流框架全支持分布式训练,甚至有专门为分布式训练打造的框架。目前深度学习主流框架(如TensorFlow, PyTorch, Paddle Paddle, MXNet等)全支持分布式训练,也因为分布式训练性能优化的难题,学术界和业界也有专门为分布式训练设计的框架(如Horovod, DeepSpeed)。

为什么要分布式训练
驱动因素一:算力瓶颈
最简单的理解就是为了解决单机算力的瓶颈问题。
举个直观的例子:ResNet-50 训练 ImageNet 128 万张图片 90 个 epoch 可以达到 75% 的 Top-1 精度,用一块 P100 的 GPU 需要大概 5 天的时间。
①从技术的角度,5 天的时间是非常不利于算法工程师去做一些模型迭代的。
②从业务的角度,因为需要经常更新数据,5 天的时间也是一个无法承受的训练成本。
解决问题的方法:采用分布式训练
通过叠加大量的GPU,采用分布式训练方式,可以把训练时间缩短到分钟级别。由此可见,分布式训练其实在我们日常AI模型训练、算法升级迭代过程中是非常有用的,很多企业都在探索分布式训练的极限。
 数据引用:Extremely Accelerated Deep Learning: ResNet-50 Training in 70.4 Seconds
数据引用:Extremely Accelerated Deep Learning: ResNet-50 Training in 70.4 Seconds
驱动因素二:
单机环境下会遇到一些问题,例如模型复杂导致GPU放不下,数据量太大无法加载,所以需要进行分布式训练。以一个大规模无监督 NLP 模型:GPT-2来举例。在过去一段时间,GPT-2 凭借其稳定、优异的性能吸引了业界的关注,因此该模型被称为“史上最强通用 NLP 模型”(现在更强的GPT-3已经出现了)。
优异的表现来源于GPT-2 有着超大的训练规模,它是一个在海量数据集上基于 transformer 训练的巨大模型。

从占用存储大小的角度进行比较,GPT-2 的最小模型版本有117 million个参数,光模型parameter就要至少 500MB 的空间来存储这些参数;最大版本的 GPT-2 甚至需要超过 6.5GB 的显存空间。雪上加霜的是模型训练时,不仅仅参数会占用GPU显存,网络激活特征图、梯度、优化器状态(比如Adam的momentum和variances)都会占用显存。以典型的混合精度训练的GPT-2 extra large为例,所有的这些参数占用的显存字节数为16倍参数数目,也就是26GB显存,所以一张小卡的显存是很难去满足现在越来越大的模型需求。另一方面,从算法训练的本质上来说的话,适当增大batchsize有助于提升minibatch梯度的准确率,从而提升的模型训练效果(比如图像分割)。
从下面这个图也可以看出一个非常明显的趋势:越来越大的模型,越来越多的GPU数量需求:
 数据引用:
数据引用:
1、AI and Compute: 2018
2、完全图解GPT-2
如何做分布式训练
分布式框架是实现分布式训练的基础工具。目前业界主流的深度学习框架基本都支持分布式训练。以市场占有率最高的TensorFlow和PyTorch举例:
1、TensorFlow1.x原生的PS-Worker架构可以采用分布式训练进而提升模型的训练效果,而TensorFlow 2.x通过tf.distribute.Strategy接口可以定义PS-Worker或collective分布式策略,并通过这些不同的策略,来进行模型的分布式训练。
2、PyTorch从1.0稳定版本开始,torch.distributed软件包和torch.nn.parallel.DistributedDataParallel 模块由全新的、重新设计的分布式库提供支持。
但是这两种框架的原生分布式使用起来并不轻松,1) 开发难度上变大,用户需要手写支持分布式训练的全套代码, 2) 在调试和部署上两者都需要在多台机器上a) 同步代码和数据,b) 手动执行训练脚本,这几点给开发者带来了较大难度。 于是,业界也催生了一个更加简单易用、并且兼容主流计算框架的分布式机器学习训练框架Horovod,能改善代码需要修改的难度,优化了框架原生(比如tensorflow)的分布式训练性能,同时减少了上述第2.b点的困扰 。
Horovod 是一套支持TensorFlow, Keras, PyTorch, 和MXNet 的分布式训练框架,由 Uber 构建并开源,旨在使分布式深度学习变得快速且易于使用,使模型训练时间从几天和几周缩短到数分钟和数小时。使用Horovod,可以将现有的训练脚本扩大规模,使其仅用几行Python代码就可以在跨设备的多个GPU上运行。
Horovod 的主要优点有:
- 采用Ring-Allreduce算法,提高分布式设备的效率;
- 代码改动少,能够简化分布式深度学习项目的启动与运行:
- 提供各种框架的支持,适配的成本不高;
- MPI的实现方式多,比如OpenMPI 、Nvidia的NCCL、facebook的gloo。
但是,MPI的启动方式依然不简单:不仅需要在slave机器上启动sshd server,并且配置机器间免密可访问,只是减少了用户在每台机器上启动脚本的困扰;幸运的是,我们看到接下来要介绍的OrionX软件能解决horovod上述多台机器部署的问题,减少horovod部署的难点,轻松实现在一台机器上跨机调用多台机器的GPU资源的功能。
有了一个好的分布式训练框架之后,我们就可以继续来看具体的训练方案:数据并行(data parallel)和模型并行(model parallel)。

数据并行:每个工作机器上保留整个模型的完整副本,把数据进行拆分,每台机器只是获取数据的不同部分。比如有8块GPU,batch size=1024,那么每块GPU就是128个数据,分别在每块GPU都跑BP算法,然后组合结果和同步模型参数。
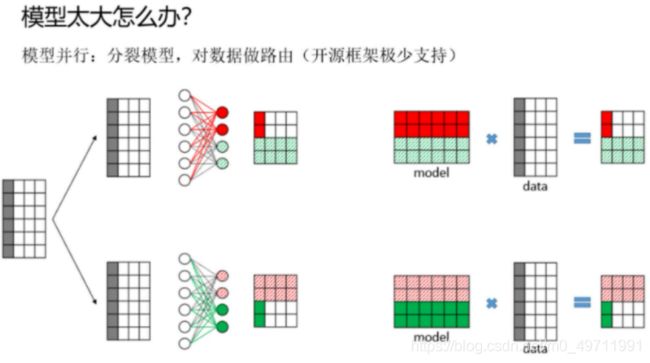
模型并行:把模型拆分成多个部分,不同机器负责单个神经网络的不同部分的计算。对于很大的网络结构在如此,一般没必要。
虽然模型并行在实践中可以很好地工作,但数据并行可以说是分布式系统的首选方法,并且一直是更多研究的重点。 一方面,业界使用场景主要面对的是数据量太大的问题,数据并行既能满足用户的需求; 其次数据并行比模型并行性更容易实现,在容错和集群利用率上也容易。
OrionX 如何支持分布式训练
OrionX的“化零为整”功能支持将多台服务器上的GPU提供给一个虚拟机或者容器使用,而该虚拟机或者容器内的基于Horovod框架的AI应用无需修改代码。通过这个功能,用户可以将多台服务器的GPU资源聚合后提供给单一虚拟机或者容器使用。

对多种分布式训练框架的支持:
1、支持TensorFlow + horovod 方式进行多机多卡训练。
2、支持 PyTorch Distributed Data Parallel数据并行接口。
使用OrionX的优势:
1、编程接口简单,不需要用户准备多个容器/虚机环境。
2、资源利用率搞,一个业务容器/虚机里面挂载的Orion vGPU可以来自于多个物理机节点,每个节点使用的vGPU数目是动态生成的。因此可以有效使用多个节点中的碎片资源。
3、降低复杂度,各个节点之间的资源调用实现免密,无需复杂申请。