【金融风控-贷款违约预测】Task3 特征工程篇
阿里云天池学习赛 – Datawhale学习笔记
文章目录
- 1、学习目标
- 2、内容介绍
- 3、特征预处理
-
- 3.1 关于异常值的补充
-
- 3.1.1 异常值检测
- 3.1.2 检测异常的方法一:**均方差**
- 3.1.3 检测异常的方法二:**箱型图**
- 3.1.4 异常值处理:
- 3.2 数据分桶
-
- 3.2.1 分箱方法:
- 3.3 特征交互
- 3.4 特征编码
- 4、特征工程
- 5、总结
1、学习目标
- Task3 特征工程篇教程链接 :点我
- 学习特征预处理、缺失值、异常值处理、数据分桶等特征处理方法
- 学习特征交互、编码、选择的相应方法
2、内容介绍

3、特征预处理
数据EDA部分我们已经对数据的大概和某些特征分布有了了解,数据预处理部分一般我们要处理一些EDA阶段分析出来的问题,这里介绍了数据缺失值的填充,时间格式特征的转化处理,某些对象类别特征的处理。
# 补充:含缺失值的数据的类型转换(直接astype会报错)
def employmentLength_to_int(s):
if pd.isnull(s):
return s
else:
return np.int8(s.split()[0])
3.1 关于异常值的补充
3.1.1 异常值检测
异常值检测的常见四种方法,分别为Numeric Outlier、Z-Score、DBSCAN、LOF(K近邻距离)以及Isolation Forest(有监督)
- 异常检测:Isolation Forest:
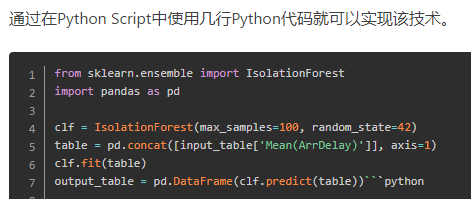
- 异常检测:LOF

3.1.2 检测异常的方法一:均方差
在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内。
def find_outliers_by_3segama(data,fea):
data_std = np.std(data[fea])
data_mean = np.mean(data[fea])
outliers_cut_off = data_std * 3
lower_rule = data_mean - outliers_cut_off
upper_rule = data_mean + outliers_cut_off
data[fea+'_outliers'] = data[fea].apply(lambda x:str('异常值') if x > upper_rule or x < lower_rule else '正常值')
return data
得到特征的异常值后可以进一步分析变量异常值和目标变量的关系
data_train = data_train.copy()
for fea in numerical_fea:
data_train = find_outliers_by_3segama(data_train,fea)
print(data_train[fea+'_outliers'].value_counts())
print(data_train.groupby(fea+'_outliers')['isDefault'].sum())
print('*'*10)
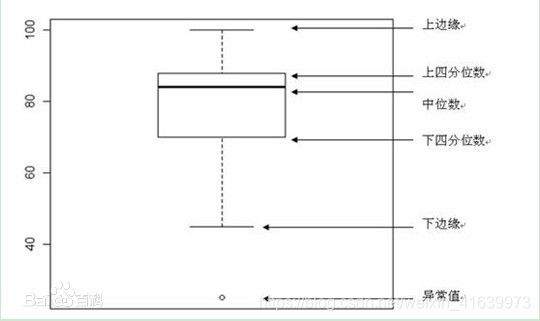
3.1.3 检测异常的方法二:箱型图
总结一句话:四分位数会将数据分为三个点和四个区间,IQR = Q3 -Q1,下触须=Q1 − 1.5x IQR,上触须=Q3 + 1.5x IQR;
- 异常值可被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的值(基于正态分布的3σ法则或z分数方法是以假定数据服从正态分布为前提的)
3.1.4 异常值处理:
当你发现异常值后,一定要先分清是什么原因导致的异常值,然后再考虑如何处理。
- 首先,如果这一异常值并不代表一种规律性的,而是极其偶然的现象,或者说你并不想研究这种偶然的现象,这时可以将其删除。
- 其次,如果异常值存在且代表了一种真实存在的现象,那就不能随便删除。在现有的欺诈场景中很多时候欺诈数据本身相对于正常数据勒说就是异常的,我们要把这些异常点纳入,重新拟合模型,研究其规律。能用监督的用监督模型,不能用的还可以考虑用异常检测的算法来做。
- **注意test的数据不能删。
3.2 数据分桶

3.2.1 分箱方法:

3.3 特征交互
交互特征的构造非常简单,使用起来却代价不菲。如果线性模型中包含有交互特征对,那它的训练时间和评分时间就会从 O(n) 增加到 O(n2),其中 n 是单一特征的数量。
for col in ['grade', 'subGrade']:
temp_dict = data_train.groupby([col])['isDefault'].agg(['mean']).reset_index().rename(columns={'mean': col + '_target_mean'})
temp_dict.index = temp_dict[col].values
temp_dict = temp_dict[col + '_target_mean'].to_dict()
data_train[col + '_target_mean'] = data_train[col].map(temp_dict)
data_test_a[col + '_target_mean'] = data_test_a[col].map(temp_dict)
# 其他衍生变量 mean 和 std
for df in [data_train, data_test_a]:
for item in ['n0','n1','n2','n2.1','n4','n5','n6','n7','n8','n9','n10','n11','n12','n13','n14']:
df['grade_to_mean_' + item] = df['grade'] / df.groupby([item])['grade'].transform('mean')
df['grade_to_std_' + item] = df['grade'] / df.groupby([item])['grade'].transform('std')
这里给出一些特征交互的思路,但特征和特征间的交互衍生出新的特征还远远不止于此,抛砖引玉,希望大家多多探索。请学习者尝试其他的特征交互方法。
3.4 特征编码
#labelEncode 直接放入树模型中
#label-encode:subGrade,postCode,title
# 高维类别特征需要进行转换
for col in tqdm(['employmentTitle', 'postCode', 'title','subGrade']):
le = LabelEncoder()
le.fit(list(data_train[col].astype(str).values) + list(data_test_a[col].astype(str).values))
data_train[col] = le.transform(list(data_train[col].astype(str).values))
data_test_a[col] = le.transform(list(data_test_a[col].astype(str).values))
print('Label Encoding 完成')
逻辑回归等模型要单独增加的特征工程
- 对特征做归一化,去除相关性高的特征
- 归一化目的是让训练过程更好更快的收敛,避免特征大吃小的问题
- 去除相关性是增加模型的可解释性,加快预测过程。
# 举例归一化过程
#伪代码
for fea in [要归一化的特征列表]:
data[fea] = ((data[fea] - np.min(data[fea])) / (np.max(data[fea]) - np.min(data[fea])))
4、特征工程
特征筛选方法总结 :特征筛选方法总结
- 特征选择:方差选择法、卡方检验、互信息法、递归特征消除、L1范数、树模型
- 特征选择主要从两个方面入手:
1、特征是否发散:特征发散说明特征的方差大,能够根据取值的差异化度量目标信息.
2、特征与目标相关性:优先选取与目标高度相关性的.
** 对于特征选择,有时候我们需要考虑分类变量和连续变量的不同.

5、总结
特征工程是机器学习,甚至是深度学习中最为重要的一部分,在实际应用中往往也是所花费时间最多的一步。各种算法书中对特征工程部分的讲解往往少得可怜,因为特征工程和具体的数据结合的太紧密,很难系统地覆盖所有场景。
- 本章主要是通过一些常用的方法来做介绍,例如缺失值异常值的处理方法详细对任何数据集来说都是适用的。但对于分箱等操作本章给出了具体的几种思路,需要读者自己探索。
- 在特征工程中比赛和具体的应用还是有所不同的,在实际的金融风控评分卡制作过程中,由于强调特征的可解释性,特征分箱尤其重要。
- 学有余力同学可以自行多尝试,希望大家在本节学习中有所收获。
END.