怎么做好Java性能优化
0. 开篇
性能优化是一个很复杂的工作,且充满了不确定性。它不像Java业务代码,可以一次编写到处运行(write once, run anywhere),往往一些我们可能并不能察觉的变化,就会带来惊喜/惊吓。能够全面的了解并评估我们所负责应用的性能,我认为是提升技术确定性和技术感知能力的非常有效的手段。本文尽可能简短的总结我自己在性能优化上面的一些体会和经验,从实践的角度出发尽量避免过于啰嗦和生硬,但相关的知识实在太多,受限于个人经验和技术深度,不足之外还请大家补充。
第1部分是偏背景类知识的介绍,有这方面知识的同学可以直接跳过。
1. 了解运行环境
大多数的编程语言(尤其是Java)做了非常多的事情来帮助我们不用太了解硬件也能很容易的写出正确工作的代码,但你如果要全面了解性能,却需要具备不少的从硬件、操作系统到软件层面的知识。
1.1 服务器
目前我们大量使用Intel 64位架构的Xeon处理器,除此之外还会有AMD x64处理器、ARM服务器处理器(如:华为鲲鹏、阿里倚天)、未来还会有RISC-V架构的处理器、以及一些专用FPGA芯片等等。我们这里主要聊聊目前我们大量使用的阿里云ECS使用的Intel 8269CY处理器。
1.1.1 处理器
Intel Xeon Platinum 8269CY,阿里云使用的这一款处理器是阿里定制款,并不能在Intel的官方手册中查询到,不过我们可以通过下方Intel处理器的命名规则了解到不少的信息,它是一款这样的处理器:主频2.5GHz(睿频3.2GHz、最大睿频3.8GHz),26核心52线程(具备超线程技术),6通道DDR4-2933内存,最大配置内存1T,Cascade Lake微架构,48通道PCI-E 3.0,14nm光刻工艺,205W TDP。它是这一代至强处理器中性能比较强的型号了,最大支持8路部署。
具备动态自动超频的能力将能够短时间提升性能,同时在少数核心忙碌的时候还可以让它们保持长时间的自动超频,这会严重的影响我们对应用性能的评估(少量测试时性能很好,大规模测试时下降很厉害)。最大配置内存1TB,代表处理器具备48bit的VA(虚拟地址),也就是通常需要四级页表(下一代具备57bit VA的处理器已经在设计中了,通常需要五级页表),过深的页表显然是极大的影响内存访问的性能以及占用内存(页表也是存储在内存中的)的,所以Intel设计了大页(2MB、1GB大页)机制,以减少过深的页表带来的影响。6通道2933MHz的内存总线代表它具备总计约137GB/s(内存总线是64bit位宽)的宽带,不过需要记住他们是高度并行设计的。

这个微处理的CPU核架构如下图所示,采用8发射乱序架构, 32KB指令+32KB数据 L1 Cache,1MB L2 Cache。发射单元是CPU内部真正的计算单元,它的多少是CPU性能的关键因素。8个发射单元中有4个单元都可以进行基本整数运算(ALU单元),只有2个可以进行整数乘除和浮点运算,所以对于大量浮点运算的场景并行效率会偏低。1个CPU核对应的2个HT(这里指超线程技术虚拟出的硬件线程)是共享8个发射单元的,所以这两个HT之间将会有非常大的相互影响(这也会导致操作系统内CPU的使用率不再是线性值,具体请查阅相关资料),L1、L2 Cache同样也是共享的,所以也会相互影响。
Intel Xeon处理器在分支预测上面花了很多功夫,所以在较多分支代码(通常就是if else这类代码)时性能往往也能做的很好,比大多数的ARM架构做的都要好。Java常用的指针压缩技术也受益于x86架构灵活的寻址能力(如:mov eax, ecx * 8 + 8),可以一条指令完成,同时也不会带来性能的损失,但是这在ARM、RISC-V等RISC(精简指令集架构,Reduced Instruction Set Computing)处理器上就不适用了。
从可靠渠道了解道,下一代架构(Sunny Cove)将大幅度的进行架构优化,升级为10发射,同时L1 Cache将数据部分增加到48KB,这代表接下来的处理器将更加侧重于提升SIMD(单指令多操作数,Signle Instruction Multiple Data)等的数据计算性能。
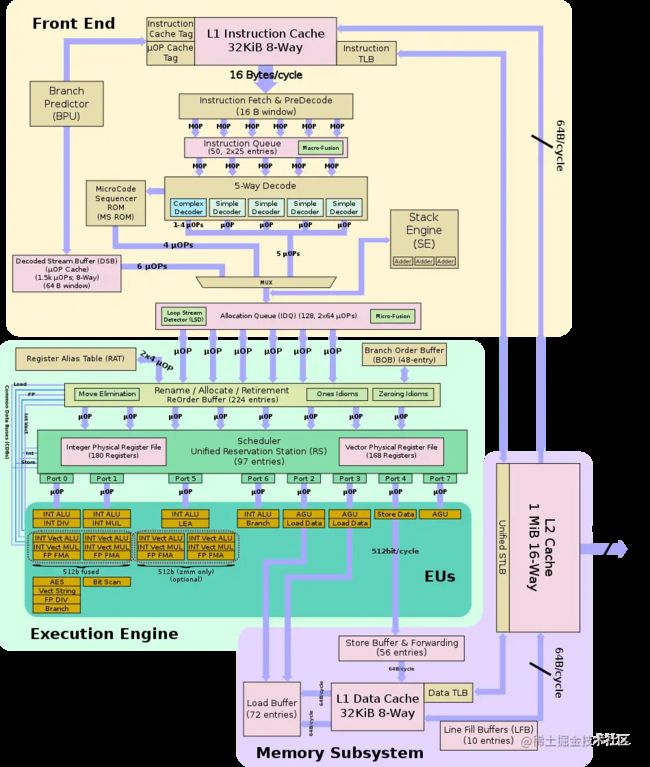
一颗8269CY内部有26个CPU核,采用如下的拓扑结构进行连接。这一代处理器最多有28个CPU核,8269CY屏蔽掉了2个核心,以降低对产品良率的要求(节约成本)。可以看到总计35.75MB的L3 Cache(图中为LLC: Last Level Cache)被分为了13块(图中是14块,屏蔽2个核心的同时也屏蔽了与之匹配的L3 Cache),每块2.75MB,并不是简单意义理解上的是一大块统一的区域。6通道的内存控制器也分布在左右两侧,与实际主板上内存插槽的位置关系是对应的。这些信息都告诉我们,这是一颗并行能力非常强的多核心处理器。

1.1.2 服务器
阿里云通常都是采用双Intel处理器的2U机型(基于散热、密度、性价比等等的考虑),基本都是2个NUMA(非一致性内存访问,Non Uniform Memory Access)节点。具体到Intel 8269CY,代表一台服务器具备52个物理核心,104个硬件线程,通常阿里云会称之为104核。NUMA技术的出现是硬件工程师的妥协(他们实在没有能力做到在多CPU的情况下还能实现访问任何地址的性能一致性),所以做的不好也会严重的降低性能,大多数情况下虚拟机/容器调度团队要做的是将NUMA打开,同时将一个虚拟机/容器部署到同一个NUMA节点上。
这几年AMD的发展很好,它的多核架构与Intel有很大的不同,不久的将来阿里云将会部署不少采用AMD处理器的机型。AMD处理器的NUMA节点将会更多,而且拓扑关系也会更复杂,阿里自研的倚天(采用ARM架构)就更复杂了。这意味着虚拟机/容器调度团队够得忙了。
多数情况下服务器大都采用CPU:内存为1:2或1:4的配置,即配置双Intel 8269CY的物理机,通常都会配备192GB或384GB的内存。如果虚拟机/容器需要的内存:CPU过大的情况下,将很难实现内存在CPU对应的NUMA节点上就近分配了,也就是说性能就不能得到保证。
由于2U机型的物理高度是1U机型的2倍,所以有更多的空间放下更多的SSD盘、高性能PCI-E设备等。不过云厂商肯定是不愿意直接将物理机卖给用户(毕竟他们已经不再是以前的托管物理机公司)的,再怎么也得在上面架一层,也就是做成ECS再卖给客户,这样诸如热迁移、高可用等功能才能实现。前述的"架一层"是通过虚拟化技术来实现的。
1.1.3 虚拟化技术
一台物理机性能很强大,通常我们只需要里面的一小块,但我们又希望不要感知到其他人在共享这台物理机,所以催生了虚拟化技术(简单来说就是让可以让一个CPU工作起来就像多个CPU并行运行,从而使得在一台服务器内可以同时运行多个操作系统)。早期的虚拟机技术是通过软件实现的,老牌厂商如VMWare,但是性能牺牲的有点多,硬件厂商也看好虚拟机技术的前景,所以便有了硬件虚拟化技术。各厂商的实现并不相同,但差异不是很大,好在有专门的虚拟化处理模块去兼容就可以了。
Intel的虚拟化技术叫Intel VT(Virtualization Technology),它包括VT-x(处理器的虚拟化支持)、VT-d(直接I/O访问的虚拟化)、VT-c(网络连接的虚拟化),以及在网络性能上的SR-IOV技术(Single Root I/O Virtualization)。这里面一个很重要的事情是,原本我们访问内存的一层转换(线性地址->物理地址)会变成二层转换(VM内线性地址->Host线性地址->物理地址),这会引入更多的内存开销以及页表的转换工作。所以大多数云厂商会在Host操作系统上开启大页(Linux 操作系统通常是使用透明大页技术),以减少内存相关的虚拟化开销。
服务器对网络性能的要求是很高的,现在的网络硬件都支持网卡多队列技术,通常情况下需要将VM中的网络中断分散给不同的CPU核来处理,以避免单核转发带来的性能瓶颈。
Host操作系统需要管理它上面的一个或多个VM(虚拟机,Virtual Machine),以及前述提及的处理网卡中断,这会带来一定的CPU消耗。阿里云上一代机型,服务器总计是96核(即96个硬件线程HT,实际是48个物理核),但最多只能分配出88核,需要保留8个核(相当于物理机CPU减少8.3%)给Host操作系统使用,同时由于I/O相关的虚拟化开销,整机性能会下降超过10%。
阿里云为了最大限度的降低虚拟化的开销,研发了牛逼的“弹性裸金属服务器 - 神龙”,号称不但不会因为虚拟化降低性能,反而会提升部分性能(主要是网络转发)。
1.1.4 神龙服务器
为了避免虚拟化对性能的影响,阿里云(类似还有亚马逊等云厂商的类似方案)研发了神龙服务器。简单来说就是设计了神龙MOC卡,将大部分虚拟机管理工作、网络中断处理等从CPU offload到MOC卡进行处理。神龙MOC卡是一块PCI-E 3.0设备,其内有专门设计的用于网络处理的FPGA芯片,以及2颗低功耗的x86处理器(据传是Intel Atom),最大限度的接手Host操作系统的虚拟化管理工作。通过这样的设计,在网络转发性能上甚至能做到10倍于裸物理机,做到了当之无愧的裸金属。104核的物理机可以直接虚拟出一台104核的超大ECS,再也不用保留几个核心给Host操作系统使用了。
1.2 VPC
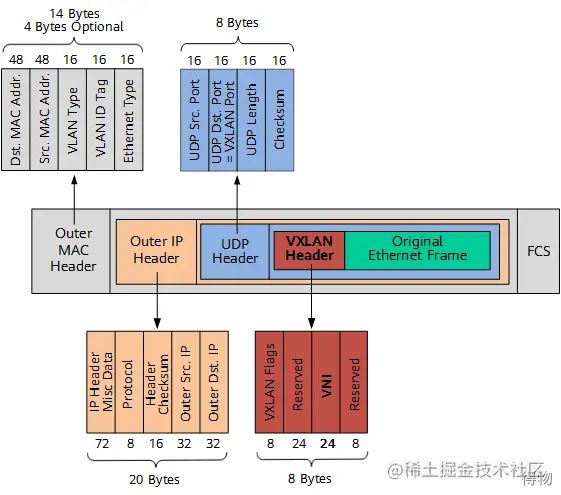
VPC(虚拟专有云,Virtual Private Cloud),大多数云上的用户都希望自己的网络与其它的客户隔离,就像自建机房一样,这里面最重要的是网络虚拟化技术,目前阿里云采用的是VxLAN协议,它底层采用UDP协议进行数据传输,整体数据包结构如下图所示。VxLAN在VxLAN帧头中引入了类似VLAN ID的网络标识,称为VxLAN网络标识VNI(VxLAN Network ID),由24比特组成,理论上可支持多达16M的VxLAN段,从而满足了大规模不同网络之间的标识、隔离需求。这一层的引入将会使原始的网络包增加50 Bytes的固定长度的头。当然,还需要与之匹配的交换机、路由器、网关等等。
1.3 容器技术
虚拟化技术的极致优化虽然已经极大解决了VM层虚拟化的额外开销问题,但VM操作系统层的开销是无法避免的,同时如今的Java应用大多都可以做到单进程部署,VM操作系统这一层的开销显得有一些浪费(当前,它换来了极强的隔离性和安全性)。容器技术构建于操作系统的支持,目前主要使用Linux操作系统,容器最有名的是Docker,它是基于Linux 的 cgroup 技术构建的。VM的体验实在是太好了,所以容器的终极目标就是具备VM的体验的同时还没有VM操作系统层的开销。在容器里,执行top、free等命令时,我们只希望看到容器视图,同时网络也是容器视图,不得不排查问题需要抓包时可以仅抓容器网络的包。
目前阿里云ECS 16GB内存的机型,实际上操作系统内看到的可用内存只有15GB,32GB的机型则只有30.75GB。容器没有这个问题,因为实际上在容器上运行的任务仅仅是操作系统上的一个或多个进程而已。由于容器的这种逻辑隔离特性,所以不同企业的应用基本上是不太可能部署到同一个操作系统上的(即同一台ECS)。
容器最影响性能的点是容器是否超卖、是否绑核、核分配的策略等等,以及前述的众多知识点都会对性能有不小的影响。
通常企业核心应用都会要求绑核(即容器的多个vCPU的分布位置是确定以及专用的,同时还得考虑Intel HT、AMD CCD/CCX、NUMA等问题),这样性能的确定性才可以得到保证。
在Docker与VM之间,其实还存在别的更均衡的容器技术,大多数公司称之为安全容器,它采用了硬件虚拟化来实现强隔离,但并不需要一个很重的VM操作系统(比如 Linux),取而代之的是一个非常轻的微内核(它仅支持实现容器所必须的部分内核功能,同时大多数工作会转发给Host操作系统处理)。这个技术是云厂商很想要的,这是他们售卖可靠FaaS(功能即服务,Function as a Service)的基础。
\
2. 获取性能数据
进行性能优化前,我们需要做的是收集到足够、准确以及有代表性的性能数据,分析性能瓶颈,然后才能进行有效的优化。
评估一个应用的性能无疑是一件非常复杂的事,大多数情况下一个应用会有很多个接口,且同一个接品会因为入参的不同或者内部业务逻辑的不同带来非常大的执行逻辑的变化,所以我们得首先想清楚,我们到底是要优化什么业务场景下的性能(对于订单来说,也许就是下单)。
在性能测试用例跑起来后,怎么样拿到我们想要的真实的性能数据就很关键了,因为观测者效应的存在(指“观测”这种行为对被观测对象造成一定影响的效应,它在生活中极其常见),获取性能数据的同时也会对被测应用产生或多或少的影响,所以我们需要深入的了解我们所使用的性能数据获取工具的工作原理。具体到Java上(其它语言也基本是类似的),我们想知道一个应用到底在做什么,主要有两种手段:
- Instrumentation(代码嵌入):指的是可以用独立于应用程序之外的代理(Agent)程序来监测运行在JVM上的应用程序,包括但不限于获取JVM运行时状态,替换和修改类定义等。通俗点理解就是在函数的执行前后插代码,统计函数执行的耗时。了解基本原理后,我们大概会知道,这种方式对性能的影响是比较大的,函数越简短执行的次数越多影响也会越大,不同它的好处也是显而易见的:可以统计出函数的执行次数以及不漏过任何一个细节。这种方式一般用于应用早期的优化分析。
- Sampling(采样):采用固定的频率打断程序的执行,然后拉取各线程的执行栈进行统计分析。采样频率的大小决定了观测结果的最小粒度和误差,一些执行次数较多的小函数可能会被统计的偏多,一些执行次数较少的小函数可能不会被统计到。主流的操作系统都会从内核层进行支持,所以这种方式对应用的性能影响相对较少(具体多少和采样频率强相关)。
在性能数据里,时间也是一个非常重要的指标,主要有两类:
- CPU Time(CPU时间):占用的CPU时间片的总和。这个时间主要用来分析高CPU消耗。
- Wall Time(墙上时间):真实流逝的时间。除了CPU消耗,还有资源等待的时间等等,这个时间主要用来分析rt(响应时间,Response time)。
性能数据获取方式+时间指标一共有四种组合方式,每一种都有它们的最适用的场景。不过需要记住,Java应用通常都需要至少5分钟(这是一个经验值,通常Server模式的JVM需要在方法执行5000~10000次后才会进行JIT编译)的大流量持续测试才能使应用的性能达到稳定状态,所以除非你要分析的是应用正在预热时的性能,否则你需要等待5分钟以上再开始收集性能数据。
Linux系统上面也有不少非常好用的性能监控工具,如下图:

\
2.1 构造性能测试用例
通常我们都会分析一个或多个典型业务场景的性能,而不仅仅是某一个或多个API接口。比如对于双11大促,我们要分析的是导购、交易、发优惠券等业务场景的性能。
好的性能测试用例的需要能够反映典型的用户和系统行为(并不是所有的。我们无法做到100%反映真实用户场景,只能逐渐接近它),比如一次下单平均购买多少个商品(实际的用例里会细分为:购买一个商品的占比多少,二个商品的占比多少,等等)、热点售买商品的数量与成交占比、用户数、商品数、热点库存分布、买家人均有多少张券等等。像淘宝的双11的压测用例,像这样关键的参数会多达200多个。
实际执行时,我们期望测试用例是可以稳定持续的运行的(比如不会跑30分钟下单发现库存没了,优惠券也没了),缓存的命中率、DB流量等等的外部依赖也可以达到一个稳定状态,在秒级时间(一般不需要更细了)粒度上应用的性能也是稳定的(即请求的计算复杂度在时间粒度上是均匀分布的,不会一会高一会低的来回抖动)。
为了配合性能测试用例的执行,有的时候还需要应用系统做一些相应的改造。比如对于会使用到缓存的场景来说,刚开始命中率肯定是不高的,但跑了一会儿过后就会慢慢的变为100%,这显然不是通常真实的情况,所以可能会配合写一些逻辑,来让缓存命中率一直维持在某个特定值上。
综上,一套好的性能测试用例是开展后续工作所必不可少的,值得我们在它上面花时间。
2.2 真实的测试环境
保持测试环境与其实环境的一致性是极其重要的,但是往往也是很难做到的,所以大多数互联网公司的全链路压测方案都是直接使用线上环境来做性能测试。如果我们无法做到使用线上环境来做性能测试,那么就需要花上不少的精力来仔细对比我们所使用的环境与线上环境的差异,确保我们知道哪一些性能数据是可以值得相信的。
直接使用线上环境来做性能测试也并不是那么简单,这需要我们有一套整体解决方案来让压测流量与真实流量进行区分,一般都是在流量中加一个压测标进行全链路的透传。同时基本上所有的基础组件都需要进行改造来支持压测,主要有:
- DB:为业务表建立对应的压测表来存储压测数据。不使用增加字段做逻辑隔离的原因是容易把它们与正式数据搞混,同时也不便于单独清理压测数据。不使用新建压测库的原因是:一方面它违背了我们使用线上环境做性能压测的基本考虑,另一方面也会导致应用端多了一倍的数据库连接。
- 缓存:为缓存Key增加特殊的前缀,如__yt_。缓存大多数没有表的概念,看起来就是一个巨大的Map存储一样,所以除了加固定前缀并没有太好的办法。不过为了减少压测数据的存储成本,通常需要:1) 在缓存client包中做一些处理来减少压测数据的缓存过期时间;2)缓存控制台提供专门清理压测数据的功能。
- 消息:在发送、消费时透传压测标。尽量做到不需要业务团队的开发同学感知,在消息的内部结构中增加是否是压测数据的标记,不需要业务团队申请新的压测专用的Topic之类。
- RPC:透传压测标。当然,HTTP、DUBBO等具体的RPC接口透传的方案会是不同的。
- 缓存、数据库 client包:根据压测标做请求的路由。这需要配合前面提到的具体缓存、DB的具体实现方案。
- 异步线程池:透传压测标。为了减少支持压测的改造代价,通常都会使用ThreadLocal来存储压测标,所以当使用到异步线程池的时候,需要记得带上它。
- 应用内缓存:做好压测数据与正式数据的隔离。如果压测数据的主键或者其它的唯一标识符可以让我们显著的让它与正式数据区分开来,也许不用做太多,否则我们也许需要考虑要么再new一套缓存、要么为压测数据加上一个什么特别的前缀。
- 自建任务:透传压测标。需要我们自行做一些与前述提到的消息组件类似的事情,毕竟任务和消息从技术上来说是很像很像的。
- 二方、三方接口:具体分析与解决。需要看二方、三方接口是否支持压测,如果支持那么很好,我们按照对方期望的方式进行参数的传递即可,如果不支持,那么我们需要想一些别的奇技婬巧(比如开设一个压测专用的商户、账户之类)了。
为了降低性能测试对用户的影响,通常都会选择流量低峰时进行,一般都是半夜。当然,如果我们能有一套相对独立的折中方案,比如使用小得物环境、在支持单元化的系统中使用部分单元等等,就可以做到在任何时候进行性能测试,实现性能测试的常态化。
2.3 JProfiler的使用
JProfiler是一款非常成熟的产品,很贵很好用,它是专门为Java应用的性能分析所准备的,而且是跨平台的产品,是我经常使用的工具。它的大体的架构如下图所示,Linux agent加上Windows UI是最推荐的使用方式,它不但同时支持Instrumentation & Sampling,CPU Time & Wall Time的选项,而且还拥有非常易用的图形界面。

分析时,我们只需要将其agent包上传到应用中的某个目录中(如:/opt/jprofiler11.1.2),然后添加JVM的启动选项来加载它,我通常都这样配置:
-agentpath:/opt/jprofiler11.1.2/bin/linux-x64/libjprofilerti.so=port=8849
复制代码接下来我们重启应用,这里的修改就会生效了。使用这个配置,Java进程在开始启动时需要等待JProfiler UI的连接才会继续启动,这样我们可以进行应用启动时性能的分析了。
JProfiler的功能很多,就不一一介绍了,大家可以阅读其官方文档。采集的性能数据还可以保存为*.jps文件,方便后续的分析与交流。其典型的分析界面如下图所示:

JProfiler的一些缺点:
1)需要在Java应用启动加载agent(当然它也有启动后attach的方式,但是有不少的限制),不太便于短时间的分析一些紧急的性能问题;
2)对Java应用的性能影响偏大。使用采样的方式来采集性能数据开销肯定会低很多,但还是没有接下来要介绍的perf做的更好。
2.4 perf的使用
perf是Linux上面当之无愧的性能分析工具的一哥,这一点需要特别强调一下。不但可以用来分析Linux用户态应用的性能,甚至还常用来分析内核的性能。它的模块结构如下图所示:

想像一下这样的场景,如果我们换了一家云厂商,或者云厂商的服务器硬件(主要就是CPU了)有了更新迭代,我们想知道具体性能变化的原因,有什么办法吗?perf就能很好的胜任这个工作。
CPU的设计者为了帮助我们分析应用执行时的性能,专门设计了相关的硬件电路,PMU(性能监控单元,Performance Monitor Unit)就是这其中最重要的部分。简单来说里面包含了很多性能计数器(图中的PMCs,Performance Monitor Counters),perf可以读取这些数据。不仅如此,内核层面还提供了很多软件级别的计数器,perf同样可以读取它们。一些和CPU架构相关的关键指标,可以了解一下:
- IPC(每周期执行指令条数,Instruction per cycle):基于功耗/性能的考虑,大多数服务器处理器的频率都在2.5~2.8GHz的范围,这代表同一时间片内的周期数是差异不大的,所以单个周期能够执行的指令条数越多说明我们的应用优化的越好。过多的跳转指令(即if else这类代码)、浮点计算、内存随机访问等操作显然是非常影响IPC的。有的人比较喜欢说CPI(Cycle per instruction),它是IPC的倒数。
- LLC Cache Miss(最后一级缓存丢失):偏内存型的应用需要关注这个指标,过大的话代表我们没有利用好处理器或操作系统的缓存预加载机制。
- Branch Misses(预测错误的分支指令数):这个值过高代表了我们的分支类代码设计的不够友好,应该做一些调整尽量满足处理器的分支预测算法的期望。如果我们的分支逻辑依赖于数据的话,做一些数据的调整一样可以提高性能(比如这个经典案例:数据有100万个元素,值在0-255之间,需要统计值小于128的元素个数。提前对数组排序再进行for循环判断会运行的更快)。
因为perf是为Linux上的原生应用准备的,所以直接使用它分析Java应用程序的话,它只会把Java程序当成一个普通的C++程序来看待,不能显示出Java的调用栈和符号信息。好消息是perf-map-agent插件项目解决了这个问题,这个插件可以导出Java的符号信息并帮助perf进行Java线程的栈回溯,这样我们就可以使用perf来分析Java应用程序的性能了。执行 perf top -p

perf仅支持采样 + CPU Time的工作模式,不过它的性能非常好,进行普通的Java性能分析任务时通常只会引入5%以内的额外开销。使用环境变量PERF_RECORD_FREQ来设置采样频率,推荐值是999。不过如你所见,它是标准的Linux命令行式的交互行为,不是那么方便。同时虽然他是可以把性能数据录制为文件供后续继续分析的,但要记得同时保存Java进程的符号文件,不然你就无法查看Java的调用栈信息了。虽然限制不少,但是perf却是最适合用来即时分析线上性能问题的工具,不需要任何前期的准备,随时可用,同时对线上性能的影响也很小,可以很快的找到性能瓶颈点。在安装好perf(需要sudo权限)以及perf-map-agent插件后,通常使用如下的命令来打开它:
export PERF_RECORD_SECONDS=5 && export PERF_RECORD_FREQ=999
./perf-java-report-stack
复制代码 重点需要介绍的信息就是这么多,实践过程中需要用好perf的话需要再查阅相关的一些文档。
2.5 内核态与用户态
对操作系统有了解的同学会经常听到这两个词,也都知道经常在内核态与用户态之间交互是非常影响性能的。从执行层面来说,它是处理器的设计者设计出来构建如今稳定的操作系统的基础。有了它,用户态(x86上面是ring3)进程无法执行特权指令与访问内核内存。大多数时候为了安全,内核也不能把某部分内核内存直接映射到用户态上,所以在进行内核调用时,需要先将那部分参数写入到特定的传参位置,然后内核再从这里把它想要的内容复制走,所以多会一次内存的复制开销。你看到了,内核为了安全,总是小心翼翼的面对每一次的请求。
在Linux上,TCP协议支持是在内核态实现的,曾经这有很多充分的理由,但内核上的更新迭代速度肯定是慢于如今互联网行业的要求的,所以QUIC(Quick UDP Internet Connection,谷歌制定的一种基于UDP的低时延的互联网传输层协议)诞生了。如今主流的发展思路是能不用内核就不用内核,尽量都在用户态实现一切。
有一个例外,就是抢占式的线程调度在用户态做不到,因为实现它需要的定时时钟中断只能在内核态设置和处理。协程技术一直是重IO型Java应用减少内核调度开销的极好的技术,但是很遗憾它需要执行线程主动让出剩余时间片,不然与内核线程关联的多个用户态线程就可能会饿死。阿里巴巴的Dragonwell版JVM还尝试了动态调整策略(即用户态线程不与固定的内核态线程关联,在需要时可以切换),不过由于前述的时钟中断的限制,也不能工作的很好。
包括如今的虚拟化技术,尤其是SR-IOV技术,只需要内核参与接口分配/回收的工作,中间的通信部分完全是在用户态完成的,不需要内核参与。所以,如果你发现你的应用程序在内核态上耗费了太多的时间,需要想一想是否可以让它们在用户态完成。
2.6 JVM关键指标
JVM的指标很多,但有几个关键的指标需要大家经常关注。
- GC次数与时间:包括Young GC、Full GC、Concurrent GC等等,Young GC频率过高往往代表过多临时对象的产生。
- Java堆大小:包括整个Java堆的大小(由Xmx、Xms两个参数控制),年轻代、老年代分别的大小。不同时指定Xms和Xmx很可能会让你的Java进程一直使用很小的堆空间,过大的老年代空间大多数时候也意味着内存的浪费(多分配一些给年轻代将显著降低Young GC频率)。
- 线程数:通常我们采用的都是4C8G(4Core vCPU,8GB内存)、8C16G的机型,分配出上千个线程大多数时候都是错误的。
- Metaspace大小和使用率:不要让JVM动态的扩展元空间的大小,尽量通过设置MetaspaceSize、MaxMetaspaceSize让它固定住。我们需要知道我们的应用到底需要多少元空间,过多的元空间占用以及过快的增长都意味着我们可能错误的使用了动态代理或脚本语言。
- CodeCache大小和使用率:同样的,不要让JVM动态的扩展代码缓存的大小,尽量通过设置InitialCodeCacheSize、ReservedCodeCacheSize让它固定住。我们可以通过它的变化来发现最近是不是又引入了新的类库。
- 堆外内存大小:限制最大堆外内存的大小,计算好JVM各块内存的大小,不要给操作系统触发OOM Killer的机会。
2.7 了解JIT
字节码的解释执行肯定是相当慢的,Java之所以这么流行和他拥有高性能的JIT(即时,Just in time)编译器也有很大的关系。但编译过程本身也是相当消耗性能的,且由于Java的动态特性,也很难做到像C/C++这样的编程语言提前编译为native code再执行,这导致Java应用的启动是相当慢的(大多数都需要3分钟以上,Windows操作系统的启动都不需要这么久),而且同一个应用的多台机器之间并不能共享JIT的经验(这显然是极大的浪费)。
我们使用的JVM都采用分层编译的策略,根据优化的程度不同从低到高分别是C1、C2、C3、C4,C4是最快的。JIT编译器会收集不少运行时的数据,来指导它的编译策略,核心假设是可以逐步收集信息、仅编译热点方法和路径。但是这个假设并不总是对的,比如对于双11大促的场景来说,我们的流量是到点突然垂直增加的,以及部分代码分支在某个时间点之前并不会运行(比如某种优惠要零点过后才会生效可用)。
2.7.1 编译
极热的函数通常JIT编译器会函数进行内联(inlining)优化,就相当于直接把代码抄写到调用它的地方来减少一次函数调用的开销,但是如果函数体过大的话(具体要看JVM的实现,通常是几百字节)将不能内联,这也是为什么编程规范里面通常都会说不要将一个函数写的过大的原因。
JVM并不会对所有执行过的方法都进行JIT优化,通常需要5000~10000次的执行后才进行,而且它还仅仅编译那些曾经执行过的分支(以减少编译所需要的时间和Code Cache的占用,优化CPU的执行性能)。所以在写代码的时候,if代码后面紧跟的代码块最好是较大概率会执行到的,同时尽量让代码执行流比较固定。
阿里巴巴的Dragonwell版JVM新增了一些功能,可以让JVM在运行时记录编译了哪些方法,再把它们写入文件中(还可以分发给应用集群中别的机器),下次JVM启动时可以利用这部分信息,在第一次运行这些方法时就触发JIT编译,而不是在执行上千次以后,这会极大的提升应用启动的速度以及启动时CPU的消耗。不过动态AOP(Aspect Oriented Programming)代码以及lambda代码将不能享受这个红利,因为它们运行时实际生成的函数名都是形如MethodAccessor$1586 这类以数字结尾的不稳定的名称,这次是1586,下一次就不知道什么了。
2.7.2 退优化
JIT编译器的激进优化并不总是对的,如果它发现目前需要的执行流在以前的编译中被省略了的话,它就会进行退优化,即重新提交该方法的编译请求。在新的编译请求完成之前,该方法很大可能是进行解释执行(如果存在还未丢弃的低阶编译代码,比如C1,那么就会执行C1的代码),加上编译线程的开销,这会导致短时间内应用性能的下降。在双11大促这种场景下,也就是零点的高峰时刻,由于退优化的发生,导致应用的性能比压测时有相当显著的降低。
阿里巴巴的Dragonwell版JVM在这一块也提供了一些选项,可以在JIT编译时去除一些激进优化,以防止退优化的发生。当然,这会导致应用的性能有微弱的下降。
2.8 真实案例
在性能优化的实践过程中,有一句话需要反复深刻的理解:通过数据反映一切,而不是听说或者经验。
下面列举一个在重构项目中进行优化的应用的性能比较数据,以展示如何利用我们前面说到的知识。这个应用是偏末端的应用,下游基本不再依赖其它应用。特别说明,【此案例非得物案例】,也不对应任何一个真实的案例。
应用容器:8C32G,Intel 8269CY处理器,8个处理器绑定到4个物理核的8个HT上。
老应用:12.177.126.52,12.177.126.141
新应用:12.177.128.150, 12.177.128.28
测试接口与流量
| 确认订单优惠渲染 单机@1012QPS |
|---|
| 下单确认优惠 单机@330QPS |
| 下单核销优惠 单机@416QPS |
时间:2021-05-03
基础数据
| 项目\数据 | 老应用(收集时间 21:00) | 新应用(收集时间 21:15) |
|---|---|---|
| CPU | 43.44%(user:36.78%) | 45.04%(user:40.52%) |
| RT: 确认订单优惠渲染 | 5.2ms | 6.1ms |
| RT: 下单确认优惠 | 7.5ms | 4.7ms |
| RT: 下单核销优惠 | 1.0ms | 1.3ms |
| GC频次 | 18.5 | 25 |
| Net | In:11.4M Out:13.7M | In:7.3M Out:12.4M |
| Thread | 669(Daemon:554) | 789(Daemon:664) |
| 每分钟Java Exception | 5132 | 7324 |
缓存访问
| 操作\QPS | 老应用 | 新应用 | 用途 |
|---|---|---|---|
| GET:9 | 3550 | 3825 | 商品缓存 |
| GET:860 | 4848 | — | 券规则缓存 |
| GET:758 | 1165 | 1365 | 卖家缓存 |
| GET:8 | 1158 | 1280 | 卖家全局规则缓存 |
| PREFIX_GETS:688 | 1425 | — | 活动索引(新应用废弃) |
| GET:688 | 2282 | — | 活动索引(新应用废弃) |
| GET:100 | 21 | 21 | 店铺免息优惠缓存 |
| PREFIX_GETS:100 | — | 73 | 店铺免息优惠缓存 |
| GET:4 | — | 1008 | 店铺某类优惠缓存 |
| GET:10086 | 2394 | 2580 | 卡券领取关系缓存 |
| GET:770 | 100 | — | SKU优惠缓存 |
| PREFIX_GETS:770 | 92 | — | SKU优惠缓存 |
| GET:88 | 21 | 21 | 商品限购缓存 |
DB访问
| 库表\QPS | 老应用 | 新应用 | 用途 |
|---|---|---|---|
| QUERY promotion_detail | 865 | — | 优惠活动 |
| KV_GET promotion_detail | — | 898 | |
| QUERY promotion_detail_sku | 21 | SKU优惠活动 | |
| QUERY buyer_coupon | 190 | 160 | 优惠券 |
| KV_GET buyer_coupon | -- | 56 | |
| UPDATE buyer_coupon | 55 | 60 | 优惠券 |
2.8.1 初步发现
- 通过外部依赖的差异可以发现,新老应用的代码逻辑会有不同,需要继续深入评估差异是什么。通常在做收集性能数据的同时,我们需要有一个简单的分析和判断,首先确保业务逻辑的正确性,不然性能数据就没有多少意义。
- Java Exception是很消耗性能的,主要消耗在收集异常栈信息,新老应用较大的异常数区别需要找到原因并解决。
- 新应用的接口“下单确认优惠”RT有过于明显的下降,其它接口都是提升的,说明很可能存在执行路径上较大的差别,也需要深入的分析。
3. 开始做性能优化
和获取性能数据需要从底层逐步了解到上层业务不同,做性能优化却是从上层业务开始,逐步推进到底层,即从高到低进行分层优化。越高层的优化往往难度更低,而且收益还越大,只是需要与业务的深度结合。越低层的优化往往难度比较大,很难获得较大的收益(毕竟一堆技术精英一直在做着呢),但是通用性比较好,往往可以适用于多类业务场景。接下来分别聊一聊每一层可以思考的一些方向和实际的例子。
3.1 优化的目的与原则
在聊具体的优化措施之前,我们先聊一聊为什么要做性能优化。多数情况下,性能优化的目的都是为了成本、效率与稳定。达到同样的业务效果,使用更少的资源,或者带来更好的用户体验(通常是指页面的响应更快)。不怎么考虑成本的技术方案往往没有太多的挑战,对于电商平台来说,我们常常用单订单成本来衡量机器成本,比如淘宝这个值可能在0.17元左右。业务发展的早期往往并不是那么在意成本,反而更加看重效率,等到逐步成熟起来过后,会慢慢的开始重视成本,通俗的讲就是开始比的是有没有,然后比的是好不好。所以在不同的时期,我们进行性能优化的目的和方向会有所侧重。
互联网行业是一个快速发展的行业,研发效率对业务的健康发展是至关重要的,在进行优化的过程中,我们在技术方案的选择上需要兼顾研发效率的提升(至少不能损害过多),给人一种“它本来应该就是这样”的感觉,而不是做一些明显无法长期持续、后期维护成本过高的设计。好的优化方案就像艺术品一样,每一个看到的人都会为之赞叹。
3.2 业务
大家为什么会在双11的零点开始上各大电商网站买东西?春节前大家为什么都在上午10点抢火车票?等等,其实都是业务上的设计。准备一大波机器资源使用2个月就为了双11峰值的那几分钟,实际上是极大的成本浪费,所以为了不那么浪费,淘宝的双11预售付尾款的时间通常都放在凌晨1点。12306早几年是每临进春节必挂,因为想要回家的游子实在是太多,所以后面慢慢按照车次将售卖时间打散,参考其公告:
自今年1月8日起,为避免大量旅客在互联网排队购票,把原来的8点、10点、12点、15点四个时间节点放票改为15个节点放票,即:8点-18点,其间每小时或每半小时均有部分新票起售。
复制代码这些策略都可以极大的降低系统的峰值流量,同时对于用户使用体验来说基本是无感的,诸如此类的许多优化是我们最开始就要去思考的(不过请记住永远要把业务效果放在第一位,和业务讲业务,而不是和业务讲技术)。
3.3 系统架构
诸如商品详情页动静分离(静态页面与动态页面分开不同系统访问),用户接口层(即HTTP/S层)与后端(Java层)合并部署等等,都是架构优化的成功典范。业务架构师往往会将系统设计为很多层,但是在运行时,他们往往可以部署在一块儿,以减少跨进程、跨机器、跨地域通信。
淘宝的单元化架构在性能上来看也是一个很好的设计,一个交易请求几乎所有的处理都可以封闭在单元内完成,减少了很多跨地域的网络长传带宽需求。
富客户端方案对于像商品信息、用户信息等基础数据来说也是很好的方案,毕竟大多数情况下它们都是访问Redis等缓存,多一次到服务端的RPC请求总是显得很多余,当然,后续需要升级数据结构的时候则需要做更多的工作。
关于架构的讨论是永恒的话题,同时不同的公司有不同的背景,实际进行优化时也需要根据实际情况来取舍。
3.4 调用链路
在分布式系统里不可避免需要依赖很多下游服务才能完成业务动作,怎么依赖、依赖什么接口、依赖多少次则是需要深入思考的问题。借助调用链查看工具(在得物,这个工具应该是dependency),我们可以仔细分析每一个业务请求,然后去思考它是不是最优的方式。举一个我听说过的例子(特别说明,【此案例非得物案例】):
背景:营销团队接到了一个拉新的需求,它会在公司周年庆的10:00形成爆点,预计会产生最高30万的UV,然后只需要点击活动页的参与按钮(预估转化率是75%),就会弹出一个组团页,让用户邀请他的好友参与组团,每多邀请一个朋友,在团内的用户都可以享受更多的优惠折扣。
营销团队为组团页提供了一个新的后台接口,最开始这个接口需要完成这些事:

在“为用户创建一个新团”这一步,会同时将新团的信息持久化到数据库中,按照业务的转化率预估,这会有30W*75%=22.5W QPS的峰值流量,基本上我们需要10个左右的数据库实例才能支撑这么高的并发写入。但这是必要的吗?显然不是,我们都知道这类需要用户转发的活动的转化率是有多么的低(大多数不到8%),同时对于那些没人参与的团,将它们的信息保存在数据库中也是意义不大的。最后的优化方案是:1)在“为用户创建一个新团”时,仅将团信息写入Redis缓存中;2)在用户邀请的朋友同意参团时,再将团信息持久化到数据库中。新的设计,仅仅需要1.8W QPS的数据库并发写入量,使用原有的单个数据库实例就可以支撑,在业务效果上也没有任何区别。
除了上述的例子,链路优化还有非常多的方法,比如多次调用的合并、仅在必要时才调用(类似COW [Copy on write]思想)等等,需要大家结合具体的场景去分析设计。
3.5 应用代码
应用代码的优化往往是我们最热衷和擅长的,毕竟业务与系统架构的优化往往需要架构师出马。JProfiler或者perf的剖析(Profiling)数据是非常有用的参考,任何不基于实际运行数据的猜测往往会让我们误入歧途,接下来我们需要做的大多数时候都是“找热点 -> 优化” ,然后“找热点 -> 优化”,然后一直循环。找热点不是那么难,难在准确的分析代码的逻辑然后判断到底它应该消耗多少资源(通常都是CPU),然后制定优化方案来达到目标,这需要相当多的优化经验。从我做过的性能优化来总结,大概主要的问题都发生在这些地方:
- 和字符串过不去:非常多的代码喜欢将多个Java变量使用StringBuilder拼接起来(那些连StringBuilder都不会用,只会使用 + 的家伙就更让人头疼了),然后再找准时机spilt成多个String,然后再转换成别的类型(Long等)。好吧,下次使用StringBuilder时记得指定初始的容量大小。
- 日志满天飞:管它有用没有,反正打了是不会错的,毕竟谁都经历过没有日志时排查问题的痛苦。怎么说呢,打印有用的、有效的日志是程序员的必修课。
- 喜爱Exception:不知道是不是某些Java的追随者吹过头了,说什么Java的Exception和C/C++的错误码一样高效。然而事实并不是这样的,Exception进行调用栈的回溯是相当消耗性能的,尤其是还需要将它们打印在日志中的时候,会更加糟糕。
- 容器的深拷贝:List、HashMap等是大家非常喜欢的Java容器,但Java语言并没有好的机制阻止别人修改它,所以大家常常深拷贝一个新的出来,反正也就是一句代码的事儿。
- 对JSON情有独钟:将对象序列化为JSON string,将JSON string反序列化为对象。前者主要用来打日志,后者主要用来读配置。JSON是挺好,只是请别用的到处都是(还把每个属性的名字都取的老长)。
- 重复重复再重复:一个请求里查询同样的商品3次,查询同样的用户2次,查询同样的缓存5次,都是常有的事,也许多查询几次一致性更好吧 :(。还有一些基本不会变的配置,也会放到缓存中,每次使用的时候都会从缓存中读出来,反序列化,然后再使用,嗯,挺重的。
- 多线程的乐趣:不会写多线程程序的开发不是好开发,所以大家都喜欢new线程池,然后异步套异步。在流量很低的时候,看起来多线程的确解决了问题(比如RT的确变小了),但是流量上来过后,问题反而恶化了(毕竟我们主流的机器都是8核的)。
再重申一遍,在这一步,找到问题并不是太困难,找到好的优化方案却是很困难和充满考验的。
3.6 缓存
大多数的缓存都是Key、Value的结构,选择紧凑的Key、Value以及高效的序列化、反序列化算法是重中之重(二进制序列化协议比文本序列化协议快的太多了)。还有的缓存是Prefix、Key、Value的结构,主要的区别是谁来决定实际的数据路由到哪台服务器进行处理。单条缓存不能太大,基本上大于64KB就需要小心了,因为它总是由某一台实际的服务器在处理,很容易将出口宽带或计算性能打满。
3.7 DB
数据库比起缓存来说他能抗的流量就低太多了,基本上是差一个数量级。SQL通信协议虽然很易用,但实际上是非常低效的通信协议。关于DB的优化,通常都是从减少写入量、减少读取量、减少交互次数、进行批处理等等方面着手。DB的优化是一门复杂的学问,很难用一篇文章说清楚,这里仅举一些我认为比较有代表性的例子:
- 使用MultiQuery减少网络交互:MySQL等数据库都支持将多条SQL语言写到一起,一起发送给DB服务器,这会将多次网络交互减少为一次。
- 使用BatchInsert代替多次insert:这个很常见。
- 使用KV协议取代SQL:阿里云数据库团队在数据库服务器上面外挂了一个KV引擎,可以直接读取InnoDB引擎中的数据,bypass掉了数据库的数据层,使得基于唯一键的查询可以比使用SQL快10倍。
- 与业务结合:淘宝下单时可以同时使用多达10个红包,这意味着一次下单需要发送至多10次update SQL。假设一次下单使用了N个红包,基于对业务行为的分析,会发现前N-1个都是全额使用的,最后一个可能会部分使用。对于使用完的红包,我们可以使用一条SQL就完成更新。
update red_envelop set balance = 0 where id in (...);
复制代码- 热点优化:库存的热点问题是每个电商平台都面临的问题,使用数据库来扣减库存肯定是可靠性最高的方案,但是基本上都很难突破500tps的瓶颈。阿里云数据库团队设计了新的SQL hint,配合上第1条说的MultiQuery技术,与数据库进行一次交互就可以完成库存的扣减。同时加上数据库内核的针对性优化,已经可以实现8W tps的热点扣减能力。下表中的commit_on_success用来表明,如果update执行成功就立即提交,这样可以让库存热点行的锁占用时间降到最低。target_affect_row(1)以及rollback_on_fail用来限制当库存售罄时(即inv_count - 1 >= 0不成立)update执行失败并回滚整个事务(即前面插入的库存流水作废)。
insert 库存扣减流水;
update /* commit_on_success rollback_on_fail target_affect_row(1) */ inventory
set inv_count = inv_count - 1
where inv_id = 11222 and inv_count - 1 >= 0;
复制代码3.8 运行环境
我们的代码是运行在某个环境中的,这个环境有很多知识是我们需要了解的,如果上面所有的优化完成后还不能满足要求,那么我们也不得不向下深入。这可能是一个困难的过程,但也会是一个有趣的过程,因为你终于有了和各领域的大佬们交流讨论的机会。
3.8.1 中间件
目前大多数中间件的代码是和我们的业务代码运行在一起的,比如监控采集、消息client、RPC client、配置推送 client、DB连接组件等等。如果你发现这些组件的性能问题,那么可以大胆的提出来,不要害怕伤害到谁 :)。
我遇到过这样的一些场景:
- 应用偶尔会大量的发生ygc:排查到的原因是,在我们依赖的服务发生地址列表变化(比如发生了重启、掉线、扩容等场景)时,RPC client会接收到大量的推送,然后解析这些推送的信息,然后再更新一大堆内存结构。提出的优化建议是:1)地址推送从全量推送改变为增量推送;2)地址列表从挂接到服务接口维度更改为挂接到应用维度。
- DB连接组件过多的字符串拼接:DB连接组件需要进行SQL的解析来计算分库分表等信息,但实现上面不够优雅,拼接的字符串过多了,导致执行SQL时内存消耗过多。
3.8.2 容器
关于容器技术本身大多数时候我们做不了什么,往往就是尽量采用最新的技术(比如使用阿里云的神龙服务器什么的),不过在梆核(即容器调度)方面往往可以做不少事。我们的应用和谁运行在一起、相互之间有资源争抢吗、有没有跨NUMA调度、有没有资源超卖等等问题需要我们关注(当然,这需要容器团队提供相应的查看工具)。这里主要有两个需要考虑的点:
- 是不是支持离在线混部:在线任务要求实时响应,而离线任务的运行又需要耗费非常多的机器。在双11大促这样的场景,把离线机器借过来用几个小时就可以减少相应的在线机器采购,能省下很多钱。
- 基于业务的调度:把高消耗的应用和低消耗的应用部署在一起,同时如果双方的峰值时刻还不完全相同,那就太美妙啦。
3.8.3 JVM
为了解决重IO型应用线程过多的问题开发了协程。
为了解决Java容器过多小对象的问题(如HashMap的K, V都只能是包装类型)开发了值容器。
为了解决Java堆过大时GC时间过长的问题(当然还有觉得Java的内存管理不够灵活的原因)开发了GCIH(GC Invisible Heap,淘宝双11期间部分热点优惠活动的数据都是存在GCIH当中的)。
为了解决Java启动时的性能问题(即代码要跑好几千次才进行JIT,而且每次启动都还要重复这个过程)开发了启动Hint功能。
为了解决业务峰值时刻JIT退优化的问题(即平时不使用的代码执行路径在业务峰值时候需要使用,比如0点才生效的优惠)开发了JIT编译激进优化去除选项。
虽然目前JVM的实现就是你知道的那样,但是并不代表这样做就一直是合理的。
3.8.4 操作系统
基本上我们都是使用Linux操作系统,新版本的内核通常会带来一些新功能和性能的提升,同时操作系统还需要为支撑容器(即Docker等)做不少事情。对Host操作系统来说,开启透明大页、配置好网卡中断CPU打散、配置好NUMA、配置好NTP(Network Time Protocol)服务、配置好时钟源(不然clock_gettime可能会很慢)等等都是必要的。还有就是需要做好各种资源的隔离,比如CPU隔离(高优先级任务优先调度、LLC隔离、超线程技术隔离等)、内存隔离(内存宽带、内存回收隔离避免全局内存回收)、网络隔离(网络宽带、数据包金银铜等级划分)、文件IO隔离(文件IO宽带的上限与下限、特定文件操作限制)等等。
大多数内核级别的优化都不是我们能做的,但我们需要知道关键的一些影响性能的内核参数,并能够理解大多数内核机制的工作原理。
3.9 硬件
通常我们都是使用Intel的x86架构的CPU,比如我们正在使用的Intel 8269CY,不过它的单颗售价得卖到4万多块人民币,却只有区区26C52T(26核52线程)。相比之下,AMD的EPYC 7763的规格就比较牛逼了(64C128T,256MB三级缓存,8通道 DDR4 3200MHz内存,拥有204GB/s的超高内存宽带),但却只要3万多一颗。当然,用AMD 2021年的产品和Intel 2019的产品对比并不是太公平,主要Intel 2021的新品Intel Xeon Platinum 8368Q处理器并不争气,仅仅只是提升到了38C76T而已(虽然和自家的上一代产品相比已经大幅提升了近50%)。
除了x86处理器,ARM 64位处理器也在向服务端产品发力,而且这个产业链还可以实现全国产化。华为2019年初发布的鲲鹏920-6426处理器,采用7nm工艺,具备64个CPU核,主频2.6GHz。虽然单核性能上其只有Intel 8269CY的近2/3,但是其CPU核数却要多上一倍还多,加上其售价亲民,同样计算能力的情况下CPU部分的成本会下降近一半(当然计算整个物理机成本的话其实下降有限)。
2020年双11开始,淘宝在江苏南通部署了支撑1万笔/s交易的国产化机房,正是采用了鲲鹏920-6426处理器,同时在2021年双11,更是用上了阿里云自主研发的倚天710处理器(也是采用ARM 64位架构)。在未来,更是有可能基于RISC-V架构设计自己的处理器。这些事实都在说明,在处理器的选择上,我们还是有不少空间的。
除了采用通用处理器,在一些特殊的计算领域,我们还可以采用专用的芯片,比如:使用GPU加速深度学习计算,在AI推理时使用神经网络加速芯片-含光NPU,以及使用FPGA芯片进行高性能的网络数据处理(阿里云神龙服务器上使用的神龙MOC卡)等等。
曾经还有人想过设计可以直接运行Java字节码的处理器,虽然最终因为复杂度太高而放弃。
这一切都说明,硬件也是一直在根据使用场景在不断的进化之中的,永远要充满想像。