本文来自 eBay 软件工程师、Apache Kyuubi PPMC Member王斐在Apache SeaTunnel & Kyuubi 联合 Meetup的分享,介绍了Apache Kyuubi(Incubating)的基本架构和使用场景,eBay基于自身的需求对Kyuubi所做的增强,以及如何基于Kyuubi构建Unified & Serverless Spark Gateway。
Kyuubi是什么
首先介绍一下Kyuubi。Kyuubi是一个分布式的Thrift JDBC/ODBC server,支持多租户和分布式等特性,可以满足企业内诸如ETL、BI报表等大数据场景的应用。项目由网易数帆发起,已经进入Apache基金会孵化,目前的主要方向是依托本身的架构设计,围绕各类主流计算引擎,打造一个Serverless SQL on Lakehouse服务,目前支持的引擎有Spark、Flink、Trino(也就是Presto)。我今天的主题是围绕Kyuubi和Spark, 关于其它计算引擎这里不再展开。
对于Spark,Kyuubi有HiveServer2的API,支持Spark多租户,然后以Serverless的方式运行。HiveServer2是一个经典的JDBC服务,Spark社区也有一个类似的服务叫做Spark Thrift Server。这里介绍一下Spark Thrift Server和Kyuubi的对比。
Spark Thrift Server可以理解为一个独立运行的Spark app,负责接收用户的SQL请求, SQL的编译以及执行都会在这个app里面去运行,当用户的规模达到一定的级别,可能会有一个单点瓶颈。
对于Kyuubi,我们可以看右边这张图,有一个红色的用户和一个蓝色的用户,他们分别有一个红色的Spark app和一个蓝色的Spark app,他们的SQL请求进来之后,SQL的编译和执行都是在对应的app之上进行的,就是说Kyuubi Server只进行一次SQL请求的中转,把SQL直接发送给背后的Spark app。

对于Spark Thrift Server来讲,它需要保存结果以及状态信息,是有状态的,所以不能支持HA和LB。而Kyuubi不保存结果,几乎是一个无状态的服务,所以Kyuubi支持HA和LB,我们可以增加Kyuubi Server的个数来满足企业的需求。所以说Kyuubi是一个更好的Spark SQL Gateway。
Kyuubi的架构分为两层,一层是Server层,一层是Engine层。Server层和Engine层都有一个服务发现层,Kyuubi Server层的服务发现层用于随机选择一个Kyuubi Server,Kyuubi Server对于所有用户来共享的。Kyuubi Engine层的服务发现层对用户来说是不可见的,它是用于Kyuubi Server去选择对应的用户的Spark Engine,当一条用户的请求进来之后,它会随机选择一个Kyuubi Server,Kyuubi Server会去Engine的服务发现层选择一个Engine,如果Engine不存在,它就会创建一个Spark Engine,这个Engine启动之后会向Engine的服务发现层去注册,然后Kyuubi Server和Engine之间的再进行一个Internal的连接,所以说Kyuubi Server是所有用户共享,Kyuubi Engine是用户之间资源隔离。

Kyuubi支持一些Engine的共享级别,它是基于隔离和资源之间的平衡。在eBay我们主要使用到了USER 和CONNECTION级别。首先对于CONNECTION级别,对于用户的每次连接都会创造一个新的app,也就是一个Kyuubi Engine,适用于ETL场景,ETL的workload比较高,需要一个独立的app去执行;对于USER级别,我们可以看到这里有两个user,一个叫Tom,一个叫Jerry,Tom的两个client连接Kyuubi Server,会连接到同一个属于Tom的Kyuubi Engine,USER级别适用于ad-hoc场景,就是对于同一个用户所有的连接都会到同一个Kyuubi Engine去执行,而对Jerry的所有请求都会到Jerry的Kyuubi Engine去执行。

对USER共享级别Kyuubi做了一些加强,引入了一个Engine POOL的概念,就像编程里面的线程池一样,我们可以创建一个Engine的pool,pool里面有编号,比如说这里Tom创建了两个pool,叫做pool-a和pool-b,编号为pool-a-0,pool-a-1,如果说在客户端请求的时候直接指定这个pool的名字,Kyuubi server会从这个pool里面去随机选择一台Engine执行;如果Tom在请求的时候不仅指定pool的名字,还指定了这个Engine在pool里面的索引,比如说这里指定pool-b-0,Kyuubi Server会从这个pool-b里面选择编号为0的Engine去做计算。对应的参数为kyuubi.engine.share.level.subdomain.
这在eBay里面为BI工具集成提供了很大的便利,因为eBay,每个分析师团队可能用同一个账号去执行数据分析,BI工具会根据用户的IP去创建一个Kyuubi Engine,因为每个分析师需要的参数配置可能是不一样的,比如说他们的内存的配置是不一样的,BI工具就可以创建一个这样的engine pool,然后保存用户的IP和所创建Engine 索引的一个mapping,然后在这个用户的请求过来的时候,根据BI工具保存的IP映射关系,去找到该用户所创建的Engine,或者是说一个团队里面很多人使用一个pool,可以预创建许多Spark app,让这一个组里面的人可以随机选择一个Engine去做执行,这样可以加大并发度。 同时也可以作为USER共享级别下面的一个标签用于标注该引擎的用途,比如说我们可以给beeline场景和java JDBC应用使用场景创建USER共享级别下的不同engine pool,在不同使用场景下使用不同的engine pool, 互相隔离。
前面提到了不同的Engine共享级别,有的是为每个连接创建一个Spark App,有的是为一个用户创建一个或者多个Kyuubi Engine,你可能会担心资源浪费,这里讲一下Kyuubi Engine对资源的动态管理。首先,一个Kyuubi Engine,也就是一个Spark app,分为Spark driver和Spark executor,对于executor,Spark本身就有一个executor dynamic allocation机制,它会根据当前Spark job的负载来决定是否向集群申请更多的资源,或者是说将目前已申请的资源返还给集群。所说我们在Kyuubi Server层加一些限制,比如强制打开这个executor dynamic allocation,并且把在空闲时候最小的executor数量设为0,也就是说当一个app非常空闲的时候只有一个driver带运行,避免浪费资源。除了executor层的动态回收机制,Kyuubi 为driver层也加了资源回收机制。对于CONNECTION分享级别,Kyuubi Engine只有在当前连接才使用,当连接关闭的时候Spark driver会直接被回收掉。对USER级别的共享,Kyuubi 有一个参数kyuubi.session.engine.idle.timeout 来控制engine的最长空闲时间,比如说我们将空闲时间设置为12小时,如果12个小时之内都没有请求连接到这个Spark app上,这个Spark app就会自动结束,避免资源浪费。
Kyuubi的使用场景
下面讲一下Use Case。目前Kyuubi支持了SQL语言和Scala语言的执行,也可以把SQL和Scala写在一起去跑。因为SQL是一种非常用户友好的语言,它可以让你不用了解Spark内部的原理,就可以使用简单的SQL语句去查询数据,但是它也有一定的局限性;而Scala语言需要一定的门槛,但它非常的灵活,我们可以去写代码或者去操纵一些Spark DataFrame API。
举一个例子,就是可以在一个SQL文件或者一个notebook里面去混合编程。首先用SQL语句创建了一张训练的数据表,在创建表之后通过SET语句把语言模式设为Scala,然后开始用Scala去写代码,这里是用一个kMeans把训练数据进行处理,处理完之后把输出保存在一张表里面,再把语言模式切换到SQL,继续用SQL去处理。这样非常方便,我们可以结合SQL、Scala的优点,基本上可以解决数据分析里面的大部分的case。我们也在Kyuubi JDBC里面提供了一个非常友好的接口,可以直接调用KyuubiStatement::ExecuteScala去执行Scala语句。

Kyuubi在eBay的实践
eBay需求背景
我们Hadoop team管理了很多个Hadoop集群,这些集群分布在不同的数据中心,有不同的用途,有一套统一的基于KDC和LDAP的权限校验。

刚开始引入Kyuubi的时候,我们就在想要为每个集群都部署一个Kyuubi服务吗?如果这样我们可能要部署三四个Kyuubi服务,在升级的时候需要进行重复操作,管理起来很不方便,所以我们就想是否能够用一套Kyuubi来服务多个Hadoop集群。
eBay对Kyuubi的增强
下图就是我们为这个需求所做的一些增强。首先,因为我们是支持KDC和LDAP认证的,我们就让Kyuubi同时支持Kerberos和Plain类型的权限认证,并对Kyuubi Engine的启动、Kyuubi的Beeline做了些优化,然后我们扩展了一些Kyuubi的thrift API支持上传下载数据。针对前面说的要用一个Kyuubi去访问多个Hadoop集群,我们加了一个cluster selector的概念,可以在连接的时候指定参数,让请求路由到对应的集群。还有就是我们也在完善RESTfull API,已经为Kyuubi支持了SPNEGO和BASIC 的RESTfull API权限认证。此外我们也在做RESTfull API去跑SQL Query 和 Batch job的一些工作。图中打编号的是已经回馈社区的一些PR。

这里讲一下2、3、4,对Kyuubi的Thrift RPC的一些优化。首先因为Thrift RPC本身是针对HiveServer2来设计的,HiveServer2/Spark Thriftserver2里面建立一个连接是非常快的。而在Kyuubi里面建立一个连接的话,首先要连接到Kyuubi Server,Kyuubi Server要等到和远端的Kyuubi Engine建立连接完成之后,才能把结果返回给客户端。
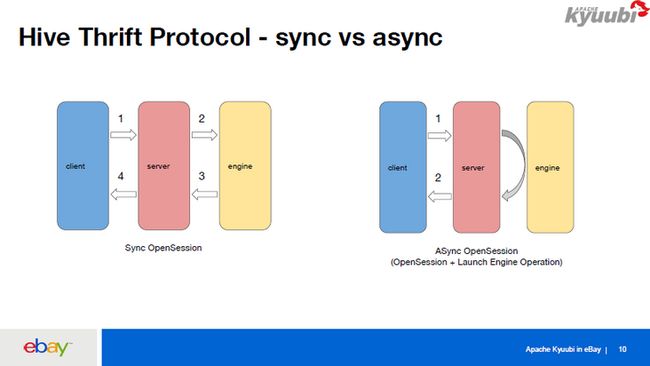
如果Kyuubi Engine一开始不存在,而且在启动Kyuubi Engine的时候由于资源问题,或者是有一些参数设置不对,比如说他设置了无效的spark.yarn.queu,导致出现错误的话,中间可能会有一分钟或者说几十秒的延迟,客户端要一直等,在等的过程中也没有任何的log返回给客户端。我们就针对这个做了一些异步的OpenSession,将OpenSession分为两部分,第一步是连接到Kyuubi Server,Kyuubi Server再异步启动一个LaunchEngine Operation,之后立即把Kyuubi Server连接给客户端,这样客户端可以做到一秒钟就可以连接到Kyuubi Server。但是他的下条语句以及进来之后,会一直等到这个Engine初始化好之后才开始运行。其实这也是我们的PM的一个需求,即使第一条语句运行时间长一点也没关系,但是连接是一定要很快,所以我们就做了这样一个工作。
因为Hive Thrift RPC是一个广泛应用而且非常用户友好的RPC,所以我们在不破坏它的兼容性的情况下基于Thrift RPC做了一些扩展。首先对于ExecuteStatement这种请求及返回结果,它会在API里面返回一个OperationHandle,再根据OperationHandle获取当前Operation的状态和日志。因为我们前面已经把OpenSession拆成了OpenSession加上一个LaunchEngine Operation,所以我们想把LaunchEngine Operation的一些信息,通过OpenSession request这个configuration map把它返回去,我们是把一个OperationHandler分为两部分,一部分是guid,另一部分是secret,放到OpenSessionResp 的configuration Map里面。

然后在拿到OpenSessionResp之后就可以根据这个configuration拼出Launch Engine Operation对应的OperationHandler,然后再根据它去拿这个LaunchEngine的日志和状态。
下面是一个效果,我们在建立Kyuubi连接的时候可以实时知道spark-submit的过程中到底发生了什么。比如说用户将spark.yarn.queue设置错了,或者说由于资源问题一直在等待,都可以清楚的知道这中间发生了什么,不需要找平台维护人员去看日志,这样既让用户感到极为友好,也减少了平台维护人员的efforts。

构建Unified & Serverless Spark Gateway
前面说到要用一个Kyuubi服务来服务多个集群,我们就基于Kyuubi构建了一个Unified & Serverless Spark Gateway。Unified是说我们只有一个endpoint,我们是部署在Kubernetes之上的,使用Kubernetes的LB作为Kyuubi Server的服务发现,endpoint的形式就是一个Kubernetes的LB加上一个端口,比如说kyuubi.k8s-lb.ebay.com:10009,要服务多个集群,我们只需要在JDBC URL里面加上一个参数kyuubi.session.cluster,指定cluster name,就可以让他的请求到指定的集群去执行。关于权限校验我们也是用Unified的,同时支持Kerberos和LDAP权限校验。关于functions(功能)也是Unified的,同时支持Spark-SQL、Spark-Scala以及ETL Spark Job的提交。
关于Serverless, Kyuubi Server部署在Kubernetes之上,是Cloud-native的,而且Kyuubi Server支持HA和LB,Kyuubi Engine支持多租户,所以对于平台维护人员来说成本非常低。
这是我们大概的一个部署,对于多集群我们引入了Cluster Selector的概念,为每个集群都配了一个Kubernetes ConfigMap文件,在这个文件里面有这个集群所独有的一些配置,比如这个集群的ZooKeeper的配置,集群的环境变量,会在启动Kyuubi Engine的时候注入到启动的进程里面。

每个集群的super user的配置也是不一样的,所以我们也支持了对各个集群进行super user的校验。目前Kyuubi支持HadoopFSDelegation token和HiveDelegation token的刷新,可以让Spark Engine在没有keytab的情况下去长运行,而不用担心token过期的问题。我们也让这个功能支持了多集群。
用户一个请求进来的过程是这样的:首先他要指定一个Cluster Selector,Kyuubi Server(on Kubernetes)根据这个Selector去找到对应的集群,连接集群的ZooKeeper,然后查找在ZooKeeper里面有没有对应的Spark app, 如果没有就提交一个app到YARN上面(Spark on YARN),Engine在启动之后会向ZooKeeper注册,Kyuubi Server和Kyuubi Engine通过ZooKeeper找到Host和Port并创建连接。
Kyuubi从一开始就支持Thrift/JDBC/ODBC API, 目前社区也在完善RESTFul API. eBay也在做一些完善RESTFul API的工作,我们给RESTful API加了权限校验的支持,同时支持SPNEGO(Kerberos)和BASIC(基于密码)的权限校验。我们计划给Kyuubi增加更多的RESTful API。目前已有的是关于sessions的API,比如可以关掉session,主要用于来管理Kyuubi的sessions。我们准备加一些针对SQL以及Batch Job的API。关于SQL就是可以直接通RESTful API提交一条SQL Query,然后可以拿到它的结果以及log。关于Batch Job就是可以通过RESTful API提交一个普通的使用JAR来运行的Spark app,然后可以拿到Spark app的ApplicationId,还有spark-submit的log,这样可以让用户更加方便地使用Kyuubi完成各种常用的Spark操作。
eBay的收益
对用户来说,他们能够非常方便地使用Spark服务,可以使用Thrift、JDBC、ODBC、RESTful的接口,它也是非常轻量的,不需要去安装Hadoop/Spark binary,也不需要管理Hadoop和Spark的Conf,只需要用RESTful或者Beeline/JDBC的形式去连接就好。
对我们平台开发团队来说,我们有了一个中心化的Spark服务,可以提供SQL、Scala的服务,也可以提供spark-submit的服务,我们可以方便地管理Spark版本,不需要将Spark安装包分发给用户去使用,可以更好地完成灰度升级,让Spark版本对于用户透明化,让整个集群使用最新的Spark,也节省集群的资源,节省公司的成本。此外,平台的维护也是比较方便的,成本很低,因为我们只需要维护一个Kyuubi服务来服务多个Hadoop集群。
作者:王斐,eBay 软件工程师,Apache Kyuubi PPMC Member
附视频回放及PPT下载:
延伸阅读: