jpmml导出java文件_如何使用 Java 调取 Python、R 的训练模型?
原标题:如何使用 Java 调取 Python、R 的训练模型?

在工业界,我们经常会使用 Python 或 R 来训练离线模型, 使用 Java 来做在线 Web 开发应用——这就涉及到了使用 Java 跨语言来调用 Python 或 R 训练的模型。
PMML
PMML 是 Predictive Model Markup Language 的缩写,翻译为中文就是“预测模型标记语言”。它是一种基于XML的标准语言,用于表达数据挖掘模型,可以用来在不同的应用程序中交换模型。
也就是说它定义了一个标准,不同语言都可以根据这个标准来实现。关于 PMML 内部的实现原理细节,我们这里不做深究,感兴趣的可以参见:http://dmg.org/pmml/v4-3/GeneralStructure.html。
PMML 能做什么
介绍完了 PMML 的概念后,大家可能还是很懵,不清楚它有什么用。先来相对正式地说下它的用处:对于 PMML,使用一个应用程序很容易在一个系统上开发模型,并且只需通过发送XML配置文件就可以在另一个系统上使用另一个应用程序部署模型。也就是说我们可以通过 Python 或 R 训练模型,将模型转为 PMML 文件,再使用 Java 根据 PMML 文件来构建 Java 程序。
来看一张关于 PMML 用途的图片:
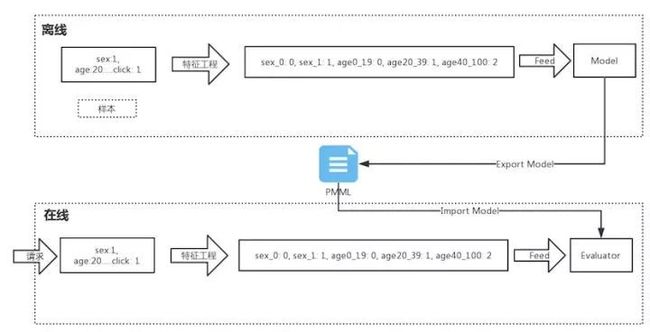
这张图的信息来一一说明下:
整个流程分为两部分:离线和在线。
离线部分流程是将样本进行特征工程,然后进行训练、生成模型。一般离线部分常用 Python 中的 sklearn、R 或者 Spark ML 来训练模型。
在线部分是根据请求得到样本数据,对这些数据采用与离线特征工程一样的方式来处理,然后使用模型进行评估。一般在线部分常用 Java、C++ 来开发。
离线部分与在线部分是通过 PMML 连接的,也就是说离线训练好了模型之后,将模型导出为 PMML 文件,在线部分加载该 PMML 文件生成对应的评估模型。
我们可以看到,PMML 是连接离线与在线环节的关键,一般导出 PMML 文件和加载 PMML 文件都需要各个语言来做单独的实现。不过幸运的是,已经有很多大神实现了这些,可以参见:https://github.com/jpmml 。
实战环节
训练并导出 PMML
我们这里仍然是通过 sklearn 训练一个随机森林模型,我们需要借助 sklearn2pmml 将 sklearn 训练的模型导出为 PMML 文件。如果没有 sklearn2pmml,请输入以下命令来安装:
pip install --user git+https://github.com/jpmml/sklearn2pmml.git
我们来看下如何使用 sklearn2pmml 。
fromsklearn.datasets importload_iris
fromsklearn.ensemble importRandomForestClassifier
fromsklearn2pmml importPMMLPipeline, sklearn2pmml
iris = load_iris()
# 创建带有特征名称的 DataFrame
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 创建模型管道
iris_pipeline = PMMLPipeline([
( "classifier", RandomForestClassifier())
])
# 训练模型
iris_pipeline.fit(iris_df, iris.target)
# 导出模型到 RandomForestClassifier_Iris.pmml 文件
sklearn2pmml(iris_pipeline, "RandomForestClassifier_Iris.pmml")
导出成功后,我们将在当前路径看到一个 PMML 文件:RandomForestClassifier_Iris.pmml。
导入 PMML 并进行评估
生成了 PMML 文件后,接下来我们要做的就是使用 Java 导入(加载)PMML文件。这里借助了 Java 的第三方依赖:pmml-evaluator。我们需要在 pom.xml 文件中加入以下依赖:
org.jpmml
pmml-evaluator
1.4.1
org.jpmml
pmml-evaluator-extension
1.4.1
引入 PMML 文件并进行评估的代码如下:
importorg.dmg.pmml.FieldName;
importorg.dmg.pmml.PMML;
importorg.jpmml.evaluator.*;
importorg.jpmml.model.PMMLUtil;
importorg.xml.sax.SAXException;
importjavax.xml.bind.JAXBException;
importjava.io.FileInputStream;
importjava.io.FileNotFoundException;
importjava.io.IOException;
importjava.io.InputStream;
importjava.util.ArrayList;
importjava.util.HashMap;
importjava.util.List;
importjava.util.Map;
publicclassClassificationModel{
privateEvaluator modelEvaluator;
/**
* 通过传入 PMML 文件路径来生成机器学习模型
*
* @parampmmlFileName pmml 文件路径
*/
publicClassificationModel(String pmmlFileName){
PMML pmml = null;
try{
if(pmmlFileName != null) {
InputStream is = newFileInputStream(pmmlFileName);
pmml = PMMLUtil.unmarshal(is);
try{
is.close();
} catch(IOException e) {
System.out.println( "InputStream close error!");
}
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance();
this.modelEvaluator = (Evaluator) modelEvaluatorFactory.newModelEvaluator(pmml);
modelEvaluator.verify();
System.out.println( "加载模型成功!");
}
} catch(SAXException e) {
e.printStackTrace();
} catch(JAXBException e) {
e.printStackTrace();
} catch(FileNotFoundException e) {
e.printStackTrace();
}
}
// 获取模型需要的特征名称
publicList getFeatureNames(){
List featureNames = newArrayList();
List inputFields = modelEvaluator.getInputFields();
for(InputField inputField : inputFields) {
featureNames.add(inputField.getName().toString());
}
returnfeatureNames;
}
// 获取目标字段名称
publicString getTargetName(){
returnmodelEvaluator.getTargetFields().get( 0).getName().toString();
}
// 使用模型生成概率分布
privateProbabilityDistribution getProbabilityDistribution(Map arguments){
Map evaluateResult = modelEvaluator.evaluate(arguments);
FieldName fieldName = newFieldName(getTargetName());
return(ProbabilityDistribution) evaluateResult.get(fieldName);
}
// 预测不同分类的概率
publicValueMap predictProba(Map arguments){
ProbabilityDistribution probabilityDistribution = getProbabilityDistribution(arguments);
returnprobabilityDistribution.getValues();
}
// 预测结果分类
publicObject predict(Map arguments){
ProbabilityDistribution probabilityDistribution = getProbabilityDistribution(arguments);
returnprobabilityDistribution.getPrediction();
}
publicstaticvoidmain(String[] args){
ClassificationModel clf = newClassificationModel( "RandomForestClassifier_Iris.pmml");
List featureNames = clf.getFeatureNames();
System.out.println( "feature: "+ featureNames);
// 构建待预测数据
Map waitPreSample = newHashMap<>();
waitPreSample.put( newFieldName( "sepal length (cm)"), 10);
waitPreSample.put( newFieldName( "sepal width (cm)"), 1);
waitPreSample.put( newFieldName( "petal length (cm)"), 3);
waitPreSample.put( newFieldName( "petal width (cm)"), 2);
System.out.println( "waitPreSample predict result: "+ clf.predict(waitPreSample).toString());
System.out.println( "waitPreSample predictProba result: "+ clf.predictProba(waitPreSample).toString());
}
}
输出结果:
加载模型成功!
feature: [sepal length (cm), petal width (cm), sepal width (cm), petal length (cm)]
waitPreSample predict result: 1
waitPreSample predictProba result: {0=0.0, 1=0.5, 2=0.5}
可以看到,模型需要的特征为:[sepal length (cm), petal width (cm), sepal width (cm), petal length (cm)],预测该样本最终属于目标编号为 1 的类型,预测该样本属于不同目标编号的概率分布,{0=0.0, 1=0.5, 2=0.5}。
小结
为了实现 Java 跨语言调用 Python/R 训练好的模型,我们借助 PMML 的规范,将模型固化为 PMML 文件,再使用该文件生成模型来评估。
作者:1or0,专注于机器学习研究。
声明:本文为公众号 AI派 投稿,版权归对方所有。返回搜狐,查看更多
责任编辑: