Linux编程 - 进程详解
一 进程基本概念
1.1 进程和程序
- 进程(process)的定义
狭义定义是:进程是正在运行的程序(program)的实例。
更精确的定义是:进程是允许某个并发执行的程序在某个数据集合上的一次运行活动。进程是操作系统进行资源分配和调度的基本单位。
程序(program):是包含了一系列信息的文件,这些信息描述了如何在运行时创建一个进程。所包含的信息内容如下:
- 二进制格式标识。每个程序文件都包含用于描述可执行文件格式的元信息(metainformation)。内核(kernel)利用此信息来解释文件中的其他信息。历史上,UNIX可执行文件曾有两种广泛使用的格式,分别为最初的 a.out(汇编程序输出)和更加复杂的 COFF(通用对象文件格式)。现在,大多数UNIX实现(包括Linux)采用可执行连接格式(ELF),这一文件格式比老版本格式具有更多优点。
- 机器语言指令:对程序算法进行编码的二进制指令。
- 程序入口地址:标识程序开始执行时的起始指令位置。
- 数据:程序文件包含的变量初始值和程序使用的字面常量(literal constant)值。比如:字符串,数值常量。
- 符号表及重定位表:描述程序中函数和变量的位置和名称。这些表格有多种用途,其中包括调试和运行时的符号解析(动态链接)。
- 共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态链接器的路径名。
- 其他信息:程序文件还包含许多其他信息,用以描述如何创建进程。
从内核角度看,进程是由内核定义的抽象的实体,并为该实体分配用以执行程序所需的各项系统资源。因此,进程是由用户内存空间(user-space memory)和一系列内核数据结构组成。其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程的状态信息。记录在内核数据结构中的信息包括进程标识符(PID)、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
1.2 进程的特征
进程是操作系统管理的实体,对应了程序的执行过程。其具有以下几个特征:
- 并发性。多个进程实体能在一段时间间隔内同时运行。并发性是进程和现代操作系统的重要特征。
- 动态性。进程是程序实例的执行过程。进程的动态性表现在因运行程序而被创建、因获得CPU而执行进程的指令、因运行终止而被撤销的动态变化过程。此外,进程在创建后还有进程状态的变化。
- 独立性。在没有引入线程概念的操作系统中,进程是独立运行和资源调度的基本单位。在有引入线程概念的操作系统中,进程是资源调度的基本单位,线程是CPU调度的基本单位。每个进程都有自己独立的地址空间,互不干扰。
- 随机性。是指进程的执行时断时续,进程什么时候执行、什么时候暂停都无法预知,呈现一种随机的特性。
- 结构特征。 进程实体包括用户代码段、用户数据段和进程控制块(PCB)。
1.3 进程与程序的联系与区别
1.3.1 进程与程序的联系
(1)进程是程序在某个数据集合的运行过程,即进程是程序的一次执行过程。
(2)可以用同一个程序来创建多个进程,或者反过来说,多个进程运行的可以是同一个程序代码,即一个程序可以对应多个进程。
(3)同一个程序可以在不同的数据集合上运行,因而构成多个不同的进程。
(4)多个进程能并发地执行同一个程序,而一个进程只能对应一个特定的程序。进程和程序的关系犹如演出和剧本的关系。
1.3.2 进程与程序的区别
- 动态和静态的区别
(1)进程是动态的,而程序是静态的。因为程序是存储在某种介质上的指令集合,它是静止不变的;而进程是程序在某个数据集合的一次执行过程,进程一旦被创建,就处于不断变化的动态过程中,对应了一个不断变化的上下文环境。这是二者最本质的区别。
- 生存周期的区别
(2)进程是程序的一次执行过程,它是动态创建和消亡的,具有一定的生命周期,是暂时存在的;程序是一组指令的集合,它是永久存在,可以长期保存。
- 组成的区别
(3)进程是由程序、数据和进程控制块(PCB)三部分组成;而程序只是一组有序的指令集合。
1.4 进程与线程的联系与区别
1.4.1 进程和线程之间的联系
1、一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程(通常说的主线程)。
2、资源分配给进程,同一进程的所有线程共享该进程的所有资源。
3、线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
4、处理机分给线程,即真正在处理机上运行的是线程。
5、线程是进程内的一个执行单元,也是进程内的可调度实体。
1.4.2 进程与线程的区别,从四个角度来剖析二者之间的区别
(1)调度:线程是CPU调度的基本单位,而进程是操作系统资源分配的基本单位。(这一条是本质区别)
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行。
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以共享隶属于进程的资源。
(4)系统开销:在创建或撤消进程时,由于操作系统都要为之分配和回收资源,导致系统开销明显高于创建或撤消线程时的开销。
【参考博文链接】
进程、线程和上下文切换
1.5 进程的状态和状态转换
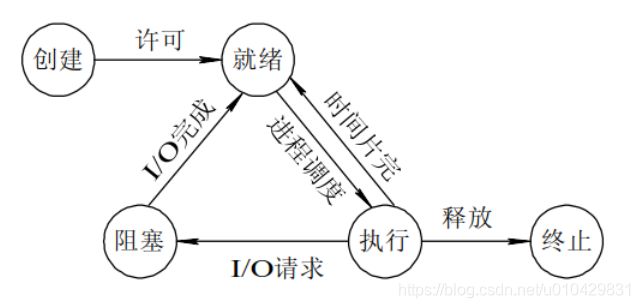 图1-1 进程的五种基本状态及转换
图1-1 进程的五种基本状态及转换
创建态:进程在创建时需要申请一个空白进程控制块(PCB),向其中填充控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
就绪态:进程已经准备好,已分配到所需资源,已经具备运行条件,但是CPU还没有分配过来,一旦获得CPU的控制权,便可立即执行。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列。
运行态:进程处于就绪状态被CPU调度后,进程进入运行的状态。在单处理机系统中,只有一个进程处于运行状态; 在多处理机系统中,则可以有多个进程同时处于运行状态。
阻塞态:正在运行的进程由于某种事件(如 I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时,就会重新进入就绪态等待CPU调用执行。处于阻塞状态的进程也会排成一个队列,称为阻塞队列。有的系统则根据阻塞原因的不同而把处于阻塞状态的进程排成多个队列。
终止态:进程运行结束,或运行出现错误,或被系统终止,进入终止状态。无法再继续执行。
进程的状态主要是就绪态、运行态和阻塞态 这三种状态之间的转换条件。
1、就绪态 ——> 运行态:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配给CPU执行。
2、运行态 ——> 就绪态:(1) 主要是进程占用CPU的时间过长,而系统分配给该进程占用CPU的时间是有限的;(2) 在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行时,该进程就被迫让出CPU,该进程便由运行态转变为就绪态。
3、运行态 ——> 阻塞态:正在执行的进程因发生某种等待事件而无法执行,则进程由运行态转变为阻塞态,如发生了I/O请求事件。
4、阻塞态 ——> 就绪态:进程所等待的事件已经完成,则进程进入就绪态。
以下两种情况是不可能发生的:
阻塞态 ——> 运行态:即使给阻塞进程分配CPU,也无法执行,操作系统在进行进程调度时不会从阻塞队列中进行挑选,而是从就绪队列中选取。
就绪态 ——> 阻塞态:处于就绪态的进程根本就没有执行,谈不上进入阻塞态。
在一些操作系统的具体实现中(如Linux操作系统),设计者可以根据实际情况设置不同的状态,这样一来就出现了以下几种状态:
- 可运行态:它是运行态和就绪态的合并,表示进程正在运行或准备运行,Linux 中使用 TASK_RUNNING 宏表示此状态。
- 浅度睡眠态:进程正在睡眠(被阻塞),等待资源到来时唤醒,也可以通过其他进程信号或时钟中断唤醒,进入运行队列。Linux 使用 TASK_INTERRUPTIBLE 宏表示此状态。
- 深度睡眠态:其和浅度睡眠态基本类似,但有一点不同就是不可被其他进程信号或时钟中断唤醒。Linux 使用 TASK_UNINTERRUPTIBLE 宏表示此状态。
- 暂停状态:进程暂停执行接受某种处理。如正在接受调试的进程处于这种状态,Linux 使用 TASK_STOPPED 宏表示此状态。
- 僵尸状态:进程已经结束运行但未释放进程控制块(PCB),Linux 使用 TASK_ZOMBIE 宏表示此状态。
我们可以来看下以上宏在内核中的定义:
182 #define TASK_RUNNING 0
183 #define TASK_INTERRUPTIBLE 1
184 #define TASK_UNINTERRUPTIBLE 2
185 #define __TASK_STOPPED 4
186 #define __TASK_TRACED 8
187 /* in tsk->exit_state */进程的退出状态
188 #define EXIT_ZOMBIE 16
189 #define EXIT_DEAD 32
190 /* in tsk->state again */我理解为进程的唤醒状态
191 #define TASK_DEAD 64
192 #define TASK_WAKEKILL 128
193 #define TASK_WAKING 256
194 #define TASK_STATE_MAX 512
195
196 #define TASK_STATE_TO_CHAR_STR "RSDTtZXxKW"- 挂起状态:在执行状态的进程通过挂起即可进入就绪状态,就绪态和阻塞态分别称为活动态和静止态。由活动态向静止态转换就是通过挂起实现的。
引入挂起状态的原因有:
(1) 终端用户的请求。当终端用户在自己的程序运行期间发现有可疑问题时,希望暂时使自己的程序静止下来。亦即,使正在执行的进程暂停执行;若此时用户进程正处于就绪状态而未执行,则该进程暂不接受调度,以便用户研究其执行情况或对程序进行修改。我们把这种静止状态称为挂起状态。
(2) 父进程请求。有时父进程希望挂起自己的某个子进程,以便考查和修改该子进程,或者协调各子进程间的活动。
(3) 负荷调节的需要。当实时系统中的工作负荷较重,可能已影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
(4) 操作系统的需要。操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
具有挂起状态的进程状态转换图如下所示:
 具有挂起状态的进程状态转换图
具有挂起状态的进程状态转换图
- 子进程被Linux内核调入CPU执行的过程
父进程通过 fork() 系统调用创建子进程,子进程被创建后,处于创建态。当子进程处于就绪态后,等待Linux内核调度。Linux内核会为子进程分配CPU时间片,在合适的时间将子进程调度到CPU上运行,这是子进程处于内核态,子进程开始运行。当被分配的时间片结束时,Linux内核再次调度子进程,将子进程调出CPU,此时子进程进入用户态。待子进程被分配到下一个CPU时间片到来时,Linux内核又将子进程调度到CPU运行,使子进程进入内核态。如果有其他的进程获得更高的优先级,子进程可能会被抢占,这时子进程又会回到用户态。
1.6 进程终止
有8种方式可以使进程终止(termination),其中5种为正常终止,它们是:
(1)从main()函数返回;
(2)调用 exit() 系统调用;
(3)调用 _exit() 或 _Exit() 系统调用;
(4)最后一个线程从其启动例程返回;
(5)从最后一个线程调用 pthread_exit() 函数。
异常终止有3种方式,它们是:
(6)调用 abort() 函数;
(7)接到一个信号(Signal);
(8)最后一个线程对取消请求做出反应。
1.7 进程上下文切换
子进程在内核中的数据结构又被称为进程上下文。进程上下文包括3个部分:用户级上下文是子进程用户空间的内容;寄存器上下文是子进程运行时装入CPU寄存器的内容;系统级上下文是子进程在Linux内核中的数据结构。
子进程在切换时,CPU会收到一个软中断,这是上下文环境将会被保存在内存中,称之为保护现场。子进程再次运行时,上下文会被还原到相关位置,称之为还原现场。整个过程称为上下文切换,保存上下文的数据空间称为 u 区,是Linux内核为进程分配的存储空间。内核在以下情况会进行上下文切换操作:
- 子进程进入睡眠状态。
- 子进程时间片结束,被转为用户态。
- 子进程再次被调度到CPU上运行,转为内核态。
- 子进程僵死时。
1.8 进程控制
在Linux系统中,用户创建子进程的唯一方法就是使用 fork() 系统调用。
首先,Linux内核在进程表中为子进程分配一个进程表项,然后分配进程号PID。子进程表项来自于父进程,fork 系统调用父进程的进程表项复制为副本,并分配给子进程。
然后,Linux内核使父进程的文件表和索引表的节点自增1,创建用户级上下文。
最后,将父进程的上下文复制到子进程的上下文地址空间中。fork 系统调用结束后,子进程的PID被返回给父进程,而子进程获得的值为0。
最简单的进程控制为结束进程,通过 exit() 系统调用实现。进程执行 exit() 系统调用后,Linux内核将删除进程的上下文,但保留进程表项,进程进入僵死状态。等待合适的时候,再删除进程表项中的内容,释放进程PID。
父进程与子进程的同步是通过 wait() 系统调用实现的。父进程调用 wait() 系统调用后,父进程的执行被阻塞,直到子进程进入僵死状态。这是,子进程的退出参数可通过 wait() 函数返回给父进程。wait() 系统调用常被用来判断子进程是否已运行结束。
除此之外,进程还可使用 exec() 系统调用运行一个可执行文件。该 exec 和 fork 系统调用的区别是,exec 系统调用会结束原有进程,原有进程的上下文(代码段、数据段、堆栈段)会被改写,并在原有进程内存空间里重新开始执行一个新的进程来代替调用exec()系统调用的那个进程。新进程会保持原有进程的PID不变。新进程与原有进程之间没有父子关系。
下图是 fork() 系统调用流程:
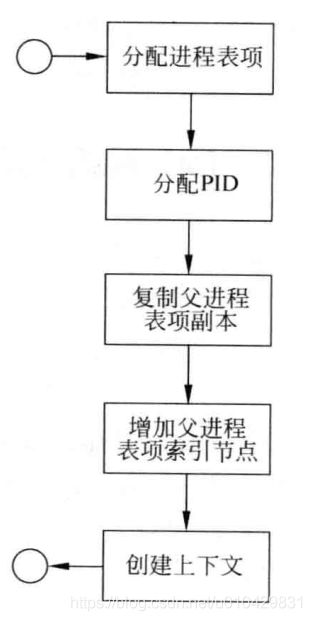 fork系统调用流程
fork系统调用流程
1.9 进程调度
Linux系统是分时操作系统。Linux内核可同时执行多个进程,并为每个进程分配CPU时间片。当一个进程的时间片结束时,Linux内核会调度另一个进程到CPU上执行,如此往复。这种调度方法属于多级反馈循环,Linux内核会为每个进程设定优先级。如果有进程处于较高的优先级,那么它能够抢占较低优先级进程的CPU时间片。
Linux系统进程调度包括两个概念,分别是调度时机和调度算法。调度时机是指进程何时被调度到CPU上执行。例如,转变为睡眠状态的进程将获得较高的优先级,一旦所需要的资源得到满足,该进程可以立即被调度到CPU上执行。被抢占的进程也将获得一个较高的优先级,抢占其CPU时间片的进程一旦转为用户态,被抢占的进程可以立即转为内核态,调度到CPU上执行。调度算法所关心的内容就是如何为进程分配优先级。
为Linux设计程序时,通常不需要人为地设置进程的优先级,Linux系统进程调度机制可以保证所有进程都能获得足够的运行时间。
二 进程内存管理
2.1 进程内存布局
当可执行文件运行为进程时,操作系统会为每个进程分配内存空间。这个空间是进程自己的内存空间,它是由很多部分组成,通常称之为“段(segment)”,有时也会使用术语“区(section)”来代替段。
每个进程内存空间按照如下方式分为不同区域:
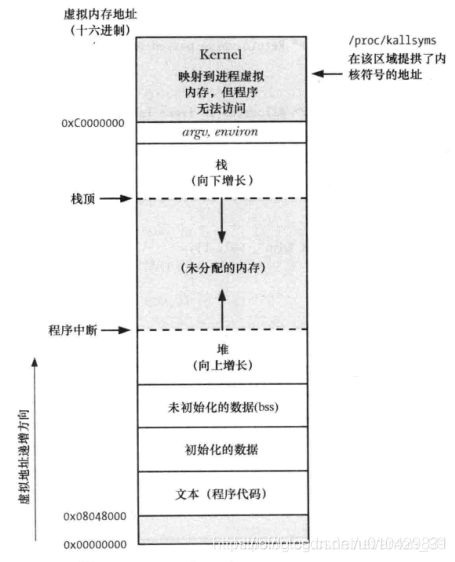 x86-32体系结构中的进程内存布局
x86-32体系结构中的进程内存布局
- 文本段(text):包含了进程运行的程序代码(.init 和 .text)和只读数据(.rodata)。文本段具有只读属性,以防止进程通过错误指针意外修改程序指令。因为多个进程可同时运行同一程序,所以又将文本段设为可共享,这样,一份程序代码的拷贝可以映射到所有这些进程的虚拟地址空间中。
- 数据段(data):数据段具体又分为初始化数据段和未初始化数据段。初始化数据段包含显式初始化的全局变量和静态变量。当程序加载到内存时,从可执行文件中读取这些变量的值。未初始化数据段包含了未进行初始化的全局变量和静态变量。程序启动之前,系统将本段内的所有内存的值初始化为零值。出于历史原因,此段常被称为 BSS 段,这源于老版本的汇编语言助记符“block started by symbol”。将经过初始化的全局变量和静态变量与未经过初始化的全局变量和静态变量分开存放,其主要原因在于程序在磁盘中存储时,没有必要为未经初始化的变量分配存储空间。相反,可执行文件只需记录未初始化数据段的位置及所需存储空间大小,直到运行时再由程序加载器来分配这一空间。
- 栈(stack):栈是一个动态增长和收缩的段,由栈帧(stack frames)组成。系统会为每一个当前调用的函数分配一个栈帧。栈帧中存储了函数的局部变量(即所谓的自动变量)、实参和返回值。注意:当给被调用函数分配栈帧时,此时栈是向内存低地址延伸;当函数返回值,栈会向高地址延伸,这相当于释放栈帧的内存空间。
- 堆(heap):堆是在运行期间动态分配的一块内存区域。一般由程序动态分配和释放(new/malloc/calloc,delete/free),动态分配的内存空间在进程运行结束前,会一直存在,直到使用free()系统调用释放或者进程运行结束。一个经典的错误是内存泄漏(memory leakage),就是指进程没有释放不再使用的堆空间,导致堆区空间不断增长,使得内存可用空间不断减少。注意:当使用malloc()申请空间时,堆向高地址延伸,即上图中的向上增长,其增长的部分就成为malloc从内存中分配的空间。
- 图中的顶部标记为argv、environment的空间存放的是命令行参数和环境变量,将命令行参数和环境变量放到指定位置这个操作是由操作系统(OS)的一段代码(exec系统调用)在加载可执行文件到内存后,开始运行程序前完成的。
- 图中最上面的区域是共享库的内存映射区域:这是Linux动态链接器和其他共享库代码的映射区域。
栈和堆的大小会随着进程的运行增大或者变小。当栈和堆增长到两者相遇的时候,也就是内存空间图中的未分配内存区域(Unused Area)完全消失的时候,再无可用内存。进程会出现栈溢出(stack overflow)的错误,导致进程终止。在现代计算机中,内核一般会为进程分配足够多的Unused Area区域,如果清理及时,栈溢出很容易避免。即便如此,内存负荷过大,依然可能出现栈溢出的情况。我们就需要增加物理内存了。
对于初始化和未初始化的数据段(Data Segment )而言,不太常用,当表述更清晰的称谓分别是用户初始化数据段(user-initialized data segment)和零初始化数据段(zero-initialized data segment)。
在Linux系统中,我们可以使用 size 命令来显示一个二进制可执行文件的文本段(.text)、初始化数据段(.data)和非初始化数据段(.bss)的段大小。示例如下:
$ size a.out
text data bss dec hex filename
521983 16048 12616 550647 866f7 a.out2.2 虚拟内存管理
2.1节中描述的进程内存布局其实是存在于虚拟内存中的,并不是真正的物理内存。现在的操作系统都是多用户多任务的,同时运行着很多进程,为了方便对内存资源进行管理,操作系统大多都采用了虚拟内存管理技术。该技术利用了大多数程序的一个典型特征,即访问局部性(locality of reference),以求高效使用CPU(处理机)和RAM(物理内存)资源。大多数程序都展现了两种类型的局限性:
- 空间局部性(Spatial locality):是指程序倾向于访问在最近访问过的内存地址附近的内存(由于指令是顺序执行的,且有时会按顺序处理数据结构)。
- 时间局部性(temporal locality):是指程序倾向于在不久的将来再次访问最近刚访问过的内存地址(由于循环执行)。
正是由于访问局部性特征,使得程序即使仅有部分地址空间存在于RAM中,依然可能得到执行。正是由于使用了虚拟物理内存技术,使得程序在运行时,给每个进程虚拟出的内存空间,可能会比实际物理内存还要大,让每个进程认为自己独占所有的物理内存。这样做的好处之一就是程序开发人员在开发程序时不需要增加管理物理内存的问题,这个任务交由操作系统来解决。
以32位系统为例,系统会为每个进程提供4G的虚拟内存,其中3G是用户空间,1G是内核空间。如下图所示:
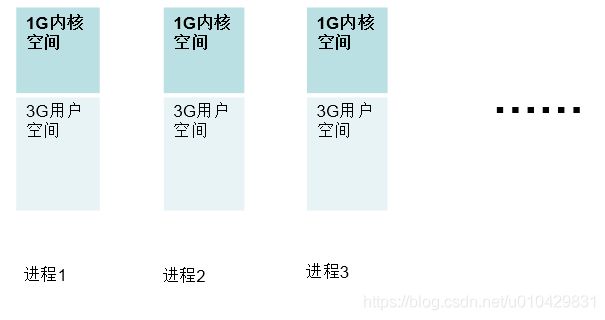
虚拟内存的实现机制
虚拟内存的规划之一就是将每个程序使用的内存切割成小型的、固定大小的“页(page)”单元。相应地,将RAM划分成一系列与虚拟页大小相同的页帧(page frame)。任意时刻,每个程序仅有部分页需要驻留在物理内存页帧中。这些页构成了所谓的驻留集(resident set)。而程序未使用的页则拷贝保存在交换区(swap area)内——这是磁盘空间中的保留区域,交换区是作为计算机RAM的补充——仅在需要时才会载入物理内存。若进程欲访问的页面目前并未驻留在物理内存中,将会发生页面错误(page fault),内核即刻挂起进程的执行,同时从磁盘交换区中将该页面载入内存中。
在 x86-32中,页面大小为4096个字节大小。其他一些Linux实现使用的页面比4096个字节更大。程序可调用 sysconf(_SC_PAGESIZE) 来获取系统虚拟内存的页面大小。
为支持上面的这一组织方式,内核需要为每个进程维护一张页表(page table)。该页表描述了每一页在进程虚拟地址空间(virtual address space)中的位置(可为进程所用的所有虚拟内存页面的集合)。页表中的每个条目要么指出一个虚拟页面在RAM中的所在位置,要么表明其当前驻留在磁盘的交换区中。
虚拟内存的映射机制 —— 页机制
页:系统将虚拟内存分成4K大小的块。每一块就是一页,作为内存管理的最小单位。每个页都会有一个编号,按从小到大的顺序编号。
页框(块):系统将物理内存也和虚拟内存一样分成4K大小的块,每块就是一个页框,与页一一对应。
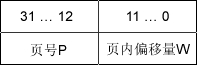
地址结构:分页存储管理的逻辑地址结构如图前一部分为页号P,后一部分为页内偏移量W。地址长度为32 位,其中0~11位为页内地址,即每页大小为4KB;
页表:为了便于在内存中找到进程的每个页面所对应的物理页块,系统为每个进程建立一张页表,记录页在内存中对应的页块号,页表一般存放在内存中。在配置了页表后,进程执行时,通过查找该表,即可找到每页在内存中的物理块号。可见,页表的作用是实现从页号到页块号的地址映射,亦即实现虚拟(逻辑)地址到物理地址的映射。
如下图,就是虚拟地址的各个页面通过页表找到具体的物理页块,也就是找到真正的物理内存。同时可以看到在虚拟地址空间中连续的空间,实际上在物理上不连续的。这样就使碎片化内存得到利用,使内存的利用率变得更高。
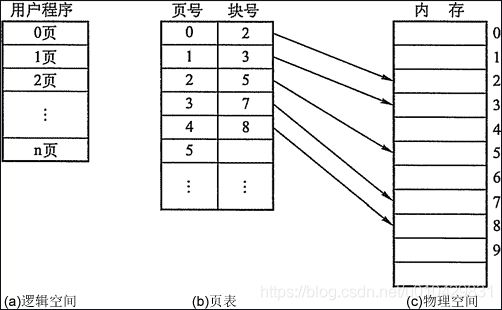 虚拟地址与物理地址的映射关系
虚拟地址与物理地址的映射关系
二级页表
分页管理,进程在执行时不需要将所有页帧调入物理内存页块中,而只需将保存有映射关系的页表调入内存中即可。但是我们仍然需要考虑页表的大小。以32 位逻辑地址空间、页面大小4KB、页表项大小4B为例,若要实现进程对全部逻辑地址空间的映射,则每个进程需要2^20,1M个表项。也就是说,每个进程仅页表这一项就需要4MB主存空间,这显然是不切实际的。而即便不考虑对全部逻辑地址空间进行映射的情况,一个逻辑地址空间稍大的进程,其页表大小也可能是很大的。以一个40MB的进程为例,页表项共40KB,如果将所有页表项内容保存在内存中,那么需要10个内存页块来保存整个页表。整个进程大小约为1万个页面,而实际执行时只需要几十个页面进入内存页块就可以运行,但如果要求10个页面大小的页表必须全部进入内存,这相对实际执行时的几十个进程页面的大小来说,肯定是降低了内存利用率的;从另一方面来说,这10页的页表项也并不需要同时保存在内存中,因为大多数情况下,映射所需要的页表项都在页表的同一个页面中。
将页表映射的思想进一步延伸,就可以得到二级分页:将页表的2^10页空间也进行地址映射,建立上一级页表,用于存储页表的映射关系。这里对页表的2^10个页面进行映射只需要2^10个页表项,所以上一级页表只需要1页就足够(可以存储2^10=1024个页表项)。在进程执行时,只需要将这1页的上一级页表调入内存即可,进程的页表和进程本身的页面,可以在后面的执行中再调入物理内存。
我们以Intel处理器80x86系列的硬件分页的地址转换过程为例。在32位系统中,全部32位逻辑地址空间可以分为2^20(4GB/4KB)个页面。这些页面可以再进一步建立顶级页表,需要2^10个顶级页表项进行索引,这正好是一个页面的大小4KB,所以建立二级页表即可,所以内存实际要保存页表所占的空间就极少了。假设:每2^10个页面映射一个顶级页表表项。
进程虚拟内存大小:4GB;页面大小:4KB;页表项大小:4B;物理内存页块大小:4KB。
页面个数=4GB / 4B = 2^20;一级页表项数=页面个数 / 2^10 = 2^10;二级页表项数=2^10。
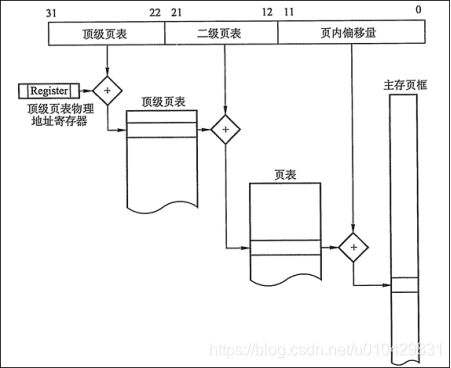 二级页表映射图
二级页表映射图
例如逻辑地址: 0x20021406 (0010 0000 0000 0010 0001 0100 0000 0110 B)
顶级页表字段:0x80 (00 1000 0000 B)
二级页表字段:0x21 (00 0010 0001 B)
页内偏移量字段:0x406 (0100 0000 0110 B)
顶级页表字段的0x80用于选择顶级页表的第0x80表项,此表项指向和该进程的页相关的二级页表;二级页表字段0x21用于选择二级页表的第0x21表项,此表项指向包含所需页的页块;最后的页内偏移量字段0x406用于在目标页块中读取偏移量为0x406中的字节。
页表结构
在请求分页系统中,请求分页系统在一个作业运行之前不需要一次性全部调入物理内存,因此在作业的运行过程中,必然会出现要访问的页面不在内存的情况,如何发现和处理这种情况是请求分页系统必须解决的两个基本问题。为此,在请求页表项中增加了四个字段。
增加的四个字段说明如下:
状态位P:用于指示该页是否已调入物理内存,供程序访问时参考。
访问字段A:用于记录本页在一段时间内被访问的次数,或记录本页最近己有多长时间未被访问,供置换算法换出页面时参考。
修改位M:标识该页在调入内存后是否被修改过。
外存地址:用于指出该页在外存上的地址,通常是物理块号,供调入该页时参考。
![]()
虚拟内存管理技术的优点
虚拟内存管理使进程的虚拟地址空间与RAM物理地址空间隔离开来,这带来很多优点。
- 进程与进程、进程与内核相互隔离,所以一个进程不能读取另一个进程或内核的内存。这是因为每个进程的页表项指向RAM(或交换区)中完全不同的物理页面集合。
- 适当情况下,两个或者更多个进程能够共享内存。这是由于内核可以使不同进程的页表项指向相同的RAM页块。内存共享常发生于如下两种场景:
(1)执行同一程序的多个进程,可共享一份(只读的)程序代码副本。当多个程序执行相同的程序文件(或加载相同的共享库)时,会隐式地实现这一类型的共享。
(2)进程可以使用 shmget() 和 mmap() 系统调用显式地请求与其他进程共享内存区。这么做是出于进程间通信的目的,即通过共享内存的方式实现进程间通信。
- 便于实现内存保护机制:可以通过对页表条目进行标记,以表示相关页面内容是可读、可写、可执行亦或是这些保护措施的组合。多个进程共享RAM页块时,允许每个进程对内存页块采取不同的保护措施。例如,一个进程可能以只读方式访问某页面,而另一进程则以读写方式访问同一页面。
- 开发人员和编译器、链接器之类的工具无需关注程序在RAM中的物理布局。
- 因为需要驻留在物理内存中的仅是程序的一部分,所以程序的加载和运行都会很快。而且,一个进程所占用的内存(即虚拟内存大小)可以超出RAM容量。
- 由于每个进程实际使用的RAM较少了,RAM中同时可以容量的进程数量就增多了,也就提高了CPU的使用率。
参考
Linux C进程内存布局
理解进程内存布局
虚拟内存管理简要分析
Linux进程概念(精讲)
Linux进程控制(精讲)