ELK日志分析平台搭建全过程
ELK日志分析平台搭建全过程
一、使用背景
当生产环境有很多服务器、很多业务模块的日志需要每时每刻查看时
二、环境
系统:centos 6.5
JDK:1.8
Elasticsearch-5.0.0
Logstash-5.0.0
kibana-5.0.0
三、安装
1、安装JDK
下载JDK:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
本环境下载的是64位tar.gz包,将安装包拷贝至安装服务器/usr/local目录
[root@localhost ~]# cd /usr/local/
[root@localhost local]# tar -xzvf jdk-8u111-linux-x64.tar.gz
配置环境变量
[root@localhost local]# vim /etc/profile
将下面的内容添加至文件末尾(假如服务器需要多个JDK版本,为了ELK不影响其它系统,也可以将环境变量的内容稍后添加到ELK的启动脚本中)
JAVA_HOME=/usr/local/jdk1.8.0_111
JRE_HOME=/usr/local/jdk1.8.0_111/jre
CLASSPATH=.:$JAVA_HOME/lib:/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export JRE_HOME
ulimit -u 4096
[root@localhost local]# source /etc/profile
配置limit相关参数
[root@localhost local]# vim /etc/security/limits.conf
添加以下内容
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
创建运行ELK的用户
[root@localhost local]# groupadd elk
[root@localhost local]# useradd -g elk elk
创建ELK运行目录
[root@localhost local]# mkdir /elk
[root@localhost local]# chown -R elk:elk /elk
关闭防火墙:
[root@localhost ~]# iptables -F
以上全部是root用户完成
2、安装ELK
以下由elk用户操作
以elk用户登录服务器
下载ELK安装包:https://www.elastic.co/downloads,并上传到服务器且解压,解压命令:tar -xzvf 包名
配置Elasticsearch

修改如下内容:
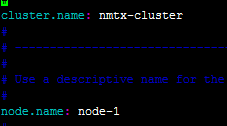
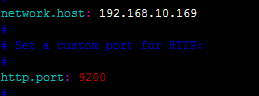
保存退出
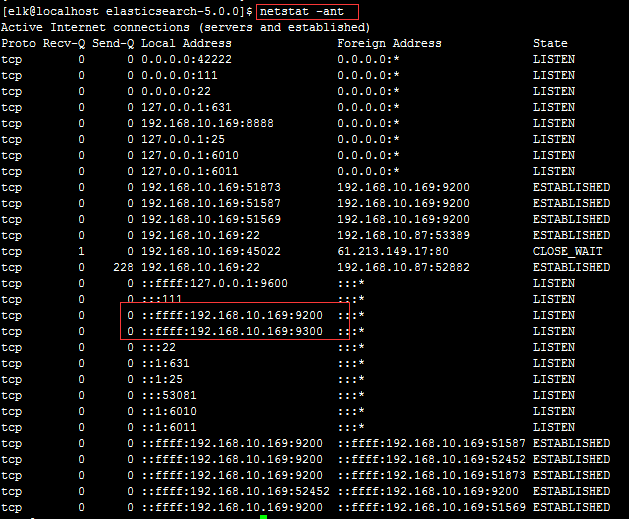
启动Elasticsearch

查看是否启动成功
用浏览器访问:http://192.168.10.169:9200
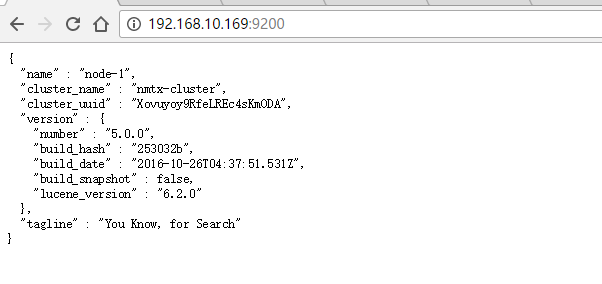
Elasticsearch安装完毕
安装logstash
logstash是ELK中负责收集和过滤日志的

编写配置文件如下:
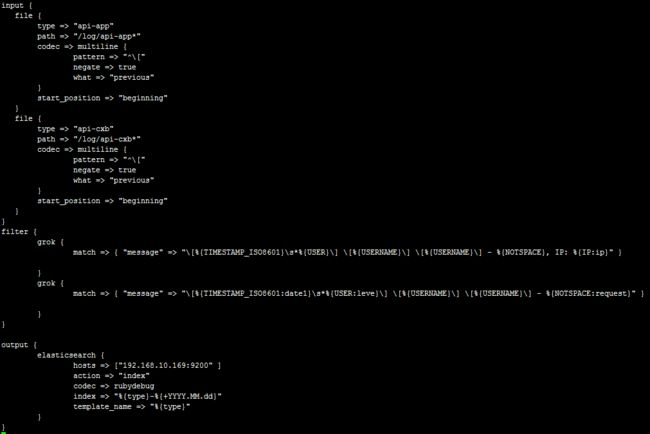
解释:
logstash的配置文件须包含三个内容:
input{}:此模块是负责收集日志,可以从文件读取、从redis读取或者开启端口让产生日志的业务系统直接写入到logstash
filter{}:此模块是负责过滤收集到的日志,并根据过滤后对日志定义显示字段
output{}:此模块是负责将过滤后的日志输出到elasticsearch或者文件、redis等
本环境采用从文件读取日志,业务系统产生日志的格式如下:
[2016-11-05 00:00:03,731 INFO] [http-nio-8094-exec-10] [filter.LogRequestFilter] - /merchant/get-supply-detail.shtml, IP: 121.35.185.117, [device-dpi = 414*736, version = 3.6, device-os = iOS8.4.1, timestamp = 1478275204, bundle = APYQ9WATKK98V2EC, device-network = WiFi, token = 393E38694471483CB3686EC77BABB496, device-model = iPhone, device-cpu = , sequence = 1478275204980, device-uuid = C52FF568-A447-4AFE-8AE8-4C9A54CED10C, sign = 0966a15c090fa6725d8e3a14e9ef98dc, request = {
"supply-id" : 192
}]
[2016-11-05 00:00:03,731 DEBUG] [http-nio-8094-exec-10] [filter.ValidateRequestFilter] - Unsigned: bundle=APYQ9WATKK98V2EC&device-cpu=&device-dpi=414*736&device-model=iPhone&device-network=WiFi&device-os=iOS8.4.1&device-uuid=C52FF568-A447-4AFE-8AE8-4C9A54CED10C&request={
"supply-id" : 192
output直接输出到Elasticsearch
本环境需处理两套业务系统的日志
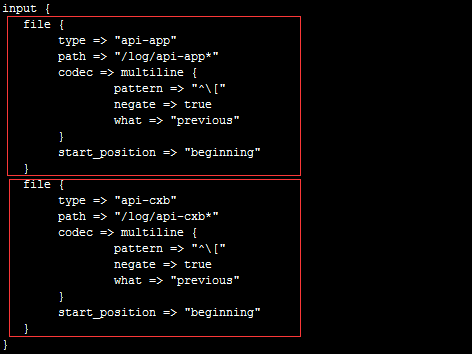
type:代表类型,其实就是将这个类型推送到Elasticsearch,方便后面的kibana进行分类搜索,一般直接命名业务系统的项目名
path:读取文件的路径
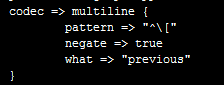
这个是代表日志报错时,将报错的换行归属于上一条message内容
start_position => "beginning"是代表从文件头部开始读取

filter{}中的grok是采用正则表达式来过滤日志,其中%{TIMESTAMP_ISO8601}代表一个内置获取2016-11-05 00:00:03,731时间的正则表达式的函数,%{TIMESTAMP_ISO8601:date1}代表将获取的值赋给date1,在kibana中可以体现出来
本环境有两条grok是代表,第一条不符合将执行第二条
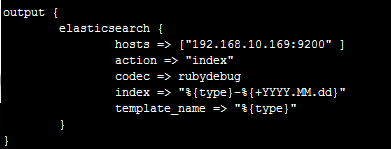
其中index是定义将过滤后的日志推送到Elasticsearch后存储的名字
%{type}是调用input中的type变量(函数)
启动logstash
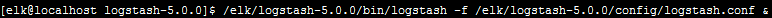

代表启动成功
安装kibana

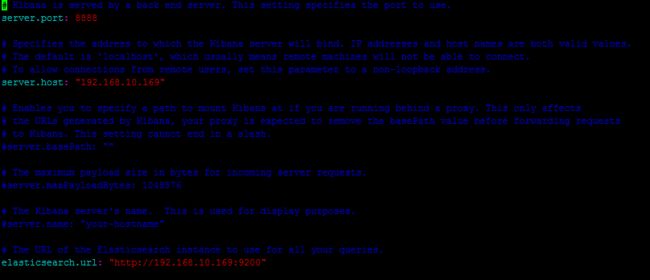
保存退出
启动kibana


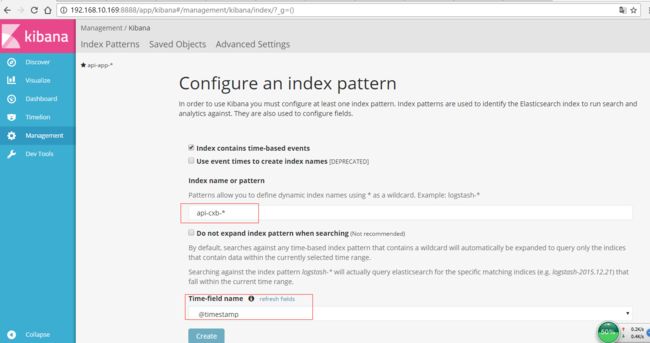
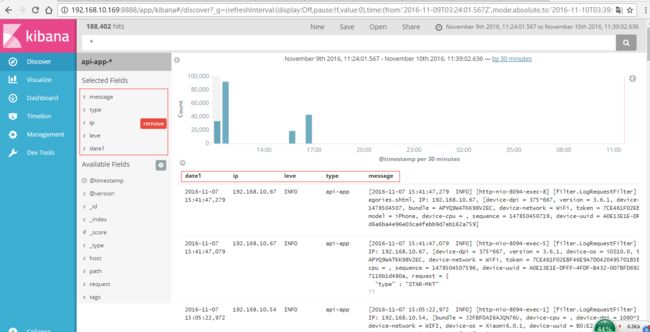
其中api-app-*和api-cxb-*从来的,*代表所有
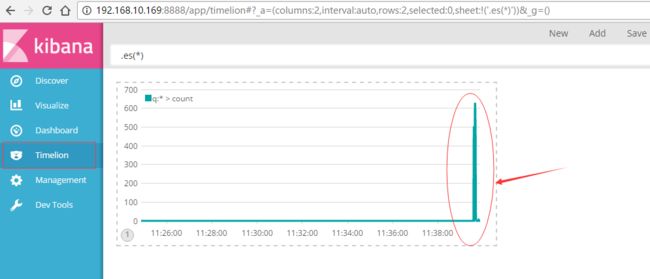
代表实时收集的日志条数
红色框内的就是在刚才filter过滤规则中定义的