Python迭代器与生成器
1、推导式
又称解析式。
推导式是可以从一 个数据序列构建另一个新的数据序列的结构体。
1)列表推导式
打印奇数
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
b = [x for x in a if x % 2 == 1]
c = [x ** 2 for x in a if x % 2 == 1]
print(b, c)
结果:
[1, 3, 5, 7, 9] [1, 9, 25, 49, 81]
打印30以内的所有能被3整除的数
print([i for i in range(1, 31) if i % 3 == 0])
嵌套循环
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva', 'Elven']]
print([name for lst in names for name in lst if name.count("e") == 2])
结果:
['Jefferson', 'Wesley', 'Steven', 'Jennifer']
过滤50以内能被3整除的数,如果这个数是奇数就返回0,偶数返回这个数本身
print([i if i % 2 == 0 else 0 for i in range(1, 51) if i % 3 == 0])
2)字典推导式
d1 = {"a": 1, "b": 2}
d2 = {v: k for k, v in d1.items()}
print(d2)
结果:
{1: 'a', 2: 'b'}
dic = {'a': 1, 'b': 2, 'c': 3, 'ab': 4}
li = {k: v for k, v in dic.items() if 'a' not in k}
print(li)
结果:
{'b': 2, 'c': 3}
3)集合推导式
和列表推导式一致,只是这里使用{},自带去重功能
l = [-1, 1, 1, 1, 2, 3]
print({i * i for i in l})
结果:
{1, 4, 9}
- 过滤掉长度小于3的字符串列表,并将剩下的转换成大写字母
q1 = ['a', 'ab', 'abc', 'abcd', 'abcde']
print([i.upper() for i in q1 if len(i) >= 3])
- 求(x,y)其中x是0-5之间的偶数,y是0-5之间的奇数组成的元组列表
x = [i for i in range(0, 6) if i % 2 == 0]
y = [i for i in range(0, 6) if i % 2 != 0]
print([(i, j) for i in x for j in y])
- 快速更换key和value
q3 = {'a': 10, 'b': 34}
print({v: k for k, v in q3.items()})
- 合并大小写对应的value值,将k统一成小写
期望 结果:{‘a’:5, ‘b’:9, ‘c’:3}
q4 = {'B': 3, 'a': 1, 'b': 6, 'c': 3, 'A': 4}
print({k.lower(): q4.get(k.lower(), 0) + q4.get(k.upper(), 0) for k in q4.keys()})
2、可迭代对象(Iterable)
定义:凡是可以返回一个迭代器的对象都可称之为可迭代对象。
判断:
- dir(对象)查看属性中是否存在__iter__方法
- from collections.abc import Iterable
print(isinstance(lst, Iterable))
分类:容器类型、打开状态的files,sockets、range
迭代器: 实现了__iter__ 和__next__ 的方法的都叫做迭代器
__iter__返回自身
__next__返回下一个值
for语法糖:先调用可迭代对象的__iter__ 方法,返回一个迭代器,然后再对迭代器调用__next__ 方法,知道最后一个退出
迭代器可以没有__iter__方法,但是要是for循环的话就要有__iter__方法,返回自身
lst = ['x', 'y', 1, 3, 4]
result = lst.__iter__() #调用__iter__()方法 返回迭代器
print(result.__next__()) #迭代器调用__next__()方法不断获取下一个值
print(result.__next__()) #超出范围就会报错
**懒加载:**需要的时候再生成,而列表一次性生成保存在内存中
from collections.abc import Iterable, Iterator
range_iter = iter(range(10))
print(isinstance(range_iter, Iterable)) # 判断是否是可迭代对象
print(isinstance(range_iter, Iterator)) # 判断是否是迭代器
3、迭代器(Iterator)
好处:迭代器就像一个懒加载的工厂惰性求值,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用
1) 生成无限序列
from itertools import count
c = count(start=10) # 指定从10开始,步长默认为1
c = count(10, 2) # 从10开始,步长为2 ,调用next可以生成无限序列
print(c, type(c))
print(next(c))
print(next(c))
print(next(c))
count(10, 2) <class 'itertools.count'>
10
12
14
2)从一个有限序列中生成无限序列
from itertools import cycle
import time
weeks = cycle(["Mon","Tue","Wed","Thu","Fri","Sat","Sun"])
print(weeks,type(weeks))
for i in weeks:
print(i)
time.sleep(1)
4、生成器(generator)
生成器一定是迭代器。懒加载,是迭代器更优雅的写法
不需要手动实现iter、next方法
生成器只有俩种写法:生成器表达式、生成器函数
1)生成器表达式
类似于列表推导式,使用()生成generator。没有手动实现__iter__和__next__方法
result = (x for x in range(1,31) if x % 3 == 0)
print(result,type(result))
结果:
<generator object <genexpr> at 0x000002F156454580>
<class 'generator'>
2)生成器函数
包含了yield关键字的函数
a、yeild关键字
把普通函数变成生成器
作用:
• 当生成器遇到一个yield时,会暂停运行生成器,返回yield后面的值。
• 当再次调用生成器的时候,会从刚才暂停的地方继续运行,直到下一个yield。
• yield关键字:保留中间算法,下次继续执行
def get_content():
x = 2
yield x
y = 3
yield y
z = 4
yield z
g = get_content()
print(g, dir(g))
print(next(g)) # 第一次执行next函数的时候 遇到yeild就退出,并且返回yeild后面携带的参数,还会记录位置
print(next(g))# 第二次执行的时候就会从上一次执行的地方继续执行
print(next(g))
b、简单的生成器
def func1():
count = 1
while 1:
yield count
count += 1
f = func1()
print(next(f))
print(next(f))
c、生成斐波拉契数列
写法一:
num = input("请输入数列长度:")
def func1():
a = 1
yield a
b = 1
yield b
while 1:
tmp = a + b
yield tmp
a = b
b = tmp
f = func1()
for i in range(int(num)):
print(next(f), end=" ")
写法二:
num = input("请输入数列长度:")
def func1():
a = 0
b = 1
while 1:
yield b
a, b = b, a+b
f = func1()
for i in range(int(num)):
print(next(f), end=" ")
d、生成器函数执行过程
- 当执行f=fib()返回的是一个生成器对象,此时函数体中的代码并不会执行,而是首先返回一个 iterable 对象!
- 只有显示或隐示地调用next的时候才会真正执行函数里面的代码
- 执行到语句 yield b 时,fab() 函数会返回yield后面(右边)的值,并记住当前执行的状态
- 下次调用next时,程序流会回到 yield b 的下一条语句继续执行
- 看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返 回当前的迭代值。
- 由此可以看出,生成器通过关键字 yield 不断的将迭代器返回到内存进行处理,而不会一次性 的将对象全部放入内存,从而节省内存空间。
3)生成器的好处
当你需要以迭代的方式去处理一个巨大的数据集合。比如:一个巨大的文件/一个复杂的数据库查 询等。
• 可以用更少地中间变量写流式代码
• 相比其它容器对象它更能节省内存
• 可以用更少的代码来实现相似的功能
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, "rb") as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的 缓冲区来不断读取文件的部分内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松 实现文件读取。
4)send
def counter(start_at=0):
count = start_at
while True:
val = (yield count)# send 发送一个数据会赋值给val,next获取时,val为None
if val is not None:
count = val
else:
count += 1
count = counter(5)
print(type(count))
print(count.__next__())
print(count.send(9))
print(count.__next__())
count.close() # 关闭生成器,后就不能调用next()
print(count.__next__())
5) yield from
后面必须返回可迭代对象
def g1(x):
yield range(x)
def g2(x):
yield from range(x)
it1 = g1(5) #生成器1
it2 = g2(5) #生成器2
print([x for x in it1])
print([x for x in it2])
结果:
[range(0, 5)]
[0, 1, 2, 3, 4]
5、可迭代对象、迭代器、生成器
可迭代对象iterable
迭代器 iterator
生成器 generator
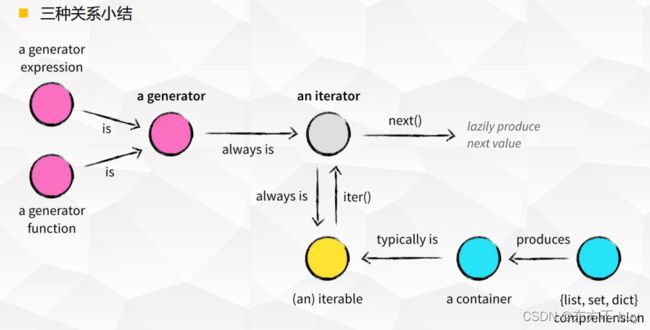
6、总结
-
如何判断一个对象是可迭代对象,迭代器对象或生成器 ?
实现了iter方法的就是可迭代对象,同时实现了next方法的就是迭代器对象。
包含了yeild关键字的迭代器就是生成器 -
迭代器与生成器的区别 ?
生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁
生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当生成器终结时,还会自动抛出 StopIteration 异常。
生成器也是一种迭代器,但是只能迭代一次,因为只保存一次值 -
可迭代对象与迭代器的区别?
实现了iter方法的就是可迭代对象,同时实现了next方法的就是迭代器对象。 -
如何定义一个生成器 ?
类似于列表推导式,使用()生成generator。
定义包含yield关键字的函数 -
如何获取可迭代对象、迭代器与生成器中的数据?
可迭代对象 :for循环
迭代器、生成器:调用__next__()方法