数据结构3--深入了解单向链表的实现
文章目录
- 链表
-
- 1.从顺序表到链表
-
- 1.1用指针来实现链表中空间的联系
- 1.2创建一个节点
- 1.3头指针、第一个节点和最后一个节点
-
- 头指针的创建
- 2.管理链表中的元素
-
- 2.1访问链表中的各个元素
-
- 2.1.1打印链表
- 2.1.2在链表中查找数据
- 2.1.3改变链表中某一个节点的值
- 2.2创建新的节点
- 2.3在链表中添加节点
-
- 2.3.1在链表的末尾添加节点
- 2.3.2在链表的头部添加节点
- 2.3.3在链表的指定位置添加节点
-
- 在指定位置的前面添加节点
- 在链表的指定位置后面添加节点
- 2.4删除链表中的节点
-
- 2.4.1删除链表最后一个节点
- 2.4.2删除链表第一个节点
- 2.4.3删除链表中指定的一个节点
-
- 删除指定位置的节点
- 删除指定位置后面的一个节点
- 2.5销毁链表
- 3.总结
-
- 2.5销毁链表
- 3.总结
链表
1.从顺序表到链表
前面我们已经实现过顺序表了,顺序表可用来存储一系列的数据,但是顺序表也有很明显的缺点
顺序表的缺点:
- 插入数据,空间不足时要扩容,扩容有性能消耗
- 头部或者中间位置插入数据时需要挪动大量数据,效率低
- 不能按需开辟合适的空间
从而我们使用了一种新的数据结构—链表
链表的优势是:我们可以按需所取,每需要一个空间,就开辟出来一个空间供利用。
链表和顺序表的空间开辟方式不同:
顺序表的空间开辟:在堆区一次性创建一个连续的空间,空间大小是明确的
顺序表中开辟六个空间:

链表中开辟六个空间:六个空间地址是随机的。
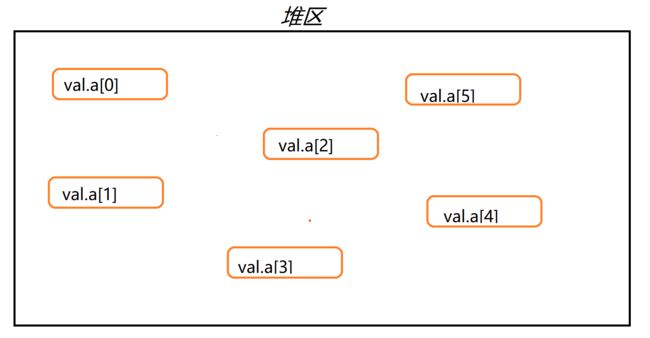
这样开辟出来的多个空间没有任何的联系,如果我们想要在堆区中找到这些空间,我们就需要将这些空间的地址放在指针中。
1.1用指针来实现链表中空间的联系
我们有两种方法可以让各个空间产生联系:
-
每一个空间都放一个指针,但是这样就需要一个很大的空间去粗放指针,这个方法不合理
-
这个方法是让每一次新开辟的空间和上一次开辟出来的空间产生联系,我们只需要有方法从上一个空间找到下一个空间的地址即可。这里我们用箭头来表示各个空间的联系

可是在C语言中,不能直接实现“箭头”,我们用一种特殊的方法—指针 。
我们直到每一次动态开辟空间都会返回该空间的起始地址,如果我们将这个地址存放在上一个空间中,那么我们就可以利用指针来实现“箭头”
因此每一次开辟出来的空间都应该是一个结构体,这种结构体被称为节点。
节点中存储的数据分为两部分,一部分是我们想要存放的数据,一部分是下一个节点的地址。

1.2创建一个节点
一个节点的类型:
typedef int SListDataType;
typedef struct SListNode {
SListDataType data;
struct SListNode* next;//正确的指针
//SListNOde *next//错误的指针
}SListNode;
注意:在定义结构体的时候指针的类型不能用类型重定义后的类型名
我们这样创建一个节点:
SListNode*newnode = (SListNode*)malloc(sizeof(SListNode));
newnode->next = NULL;
//这个节点的地址被存放在newnode指针变量中
//为了保证安全,刚创建出来的节点中的指针需要被赋值为NULL
下面是的图片可以解释节点之间是怎样产生联系的:

1.3头指针、第一个节点和最后一个节点
顺序表中可以通过下标以及表长找到顺序表中的第一个位置和最后一个位置,但是链表中各个节点是随机分配地址的,所以我们需要用其他的方法去找到第一个节点和最后一个节点。
第一个节点和头指针
我们在创建第一个节点的时候会返回一个地址,我们通过这个地址去找到第一个节点,然后才能访问后面的节点,所以第一个节点的地址是相当重要的。
我们专门创建一个指针去存放第一个节点的地址和,这个指针叫做头指针,只要我们拥有头指针,我们就可以操作链表中的各个节点。
头指针的创建
由于链表的特殊结构,我们可以通过头指针的值去访问到链表中每一个节点的信息
实现链表的第一步—创建头指针,然后将头指针赋值为空指针
创建的头指针类型应该是该结构体对应的指针类型

创建一个头指针
SListNode* phead = NULL;
//在还没有节点的时候,将头指针的值赋为NULL,可以防止该指针成为野指针,提高了安全性。
最后一个节点
我们每一个节点中都包含了一个指针类型的变量,为了防止该指针成为野指针,我们需要在创建新节点的时候把这个节点中的指针赋为
NULL,只有在后面再一次创建了新节点的时候才会让此节点的指针变量指向新节点的地址,
同样,这样我们还可以通过观察一个节点中的指针变量是否为空指针来判断这个节点是否是最后一个节点。
2.管理链表中的元素
我们已经直到了链表中各个节点的联系,已经特殊位置的节点有怎样的意义。现在可以来对链表中的各节点进行访问。
2.1访问链表中的各个元素
链表的特点是每一个节点中都存储有下一个节点的地址,所以我们可以利用这一点去访问链表中的各个节点,
我们先创建一个简单的链表:
我们创建了三个节点,并且让他们彼此产生联系(第一个节点中有第二个节点的地址,第二个节点中存有第三个节点的地址)
int main()
{
SListNode*phead = NULL;
SListNode *n1 = (SListNode *)malloc(sizeof(SListNode));
SListNode *n2 = (SListNode *)malloc(sizeof(SListNode));
SListNode *n3 = (SListNode *)malloc(sizeof(SListNode));
//创建三个节点
phead = n1;
n1->next = n2;
n2->next = n3;
n3->next = NULL;
n1->data = 1;
n2->data = 2;
n3->data = 3;
return 0;
}
2.1.1打印链表
我们利用打印函数打印出各个节点的值
声明该函数:
SListPrint(phead);//唯一的参数是头指针
实现该函数:
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
每一次循环中:
cur = cur->next都是在让cur指针指向下一个节点当
cur == NULL时,说明已经到达了最后一个节点。
打印结果:

2.1.2在链表中查找数据
如果我们要找到链表中的某个数据,我们就需要去遍历链表找到对应的值,然后返回该节点的地址。
我们这样声明该函数
SListNode* SListFind(SListNode* phead, SLTDataType x)
x是我们需要在链表中找到的元素,如果找到了我们就返回该节点的地址,如果找不到就返回空指针
我们这样实现该函数
SListNode* SListFind(SListNode* phead, SLTDataType x)
{
SListNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;//指向下一个节点
}
return NULL;
}

2.1.3改变链表中某一个节点的值
我们已经可以在链表中查到一个节点的位置,我们可以利用这个地址去修改这个节点的值
我们可以利用查找函数
void SListModify(SListNode* phead, SListDataType x);
参数
x是我们需要找到的值,参数y是我们修改后的值该函数利用
SListFind函数去找到某个元素的位置,然后用pos指针去接收返回值,通过判断返回值是否为NULL就可以直到是否找到这个元素。找到该节点后将值修改成y,修改就完成了。
该函数的具体实现
void SListModify(SListNode* phead, SListDataType x,SListDataType y)
{
SListNode *pos = SListFind(phead,x);//得到我们需要修改的节点的地址
if(pos)
{
printf("找到了:%p\n",pos);
pos->data = y;//修改该节点中的数据。
}
}
2.2创建新的节点
链表结构由节点构成,当我们需要在链表中添加节点的时候,每次单独创建节点然后再让他们彼此产生联系的效率是很低的,所以我们可以利用函数来创建新的节点。
这是创建新节点的函数
SListNode* BuySListNode(SListDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("malloc : fail\n");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
return newnode;
}
}
该函数的会接收一个数据,这个数据是存储在该节点中的值
如果动态分配失败,会返回空指针,同时该链表也不能继续进行下去(无法创建新的节点),所以就需要退出程序
如果成功开辟出空间,我们就可以给这个新空间的数据变量的赋值,给指针变量赋值为空指针(防止该指针为野指针)。
该函数的返回值是 :这个新节点的地址。
2.3在链表中添加节点
对于多个操作链表的函数,我们传递的参数都与头指针有关(如果我们想要改变头指针的值,那么在传递参数的时候就应该将头指针的地址作为参数)
如果我们定义一个函数SListPush用来向链表中添加节点,那么我们应该向这个函数传递怎样的参数?
两种情况
-
传值,传递指针
int main() { SListNode* phead = NULL; SListPush(phead); return 0; } -
传址,传递指针的地址(二级指针)
int main() { SListNode* phead = NULL; SListPush(&phead); return 0; }
结果是:第一种方式不会改变头指针的值,利用第二种传递参数的方式才能改变头指针的值
注意:如果我们想要去改变某个数据,那么我们就需要传递实参的地址

当我们将指针的地址传递作为实参的时候,形参需要二级指针来接收
2.3.1在链表的末尾添加节点
定义出一个函数
void SListPushBack(SListNode** pphead,SListDataType x);
//第一个参数接收头指针的地址
//第二个参数接收需要存储在新节点的值
第一步:创建一个新的节点,并且将要存入的值赋给该节点
SListNode* newnode = BuySListNode(x);
然后我们需要找到最后一个节点的位置
这时需要考虑多种情况
-
链表中有至少一个节点
我们知道链表的最后一个节点的指针变量的值是NULL,但是我们不能直接得到这个节点的地址,所以我们需要遍历整个链表,当找到了一个节点中的指针变量是空指针时,我们就找到了最后一个节点。
SListNode* tail = *pphead; while (tail->next != NULL) { tail = tail->next; } tail->next = newnode;我们创建了一个新的指针变量
tail,该指针的类型和头指针的类型相同,如果该链表不是一颗空链表,那么久将头指针的内容赋给tail指针,这样tail就指向了第一个节点,我们利用tail->next判断这一个节点中的指针变量是否是空指针,从而确定这个节点是否是最后一个节点,如果不是,就利用tail = tail->next让tail指针指向下一个节点,直到tail->next == NULL即找到了满足条件的节点----该节点中的指针变量为NULL,此时tail就是我们要找的最后一个节点
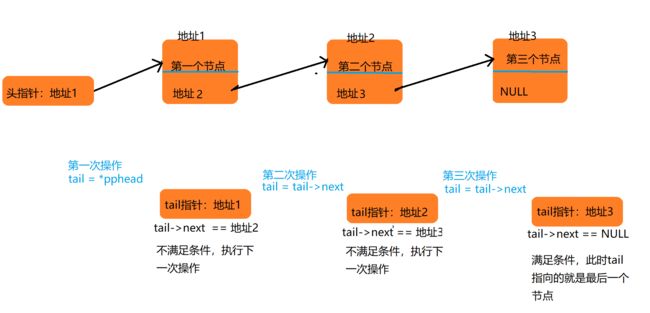
找到最后一个节点后,让该节点中的指针变量的值为新节点的地址,这样在链表结尾添加节点就完成了。
为什么要创建一个新的节点,而不是直接用头指针去遍历整个链表呢?
原因:那样会改变头指针的值,就无法再找到第一个节点的地址。 -
链表此时为空链表
此时我们只需要将动态开辟出来的空间地址保存在头指针中

if (*pphead == NULL)
{
*pphead = newnode;
}
所以如果我们想要去添加一个节点放在来年表的末尾,完整的函数代码段是这样的:
void SListPushBack(SListNode** pphead, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
if (*pphead == NULL)//是空链表的情况
{
*pphead = newnode;
}
else//不是空链表的情况
{
SListNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
2.3.2在链表的头部添加节点
我们声明该函数为
void SListPushFront(SListNode** pphead,SlistDadaType x);
该函数的实现
void SListPushFront(SListNode** pphead, SLTDataType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
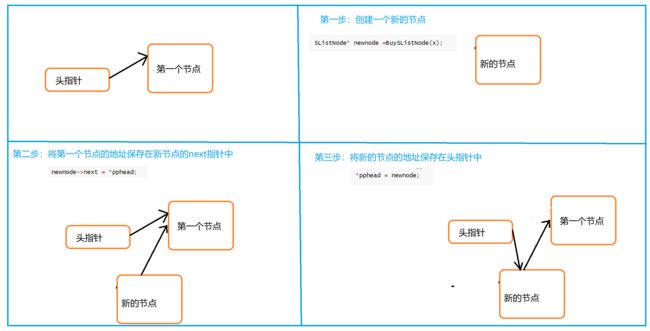
注意:一定是先将第一个节点地址保存下来后,在让头指针指向新的节点
2.3.3在链表的指定位置添加节点
首先我们需要找到所指定的位置,此外,对于向链表中添加节点,由两种添加方式,一种是在指定的节点前面添加,一种是在指定的节点后面添加。
在指定位置的前面添加节点
我们声明该函数为
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
该函数有三个参数:
第一个参数是头指针的地址;
第二个参数是一个指针;它保存了特定位置的地址
第三个参数是一个值,利用这个值可以找到我们指定的位置
在使用该函数前,我们需要判断指针的合法性:头指针的地址不能为空,pos指针也不能为空指针
所以我们在一开始就可以断言assert(pphead && pos)
我们在指定位置的前面添加节点
我们需要考虑多种情况,如果pos是第一个节点的地址,那么我们就相当于我们头插一个节点,我们可以调用SListPushBack函数
if(pos == *pphead)
{
SListPushBack(pphead,x);
}
如果pos不是第一个节点的地址,由于单链表中节点只能存储下一个节点的地址,无法通过一个节点找到上一个节点,所以我们还需要想办法找到pos前一个节点的地址。
我们创建一个新的指针
prev,初始赋值为第一个节点的地址
prev->next是下一个节点的地址,如果prev->next == pos
则说明prev的下一个节点就是我们指定的位置pos,
而prev保存的就是我们要找的前一个节点的地址
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);//判断指针的合法性
// 1、pos是第一个节点
// 2、pos不是第一个节点
if (pos == *pphead)
{
SListPushFront(pphead, x);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
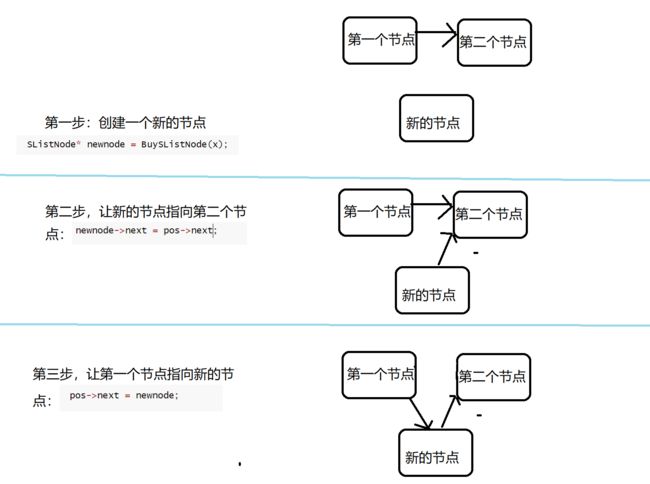
在链表的指定位置后面添加节点
在链表指定位置后面添加节点相较于在前面添加节点简单很多。我们只需要将指定位置(pos)的下一个节点的地址保存在新节点的next指针中,然后再将指针的地址保存在指定位置(pos)的next指针中
该函数可以这样实现:
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* next = pos->next;
SListNode* newnode = BuySListNode(x);
pos->next = newnode;
newnode->next = next;
newnode->next = pos->next;
}
2.4删除链表中的节点
2.4.1删除链表最后一个节点
我们声明该函数为:
void SListPopBack(SListNode** pphead);
在删除链表的最后一个节点需要注意有多种情况
-
链表是一个空链表
那么我们就不需要进行其他的操作,直接返回就行了
if(*pphead == NULL) { return; } -
链表只有一个节点
此时,将这一个节点的空间释放,然后将头指针的值赋为空指针
if((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } -
链表有多个节点
链表有多个节点的时候,如果想要删除最后一个节点,我们就需要找到最后一个节点的前一个节点
我们创建两个指针,一个用来找到最后一个节点,一个用来找到最后一个节点的前一个节点。
SListNode* prev = NULL; SListNode* tail = *pphead; while (tail->next != NULL) { prev = tail; tail = tail->next; } free(tail); tail = NULL; prev->next = NULL;
将三种情况合并在一起:
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)
{
return;
}
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SListNode* prev = NULL;
SListNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
2.4.2删除链表第一个节点
我们声明该函数为:
void SListPopFront(SListNode** pphead);
删除第一个节点也分为了不同的情况
-
链表是空链表
不用进行其他操作,直接返回或者结束程序就行
-
链表不是空链表
我们需要将第一个节点中的next指针的值赋为头指针,但是如果我们先改变了头指针的值,我们就不能在找到第一个节点的地址了,这样就不能释放第一个节点的空间,所以我们可以选择创建一个新的指针变量
psave将第一个节点中next的值保存下来,然后可以释放掉第一个节点的位置,在将psave的值赋给头指针,这样就成功的删除掉第一个节点。
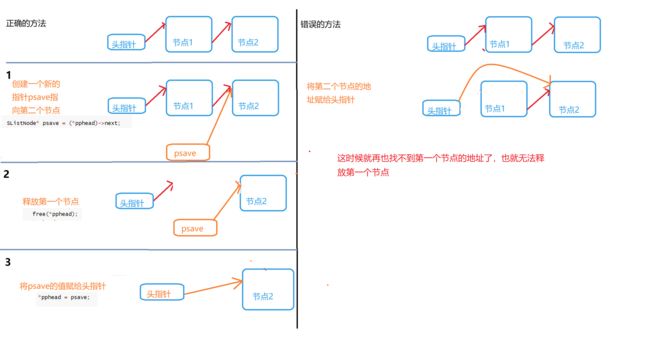
该函数的实现:
void SListPopFront(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)
{
return;
}
else
{
SListNode* psave = (*pphead)->next;
free(*pphead);
*pphead = psave;
}
}
2.4.3删除链表中指定的一个节点
和在指定位置添加节点相同,我们需要先找到指定的哪一个节点----利用SListFind函数
SListNode*pos = SListFind(x);
pos为指定位置的地址
删除指定位置的节点
如果指定位置是第一个节点,可以直接调用SListPopFront函数
if(*pphead == NULL)
{
SListPopFront(pphead)
}
如果不是第一个节点,那么需要找到pos对应节点的前面一个节点,
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (*pphead == pos)
{
SListPopFront(pphead);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
删除指定位置后面的一个节点
我们声明该函数为:
void SListErase()
需要先保存pos->next的值,以便于再释放空间的时候可以找到地址
然后然指定位置节点的next指针保存下一个节点的next指针的值。
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
if (next)
{
pos->next = next->next;
free(next);
next = NULL;
}
}
2.5销毁链表
由于我们是有的每一个节点都是动态分配出来的,所以当我们不再使用链表的时候,我们需要将该链表中的所有节点对应的空间全部释放
我们声明销毁链表的函数是
void SListDestroy(SListNode** pphead);
//唯一的参数是头指针的地址
为了保证所有动态开辟出来的空间都被释放,我们可以从头指针指向的第一个节点开始,每次释放一个节点,直到释放掉最后一个节点。
该函数的具体实现:
void SListDestroy(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
while (cur)
{
SListNode* next = cur->next;//每次指向后面一个节点
free(cur);
cur = next;
}
*pphead = NULL;
}
3.总结
定位置后面的一个节点
我们声明该函数为:
void SListErase()
需要先保存pos->next的值,以便于再释放空间的时候可以找到地址
然后然指定位置节点的next指针保存下一个节点的next指针的值。
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
if (next)
{
pos->next = next->next;
free(next);
next = NULL;
}
}
2.5销毁链表
由于我们是有的每一个节点都是动态分配出来的,所以当我们不再使用链表的时候,我们需要将该链表中的所有节点对应的空间全部释放
我们声明销毁链表的函数是
void SListDestroy(SListNode** pphead);
//唯一的参数是头指针的地址
为了保证所有动态开辟出来的空间都被释放,我们可以从头指针指向的第一个节点开始,每次释放一个节点,直到释放掉最后一个节点。
该函数的具体实现:
void SListDestroy(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
while (cur)
{
SListNode* next = cur->next;//每次指向后面一个节点
free(cur);
cur = next;
}
*pphead = NULL;
}
3.总结
由于头指针以及单向链表特殊的结构,对于链表后面的节点进行操作的效率要低于对前面部分节点操作的效率,所以单向链表更适合对前面的节点进行操作。