本周的总结
目录
本周完成的计划
论文阅读
ABSTRACT(摘要)
1 INTRODUCTION(介绍)
2 BACKGROUND(背景)
2.1 MIXMATCH
3 REMIXMATCH
3.1 DISTRIBUTION ALIGNMENT(分布对齐)
3.2 IMPROVED CONSISTENCY REGULARIZATION(改进的一致性正则化)
3.3 PUTTING IT ALL TOGETHER(综合考虑)
4 EXPERIMENTS(实验)
5 CONCLUSION(结论)
Pytorch多GPU训练
多GPU训练介绍
Single Machine Data Parallel(单机数据并行)
Single Machine Model Parallel(单机模型并行)
Distributed Data Parallel(分布式数据并行)
代码实践
使用DataParallel类实现多GPU训练
使用DistributedDataParallel类实现多GPU训练
使用nvidia-msi命令查看GPU的使用情况
本周工作总结
本周完成的计划
- 读论文《ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring》
- 学习pytorch框架中如何使用多GPU进行训练
- 参加计算机网络考试
论文阅读
ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring(具有分布对齐和增广锚定的半监督学习)
ABSTRACT(摘要)
我们改进了最近提出的“MixMatch”半监督学习算法,引入了两种新的技术:分布对齐和增强锚定。分布对齐鼓励对未标记数据的预测的边际分布接近真实标签的边际分布。增强锚定将输入的多个强增强版本输入到模型中,并鼓励每个输出都接近相同输入的弱增强版本的预测。为了产生强增强,我们提出AutoAugment的一个变体,它在模型被训练时学习增强策略。我们的新算法被称为ReMixMatch,它比之前的算法的数据效率要高得多,减少5到16倍的数据才能达到同样的精度。例如,在CIFAR-10中,使用250个标记的样本,我们达到了93.73%的正确率(相比之下,MixMatch对4000个样本的正确率为93.58%),在每个类只有4个标签的情况下,中值正确率为84.92%。
1 INTRODUCTION(介绍)
半监督学习(SSL)提供了一种在有限的标记数据可用时利用未标记数据来提高模型性能的方法。当标记数据很昂贵或不方便时,可以使用大型、功能强大的模型。对SSL的研究产生了多种方法,包括一致性正则化,鼓励模型在输入扰动时产生相同的预测,以及熵最小化,鼓励模型输出高置信度预测。最近提出的“MixMatch”算法将这些技术结合在一个统一的损失函数中,并在各种图像分类基准上实现了强大的性能。在本文中,我们提出了两个可以很容易地集成到MixMatch框架中的改进。
首先,我们引入“分布对齐”,它鼓励模型聚合类预测的分布与真实类标签的边缘分布相匹配。其次,我们引入了“增广锚定”,它取代了MixMatch的一致性正则化部分。为了产生强增强,我们引入了一种基于控制理论的自动增强变体,我们称之为“CTAugment”。与AutoAugment不同,CTAugment在模型训练的同时学习一个增强策略,这使得它在SSL设置中特别方便。我们将改进算法称为“ReMixMatch”,并在一组标准SSL图像基准上进行了实验验证。ReMixMatch在所有标记的数据量中实现了最先进的精度,例如,在CIFAR-10上使用250个标签时,精度达到93.73%,而以前的最先进水平为88.92%(而使用50000个标签进行完全监督分类时,精度为96.09%)。
2 BACKGROUND(背景)
半监督学习算法的目标是从未标记数据中学习,以提高标记数据的性能。实现这一点的典型方法包括针对未标记数据的“猜测”标签进行训练,或者优化不依赖标签的启发式目标。本节回顾与ReMixMatch相关的半监督学习方法,特别关注我们工作所基于的MixMatch算法的组件。
Consistency Regularization :许多SSL方法依赖于一致性正则化来强制当输入受到扰动时模型输出保持不变。Entropy Minimization :认为应该使用未标记的数据来确保类被很好地分离。这可以通过鼓励模型的输出来实现分布对未标记数据具有低熵(即,进行“高置信度”预测)。Standard Regularization :在SSL设置之外,在过度参数化的情况下,正则化模型通常是有用的。这种正则化通常可以应用于有标记和无标记数据的训练。
Other Approaches :上述三类SSL技术并未涵盖半监督学习的全部文献。还很很多半监督学习方法,比如基于GAN的,基于图的半监督学习算法。
2.1 MIXMATCH
MixMatch(Berthelot等人,2019年)统一了前面提到的几种SSL技术。该算法的工作原理是为每个未标记的样本生成“猜测标签”,然后使用全监督技术对原始的已标记数据以及未标记数据的猜测标签进行训练。
完整的MixMatch算法流程:

3 REMIXMATCH
在介绍了MixMatch之后,我们现在转向本文提出的两个改进:分布对齐和增广锚定。为了清晰起见,我们描述了如何将它们集成到基本MixMatch算法中。
3.1 DISTRIBUTION ALIGNMENT(分布对齐)
我们的第一个贡献是分布对齐,它强制未标记数据的预测集合与所提供的标记数据的分布相匹配。这个基本思想是在25年前首次提出的(Bridle等人,1992年),但据我们所知,在现代SSL技术中并没有使用。分布对齐的示意图如图1所示。在回顾和扩展了该理论之后,我们描述了如何将其直接包含在ReMixMatch中。
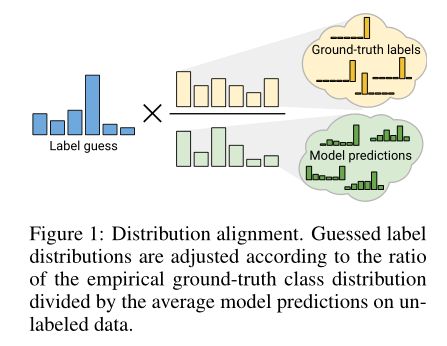
3.1.1 INPUT-OUTPUT MUTUAL INFORMATION(输入-输出互信息)

为了解释这一结果,可以观察eq.(2)中的第二项是熟悉的熵最小化目标,它简单地鼓励每个模型输出具有低熵(表明对一个类标签有很高的信心)。然而,在现代SSL技术中,第一个项并没有得到广泛使用。这个term(粗略地说)鼓励在整个训练集中,该模型平均地以相等的频率预测每一类,Bridle等人(1992)将此模型称为“公平”。
3.1.2 DISTRIBUTION ALIGNMENT IN REMIXMATCH(REMIXMATCH中的分布对齐)
MixMatch已经包含了一种通过“锐化”操作实现的熵最小化的形式,该操作使得未标记数据的猜测标签(合成目标)具有较低的熵。因此,我们也有兴趣在ReMixMatch中加入一种“公平”形式。然而,请注意,目标![]() 意味着模型应该以相同的频率预测每个类。如果数据集的边际类分布p(y)不均匀,这不一定是一个有用的目标。此外,虽然原则上可以在每个批次的基础上直接最小化该目标,但我们感兴趣的是以不引入额外损失项或任何敏感超参数的方式将其集成到MixMatch中。
意味着模型应该以相同的频率预测每个类。如果数据集的边际类分布p(y)不均匀,这不一定是一个有用的目标。此外,虽然原则上可以在每个批次的基础上直接最小化该目标,但我们感兴趣的是以不引入额外损失项或任何敏感超参数的方式将其集成到MixMatch中。
为了解决这些问题,我们引入了一种我们称为“分布对齐”的公平形式,其过程如下:在训练过程中,我们保持模型对未标记数据的预测的运行平均值,我们称之为![]() ,给定模型对一个未标记样本u 的预测q=
,给定模型对一个未标记样本u 的预测q=![]() (y|u;
(y|u; ),我们将q按照
),我们将q按照![]() 的比例缩放,然后将结果重新正规化以形成一个有效的概率分布
的比例缩放,然后将结果重新正规化以形成一个有效的概率分布![]() ,然后我们用作为u标签的猜测,并像往常一样进行锐化和其他处理。
,然后我们用作为u标签的猜测,并像往常一样进行锐化和其他处理。
3.2 IMPROVED CONSISTENCY REGULARIZATION(改进的一致性正则化)
一致性正则化是大多数SSL方法的基础。对于图像分类任务,通常在同一未标记图像的两个增强版本之间执行一致性。为了实施一种形式的一致性正则化,MixMatch生成每个未标记样本u的K(实际上,K=2)增强,并将它们平均在一起以生成u的“猜测标签”。
最近的研究(Xie et al.,2019)发现,应用更强形式的增强可以显著提高一致性正则化的性能。特别是,对于图像分类任务,使用AutoAugment的变体产生了巨大的收益。由于MixMatch使用一种简单的翻转和裁剪增强策略,我们有兴趣看看用AutoAugment替换MixMatch中的弱增强是否会提高性能,但发现训练不会收敛。为了避免这个问题,我们提出了一种新的方法来实现MixMatch中的一致性正则化,称为“增广锚定”。其基本思想是利用模型对弱增强未标记图像的预测作为同一图像的多个强增强版本的猜测标签。
使用AutoAugment的另一个逻辑问题是,它使用强化学习来学习一个策略,该策略需要许多有监督模型训练的试验。这在SSL设置中提出了一些问题,在SSL设置中,我们通常只有有限的标记数据。为了解决这个问题,我们提出了一种称为“CTAugment”的自动增强变体,它使用控制理论的思想在线调整自己,而不需要任何形式的基于强化学习的训练。我们将在以下两个小节中描述增强锚定和增强。
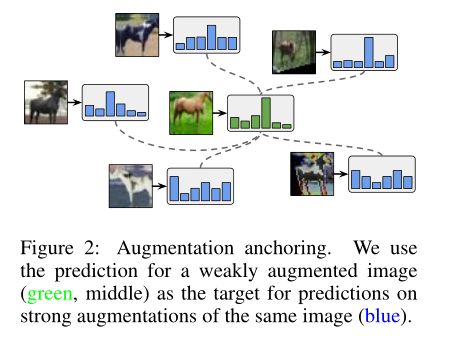
3.2.1 AUGMENTATION ANCHORING(增强锚固)
我们假设MixMatch和AutoAugment不稳定的原因是MixMatch平均了K个扩增的预测。更强的增强可能导致不同的预测,因此它们的平均值可能不是一个有意义的目标。相反,给定一个未标记的输入,我们首先通过对其应用弱增广来生成一个“锚”。然后,我们使用CTAugment(如下所述)生成相同未标记输入的K个强增强版本。我们使用猜测的标签(在应用分布对齐和锐化之后)作为所有K个强增强版本的图像的目标。该过程如图2所示。
3.3 PUTTING IT ALL TOGETHER(综合考虑)
ReMixMatch处理一批标记和未标记样本的算法如算法1所示。该算法的主要目的是生成集合 ![]() 和
和![]() ,包括应用MixUp的扩展标记和未标记样本。
,包括应用MixUp的扩展标记和未标记样本。

在![]() 和
和![]() ,中的标签和标签猜测被输入到标准的交叉熵损失项与模型的预测。算法1还输出
,中的标签和标签猜测被输入到标准的交叉熵损失项与模型的预测。算法1还输出![]() ,它包含每个未标记图像的一个单一的高度增强版本,并且猜测它的标签没有应用MixUp。
,它包含每个未标记图像的一个单一的高度增强版本,并且猜测它的标签没有应用MixUp。![]() 用于两个额外的损失项,提供一个温和的提高性能和改进的稳定性。
用于两个额外的损失项,提供一个温和的提高性能和改进的稳定性。
ReMixMatch总损失是:

4 EXPERIMENTS(实验)
在CIFAR10和SVHN数据集上ReMixMatch和其它数据集在给定不同标签数量条件下准确率的比较:

ABLATION STUDY(消融研究)

上面消融实验的结果是从CIFAR-10拆分出来的单个250个标签的错误率。
5 CONCLUSION(结论)
过去一年半监督学习的进展颠覆了许多长期以来关于分类的观念,即大量有标签的数据是必要的。通过在MixMatch中引入增强锚定和分布对齐,我们延续了这一趋势:与之前的工作相比,ReMixMatch减少了大量需要的标记数据(例如,在CIFAR-10上击败了4000个标记样本的MixMatch,只有250个;在STL-10上接近于5000个标记样本的MixMatch,只有1000个)。数据高效学习的真正力量将来自于将这些技术应用到实际问题中,在这些问题中获取标签数据是昂贵的或不切实际的。
总结一下这篇论文
主要就是在 MixMatch 的基础上改进了两个部分:
- Distribution Alignment
- Augmentation Anchoring
- CTAugement
ReMixMatch采用弱增强数据的预测结果作为guessing label, 还用了更复杂的 Loss Function ,使不同类的 unlabeled data 在空间中能够被分隔的更远。
自己跑了一下GitHub上找的代码,效果如下:
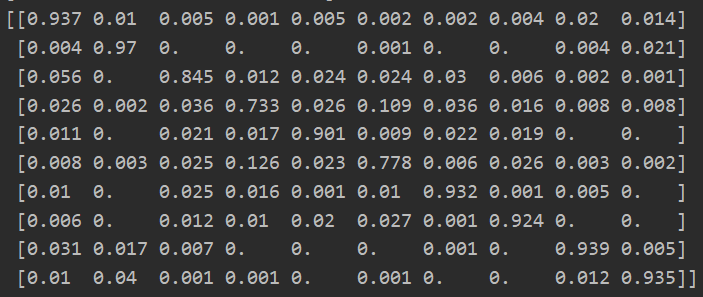
![]()
论文中说使用250个标记的样本,我们达到了93.73%的正确率,目前跑到了89%,可能是因为训练次数不够和调参的原因。
Pytorch多GPU训练
多GPU训练介绍
常见的多GPU的使用方法有以下两种:
- model parallel,当模型很大,单块GPU的显存不足以放下整个模型时,通常会将模型分成多个部分,每个部分放到不同的GUP设备中,这样就能将原本跑不了的模型利用多块GPU跑起来。但这种情况,一般不能加速模型的训练。
- data parallel,当模型不是很大可以放入单块GPU时,可以将模型复制到多块GPU上,进行并行加速训练。这种情况更常见,我也是学习的这种方式的多GPU并行训练。
Single Machine Data Parallel(单机数据并行)


工作过程:
如上图所示,scatter(打散)是将上面batch size=4中的四个sampler,分别放入GPU0、GPU1、GPU2、GPU3中,同样的网络模型m也会被复制4分放入这四个GPU中,然后分别同时进行训练,最后将训练的结果gather(收集)到GPU0(主GPU)中,然后再GPU0上求Loss,再更新模型参数,然后继续重复执行上面操作,直到模型收敛。
Single Machine Model Parallel(单机模型并行)

工作过程:
如上图所示,将模型m分成net1和net2两部分,分别放入GPU0和GPU1中,然后将训练数据线放入GPU0的net1模型中进行训练,将net1得到的结果作为输入,放入GPU1中进行训练,在GPU1上算loss,然后更新模型参数。
Distributed Data Parallel(分布式数据并行)
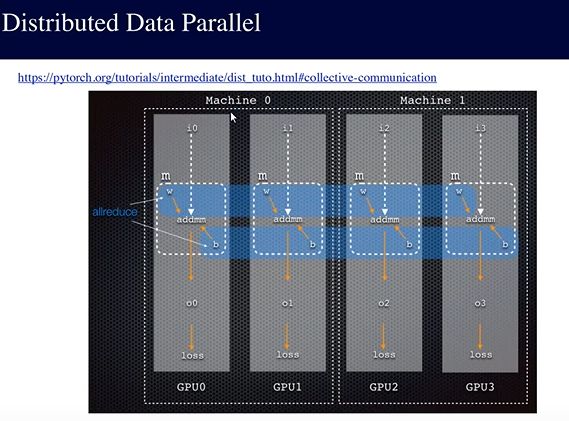

工作过程:
如上图所示,和Data Parallel数据并行不一样的是,我们不是将模型每次都复制到4个GPU中,并行是在每个GPU中单独算loss,gradient等,然后使用一个在分布式系统经常使用的allreduce操作,意思是最后同步的只是loss,gradient这种,然后更新模型参数。
代码实践
使用DataParallel类实现多GPU训练
import time
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
from torch.nn.parallel import DataParallel
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x)
return x
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for idx, (images, targets) in enumerate(train_loader):
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % args.log_interval == 0:
print("Train Time:{}, epoch: {}, step: {}, loss: {}".format(time.strftime("%Y-%m-%d%H:%M:%S"), epoch + 1, idx, loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
test_acc = 0
with torch.no_grad():
for (images, targets) in test_loader:
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets, reduction="sum")
test_loss += loss.item()
pred_label = torch.argmax(pred, dim=1, keepdims=True)
test_acc += pred_label.eq(targets.view_as(pred_label)).sum().item()
test_loss /= len(test_loader.dataset)
test_acc /= len(test_loader.dataset)
print("Test Time:{}, loss: {}, acc: {}".format(time.strftime("%Y-%m-%d%H:%M:%S"), test_loss, test_acc))
def main():
parser = argparse.ArgumentParser(description="MNIST TRAINING")
parser.add_argument('--device_ids', type=str, default='0', help="Training Devices, example: '0,1,2'")
parser.add_argument('--epochs', type=int, default=10, help="Training Epoch")
parser.add_argument('--log_interval', type=int, default=100, help="Log Interval")
args = parser.parse_args()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307), (0.3081))])
dataset_train = datasets.MNIST('../data', train=True, transform=transform)
dataset_test = datasets.MNIST('../data', train=False, transform=transform)
train_loader = DataLoader(dataset_train, batch_size=8, shuffle=True, num_workers=8)
test_loader = DataLoader(dataset_test, batch_size=8, shuffle=False, num_workers=8)
device_ids = list(map(int, args.device_ids.split(',')))
device = torch.device('cuda:{}'.format(device_ids[0]))
model = Net().to(device)
model = DataParallel(model, device_ids=device_ids, output_device=device)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = StepLR(optimizer, step_size=1)
for epoch in range(args.epochs):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
scheduler.step()
torch.save(model.state_dict(), 'train.pt')
if __name__ == '__main__':
main()使用DistributedDataParallel类实现多GPU训练
import time
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
self.fc3 = nn.Linear(128, 128)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x)
return x
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for idx, (images, targets) in enumerate(train_loader):
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % args.log_interval == 0 and args.local_rank == 0:
print("Train Time:{}, epoch: {}, step: {}, loss: {}".format(time.strftime("%Y-%m-%d%H:%M:%S"), epoch + 1, idx, loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
test_acc = 0
with torch.no_grad():
for (images, targets) in test_loader:
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets, reduction="sum")
test_loss += loss.item()
pred_label = torch.argmax(pred, dim=1, keepdims=True)
test_acc += pred_label.eq(targets.view_as(pred_label)).sum().item()
test_loss /= len(test_loader.dataset)
test_acc /= len(test_loader.dataset)
print("Test Time:{}, loss: {}, acc: {}".format(time.strftime("%Y-%m-%d%H:%M:%S"), test_loss, test_acc))
def main():
parser = argparse.ArgumentParser(description="MNIST TRAINING")
parser.add_argument('--device_ids', type=str, default='0', help="Training Devices")
parser.add_argument('--epochs', type=int, default=10, help="Training Epoch")
parser.add_argument('--log_interval', type=int, default=100, help="Log Interval")
parser.add_argument('--local_rank', type=int, default=-1, help="DDP parameter, do not modify")
args = parser.parse_args()
device_ids = list(map(int, args.device_ids.split(',')))
dist.init_process_group(backend='nccl')
device = torch.device('cuda:{}'.format(device_ids[args.local_rank]))
torch.cuda.set_device(device)
model = Net().to(device)
model = DistributedDataParallel(model, device_ids=[device_ids[args.local_rank]], output_device=device_ids[args.local_rank], find_unused_parameters=True)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307), (0.3081))])
dataset_train = datasets.MNIST('../data', train=True, transform=transform)
dataset_test = datasets.MNIST('../data', train=False, transform=transform)
sampler_train = DistributedSampler(dataset_train)
train_loader = DataLoader(dataset_train, batch_size=8, num_workers=8, sampler=sampler_train)
test_loader = DataLoader(dataset_test, batch_size=8, shuffle=False, num_workers=8)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = StepLR(optimizer, step_size=1)
for epoch in range(args.epochs):
sampler_train.set_epoch(epoch)
train(args, model, device, train_loader, optimizer, epoch)
if args.local_rank == 0:
test(args, model, device, test_loader)
scheduler.step()
if args.local_rank == 0:
torch.save(model.state_dict(), 'train.pt')
if __name__ == '__main__':
main()使用nvidia-msi命令查看GPU的使用情况
本周工作总结
1.学习了半监督论文ReMixmatch,其是对MixMatch的改进,在 MixMatch 的基础上改进了两个部份:Distribution Alignment和Augmentation Anchoring。
2.学习了如何在pytorch框架中使用DaraParallel类和DistributedDataParallel类进行多GPU并行训练。pytorch官方推荐使用DistributedDataParallel类,但是DaraParallel使用起来很方便,只需要加几行代码就能搞定。