用python建立gm(1、1)模型_灰色预测模型GM(1,1)的全面讲解及python实现
1. 灰色预测的概念
(1)灰色系统、白色系统和黑色系统
白色系统是指一个系统的内部特征是完全已知的,既系统信息是完全充分的。
黑色系统是一个系统的内部信息对外界来说是一无所知的,只能通过它与外界的联系来加以观测研究。
灰色系统介于白色和黑色之间,灰色系统内的一部分信息是已知的,另一部分信息是未知的,系统内各因素间有不确定的关系。
(2)灰色预测法
所以灰色预测就是通过这样的信息前提下做的一种预测分析,即灰色预测法是一种预测灰色系统的预测方法。
灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况,最后得到其发展的模型。
一般表达方式为GM(n,x)模型,其含义是:用n阶微分方程对x个变量建立模型
关联分析实际上是动态过程发展态势的量化比较分析。所谓发展态势比较,也就是系统各时期有关统计数据的集合关系的比较。例如,某地区1977~1983年总收入与养猪、养兔收入资料见下表格。

2. 灰色生成数列
灰色系统理论认为,尽管客观表象复杂,但总是有整体功能的,因此必然蕴含某种内在规律。关键在于如何选择适当的方式去挖掘和利用它。灰色系统是通过对原始数据的整理来寻求其变化规律的,这是一种就数据寻求数据的现实规律的途径,也就是灰色序列的生产。一切灰色序列都能通过某种生成弱化其随机性,显现其规律性。数据生成的常用方式有累加生成、累减生成和加权累加生成,将灰色系统中的未知因素弱化,强化已知因素的影响程度,最后构建一个以时间为变量的连续微分方程,通过数学方法确定方程中的参数,从而实现预测目的。
(1)累加生成(AGO)
设原始序列为
![]() ,令
,令
![]()
![]() 为数列
为数列
![]() 的1次累加生成数列。类似的有:
的1次累加生成数列。类似的有:
![]() 称为
称为
![]() 的r次累加生成数列
的r次累加生成数列
(2)累减生成(IAGO)
如果原始数列为
![]() ,令
,令
![]() ,称
,称
![]() 为x1
为x1
![]() 的1次累减生成数列。
的1次累减生成数列。
(3)加权邻值生成:
如果原始数列为
![]() ,称任意一对相邻元素
,称任意一对相邻元素
![]() 互为邻值。对于常数
互为邻值。对于常数
![]() ,令
,令
![]()
由此得到的数列称为邻值生成数,权α 也称为生成系数。特别地,当α=0.5 时,则称该数列为均值生成数,也称为等权邻值生成数。
3. 灰色模型GM(1,1)
灰色系统理论是基于关联空间、光滑离散函数等概念定义灰导数与灰微分方程,进而用离散数据列建立微分方程形式的动态模型,即灰色模型是利用离散随机数经过生成变为随机性被显著削弱而且较有规律的生成数,建立起的微分方程形式的模型,这样便于对其变化过程进行研究和描述。
G表示grey(灰色),M表示model(模型)
定义
![]() 的灰导数为:
的灰导数为:
![]()
令
![]() 为数列
为数列
![]() 的邻值生成数列,即
的邻值生成数列,即
![]()
于是定义GM(1,1,)的灰微分方程模型为:
![]() 或
或
![]() ,其中
,其中
![]() 称为灰导数,
称为灰导数,
![]() 称为发展系数,
称为发展系数,
![]() 称为白化背景值,b称为灰作用量。
称为白化背景值,b称为灰作用量。
将时刻k=2,3,…,n代入上式有
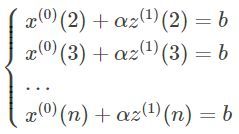
引入矩阵向量记号:
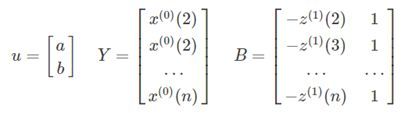
于是GM(1,1模型可表示为Y=Bu
那么现在的问题就是求a和b的值,我们可以用一元线性回归,也就是最小二乘法求它们的估计值:
![]()
对于GM(1,1)的灰微分方程,如果将时刻k=2,3,…,n视为连续变量t,则之前的
![]() 视为时间t函数,于是灰导数
视为时间t函数,于是灰导数
![]() 变为连续函数的导数
变为连续函数的导数![]() ,白化背景值
,白化背景值
![]() 对应于导数
对应于导数
![]() ,于是GM(1,1)的灰微分方程对应于的白微分方程为:
,于是GM(1,1)的灰微分方程对应于的白微分方程为:![]()
4. GM(1,1)灰色预测的步骤
(1)数据的检验与处理
为了保证GM(1,1)建模方法的可行性,需要对已知数据做必要的检验处理。设原始数据列为
![]() ,首先计算数列的级比:
,首先计算数列的级比:
![]()
如果所有的级比都落在可容覆盖区间
![]() 内,则数列
内,则数列
![]() 可以建立GM(1,1)模型且可以进行灰色预测。否则,对数据做适当的变换处理,如平移变换:
可以建立GM(1,1)模型且可以进行灰色预测。否则,对数据做适当的变换处理,如平移变换:
![]() ,取c使得数据列的级比都落在可容覆盖内。
,取c使得数据列的级比都落在可容覆盖内。
(2)建立GM(1,1)模型
不妨设
![]() 满足上面的要求,以它为数据列建立GM(1,1)模型
满足上面的要求,以它为数据列建立GM(1,1)模型
![]() ,用回归分析求得a,b的估计值,于是相应的白化模型为:
,用回归分析求得a,b的估计值,于是相应的白化模型为:![]() ,解为
,解为
![]() 。
。
于是得到预测值:
![]()
从而相应地得到预测值:
![]()
5. 检验预测值
(1)残差检验:计算相对残差:![]() ,如果对所有的|ε(k)|<0.1,则认为到达较高的要求;否则,若对所有的|ε(k)|<0.2,则认为达到一般要求。
,如果对所有的|ε(k)|<0.1,则认为到达较高的要求;否则,若对所有的|ε(k)|<0.2,则认为达到一般要求。
(2)级比偏差值检验:计算:![]() 。如果对所有的
。如果对所有的
![]() ,则认为达到较高的要求;否则,对于所有的
,则认为达到较高的要求;否则,对于所有的
![]() ,则认为达到一般要求。
,则认为达到一般要求。
6. 计算实例




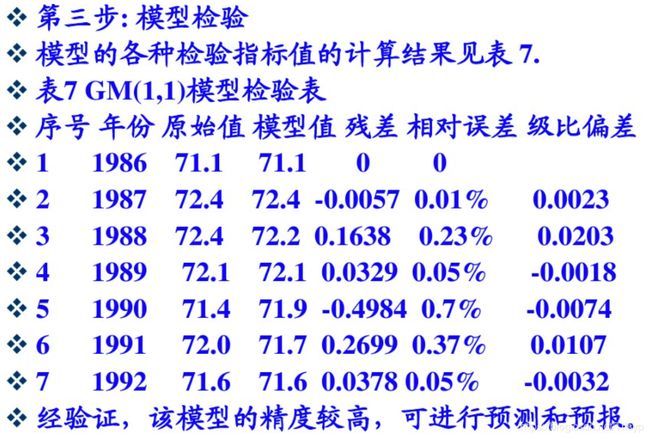
Python完整代码:
importpandasaspd
importnumpyasnp
defstep_ratio(x0):
n =len(x0)
ratio = [x0[i]/x0[i+1]foriinrange(len(x0)-1)]print(f"级比:{ratio}")
min_la, max_la =min(ratio),max(ratio)
thred_la = [np.exp(-2/(n+2)), np.exp(2/(n+2))]ifmin_la < thred_la[0]ormax_la > thred_la[-1]:print("级比超过灰色模型的范围")else:print("级比满足要求,可用GM(1,1)模型")returnratio, thred_la
defpredict(x0):
n =len(x0)
x1 = np.cumsum(x0)
z = np.zeros(n-1)foriinrange(n-1):
z[i] =0.5*(x1[i]+x1[i+1])
B = [-z, [1]*(n-1)]
Y = x0[1:]
u = np.dot(np.linalg.inv(np.dot(B, np.transpose(B))),np.dot(B, Y))
x1_solve = np.zeros(n)
x0_solve = np.zeros(n)
x1_solve[0] = x0_solve[0] = x0[0]foriinrange(1, n):
x1_solve[i] = (x0[0]-u[1]/u[0])*np.exp(-u[0]*i)+u[1]/u[0]foriinrange(1, n):
x0_solve[i] = x1_solve[i] - x1_solve[i-1]returnx0_solve, x1_solve, u
defaccuracy(x0, x0_solve, ratio, u):
epsilon = x0 - x0_solve
delta =abs(epsilon / x0)print(f"相对误差:{delta}")# Q = np.mean(delta)
# C = np.std(epsilon)/np.std(x0)S1 = np.std(x0)
S1_new = S1*0.6745temp_P = epsilon[abs(epsilon-np.mean(epsilon)) < S1_new]
P =len(temp_P)/len(x0)print(f"预测准确率:{P*100}%")
ratio_solve = [x0_solve[i]/x0_solve[i+1]foriinrange(len(x0_solve)-1)]
rho = [1-(1-0.5*u[0]/u[1])/(1+0.5*u[0]/u[1])*(ratio[i]/ratio_solve[i])foriinrange(len(ratio))]print(f"级比偏差:{rho}")returnepsilon, delta, rho, P
if__name__ =='__main__':
data=pd.DataFrame(data={"year":[1986,1987,1988,1989,1990,1991,1992],"eqL":[71.1,72.4,72.4,72.1,71.4,72.0,71.6]})
x0 = np.array(data.iloc[:,1])
ratio, thred_la = step_ratio(x0)
x0_solve, x1_solve, u = predict(x0)
epsilon, delta, rho, P = accuracy(x0, x0_solve, ratio, u)
7. 优缺点:
灰色系统预测模型的特点:无需大量数据样本,短期预测效果好,运算过程简单。
灰色系统预测模型的不足:对非线性数据样本预测效果差。
8. GM(1,n)模型
GM(1,n)模型的预测原理与GM(1,1)类似,不同在于输入数据变量为N个。即:
![]() ,其它特征数据序列分别为:
,其它特征数据序列分别为:
![]()
……
![]()
这样,只需每个变量对应数据列建立GM(1,1)模型即可,即
![]()
参考地址:https://blog.csdn.net/qq547276542/article/details/77865341