面试官让我写strlen函数?|详解字符串函数与内存函数【C语言/进阶】
文章目录
- 前言
- 1. 字符串函数
-
- 1.1 strlen
- 1.2 strcpy
- 1.3 strcat
- 1.4 strcmp
- 1.5 strnpy
- 1.6 strncat
- 1.7 strncmp
- 1.8 strstr
- 1.9 strtok
- 1.9 strerror
- 1.11 memcpy
- 1.12 **memmove**
- 1.13 memcmp
- 1.14 memset
- 2. 字符函数
- 结语
前言
请原谅我的文章跟雅鲁藏布江一样长,但跟它一样,蕴藏着宝藏。
下面重点介绍处理字符和字符串的库函数的使用和注意事项
1. 字符串函数
注意:
- NULL是空指针,它是定义在stdio.h头文件中的宏,值为0
- NUL和null一般情况下指的是\0(图片里有出现,翻译为终止空字符)
1.1 strlen
size_t strlen ( const char * str );

要点
-
字符串已经’\0’ 作为结束标志,strlen函数返回的是在字符串中’\0’ 前面出现的字符个数(不包含’\0’ )
-
参数指向的字符串必须要以’\0’ 结束
//strlen统计的是第一个'\0'前的元素的个数 int main() { char a[] = "abc\0defg"; printf("%d\n", strlen(a)); return 0; }

-
注意函数的返回值数据类型为size_t,是unsigned int型。Why?长度不可能为负。在这里知道它是unsigned 型即可(64位可能为unsigned long int)。
#includeint main() { const char*str1 = "abcdef"; const char*str2 = "abc"; if(strlen(str2)-strlen(str1)>0) { printf("str2>str1\n"); } else { printf("srt1>str2\n"); } return 0; } 如果它的返回值不是unsigned int型,而是int型,结果是哪个呢?
-
模拟实现strlen函数
-
上面我们知道,strlen函数是统计第一个\0之前的元素个数,那么根据此原理,可以通过循环实现该功能。
注:当我们不希望函数的参数即源字符串不被修改,需要用const修饰形参。assert(断言),作为初学者,我们应该使用它以避免可能发生传入空指针的情况。
//1. 常规 //2. 递归//不创建临时变量 //3. 指针-指针 #include#include size_t my_strlen(const char* str) { assert(str);//断言:提醒用户传参为非空指针 //等价于assert(str != NULL); //NULL在stdio.h库中,它是一个宏,值为0 int count = 0;//计数器 while (*str)//'\0'的ASCII值为0 { count++; str++;//指针后移 } return count; } int main() { char a[] = "abcdefg"; printf("%d\n", my_strlen(a)); return 0; } -
或许有一天,面试官会问你:那有没有一种方法,可以不通过创建临时变量得到字符串的长度呢?不通过临时变量,那就是只通过str这个指针变量自己运算,当达到某种条件,返回1/0,我们想到递归。
#include#include size_t my_strlen(const char* str) { assert(str); //每当指针指向的不是\0,返回1+my_strlen(指向下一个),直到遇到\0,返回0 if (*str) { return 1+ my_strlen(++str);//注意是前置++哦 } return 0; } int main() { char a[] = "abcdefg"; printf("%d\n", my_strlen(a)); return 0; } -
学习指针的时候我们知道,指针-指针=两指针之间的元素个数。我们可以用让一个指针指向起始位置,然后让另一个指针移动到\0的位置,返回指针之差即为字符串长度
注意:在保存初始位置时,变量start的类型要和形参一致,因为我们用const修饰变量,是为了更安全地使用它,假若将这个安全的变量交给一个不安全( 没有const修饰)的变量,它的内存访问权限就被放大了,也就是说它又不安全了(相当于形参的const白修饰了)。后面也有同样的例子。
#include#include size_t my_strlen(const char* str) { assert(str); const char* start = str;//保存初始位置 while (*str) { str++; } return str - start;//返回元素个数 } int main() { char a[] = "abcdefg"; printf("%d\n", my_strlen(a)); return 0; }
-
1.2 strcpy
char* strcpy(char * destination, const char * source );

要点
-
源字符串必须以’\0’ 结束
-
最后将源字符串中的’\0’ 拷贝到目标空间
-
目标空间必须足够大,以确保能存放源字符串。因为strcpy不会为程序员检查。
-
目标空间必须可修改。什么意思呢?形参中只有源字符串被const修饰,表示它不可修改;相反地,目标字符串不能被const修饰,表示它是将被修改的。
-
模拟实现strcpy函数
//化简代码、链式访问、高质量C/C++编程 #include#include char* my_strcpy(char* dest, const char* src) { char *ret = dest;//保存目标字符串的地址 assert(dest ); assert(src ); while (*src) { *dest = *src; dest++; src++; } //将src'\0'之前的元素赋给dest *dest = *src;//将src的'\0'赋给dest return ret;//返回目标字符串的地址 } int main() { char* str1 = "abcdef"; char arr[20] ="XXXXXXXXXXXXX"; printf("%s\n", my_strcpy(arr, str1)); return 0; } -
化简代码:在while循环中,我们可以将指针移动和赋值放在一个语句中
while (*src) { *dest++ = *src++; } *dest++ = *src++;//将src的'\0'赋给dest -
括号内判断的是\0,而*dest++ = *src++这个赋值表达式的结果是被赋值的那个值,所以可以将循环外的语句放在括号里面。
while (*dest++ = *src++) //这里最后已经将src的'\0'赋给dest了 { ; } //';' 表示这是一个空语句,它什么都不干,这是合法的
-
1.3 strcat
char * strcat ( char * destination, const char * source );

要点
-
源字符串必须以’\0’ 结束。
-
目标空间必须有足够的大,能容纳下源字符串的内容。
-
目标空间必须可修改。
//用例如下 int main() { char arr1[20] = "hello "; printf("%s\n", strcat(arr1, "world")); return 0; } //arr1的内容:"hello world\0" //实际上打印的结果为:hello world -
模拟实现strcat函数
思路:用一个指针移动到目标字符串的\0位置,然后以这个位置开始,将源字符串的内容追加,其实也就是strcpy的模拟实现。
char* my_strcat(char* dest, const char* src) { char* ret = dest;//保存目标字符串的地址 assert(dest); assert(src); //1. 找目标字符串的'\0' while (*dest) { dest++; } //2. 拷贝数据,同strcpy while (*dest++ = *src++) { ; } return ret; } int main() { char arr1[20] = "hello "; printf("%s\n", my_strcat(arr1, "world")); return 0; } -
字符串自己给自己追加,如何?
int main() { char arr1[20] = "hello "; printf("%s\n", my_strcat(arr1, arr1)); return 0; } //程序跑不起来,因为当源字符串copy到目标字符串时,\0总是被覆盖 //以至于一直找不到\0,造成越界访问,程序崩溃
1.4 strcmp
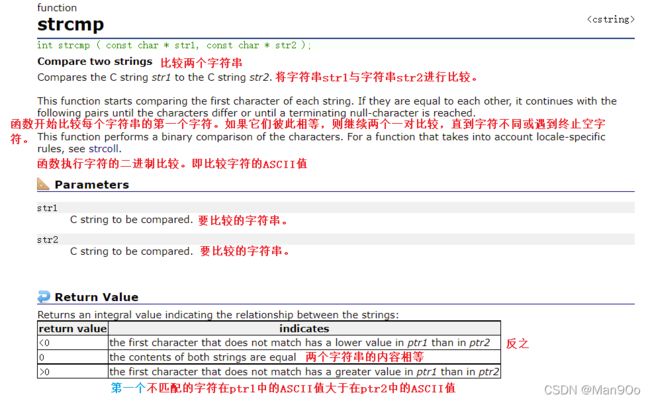
int strcmp ( const char * str1, const char * str2 );
要点
-
标准规定(返回值):
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字注意:在VS编译器中,返回值分别是1、0、-1
-
那么如何判断两个字符串?
//用例 #includeint main() { char a[] = "abcde"; char b[] = "abcdz"; printf("%d\n", strcmp(a, b)); return 0; } //结果为-1 -
模拟实现strcmp
思路:将两个指针的值(字符的ASCII值)比较,如果相同就同时往前走,直到遇到\0为止两者都相等,返回0;如果一开始或中途就不相等,若两者ASCII差值为负数,返回-1,反之则返回1
#include#include int my_strcmp(const char* str1, const char* str2) { //函数没有对两个字符串的内容修改,为保护两者在内存中的安全 //都用const修饰 assert(str1); assert(str2); while (*str1 == *str2) { if (*str1 == '\0') //if语句在前在后都可以, //因为当指向最后一个元素时,后面是\0 while判断也能进来 { return 0; } str1++; str2++; } //如果没有进入if语句则说明两者不相等 //此时两个指针已经指向了不同的字符 if (*str1 > *str2) return 1; else return -1; } int main() { char a[] = "abcde"; char b[] = "abcdz"; printf("%d\n", my_strcmp(a, b)); return 0; } //结果为-1 这样的函数还是不够完美,因为返回值在不同编译器是不同的,将返回值改成大于零或小于零的值更有普适性,可以直接返回两者的差值。
#include#include int my_strcmp(const char* str1, const char* str2) { assert(str1); assert(str2); while (*str1 == *str2) { if (*str1 == '\0') return 0; str1++; str2++; } return *str1 - *str2; } int main() { char a[] = "abcde"; char b[] = "abcdz"; printf("%d\n", my_strcmp(a, b)); return 0; } //结果为-21
1.5 strnpy
char * strncpy ( char * destination, const char * source, size_t num );

它是strcpy函数的安全版本,因为strcpy不会替程序员检查目标字符串的空间是否足以提供源字符串复制,因此多了一个参数,复制字符的个数num。其实在了解它之后,会觉得其实它也不那么安全,num的主要作用我认为是提醒程序员在使用它时能注意这个问题。个人理解这个多出来的n可能是num的意思。
要点
-
拷贝num个字符从源字符串到目标空间。
-
如果源字符串的长度小于num,则拷贝完源字符串之后,在目标字符串的后面追加0直到修改次数达到num为止。
//示例 #include#include int main() { char a[] = "abcd"; printf("%s\n", strncpy(a, "qwer",3)); return 0; } //结果为qwed 假若num的值大于要复制的源字符串的长度,剩余的空间

-
模拟实现strncpy
思路:此函数有“复制不够0来凑”的功能,把num当作计数器,分情况决定要不要添0。除此之外,和strcpy的模拟实现相同。
#include#include char* my_strncpy(char* dest, const char* src, size_t num) { char* ret = dest;//记录目标字符串地址 assert(dest); assert(src); //先不管三七二十一, //两种情况可以先复制,然后通过num再看是否还有位置 while (num-- && (*dest++ = *src++)) { //1. num=len,直接将\0之前的字符复制到dest中,相当于strcpy ; //2. num

注意:第一个while循环中的num的左右位置(&&前面为假时,直接跳出循环)、以及是否在循环体内自减1、第二个while循环的`--`前置或后置都会对结果产生影响,需要根据实际情况进行匹配。
1.6 strncat
char * strncat ( char * destination, const char * source, size_t num );

要点
同strcat,只不过多了一个参数num。
用法
参照strncpy:
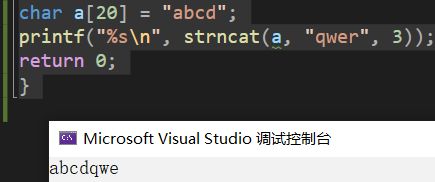
int main()
{
char a[20] = "abcd";
printf("%s\n", strncat(a, "qwer", 3));
return 0;
}
int main()
{
char a[20] = "abcdxxxxxx\0xxxxxxx";
printf("%s\n", strncat(a, "qwer", 6));
return 0;
}

至此我们可以了解它的原理:在目标字符串第一个\0处将源字符串的前num个元素copy并赋值,最后添加\0。
下面模拟实现strncat:
思路:用指针找到目标字符串\0的位置,然后将源字符串的前num个元素赋值,num当作计数器。
#include
1.7 strncmp
int strncmp ( const char * str1, const char * str2, size_t num );

要点同strcmp,用法同上
用例
int main()
{
char arr1[] = "hello";
printf("%d\n", strncmp(arr1, "helo", 3));
return 0;
}

int main()
{
char arr1[] = "hello";
printf("%d\n", strncmp(arr1, "helo", 4));
return 0;
}

通过用例,我们可以知道它的原理。在前面几个模拟实现的例子的基础上,请读者自己思考是怎样实现的。
由于模拟实现strncmp更加麻烦,需要更多知识,作者目前还不具备这样的能力。但实现它的思想是不变的。这里附上VS编译器的参考代码。(路径:(VS所在的磁盘)E:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\crt\src)
int __cdecl strncmp
(
const char *first,
const char *last,
size_t count
)
{
size_t x = 0;
if (!count)
{
return 0;
}
/*
* This explicit guard needed to deal correctly with boundary
* cases: strings shorter than 4 bytes and strings longer than
* UINT_MAX-4 bytes .
*/
if( count >= 4 )
{
/* unroll by four */
for (; x < count-4; x+=4)
{
first+=4;
last +=4;
if (*(first-4) == 0 || *(first-4) != *(last-4))
{
return(*(unsigned char *)(first-4) - *(unsigned char *)(last-4));
}
if (*(first-3) == 0 || *(first-3) != *(last-3))
{
return(*(unsigned char *)(first-3) - *(unsigned char *)(last-3));
}
if (*(first-2) == 0 || *(first-2) != *(last-2))
{
return(*(unsigned char *)(first-2) - *(unsigned char *)(last-2));
}
if (*(first-1) == 0 || *(first-1) != *(last-1))
{
return(*(unsigned char *)(first-1) - *(unsigned char *)(last-1));
}
}
}
/* residual loop */
for (; x < count; x++)
{
if (*first == 0 || *first != *last)
{
return(*(unsigned char *)first - *(unsigned char *)last);
}
first+=1;
last+=1;
}
return 0;
}
1.8 strstr
char * strstr ( const char *str1, const char * str2);

用例
#include#include
由用例可知:如果找到子字符串,则返回第一个子字符串出现的起始位置,否则返回空指针。
模拟实现strstr
思路:两个指针ab分别维护两个字符串,以要找的字符串find为准,从开始往后比较,如果相等,则继续,否则指针a往后走一步,指针b则回到字符串find的起始位置,重复上述操作。直到指针b指向\0为止,在指针a指向\0时前,字符串find的所有元素在另一个字符串中都能对应,则找到子字符串。否则没找到,返回空指针。
#include1.9 strtok
char * strtok ( char * str, const char * sep );

要点
- sep参数是个字符串,定义了用作分隔符的字符集合
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回 NULL 指针。
用途
诸如198.162.1.1、[email protected]含有除了数字和字母之外的字符这类字符串,以这些字符为分隔标志,将它们分为:198 162 1 1、123456 qq com若干个子字符串。

用例
int main()
{
char arr1[] = "[email protected]";
char tmp[30] = { 0 };
strcpy(tmp, arr1);//临时拷贝一份
char arr2[] = "@.";//将源字符串中出现的字符放入数组中,顺序任意
char* p = NULL;
//用p接收函数返回的标志的地址
p = strtok(tmp, arr2);
printf("%s\n", p);
p = strtok(NULL, arr2);
printf("%s\n", p);
p = strtok(NULL, arr2);
printf("%s\n", p);
return 0;
}

在这里,因为第一条语句只用执行一次,而后面的调用函数传参在形式上都是相同的,所以我们可以用for语句化简代码。
for (p = strtok(tmp, arr2); p != NULL; p = strtok(NULL, arr2))
{
printf("%s\n", p);
}
1.9 strerror
char * strerror ( int errnum );
功能:返回错误码,所对应的错误信息。也就是根据错误的类型,返回一段含有错误信息的文字。
用例
#include 
1.11 memcpy
void * memcpy ( void * destination, const void * source, size_t num );

它存在的意义
strcpy或strncpy函数只能对字符串进行操作,也就是char型,而内存中的数据不止char型,所以需要用一个“万能”的拷贝函数实现各种数据之间的拷贝。这便是它的参数和返回值类型为void*型的原因。
要点
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
- 这个函数在遇到’\0’ 的时候并不会停下来,和\0无关,所以目标内存中无\0无所谓。
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
用例
#include 
模拟实现memcpy
思路:这里的memcpy和strcpy十分类似,只是处理的数据不同,以及没有\0作为终止的条件,但是思路是一致的。这里的思路在模拟实现qsort中的交换函数部分一致,当复制数据时,是以一个字节为一个单位复制呢还是以4个(int)字节或5个字节为一个单位复制?仔细想想,假若需要复制的数据占15个字节,最快的办法当然是以15个字节为单位复制,接着是5,然后是三。但下次是18呢?所以具有普适性的方法应该是以一个字节为单位复制。
#include
注意:
在函数中,指针变量dest和src必须强转为(char*)型才能进行+1操作
用例
假设将数组a的1234,复制到a+2开始的16个字节的位置上理想结果应该是121234
因为memcpy的缺陷,不能复制数据有重叠部分的内存块(不论大小端)结果都将会是121212
#include
1.12 memmove
void * memmove ( void * destination, const void * source, size_t num );

要点
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。所以此函数是memcpy的优化函数。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理。
用例
#include模拟实现memmove
思路:如图只分析了其中一种情况,还有两种情况分别是与之相反的情况和两个内存块完全重叠的情况(将蓝色框看成可移动的)。

#include
1.13 memcmp
int memcmp ( const void * ptr1, const void * ptr2, size_t num );

要点
它与strlen的不同点在于它不由\0决定程序是否终止,而由计数器num控制。
用例
#include 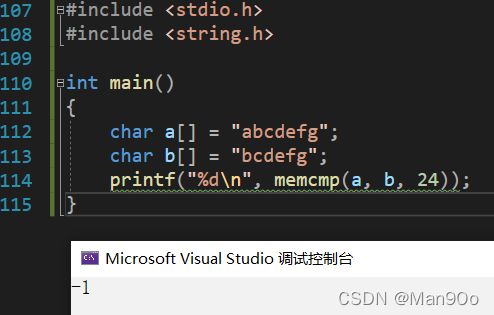
模拟实现memcmp
思路同strcmp,只不过程序是否终止由字节计数器决定。由于涉及到其他知识,在此给出核心代码。
while ( --count && *(char *)buf1 == *(char *)buf2 )
{
buf1 = (char *)buf1 + 1;
buf2 = (char *)buf2 + 1;
}
return( *((unsigned char *)buf1) - *((unsigned char *)buf2) );
1.14 memset
void * memset ( void * ptr, int value, size_t num );

要点
要注意它是设置内存块的前num个字节,是以字节为单位的。
用例
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
memset(a, 0, 17);
return 0;
}


我们将0改成1
int main()
{
int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
memset(a, 1, 17);
return 0;
}

所以memset的功能单一,个人觉得它的用处不是很广泛,通常用在将内存数据归零的情况下,且一般是0而不是其它。
模拟实现memset
有了前面的铺垫,要实现memset并不难,无非是强转+循环。由于涉及到其他知识,这里只给出核心代码,理解原理即可。
void * my_memset(void *dst, int val, size_t count)
{
assert(dst);
char* ret = (char*)dst;
while (count--)
{
*ret++ = (char)val; }
return dst;
}
}
2. 字符函数
| 头文件 | ctype.h |
|---|---|
| 函数 | 如果参数符合下列条件则返回真值 |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母af,大写字母AF |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母az或AZ |
| isalnum | 字母或者数字,az,AZ,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
| tolower | 转换为小写字母 |
| toupper | 转换为大写字母 |
这些函数功能单一,但十分实用,利用得当能提高程序的效率。例如判断字母大小写、判断是否为字母、大小写转换等函数。
用例
#include 
结语
至此,若读者在认真阅读时,并自己动手实现它们,会发现其实它们并不难。而要巧妙高效地使用它们,最好了解它们地工作原理,以避免不必要的错误。
欢迎读者指正,请原谅我的文章是那么的平淡无奇,且长。
如果你有收获的话,请给作者一个鼓励吧~