来自公众号:Gopher指北
在一次性能分析中,发现线上服务CompareVersion占用了较长的CPU时间。如下图所示。
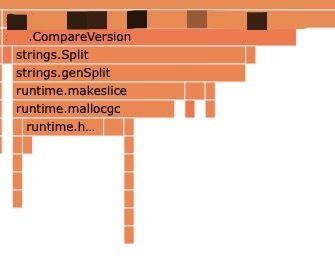
其中占用时间最长的为strings.Split函数,这个函数对Gopher来说应该是非常熟悉的。而CompareVersion就是基于strings.Split函数来实现版本比较的,下面看一下CompareVersion的实现。
// 判断是否全为0
func zeroRune(s []rune) bool {
for _, r := range s {
if r != '0' && r != '.' {
return false
}
}
return true
}
// CompareVersion 比较两个appversion的大小
// return 0 means ver1 == ver2
// return 1 means ver1 > ver2
// return -1 means ver1 < ver2
func CompareVersion(ver1, ver2 string) int {
// fast path
if ver1 == ver2 {
return 0
}
// slow path
vers1 := strings.Split(ver1, ".")
vers2 := strings.Split(ver2, ".")
var (
v1l, v2l = len(vers1), len(vers2)
i = 0
)
for ; i < v1l && i < v2l; i++ {
a, e1 := strconv.Atoi(vers1[i])
b, e2 := strconv.Atoi(vers2[i])
res := 0
// 如果不能转换为数字,使用go默认的字符串比较
if e1 != nil || e2 != nil {
res = strings.Compare(vers1[i], vers2[i])
} else {
res = a - b
}
// 根据比较结果进行返回, 如果res=0,则此部分相等
if res > 0 {
return 1
} else if res < 0 {
return -1
}
}
// 最后谁仍有剩余且不为0,则谁大
if i < v1l {
for ; i < v1l; i++ {
if !zeroRune([]rune(vers1[i])) {
return 1
}
}
} else if i < v2l {
for ; i < v2l; i++ {
if !zeroRune([]rune(vers2[i])) {
return -1
}
}
}
return 0
}尝试优化strings.Split函数
CompareVersion的逻辑清晰且简单,而根据火焰图知性能主要消耗在strings.Split函数上,所以老许的第一目标是尝试优化strings.Split函数。
每当此时老许首先想到的方法就是百度大法和谷歌大法,最后在某篇文章中发现strings.FieldsFunc函数,根据该文章描述,strings.FieldsFunc函数分割字符串的速度远快于strings.Split函数。那么我们到底能不能使用strings.FieldsFunc函数替换strings.Split函数请看下面测试结果。
func BenchmarkSplit(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
strings.Split("7.0.09.000", ".")
strings.Split("7.0.09", ".")
strings.Split("9.01", ".")
}
}
func BenchmarkFieldsFunc(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
strings.FieldsFunc("7.0.09.000", func(r rune) bool { return r == '.' })
strings.FieldsFunc("7.0.09", func(r rune) bool { return r == '.' })
strings.FieldsFunc("9.01", func(r rune) bool { return r == '.' })
}
}上述benchmark测试在老许的机器上某次运行结果如下:
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkSplit-4 3718506 303.2 ns/op 144 B/op 3 allocs/op
BenchmarkSplit-4 4144340 287.6 ns/op 144 B/op 3 allocs/op
BenchmarkSplit-4 3859644 304.5 ns/op 144 B/op 3 allocs/op
BenchmarkSplit-4 3729241 287.9 ns/op 144 B/op 3 allocs/op
BenchmarkFieldsFunc-4 3459463 336.5 ns/op 144 B/op 3 allocs/op
BenchmarkFieldsFunc-4 3604345 335.5 ns/op 144 B/op 3 allocs/op
BenchmarkFieldsFunc-4 3411564 313.9 ns/op 144 B/op 3 allocs/op
BenchmarkFieldsFunc-4 3661268 309.6 ns/op 144 B/op 3 allocs/op根据输出知,strings.FieldsFunc函数没有想象中那么快,甚至还比不过strings.Split函数。既然此路不通,老许只好再另寻他法。
尝试引入缓存
按照最卷的公司来,假如我们每周一个版本,且全年无休则一个公司要发布1000个版本需19年(1000/(365 / 7))。基于这个内卷的数据,我们如果能够把这些版本都缓存起来,然后再比较大小,其执行速度绝对有一个质的提升。
自实现过期缓存
要引入缓存的话,老许第一个想到的就是过期缓存。同时为了尽可能的轻量所以自己实现一个过期缓存无疑是一个不错的方案。
1、定义一个包含过期时间和数据的结构体
type cacheItem struct {
data interface{}
expiredAt int64
}
// IsExpired 判断缓存内容是否到期
func (c *cacheItem) IsExpired() bool {
return c.expiredAt > 0 && time.Now().Unix() >= c.expiredAt
}2、使用sync.Map作为并发安全的缓存
var (
cacheMap sync.Map
)
// Set 增加缓存
func Set(key string, val interface{}, expiredAt int64) {
cv := &cacheItem{val, expiredAt}
cacheMap.Store(key, cv)
}
// Get 得到缓存中的值
func Get(key string) (interface{}, bool) {
// 不存在缓存
cv, isExists := cacheMap.Load(key)
if !isExists {
return nil, false
}
// 缓存不正确
citem, ok := cv.(*cacheItem)
if !ok {
return nil, false
}
// 读数据时删除缓存
if citem.IsExpired() {
cacheMap.Delete(key)
return nil, false
}
// 最后返回结果
return citem.Data(), true
}3、定义一个通过.分割可存储每部分数据的结构体
// 缓存一个完整的版本使用切片即可
type cmVal struct {
iv int
sv string
// 能否转换为整形
canInt bool
}4、将app版本转为切片以方便缓存
func strs2cmVs(strs []string) []*cmVal {
cmvs := make([]*cmVal, 0, len(strs))
for _, v := range strs {
it, e := strconv.Atoi(v)
// 全部数据都保存
cmvs = append(cmvs, &cmVal{it, v, e == nil})
}
return cmvs
}5、使用带缓存的方式进行版本大小比较
func CompareVersionWithCache1(ver1, ver2 string) int {
// fast path
if ver1 == ver2 {
return 0
}
// slow path
var (
cmv1, cmv2 []*cmVal
cmv1Exists, cmv2Exists bool
expire int64 = 200 * 60
)
// read cache 1
cmv, cmvExists := Get(ver1)
if cmvExists {
cmv1, cmv1Exists = cmv.([]*cmVal)
}
if !cmv1Exists {
// set val and cache
cmv1 = strs2cmVs(strings.Split(ver1, "."))
Set(ver1, cmv1, time.Now().Unix()+expire)
}
// read cache 2
cmv, cmvExists = Get(ver2)
if cmvExists {
cmv2, cmv2Exists = cmv.([]*cmVal)
}
if !cmv2Exists {
// set val and cache
cmv2 = strs2cmVs(strings.Split(ver2, "."))
Set(ver2, cmv2, time.Now().Unix()+expire)
}
// compare ver str
var (
v1l, v2l = len(cmv1), len(cmv2)
i = 0
)
for ; i < len(cmv1) && i < len(cmv2); i++ {
res := 0
// can use int compare
if cmv1[i].canInt && cmv2[i].canInt {
res = cmv1[i].iv - cmv2[i].iv
} else {
res = strings.Compare(cmv1[i].sv, cmv2[i].sv)
}
if res > 0 {
return 1
} else if res < 0 {
return -1
}
}
if i < v1l {
for ; i < v1l; i++ {
if cmv1[i].canInt && cmv1[i].iv != 0 {
return 1
}
if !zeroRune([]rune(cmv1[i].sv)) {
return 1
}
}
} else if i < v2l {
for ; i < v2l; i++ {
for ; i < v1l; i++ {
if cmv2[i].canInt && cmv2[i].iv != 0 {
return -1
}
if !zeroRune([]rune(cmv2[i].sv)) {
return -1
}
}
}
}
return 0
}CompareVersionWithCache1函数比较步骤为:
- 如果版本字符串相等直接返回
- 分别读取两个版本对应的缓存数据,如果没有缓存数据数据则生成缓存数据并缓存
- 分别对比两个版本对应的
[]*cmVal数据,返回大小
最后进行性能验证,以下为CompareVersionWithCache1函数和CompareVersion函数的benchmark对比。
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1642657 767.6 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache1-4 1296520 844.9 ns/op 0 B/op 0 allocs/op通过上述结果分析知,使用缓存后唯一的优化只是减少了微乎其微的内存分配。这个结果实在令老许充满了疑惑,在使用pprof分析后终于发现性能没有提升的原因。以下为benchmark期间BenchmarkCompareVersionWithCache1函数的火焰图。

因为考虑到app版本数量较小,所以使用了惰性淘汰的方式淘汰过期缓存,在每次读取数据时判断缓存是否过期。根据火焰图知性能损耗最大的就是判断缓存是否过期,每次判断缓存是否过期都需要调用 time.Now().Unix()得到当前时间戳。也就是因为time.Now()的这个调用导致这次优化功亏一篑。
引入LRU缓存
考虑到版本数量本身不多,且对于常用的版本可以尽可能永久缓存,因此引入LRU缓存做进一步性能优化尝试。
1、引入开源的LRU缓存,对应开源库为: github.com/hashicorp/golang-lru
2、在CompareVersionWithCache1函数的基础上将读写缓存替换为引入的LRU缓存
最后进行性能验证,以下为CompareVersionWithCache2函数和CompareVersion函数的benchmark对比。
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1583202 841.7 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache2-4 1671758 633.9 ns/op 96 B/op 6 allocs/op哎,这个结果终于有点样子了,但优化效果并不明显,还有进一步提升的空间。
自实现LRU缓存
选择LRU缓存是有效果的,在这个基础上老许决定自己实现一个极简的LRU缓存。
1、定义一个缓存节点结构体
type lruCacheItem struct {
// 双向链表
prev, next *lruCacheItem
// 缓存数据
data interface{}
// 缓存数据对应的key
key string
}2、 定义一个操作LRU缓存的结构体
type lruc struct {
// 链表头指针和尾指针
head, tail *lruCacheItem
// 一个map存储各个链表的指针,以方便o(1)的复杂度读取数据
lruMap map[string]*lruCacheItem
rw sync.RWMutex
size int64
}
func NewLRU(size int64) *lruc {
if size < 0 {
size = 100
}
lru := &lruc{
head: new(lruCacheItem),
tail: new(lruCacheItem),
lruMap: make(map[string]*lruCacheItem),
size: size,
}
lru.head.next = lru.tail
lru.tail.prev = lru.head
return lru
}
3、LRU缓存的Set方法
func (lru *lruc) Set(key string, v interface{}) {
// fast path
if _, exist := lru.lruMap[key]; exist {
return
}
node := &lruCacheItem{
data: v,
prev: lru.head,
next: lru.head.next,
key: key,
}
// add first
lru.rw.Lock()
// double check
if _, exist := lru.lruMap[key]; !exist {
lru.lruMap[key] = node
lru.head.next = node
node.next.prev = node
}
if len(lru.lruMap) > int(lru.size) {
// delete tail
prev := lru.tail.prev
prev.prev.next = lru.tail
lru.tail.prev = prev.prev
delete(lru.lruMap, prev.key)
}
lru.rw.Unlock()
}
4、LRU缓存的Get方法
func (lru *lruc) Get(key string) (interface{}, bool) {
lru.rw.RLock()
v, ok := lru.lruMap[key]
lru.rw.RUnlock()
if ok {
// move to head.next
lru.rw.Lock()
v.prev.next = v.next
v.next.prev = v.prev
v.prev = lru.head
v.next = lru.head.next
lru.head.next = v
lru.rw.Unlock()
return v.data, true
}
return nil, false
}5、在CompareVersionWithCache1函数的基础上将读写缓存替换为自实现的LRU缓存
最后进行性能验证,以下为CompareVersionWithCache3函数和CompareVersion函数的benchmark对比:
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1575007 763.1 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache3-4 3285632 317.6 ns/op 0 B/op 0 allocs/op引入自实现的LRU缓存后,性能足足提升了一倍,到这里老许几乎准备去公司装逼了,但是心里总有个声音在问我有没有无锁的方式读取缓存。
减少LRU缓存锁竞争
无锁的方式确实没有想到,只想到了两种减少锁竞争的方式。
- 不需要每次读数据时都将节点移动到链表头,只有当LRU缓存数量接近Size上限的时候才将最新读取的数据移动到链表头
- 既然是LRU缓存,那么访问频率越高,缓存节点越靠近链表头,基于这个特性可以考虑在每次访问的时候加入随机数以减小锁的竞争(即访问频率越高越有机会通过随机数控制将缓存节点移动到链表头)。
加入随机数后的实现如下:
func (lru *lruc) Get(key string) (interface{}, bool) {
lru.rw.RLock()
v, ok := lru.lruMap[key]
lru.rw.RUnlock()
if ok {
// 这里随机写100
if rand.Int()%100 == 1 {
lru.rw.Lock()
v.prev.next = v.next
v.next.prev = v.prev
v.prev = lru.head
v.next = lru.head.next
lru.head.next = v
lru.rw.Unlock()
}
return v.data, true
}
return nil, false
}加入随机数后的CompareVersionWithCache3函数和CompareVersion函数的benchmark对比如下:
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1617837 761.5 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache3-4 4817722 251.3 ns/op 0 B/op 0 allocs/op加入随机数后,CompareVersionWithCache3函数性能再次提升20%左右。优化还没结束,当缓存数量远不足设置的缓存上限时不需要移动到链表头。
func (lru *lruc) Get(key string) (interface{}, bool) {
lru.rw.RLock()
v, ok := lru.lruMap[key]
lru.rw.RUnlock()
if ok {
// move to head.next
if len(lru.lruMap) > int(lru.size)-1 && rand.Int()%100 == 1 {
lru.rw.Lock()
v.prev.next = v.next
v.next.prev = v.prev
v.prev = lru.head
v.next = lru.head.next
lru.head.next = v
lru.rw.Unlock()
}
return v.data, true
}
return nil, false
}引入上述优化后,benchmark对比如下:
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1633576 793.2 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1619822 882.7 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1639792 737.2 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1630004 758.3 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache3-4 7538025 155.9 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 7514742 150.1 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 8357704 162.9 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 7748578 148.0 ns/op 0 B/op 0 allocs/op至此,最终版的版本比较实现在理想情况下(缓存空间较足)性能达到原先的4倍。
有的人就是老天爷赏饭吃
本来老许都准备去公司装逼了,万万没想到同事已经搞了一个更加合理且稳定的版本比较算法,让老许自愧不如。
该算法思路如下:
- 不使用
strings.Split函数将版本以.分割,而是从左到右依次对比每一个字符直至遇到不同的字符,并分别记录索引i,j - 遍历两个版本剩余部分字符串,以
i、j为始直至遇到第一个.,将这两部分字符串转为整形进行比较 - 如果前两步完成后仍相等,则谁还有剩余字符则谁大
三种算法benchmark如下:
cpu: Intel(R) Core(TM) i7-7567U CPU @ 3.50GHz
BenchmarkCompareVersion-4 1803190 674.8 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1890308 630.9 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1855741 631.8 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersion-4 1850410 629.4 ns/op 304 B/op 6 allocs/op
BenchmarkCompareVersionWithCache3-4 8877466 132.2 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 8489661 132.6 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 8358210 132.6 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionWithCache3-4 8456853 131.9 ns/op 0 B/op 0 allocs/op
BenchmarkCompareVersionNoSplit-4 6309705 178.9 ns/op 8 B/op 2 allocs/op
BenchmarkCompareVersionNoSplit-4 6228823 181.2 ns/op 8 B/op 2 allocs/op
BenchmarkCompareVersionNoSplit-4 6370544 177.8 ns/op 8 B/op 2 allocs/op
BenchmarkCompareVersionNoSplit-4 6351043 180.0 ns/op 8 B/op 2 allocs/opBenchmarkCompareVersionNoSplit函数不需要引入缓存,也不会像BenchmarkCompareVersionWithCache3中的缓存数量接近上限后会有一定的性能损失,几乎是我目前发现的最为理想的版本比较方案。
老许也不说什么当局者迷,旁观者清这种酸葡萄一般的话,只得承认有的人就是老天爷赏饭吃。有一说一碰上这种人是我的幸运,我相信他只要有口饭吃,我就能在他屁股后面蹭口汤喝。关于文中最后提到的版本号比较算法完整实现请至下面的github仓库查看:
https://github.com/Isites/are...
最后,衷心希望本文能够对各位读者有一定的帮助。
注:
写本文时, 笔者所用go版本为: go1.16.6
文章中所用完整例子:https://github.com/Isites/go-...