【YOLO系列】论文笔记————YOLOv1
近期一直在做基于YOLOv3模型的烟雾火灾检测项目。虽然其模型能够跑起来了,但是对它的原理和参数含义并不是很理解,所以打算花费一些时间,从YOLO系列论文入手,彻头彻尾的把它搞个明白。这样做虽然会浪费一些时间,但是我相信会对以后有很大的帮助,若再做类似的项目,会有事半功倍的效果!!
论文标题:《You Only Look Once: Unified, Real-Time Object Detection》
论文地址:https://arxiv.org/pdf/1506.02640.pdf
一、建模
v1是yolo系列的开山之作,以简洁的网络结构,简单的复现过程(详细的教程)而受到广大爱好者的追捧。
yolov1奠定了yolo系列算法“分而治之”的基调。
------模型流程,将图片分割成S*S的网格,如下图所示:
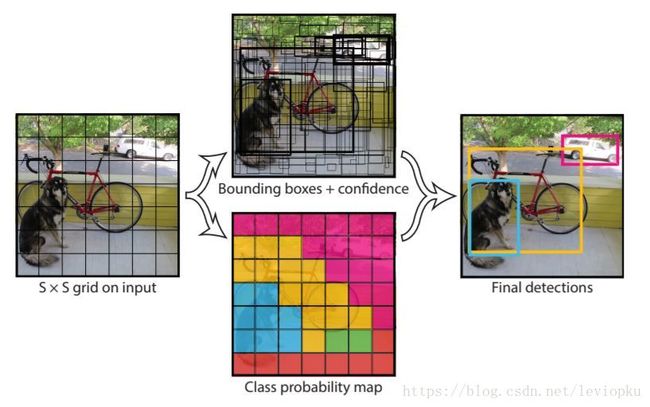
1)输入图片被划分成7*7个单元格,每个单元格独立作检测。注意:这里很容易被误导——每个单元格的视野有限而且很可能只有局部特征,这样就很难理解yolo为何能检测比grid_cell大很多的物体。其实,yolo的做法并不是把每个单独的网格作为输入feed到模型,在inference的过程中,网格只是物体中心点位置的划分之用,并不是对图片进行切片,不会让网格脱离整体的关系。
2)每个网格预测B个bounding boxes(bounding boxes包括置信度分数confidence和其坐标或者偏置(x,y,w,h),(x,y)为中心坐标,w为该box的宽,h为高,confidence表示预测的box与任意真实box的IOU;)
confidence= 
3)每个网格还会预测C个条件概率,表示该网络包含目标的概率;
4)由以上可知,类出现在盒子的概率与预测的目标框适合真实目标的程度为:
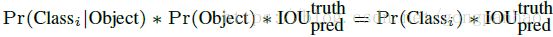
5)根据以上流程,如下的网络只需预测一个S*S*((4+1)+C)的向量,该向量用于最终回归框的生成,以及训练时损失函数的计算。
二、网络模型
网络模型受到GoogleLeNet启发,包含24个卷积层和2个全连接层。

上图为YOLOv1的结构图,通过结构图可以轻易知道前向传播的计算过程,是很便于读者理解的。v1的输出是一个7*7*30的张量,7*7表示把图片划分成7*7的网格,每一个小单元的另一个维度等于30=(2*5+20)。代表能预测2个框的5个参数(x,y,w,h,score)和20个类别。
| SxSx(B∗5+C) = 7x7x(2*5 + 20) |
|---|
| SxS表示网格数量,B表示每个网格生成框的个数,C表示能检测识别的种类。 |
可以看出输出张量的深度影响yolo_v1能检测目标的种类。v1的输出深度只有30,意味着每个单元格只能预测两个框(而且只认识20类物体),这对于密集型目标检测和小物体检测都不能很好适用。
三、训练
1)预训练模型:利用如上网络框架的前20个卷积层+1平均池化层+1全连接层组成分类框架和ImageNet 1000-class比赛数据集训练大约一周的时间,并且在ImageNet2012验证集上single crop top-5准确率达到88%;其训练集图片设计为224*224(因为后期用于检测时需要细粒度视觉信息),YOLO网络训练集图片大小的一半;
2)YOLO的网络框架是预训练模型框架后添加4个卷积层和2个全连接层,在训练时随机初始化;(实验发现,在预训练模型后添加卷积层和全连接层能够提高性能。)
3)最终层激活函数为linear(y=x);其他所有层激活函数为leaky;
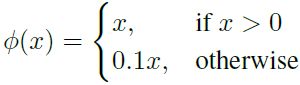
4)预测输出:class probabilities和BBs坐标((x,y)为中心坐标的偏置,处于0-1;w,h为BBs的宽和高,利用图像的宽和高正则化为0-1之间);
5)损失优化时,(1)由于每张图片中的许多网格中不包含目标,使得其计算的置信度分数趋于0,如果误差和中各种误差的权重相等,则会导致模型的不稳定性以及在训练过程中提前出现分歧;其处理方法为使包含目标的网格拥有大的梯度,也就是说,其误差在误差和中有一个大的比重;所以在最终损失中,包含目标的boundingbox的损失权重设置为5,不包含的设置为0.5;(2)为了解决小boundingbox的小偏差比大BBs的重要,模型预测BBs的宽和高的平方根(由于预测的宽和高处于0到1之间,平方根属于比宽和高大的值,在计算损失时,就缓和了小BBs对小偏差的敏感程度)已达到目的;
6)损失函数
说明,对为什么这样计算损失的理解:每个网格期望有一个最优目标框(具有该网格预测的目标框与真实目标框的最大IOU值)。在计算损失时,认为该网格预测的置信度分数和该网格预测目标框与真实目标框的最大IOU值有关。置信度的损失是利用每个Cell的最优目标框与ground truth的IOU作为监督信息计算(IOU为0时,就证明无目标,就会计算无目标对象的置信度损失);当Cell在ground truth内时,计算当前cell的分类损失;坐标损失只计算最优目标框的,包括中心坐标和该框的宽和高的平方根的损失;
7)数据集:PASCAL VOC 2007和2012的训练集和验证集上训练;VOC2007的测试集上测试;
8)训练参数:135 epochs;momentum 0.9;decay 0.0005;学习率:前75epochs:开始时为10^-3,然后慢慢的变为10^-2,开始时的高学习率会因为模型的不稳定使得模型分歧;接下来的30epochs为10^-3;最后的30epochs为10^-4;
知识点积累:a、epoch代表过完一次所有的训练数据;b、momentum,动量来源于牛顿定律,基本思想是为了找到最优加入“惯性”的影响,当误差曲面中存在平坦区域,SGD就可以更快的学习;c、decay,上述decay指的是权值训练过程中,正则化权值的衰减系数(参照机器学习的正则化L1、L2); 动量的公式
动量的公式
d、防止过拟合采取的措施:(1)dropout,0.5;(2)扩展数据集:对随机缩放和翻转的比例是原始图片大小的20%,并随机调整图片的曝光度和饱和度,调节因子为1.5;
四、模型分析
1)网格(grid cell)设计boundingbox的预测中增加了其空间的多样性,无论训练以何种方式计算损失,但在预测时,它能够把大的目标或者网格中有相邻边界的目标在多个网格中进行多次预测,使得这些目标能够被很好的预测;非极大值抑制的方法使mAP增加了1-2个百分点;
2)YOLO的局限性:(1)强加在boundingbox上空间约束(每个网格只能预测两个boxes和一个类)限制了模型预测相邻目标的box的数量;模型不能够很好的预测成群出现的小目标;(2)模型所能预测的box的比例和大小有限(所能预测的比例和大小只能是训练数据中出现的);预测box的特征比较粗糙(训练经历了多次下采样);(3)损失函数的近似性(处理小box和大box的误差的方法相同,没有充分考虑到小误差对于小box的IOU比大box的大,使得主要错误来源于定位错误);
五、与其他检测系统的比较
六、实验

在VOC2007上的错误分析:Correct: correct class and IOU > 0.5; Localization: correct class, 0.1 < IOU <0.5; Similar: class is similar, IOU > 0.1;Other: class is wrong, IOU > 0.1; Background: IOU <0.1 for any object;

--Fast R-CNN与YOLO的联合使用

在VOC2012上的结果

--艺术作品中人的检测


参考:
https://arxiv.org/pdf/1506.02640.pdf
https://blog.csdn.net/gongpanhao/article/details/79785351
https://blog.csdn.net/leviopku/article/details/82660381