股票数据分析
股票数据分析
前面我们介绍了Spark 和 Spark SQL,今天我们就使用 Spark SQL来分析一下我们的数据,今天我们主要分析一下股票数据
数据准备
这里郑重申明,我们的全部数据来自tushare, tushare 是一个免费提供各类金融数据 , 助力智能投资与创新型投资的社区,也鼓励大家对社区多多支持和赞助。
交易数据
我们拿到了最近几年的交易数据

下面是具体的数据格式,csv 文件,ts_code 对于的是一个股票代码

股票详情数据

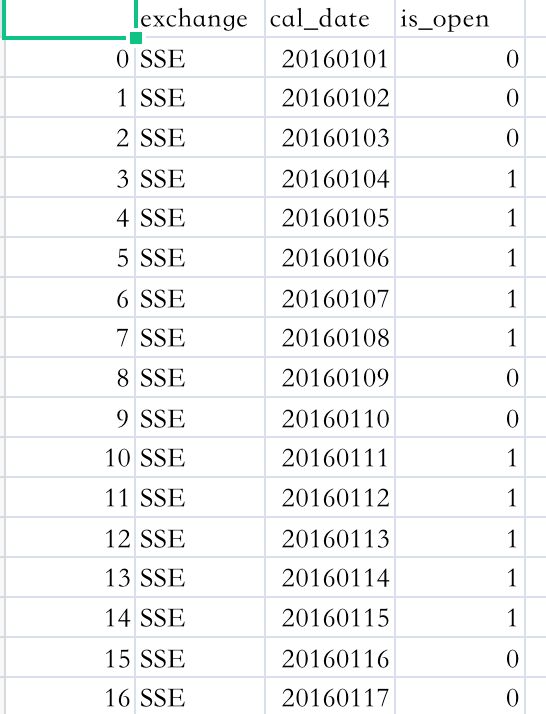
日期数据
因为股票市场不是天天开的,只有交易日才开门,下面就是我们的交易日数据
数据分析
当然这里我们的分析并不是教大家去怎么买卖股票,我们的目标是为了学习Spark ,所以我们下面就有一些例子,当然大家也可以自行去补充
统计每天的成交额
下面我们统计一下每天的成交额,这也是最简单的了
def lastDaysamount(): Unit ={
sql(
"""
|select
| trade_date,sum(amount) as amount
|from
| trade
|group by
| trade_date
|order by
| trade_date desc
|limit
| 20
|""".stripMargin
).show(20,false)
}
统计结果
+----------+---------------------+
|trade_date|amount |
+----------+---------------------+
|20211101 |1.2228828557399983E12|
|20211029 |1.1381616219410015E12|
|20211028 |1.1072842704220002E12|
|20211027 |1.0765778557610035E12|
|20211026 |1.0821421444879968E12|
|20211025 |1.0145576773829996E12|
|20211022 |1.0149981487659999E12|
|20211021 |9.92753188046003E11 |
|20211020 |1.0197585589460028E12|
|20211019 |9.730877555890015E11 |
|20211018 |1.0019797845380023E12|
|20211015 |9.888019904729999E11 |
|20211014 |8.606463289579985E11 |
|20211013 |8.894112029519983E11 |
|20211012 |9.962537488750033E11 |
|20211011 |9.918985312839995E11 |
|20211008 |1.0603440896720006E12|
|20210930 |9.502251816350017E11 |
|20210929 |1.0775000013559976E12|
|20210928 |1.043524548934001E12 |
+----------+---------------------+
过去n天连续涨停的票
这个分析是这样的,用户输入一个数字n则代表的是过去n天,我们要做的的是筛选出过去连涨停n天、连涨停n-1天、连涨停n-2天一直到n-(n-1)天连续涨停的票,其实这个实现起来还是有一定难度的,因为这里有个累积的效果,而且就是连续涨停n天的票一定是涨停n-1天的,但是我们需要将它算在n 天里而不是n-1天,还 有就是我们的连续涨停是相对昨天的,例如昨天前天就是连续两次涨停,昨天前天大前天就是连续三次涨停。
数据准备
def main(args: Array[String]): Unit = {
// 股票交易数据
val data=spark
.read
.option("header", true)
.csv(path)
.select("ts_code","trade_date","open","high","low","close","pre_close","change","pct_chg","vol","amount")
// close 收盘价 pre_close 昨收价 change 涨跌额 pct_chg 涨跌幅 vol 成交量 (手) amount 成交额 (千元)
data.createOrReplaceTempView("trade")
// 股票基本数据
val stocks=spark
.read
.option("header", true)
.csv(stocksPath)
stocks.createOrReplaceTempView("stocks")
// 连续涨停的方法
lastContinueDays(5)
}
for循环实现
因为直接使用SQL很难实现,所以我们这里使用了混合编程的方式,也就是借助scala 的for 循环和SQL 来配合实现
/**
*
* @param n 连续多少天
*/
def lastContinueDays(n:Int): Unit ={
// 因为我们的n 是指n个交易日的数据,这里为了方便所以我们直接多取了一段时间的数据,直接来了个2倍,好的做法是你取dates 里面查
val startDate = LocalDate.now().plusDays(-2*n).format(DateTimeFormatter.ofPattern("yyyyMMdd"))
// 创建了一个空的实图,后面需要把for 循环里面的数据放到这个试图里面
sql(
"""
|select
| 0 as days,null as ts_code,null as name,null as industry,null as market
|""".stripMargin
).createOrReplaceTempView("base")
// 循环实现上面的效果
for(i <- 1 to n){
sql(
s"""
|select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,rn
|from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,row_number() over(partition by ts_code order by trade_date desc) as rn
| from
| trade
| where
| -- 时间要换掉 大致的过滤条件
| trade_date>='${startDate}'
|)tmp
|where
| -- 过去多少天
| rn<=$i
|""".stripMargin
).createOrReplaceTempView("continuedays")
// 更新数据到试图里
sql(
s"""
|select
| $i as days,a.ts_code,b.name,b.industry,b.market
|from(
| select
| ts_code
| from(
| select
-- pct_chg >=9.8涨停的定义
| ts_code,count(if(pct_chg>=9.8,ts_code,null)) as cnt
| from
| continuedays
| group by
| ts_code
| )tmp
| where
| cnt>=$i
|) a
|inner join
| stocks b
|on
| a.ts_code=b.ts_code
|union
-- 获取到上一次for 循环的结果
|select
| days,ts_code,name,industry,market
|from
| base
|""".stripMargin
).createOrReplaceTempView("base")
// 展示最后的结果
sql(
"""
|select
| days,ts_code,name,industry,market
|from(
| select
| days,ts_code,name,industry,market,row_number()over(partition by ts_code order by days desc) as rn
| from
| base
|)tmp
|where
| rn=1
| and days!=0
|order by
| days
|""".stripMargin
).show(2000,false)
}
我们看一下我们最终的效果,days 就是涨停的天数
+----+---------+-----------+--------+------+
|days|ts_code |name |industry|market|
+----+---------+-----------+--------+------+
|1 |603738.SH|泰晶科技 |元器件 |主板 |
|1 |301018.SZ|申菱环境 |专用机械|创业板|
|1 |300735.SZ|光弘科技 |通信设备|创业板|
|1 |300438.SZ|鹏辉能源 |电气设备|创业板|
|1 |603920.SH|世运电路 |元器件 |主板 |
|1 |002454.SZ|松芝股份 |汽车配件|中小板|
|1 |002463.SZ|沪电股份 |元器件 |中小板|
|1 |300594.SZ|朗进科技 |运输设备|创业板|
|1 |300365.SZ|恒华科技 |软件服务|创业板|
|1 |002483.SZ|润邦股份 |工程机械|中小板|
|1 |600295.SH|鄂尔多斯 |钢加工 |主板 |
|1 |603505.SH|金石资源 |矿物制品|主板 |
|1 |002610.SZ|爱康科技 |电气设备|中小板|
|1 |688059.SH|华锐精密 |机械基件|科创板|
|1 |603901.SH|永创智能 |专用机械|主板 |
|1 |603665.SH|康隆达 |纺织 |主板 |
|1 |600683.SH|京投发展 |区域地产|主板 |
|1 |688789.SH|宏华数科 |专用机械|科创板|
|1 |688518.SH|联赢激光 |专用机械|科创板|
|1 |603115.SH|海星股份 |元器件 |主板 |
|1 |603380.SH|易德龙 |元器件 |主板 |
|1 |300681.SZ|英搏尔 |汽车配件|创业板|
|1 |003043.SZ|华亚智能 |专用机械|中小板|
|1 |300835.SZ|龙磁科技 |元器件 |创业板|
|1 |600330.SH|天通股份 |元器件 |主板 |
|1 |605338.SH|巴比食品 |食品 |主板 |
|1 |688683.SH|莱尔科技 |化工原料|科创板|
|1 |300170.SZ|汉得信息 |软件服务|创业板|
|1 |001288.SZ|运机集团 |专用机械|主板 |
|1 |002522.SZ|浙江众成 |塑料 |中小板|
|1 |300990.SZ|同飞股份 |专用机械|创业板|
|1 |300953.SZ|震裕科技 |机械基件|创业板|
|1 |002701.SZ|奥瑞金 |广告包装|中小板|
|1 |603105.SH|芯能科技 |电气设备|主板 |
|1 |000931.SZ|中关村 |生物制药|主板 |
|1 |002571.SZ|德力股份 |玻璃 |中小板|
|1 |300617.SZ|安靠智电 |电气设备|创业板|
|1 |002916.SZ|深南电路 |元器件 |中小板|
|1 |603948.SH|建业股份 |化工原料|主板 |
|1 |300260.SZ|新莱应材 |机械基件|创业板|
|2 |688033.SH|天宜上佳 |运输设备|科创板|
|2 |603348.SH|文灿股份 |汽车配件|主板 |
|2 |300052.SZ|中青宝 |互联网 |创业板|
|2 |688008.SH|澜起科技 |半导体 |科创板|
|2 |603399.SH|吉翔股份 |小金属 |主板 |
|2 |002837.SZ|英维克 |专用机械|中小板|
|2 |603088.SH|宁波精达 |专用机械|主板 |
|2 |603063.SH|禾望电气 |电气设备|主板 |
|2 |603836.SH|海程邦达 |仓储物流|主板 |
|2 |002824.SZ|和胜股份 |铝 |中小板|
|2 |600742.SH|一汽富维 |汽车配件|主板 |
|2 |601218.SH|吉鑫科技 |机械基件|主板 |
|2 |605286.SH|同力日升 |运输设备|主板 |
|2 |600696.SH|岩石股份 |区域地产|主板 |
|3 |002805.SZ|丰元股份 |化工原料|中小板|
|3 |002815.SZ|崇达技术 |元器件 |中小板|
|3 |600556.SH|天下秀 |互联网 |主板 |
+----+---------+-----------+--------+------+
其实这里有一个问题,那就是我们认为每个股票不论涨跌它都应该出现在我们的数据里,其实实际情况不是这样的,可以有的股票被查封导致有一段时间是是没有它的交易数据的,所以我们上面使用row_number 排序取出来的数本身就是不连续的,例如下面的南岭民爆,我们发现它在20211019 号涨停之后一段时间没有数据,但是在20211103的时候又发生了一次涨停

也就是说我们要把这样的数据过滤掉,这个逻辑我就不再去写了了,因为很简单,而且我们的重点是SQL 实现,总觉得这种代码实现有点不优雅
SQL 实现
这个实现方式是我后来在车上和少爷讨论的时候想到的,其实这里的连续涨停和我们前面说的最大连续登陆有点不一样,那就是我们的大A股市其实在时间上是不连续的,例如周末以及节假日,这里你可以先看一下Hive实战之最大连续登陆,所以说股票它的数据理论上是没办法连续的,而且我们也不是求一段时间的最大连续涨停,我们是计算截止到昨天的连续涨停,例如昨天前天就是连续两次涨停,昨天前天大前天就是连续三次涨停,也就是说我们的时间截至点是昨天。
第一版
sql(
s"""
|select
| ts_code,
| min_trade_date as start_date,
| max_trade_date as end_date,
| days as continuedays
|from(
| select
| ts_code,
| min(trade_date) as min_trade_date,
| max(trade_date) as max_trade_date,
| -- 涨停天数
| count(1) as days
| from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,rn
| from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,row_number() over(partition by ts_code order by trade_date desc) as rn
| from
| trade
| where
| -- 时间要换掉 大致的过滤条件
| trade_date>='${startDate}'
| )tmp
| where
| -- 过去多少天
| rn<=10
| -- 涨停的数据
| and pct_chg>=9.8
| )
| group by
| ts_code
|)where
| -- 截止到昨天也是涨停的,这个日期要换成业务真实日期
| max_trade_date='20211103'
| -- 判断是不是连续的
| and datediff(to_date(max_trade_date,'yyyymmdd'),to_date(min_trade_date,'yyyymmdd'))=days-1
|order by
| days,ts_code desc
|""".stripMargin
).show(2000,false)
其实这里是有问题的,那就是判断是不是连续的条件上,这种判断方式其实是要求时间是真实连续的,也就是如果出现节假日我们这里就不算它是连续涨停,但是我们知道对于股票数据这是要算的,所以这里的我们要重新判断一下这个连续条件。
前面我们说了,我们有一个交易日期的数据表,这个里面记录了每一次的交易日数据,如果我们的days 和我们的交易日数据一致的话,那我们就可以认为它是连涨的
第二版
有了第一版之后,我们很容易改进这个实现
sql(
s"""
|select
| ts_code,
| start_date,
| end_date,
| cal_dates as continuedays,
| days
|from(
|select
| ts_code,
| max(min_trade_date) as start_date,
| max(max_trade_date) as end_date,
| max(days) as days,
| count(dates.cal_date) as cal_dates
|from(
| select
| ts_code,
| min_trade_date,
| max_trade_date,
| days
| from(
| select
| ts_code,
| min(trade_date) as min_trade_date,
| max(trade_date) as max_trade_date,
| -- 涨停天数
| count(1) as days
| from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,rn
| from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,row_number() over(partition by ts_code order by trade_date desc) as rn
| from
| trade
| where
| -- 时间要换掉 大致的过滤条件
| trade_date>='${startDate}'
| and ts_code='600556.SH'
| )tmp
| where
| -- 过去多少天
| rn<=10
| -- 涨停的数据
| and pct_chg>=9.8
| )
| group by
| ts_code
| )where
| -- 截止到昨天也是涨停的
| max_trade_date='20211103'
|) stocks
|inner join
| dates dates
|on
| dates.cal_date>=stocks.min_trade_date
| and dates.cal_date<=stocks.max_trade_date
| -- 是否是交易日
| and dates.is_open=1
|group by
| ts_code
|)
|order by
| days,ts_code desc
|""".stripMargin
).show(2000,false)
这个SQL 的确跑出来数据,这个的实现原理就是我们首先拿到最大的涨停日期,和最小的日期,然后判断这两个日期之间的交易日的个数和我们的涨停数据的个数,如果相等那就说明涨停是连续的,否则不连续但是我后来发现它还是不对的,它会遗漏一些情况下的数据,举个例子来看一下,
例如在最近5天内,“1、2 号是连涨停的,3号没有 ,4、5号是连续涨停的”
这个时候,我们发现最大和最小之间是有5个交易日的,所以1号到5号是不连续的,但是4号和5号是连续的,上面的计算逻辑就会导致我们忽略掉4号和5号的数据。
第三版
这是我第二天想到的,其实第一版和第二版都是在昨天早上想到的,第三版是我在昨天晚上江边散步的时候想到的,
既然我们找到了问题所在,我们可以这样做,来解决问题,我们构造这样的一个表,这里都是涨停的数据构造的,所以没有3号的数据
| ts_code | start_date | end_date |
|---|---|---|
| 300835.SZ | 1 | 5 |
| 300835.SZ | 2 | 5 |
| 300835.SZ | 4 | 5 |
| 300835.SZ | 5 | 5 |
有了这张表之后,我们再在这个基础上,计算两个东西,一个就是我们前面计算过的涨停天数,另外一个就是交易日期的个数,计算的范围就是我们的start_date和end_date
| ts_code | start_date | end_date | 涨停天数 | 交易天数 |
|---|---|---|---|---|
| 300835.SZ | 1 | 5 | 4 | 5 |
| 300835.SZ | 2 | 5 | 3 | 4 |
| 300835.SZ | 4 | 5 | 2 | 2 |
| 300835.SZ | 5 | 5 | 1 | 1 |
有了这个表格之后我们筛选出涨停天数和交易天数相等的记录,然后我们再筛选出涨停天数最大的即可
// 每次拿特定日期的过去10天的数据 这里我们为了避免因为节假日的原因,拿了过去一个月的数据,然后通过排序的方式再筛选出10天
val startDate = LocalDate.now().plusDays(-30).format(DateTimeFormatter.ofPattern("yyyyMMdd"))
val lastDate = LocalDate.now().plusDays(-1).format(DateTimeFormatter.ofPattern("yyyyMMdd"))
// 首先选出涨停的票,因为这张表我们要多次用到,所以我们单独创建了一个试图,你以可以使用with 语法和下面的的sql 整合
sql(
s"""
|select
| ts_code,trade_date,$lastDate as end_date
|from(
| select
| ts_code,trade_date,open,high,low,close,pre_close,change,pct_chg,vol,amount,row_number() over(partition by ts_code order by trade_date desc) as rn
| from
| trade
| where
| -- 时间要换掉 大致的过滤条件
| trade_date>='${startDate}'
|)tmp
|where
| -- 过去10条记录(这里注意一下不一定是过去10天的)
| rn<=10
| -- 涨停的数据
| and pct_chg>=9.8
|""".stripMargin
).createOrReplaceTempView("zhangting")
sql(
"""
|select
| ts_code,trade_date,end_date,zt_cnt
|from(
| select
| ts_code,
| trade_date,
| end_date,
| zt_cnt,
| row_number()over(partition by ts_code order by zt_cnt desc) as rn
| -- 筛选出 zt_cnt最大的记录
| from(
| select
| a.ts_code,
| a.trade_date,
| a.end_date,
| count(distinct b.trade_date) as zt_cnt
| from
| zhangting a
| left join
| zhangting b
| on
| a.ts_code=b.ts_code
| and a.trade_date<=b.trade_date
| and a.end_date>=b.trade_date
| left join
| dates dates
| on
| dates.cal_date>=a.trade_date
| and dates.cal_date<=a.end_date
| -- 是否是交易日
| and dates.is_open=1
| group by
| a.ts_code,a.trade_date,a.end_date
| having
| count(distinct b.trade_date)=count(distinct dates.cal_date)
| )t
|)t
|where
| rn=1
|order by
| zt_cnt
|""".stripMargin
).show(2000,false)
下面就是我们的计算结果

而且这里我把第一版和第三版的计算结果进行了对比,完全对的上,这也说明我们的计算是正确的
总结
今天我们通过使用 Spark SQL来分析股票数据,但是分析的目的不是为了买股票,而是为了学习和掌握Spark SQL。
在逻辑的实现上我们可以看到Spark SQL非常的灵活,可以使用混合编程,来完成我们复杂的业务逻辑。
还有就是过去n天连续涨停的票,其实整个计算还是很有难度的,因为股票的交易数据日期本来就不连续。