第八章 分布式相关算法和理论
8.1 分布式相关理论和算法 8.2 分布式之zookeeper 8.3 SEATA分布式事务原理
8.1 分布式相关理论和算法
分布式负载均衡算法
1 轮询算法
2 权重轮询算法
3 一致性哈希
4 最少连接数
5 最快相应时间
等
都是字面意思不解释了
分布式ID算法
1 UUID (32位数的16进制数字,太长太占空间,淘汰)
2 号段模式
3 滴滴 Tinyid
4 雪花算法
5 Redis实现
6 分布式 zookeeper ID生成
7 分片表主键自增
等
分片表主键自增
可设置起始值,增长值不同来配置
但是每加如新机器,全部配置都得改动
每次只能向db获取一个id,性能也较差
号段模式原理
批量提前提供ID,当应用时一一给具体业务分配ID
如提前提供0-1000一段ID,数据库以乐观锁形式记录号段长度和当前位置,
批量拿ID同时也能减小数据库压力
Tinyid原理
在号段模式基础上,双号段缓存优化。
随机从两个db上拿ID,一个db生成奇数ID,一个偶数ID,保证不会拿到重复值
雪花算法原理
64 bit long数字作为 ID
1 bit 无意义(统一0为正数)
41 bit 时间戳 (可表示69年时间)
5 bit 机房ID
5 bit 机器ID (机房ID+机器ID 可部署1024台机器)
12 bit 序号 (相同1毫秒内的第几个请求,id请求累加1序号)
经典基础理论基础
CAP
一致性(数据)
可用性(业务程序响应等)
容错分区(网络)
BASE
基本可用 (业务基本可用,支持分区失败)
软状态 (允许数据延迟)
最终一致性
分布式事务
TCC 截取此文章
TCC操作:
Try阶段,尝试执行业务,完成所有业务的检查,实现一致性;预留必
须的业务资源,实现准隔离性。
Confirm阶段:真正的去执行业务,不做任何检查,仅适用Try阶段预留的业务资
源,Confirm操作还要满足幂等性。
Cancel阶段:取消执行业务,释放Try阶段预留的业务资源,Cancel操作要满足幂
等性。
2PC (几乎所有主从中间件用到的方法,如zookeeper)
第三方等待所有程序预提交,收到一半以上的确认ACK信号则大家一起最终执行,
否则回滚
MQ
生产者执行时会修改发布的名称,让订阅的消费者无法消费。通过自我判断成功
执行后修改回原先名称,让订阅消费者继续消费。具体将来kafka章节再说
分布式一致性协议
Paxos算法 第一篇例子介绍的蛮好的
发布/接受/学习
该算法主要是快速度选出老大
1 当接受者第一次遇到id 100的发布者1时候,接受者将变成他铁粉不再改动支持者
并且id小于100的发布者理都不理,这样会使得选举很快。
2 当大于id100比如id200的发布者2给那个接受者拉票时,接受者依然支持发布者1
,并且id小于200的所有发布者理都不理。这样选举速度更快了
3 当有发布者拿到一半以上铁粉就成为老大了,其他发布者也得跟随这个老大
RAFT算法
主从,详情看下面zk的ZAB算法,其实差不太多
8.2 分布式之zookeeper
定义
一个拥有文件系统特点的数据库
处理数据一致性问题的分布式数据库
具有发布和订阅功能的分布式数据库(watch机制)
集群配置
1 vim 配置 zoo.cfg文件
clientPort xxxx //配置端口
server.1 = xxx
server.2 = xxx //配置集群ip和port
2 启动集群
bin/zkServer.sh start//zk会自动选举leader和follower
3 客户端接入zk集群
zk集群下任意一节点bin目录下,启动一个客户端接入即可
./zkCli.sh -server [client ip port]
zk常用命令
没参考价值,略
Dubbo下zk注册中心原理
图片不知道怎么正过来,我也很无奈

ZAB协议
领导者选举,过半机制,2pc数据同步等共同组成ZAB协议
zk领导选举
1 一开始大家都给自己投票
2 彼此之间互相比较zxid(即事务id),谁zxid大则这轮改票为大的一方。如果zxid
一致则看谁myid(自己的id)大为准
3 当一个节点得到超过一半数量的投票,则当选leader
领导选举结束后又有新节点来,如果新节点zxid大于leader的zxid,则新节点需
要回滚,新节点必须和leader节点xzid同步,然后加入集群
当leader挂掉,触发领导者选举
当有follwer挂掉导致领导者发现跟随follower未超过一半,leader停止对外服务,
仍需要重新领导者选举
zk如何处理数据
1 事务日志按照顺序添加
2 更新内存 DateTree (从内存中拿数据,不走磁盘,速度更快)
zk如何保证数据一致性
2pc事务一致性模式
1 leader生成事务
2 预提交
3 所有follower生成事务
4 ack返回
5 收到一半以上follower的ack则提交,否则回滚
6 提交成功,数据写入内存DateTree
zk和redis分布式锁区别
1 zk有节点的watch机制,注册个监听器,不需要一直主动尝试获取锁,性能开销小
redis需要不停主动尝试获取锁,性能开销较大
2 redis拿到锁的服务器挂了需要等到超时时间才释放锁,zk是临时节点拿锁,当服
务器挂了,立刻就会删除临时节点并且释放锁
8.3 SEATA分布式事务原理
场景
实际业务中,我们会遇到,订单系统代码层出错,执行回滚。但是数据库依然添加
了相关数据。为什么呢,因为库存系统和订单系统是分开的。我们只回滚了订单
系统,却没有回滚库存系统。所以分布式事务就产生了。
所以我们希望订单系统能够通知库存系统一起跟着回滚
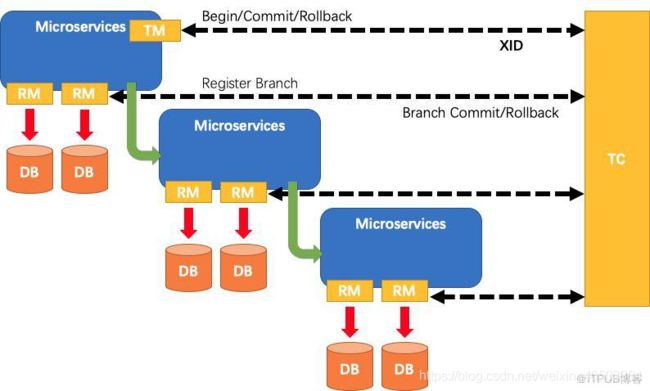
架构
RM(资源管理器) TM(事务管理器) TC(全局协调者)
RM 事务参与者
TM 全局事务管理者
TC:事务的协调者。保存全局事务,分支事务,全局锁等记录,然后通知各个RM回
滚或提交。
找的网图
简单实现思路
1 开启全局事务
创建map
2 注册分支事务
transactionIdMap.get(groupId).add(transactionId)
如果transactionType为rollback则groupId下全部回滚
3 提交全局事务
sentMsg(groupId,"commit")
seata源码基本思路
seata中维护三个表,branch_table/global_table/lock_table
branch_table维护了注册的分支事务信息
global_table维护了注册的全局事务信息
lock_table主要记录业务表在被哪个写事务执行上锁,其他事务不能冲突执行
seata也有一个undo_log表,根据事务id(xid)以Json形式保存image镜像到
undo_log内,将来可以根据镜像进行2pc回滚
1 seata首先底层实现GlobalTranscationScanner.class的注解,这个注解类
implement AbstractAutoProxyCreator(SpringAOP顶级抽象父类接口) 和
InitializingBean(初始化RMClient和TMClient)
2 判断是注解调用还是TCC调用等等,AOP生成代理类,内部织
入GlobalTransactionalInterceptor的注解拦截器
3 根据begin变量判断是全局事务还是分支事务,TM和TC开启信息交互
A 全局事务
1 getCurrentOrCreate创建TM
2 获取全局事务信息
3 开启全局事务beginTransaction(txInfo,tx);
4 调用JDBC往global_table内写入全局事务数据
B 分支事务
beforeImage原先镜像
根据增删改查不同sql创建不同执行器,执行execute方法(需要从
lock_table中拿锁,如果拿不到30ms拿一次,拿10次自旋拿锁,一直拿不
到回滚到beforeImage)
afterImage(生成执行后镜像)
prepareUndoLog(beforeImage,afterImage) 完整镜像保存到undo_log
表内,可以供将来回滚使用
commit提交,branch_table写入分支事务信息,与TC信息交互
4 提交本地事务并上传成功或失败状态到TC
5 如果有本地事务提交失败,全局事务链下所有事务全部回滚
seata原理优化
这篇讲的又全又好
个人对这篇文章总结
seata支持很多种事务模式,如AT,TCC等等
AT以数据库为一个资源,本地事务提交时会去注册一个分支事务
TCC则以发送方,消费方接口为一个资源
TCC模式下
1 TCC通过try隔离资源进行并发控制
2 分支事务记录与业务数据在相同的库中,减少TC注册
3 拿锁try隔离资源后则已经算执行成功释放锁,confirm阶段异步慢慢执行,不需要上锁阻塞
简单版seata实现
//客户端真正应用
@Service
public class DemoService{
@Autowired
DemoDao demoDao;
@GlobalTransaction(isStart=true) //我们自己实现的SEATA注解
@Transactional
public void test(){
//假设Dubbo下,demoDao,demoDao2很多个demoDao不在同一个系统
demoDao.inset("data1");
}
}
1 实现@GlobalTransaction(isStart=true)注解
@Target(~)
@Retention(~)
public @interface GlobalTransaction{
boolean isStart() default false;//控制是否是全局事务,默认不是
}
2 加切面
@Aspect //对应Seata拦截器
@Component
public class GlobalTransactionAspect implements Ordered{
@Around("@annoation(~.annoation.GlobalTransaction)")//所有加了这个注解的都要拦截走这个切面
public void invoke(ProceedigJoinPoint point){
before逻辑:
//拿point方法,拿GlobalTransaction对象,
//如果isStart是true,表示这是全局事务,开启创建全局事务组 GlobalTransactionManager.createGroup()
point.proceed(); //spring切面下@Transaction切面真正方法
after逻辑
//创建注册事务分支到事务组 TM GlobalTransactionalManager下方法
//如果proceed成功,创建的事务分支的lbTransaction.Type为提交属性,不成功设为回滚属性
//如果状态回滚,TC通知全局事务组下所有事务全部回滚
}
}
RM资源管理层(提交本地事务)
public class LbConnection implements Connection{
通过构造方法接收Spring实现的Connection,利用它完成大多数重写方法,
我们只需要改变提交方法逻辑
Connection connection;
LbTransaction lbTransaction;
@Override
~commit(){
new Thread{//不阻塞后面的注册
lbTransaction的线程wait;
//等待NettyClientHandler设置transactionType然后执行本地提交或回滚
if(lbTransaction.transactionType为commit本地提交){
connection.commit();
}else{
connection.rollback();
}
}
}
}
对Spring底层*javax.sql.DataSource.getConnection(...)加切面
@Around(...)
~ proceed ~{
Connection connection = point.proceed() //Spring本身实现类
return new LbConnection(connection); //SPring会使用我们自己重写的实现类
}
事务管理者TM
public class GlobalTransactionManager{
NettyClient nettyClient;
ThreadLocal<LbTransaction> current = new ~;
ThreadLocal<String> currentGroupId = new ~;
Map<String,LbTransaction> LB_TRANSACTION_MAP = new ~;
//创建全局事务组
public String getOrCreateGroup{
1 利用分布式ID算法创建一个唯一ID GroupId
2 以Json形式 nettyClient.send(JSONObject)发送给NettyServer
的NettyClientHandler保存事务信息
3 currentGroupId.set(groupId);
}
//注册全局事务组
public ~~~~
设置事务Type,事务Id,GroupId等然后以Json形式传给NettyServer
//提交全局事务组
//创建分支事务
public ~~~
创建lbTransaction,以Json形式 nettyClient.send(JSONObject)发送
给NettyServer
//注册分支事务
public ~~~~
map.put(groupId,lbTransaction)
}
public class LbTransaction{
public String transactionId;
public TransactionType transactionType;
构造方法 ~
}
public class NettyClientHandler{
~ channelRead(~){
LbTransaction transaction = GlobalTransactionManager.getlbTransaction(groupId);
如果GlobalTransactionAspect下point.proceed执行成功,这里会
传入成功指令,设置transaction.transactionType为commit。然后
我们配置的RM下LbConnection会执行commit方法本地提交,否则本地回滚
}
}