机器学习(1)
本章将从以下步骤完成一个机器学习项目
1,问题分析
2,获得数据
3,从数据探索和可视化中获得洞见
4,机器学习算法的数据准备
5,选择和训练模型
6,微调模型
7,启动、监控和维护系统
一,问题分析
- 首先应该明确业务目标是什么,因为建立模型本身可能不是最终目标。公司需要知道如何使用这个模型,如何从中获利。这才是最重要的问题,因为这将决定你怎么设定问题,选择说明算法,使用什么测量方法来评估模型的性能,以及应该花多少精力来进行调整。
- 其次是选择性能指标,回归问题的典型性能衡量指标是均方根误差(RMSE),平均绝对误差(MAE),标准差(SD)
RMSE
Root Mean Square Error,均方根误差
是观测值与真值偏差的平方和与观测次数m比值的平方根。
是用来衡量观测值同真值之间的偏差
MAE
Mean Absolute Error ,平均绝对误差
是绝对误差的平均值
能更好地反映预测值误差的实际情况.
SD
Standard Deviation ,标准差
是方差的算数平方根
是用来衡量一组数自身的离散程度
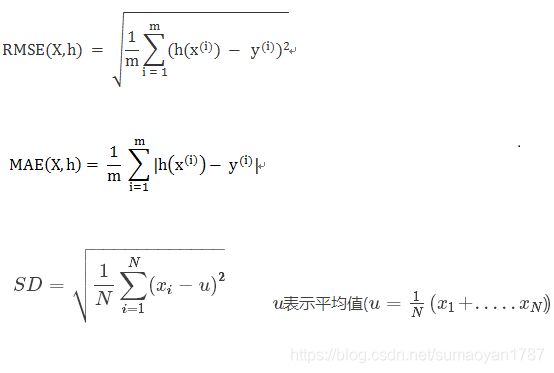
二,获取数据
- 数据下载,我们可以去一些开源数据网站下载数据,也可以自行爬取一些数据,但一定要保证数据的真实性。我们从这里下载。
- 数据加载,我们使用Pandas加载数据
import pandas an pd
def load_housing_data(housing_path):
return pd.read_csv(housing_path)这个函数会返回一个包含所有数据的Pandas DataFrame对象。
3.快速查看数据结构
(1)head()方法,查看前n行数据,默认前5行数据.
housing = load_housing_data(HOUSING_PATH)
print(housing.head()) 
(2)info()方法,快速获取数据集的简单描述,特别是总行数、每个属性的类型和非空值的数量
print(housing.info()) 
数据集中包含20640个实例,以机器学习的标准来看,这个数字非常的小,但却是个完美的开始,需要注意的是, total_bedrooms这个属性只有20433个非空值,这意味着有207个区域缺失这个特性。我们后面需要考虑这一点。
所有属性的字段都是数字,除了ocean_proximity。它的类型是object,因此它可以是任何类型的python对象。
(3)value_counts()方法,查看有多少中分类存在,每种类别下分别有多少个区域。
vc = housing[‘ocean_proximity’].value_counts()
print(vc) 
(4)describe()方法,可以显示数值属性的摘要。
print(housing.describe()) 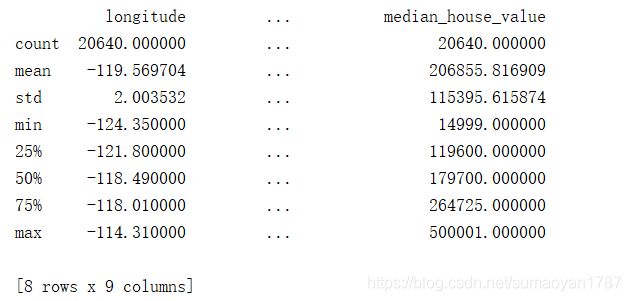
count—总行数
mean—平均值
min—最小值
max—最大值
std—标准差,用来测量数值的离散程度
25%、50%和75%--百分位数,表示一组观测值中给定百分比的观测值都低于该值。
(5)直方图,用来显示给定值范围(横轴)的实例数量(纵轴)。使用hist()方法
绘制每个属性的直方图。
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(20,15))
plt.show()
bins-每张图柱子的个数
figsize-每张图的尺寸
三,从数据探索和可视化中获得洞见
该部分内容,会深入探索数据中的奥秘
- 将地理数据可视化,由于存在地理位置信息(经度和纬度),因此建立一个各区域的分布图以便于数据可视化是一个很好的想法。
import matplotlib.pyplot as plt
housing.plot(kind="scatter",x="longitude",y="latitude")
plt.show() 
kind—图形的显示类型,scatter散点
x—横坐标
y—纵坐标
上述图形只是看起来跟加利福尼亚州一样之外,很难再看出其他信息,我们以设置
透明度alpha属性为0.1再观察。(突出高密度区域可视化)
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)
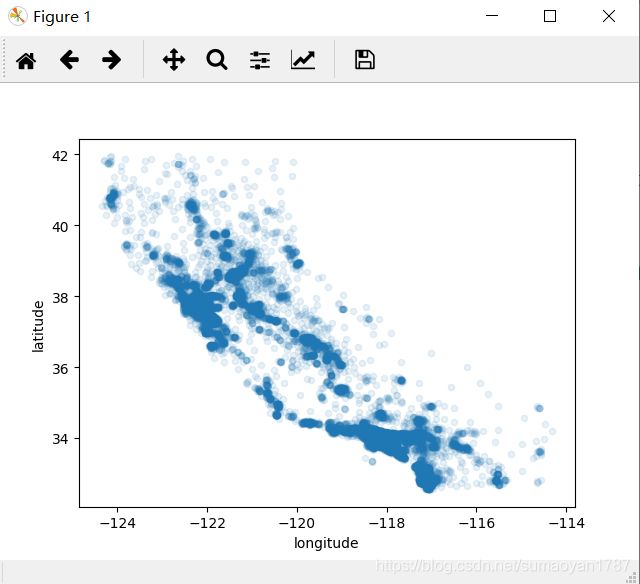
现在好多了,可以清楚的看到高密度地区,也就是湾区,洛杉矶和圣地亚哥附近
同时,在中央山谷有一条相当高密度的长线,特别是萨克拉门托和弗雷斯诺附近。
现在,再来看看房价。
import matplotlib.pyplot as plt
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing["population"]/100,
label="population",c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True)
plt.legend()
plt.show() 
图中每个圆的半径大小代表每个区域的人口数量,颜色代表房屋价格。
这张图告诉你房屋价格与地理位置和人口密度息息相关。
2.寻找相关性
由于数据集不大,你可以使用corr()方法轻松计算出每对属性之间的标准相关系数。
( 也称为皮尔逊相关系数)
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))现在看看每个属性与房屋中位数的相关性:

相关系数的范围从-1变化到1,越接近1或者-1,表示相关性越强,越接近0表示
相关性越弱,其中趋近1是整相关,趋近-1是负相关。
还有一种方法可以检测属性之间相关性,就是使用Pandas的scatter_matrix()函数,
我们只关注与房屋中位数相关的。 from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
attributes = ["median_house_value","median_income","total_rooms","housing_median_age"]
scatter_matrix(housing[attributes],figsize=(12,8))
plt.show()

最有潜力能够预测房价中位数的属性是收入中位数,所以我们放大来看看其相关性散点图 import matplotlib.pyplot as plt
housing.plot(kind="scatter",x="median_income",y="median_house_value",alpha=0.1)
plt.show()

从图中可以看出几个问题:首先,二者相关性确实很强你可以清楚的看到上升趋势,并且点也不是太分散。其次,50万美元的价格上限,在图中是一条清晰的水平线,除此之外,45,35,28处都隐约也有水平线,所以为了避免你的算法学习之后重现这些怪异的数据,可以尝试删除这些区域。
(3) 试验不同属性的组合,我们期望通过不同属性的组合,来创造新的属性,有时这些新属性和目标属性的相关性更大。比如
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"] = housing["population"]/housing["households"]
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False)) 
看起来还不错吧,新属性bedrooms_per_room较之total_rooms和total_bedrooms与房价中位数的相关性都要高。
四,机器学习算法的数据准备
- 数据清理,大部分机器学习算法无法在缺失的特征上工作,所以我们要创建一些函数来辅助它。前面我们已经注意到total_bedrooms属性有部分缺失值,所以我们要解决它,有三个办法:放弃这些相应的地区,放弃这个属性,将缺失的值设置为某个值(平均数,中位数,0等)
sample_incomplete_rows.dropna(subset=["total_bedrooms"])
sample_incmplete_rows.drop("total_bedrooms", axis=1)
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True)scikit-learn提供了一个非常容易上手的教程来处理缺失值。首先创建一个imputer实例,指定你要用属性的中位数值替换该属性的缺失值。并且,中位数值只能在数值属性上计算,所以应该先去掉数据中的文本字段。
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy="median")
#axis使用0值表示沿着每一列或行标签\索引值向下执行方法
#axis使用1值表示沿着每一行或者列标签模向执行对应的方法
housing_num = housing.drop("ocean_proximity",axis=1)
#计算每个属性的中位数值
imputer.fit(housing_num)
#将缺失值替换成中位数值,返回包含转换后特征的Numpy数组
X = imputer.transform(housing_num)
#把X转换成Pandas DataFrame
housing_tr = pd.DataFrame(X,columns=housing_num.columns)
print(housing_tr.info())
2. 处理文本和分类属性,类似ocean_proximity这种文本数据不能直接参与计算,所以我们要把这些文本数据转换成数值数据。Scikit-Learn为这类任务提供了一个转换器LabelEncoder:
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
housing_cat = housing["ocean_proximity"]
housing_cat_encoded = encoder.fit_transform(housing_cat)
print(housing_cat_encoded)
现在好了,我们把文本数据用相应数字进行了代替,这种代表方式产生的一个问题就是,机器学习算法会以为两个相近的数字比两个离得较远得数字更为相似一些,可事实并非如此,分类数字之间应该不应该存在相似性。Scikit-Learn提供一个OneHotEncoder编码器,可以将整数分类值转换为独热向量。from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
print(housing_cat_1hot.toarray())
使用LabelBinarizer类可以一次性完成两个转换(从文本到整数再到独热向量)
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
housing_cat = housing["ocean_proximity"]
housing_cat_1hot = encoder.fit_transform(housing_cat)
print(housing_cat_1hot)
注意,这时默认返回得是一个密集的Numpy数组,通过发送sparse_output=True给LabelBinarizer构造函数,可以得到稀疏矩阵。
3.特征缩放,如果输入的数值属性具有非常大的比例差异,往往导致机器学习算法的性能表现不佳,当然也有极少数特例。案例中的房屋数据就是这样,房间总数范围从6到39320,而收入中位数的范围时0到15。一般目标值通常不缩放。
同比例缩放所有属性,常用的两种方法是:最小-最大缩放和标准化
最小-最大缩放(又叫归一化)很简单:将值重新缩放使其最终范围归于0到1之间,实现方法是将值减去最小值并除以最大值与最小值的差,对此,Scikit-Learn提供了一个名为MinMaxScaler的转换器,如果你希望范围不是0~1,你可以通过调整超参数feature_range进行更改。
标准化则完全不一样:首先减去平均值(所有标准化值得均值总是零),然后除以方差,从而使得结果得分布具备单位方差,不同于最小-最大缩放的是,标准化不将值绑定到特定范围,对某些算法而言,这可能是个问题(例如,神经网络期望得输入值范围通常是0到1).但是标准化得方法受异常值得影响更小,例如,假设某个地区得平均收入等于100(错误数据),最小-最大缩放会将所有其他值从0~15降到0~0.15,而标准化则不会受到很大影响,Scikit-Learn提供一个标准化转化器StandadScaler。
4. 转换流水线,许多数据转换的步骤需要以正确的顺序来执行。
from sklearn.base import BaseEstimator,TransformerMixin
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.preprocessing import OneHotEncoder
import numpy as np
total_rooms,total_bedrooms,population,household=3,4,5,6 #取出我们需要的属性列
class Attribute_Add(BaseEstimator,TransformerMixin): # 导入两个基类获得fit、transform方法
def __init__(self,bedrooms_per_room=None): # bedrooms_per_room=bedrooms_per_room为可选属性,同时我们设置了两个必选属性
self.bedrooms_per_room=bedrooms_per_room
def fit(self,x,y=None):
return self
def transform(self, x, y=None, ):
# x=inputdata,y=targetdata
#下面两个属性为我们必选合成属性
rooms_per_household = x[:,total_rooms] / x[:,household] # 求取每个房间平均的房间数
rooms_per_population = x[:,population] / x[:,total_rooms]# 求每个人拥有的平均房间数
if self.bedrooms_per_room:
bedrooms_per_room=x[:,total_rooms]/x[:,total_bedrooms] #bedrooms_per_room为可选的合成属性
return np.c_[x,rooms_per_household,rooms_per_population,bedrooms_per_room]
else:
return np.c_[x,rooms_per_household,rooms_per_population]
class get_data(BaseEstimator,TransformerMixin):#获取数据表中数值数据或者是文本类型的数据,其中attributes为我们属性值列表
def __init__(self,attributes):
self.attributes=attributes;
def fit(self,x,y=None):
return self
def transform(self,x,y=None):
return x[self.attributes].values
class MyOneHotEncode(BaseEstimator,TransformerMixin):#将文本类型的数据转换成数值类型的数据,然后再转换成独热码
def __init__(self,data=None):
self.data=data
def fit(self,x,y=None):
return self
def transform(self,x,y=None):
encoder = LabelEncoder()
array1 = encoder.fit_transform(x)
onehotencode=OneHotEncoder()
tp=onehotencode.fit_transform(array1.reshape(-1,1))
#print(tp.toarray())
return tp.toarray()
from sklearn.pipeline import Pipeline #通俗理解就是前一个转换器的输出作为下一个转换的输入,依次对数据进行处理
from sklearn.pipeline import FeatureUnion #可以理解为多个流水线同时并行对数据操作,各个流水线工作互不影响
from sklearn.preprocessing import Imputer
"""
sklearn 中的流水线处理数字数据
"""
num_attributes = list(housing.drop("ocean_proximity", axis=1)) # ocean_proximity为非数值类型的数据,需要去除掉
num_pipeline = Pipeline([
('get_num', get_data(num_attributes)), # 获取数值类型数据
('imputer', Imputer(strategy="median")),
# 补全数据中的空值(用中位数填充空值)sklearn自带的Imputer # ( 需要导入,这里没有写出 from sklearm.preprocessing import Imputer)
('add_attributes', Attribute_Add()), # 合成属性
('normalize', StandardScaler()), # 数据标准化
])
"""
sklearn中的流水线处理非数字数据
"""
cat=["ocean_proximity"] # 非数值属性列
N_num_pipeline=Pipeline([
('get_char',get_data(cat)), #获取非数值数据
('label_bin',MyOneHotEncode()),#转换成独热码
])
union_pipeline=FeatureUnion(transformer_list=[
("pipeline1",num_pipeline),
("pipeline2",N_num_pipeline),
])
tq=union_pipeline.fit_transform(housing) # 运行 得出的结果是一个简单numpy数组,我们可以将其转换成pd中DataFrame数据
#格式,方便我们查看
list=["rooms_per_househols","rooms_per_population","hot1","hot2","hot3","hot4","hot5"] #为新增的属性列增加名称
num_attributes.extend(list) # 与之前的属性列合并
final_data=pd.DataFrame(tq,columns=num_attributes) #转换成DataFrame
print(final_data) #显示数据
5.创建训练集和测试集
理论上创建训练集和测试集非常的简单,你只需要随机选择一些实例来将整个数据集分为训练和测试两部分,一般按照8:2。
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
print(len(train_set), "train +", len(test_set), "test")看起来行的通,但却不完美,如果再运行一遍,它会产生一个不同的数据集,这样下去你将会看到整个完整的数据集,而这正是我们需要避免的。
解决方案之一是在第一次运行程序后保存训练集和测试集,随后的运行只是加载而已,另一种方法是在调用np.random.permutation(len(data))之前设置一个随机数生成器的种子np.random.seed(42),从而让它始终生成相同的随机索引。
但是这两种方案在下一次获取更新的数据时都会中断。常见的解决办法是每个实例都使用一个标识符来决定是否进入测试集。举例来说,你可以计算每个实例标识符的hash值,只取hash的最后一个字节,如果该值小于等于51(约256的20%),则将该实例放入测试集。
不幸的是,我们的数据中没有标识符列。最简单的解决方案是使用行索引作为ID
import numpy as np
import hashlib
def test_set_check(identifier, test_ratio,hash):
return hash(np.int64(identifier)).digest()[-1] < test_ratio * 256
def split_train_test_by_id(data, test_ratio, id_column,hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio,hash))
return data.loc[~in_test_set], data.loc[in_test_set]
housing_with_id = housing.reset_index()
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
print(len(train_set), "train +", len(test_set), "test")如果使用行索引作为唯一标识符,你需要确保在数据集的末尾添加新数据,并且不会删除任何行。如果不能保证这一点,那么你可以尝试使用某个最稳定的特征来创建唯一标识。例如经纬度。
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")Scikit-Learn提供了一些函数,例如train_test_split,与我们写的split_train_test类似。
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
print(len(train_set), "train +", len(test_set), "test")![]()
看似没有问题,但是我们要考虑样本是否能够代表全部数据,所以最好采用分层抽样。
根据前面的分析得知,收入中位数对预测房价很重要,而大多数中位数值聚集在2-5万,也有一部分数据超过5万,如果我们想按照收入中位数进行分层取样的话,我们的处理方式是:将收入中位数除以1.5(限制收入类别的数量),然后使用ceil进行取整(得到离散类别),最后将所有大于5的类别合并为类别5。最后使用Scikit-Learn提供的StratifiedShuffleSplit类实现子集划分。
import numpy as np
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
print(len(strat_train_set), "train +", len(strat_test_set), "test")
print(housing['income_cat'].value_counts()/len(housing))
现在你可以删除income_cat属性,将数据恢复原样了。
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)五,选择和训练模型
- 培训和评估训练集
先训练一个线性回归模型试试看。
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(strat_train_set.drop("median_house_value",axis=1), strat_train_set["median_house_value"])
print("Predictions:", lin_reg.predict(strat_ train _set.drop("median_house_value",axis=1)))
print("Labels:", strat_ train _set["median_house_value"])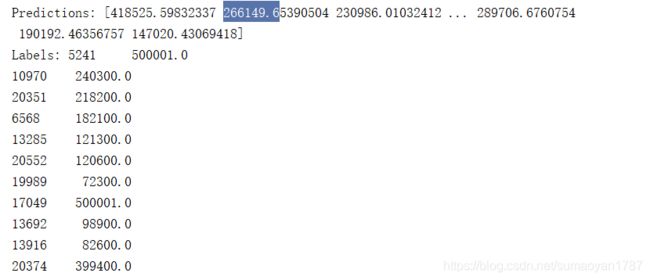
可以工作了,不过好像不太准啊,我们可以使用mean_squared_error来测量回归模型的RMSE。
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(strat_ train _set.drop("median_house_value",axis=1))
lin_mse = mean_squared_error(strat_ train _set["median_house_value"], housing_predictions)
lin_rmse = np.sqrt(lin_mse)
print(lin_rmse)![]()
好吧,明显预测不准,这是典型的欠拟合,接下来我们换一个模型。
tree_reg = DecisionTreeRegressor(random_state=42)![]()
什么情况,竟然完全没有错误,这是典型过拟合了。
2.使用交叉验证来更好的评估模型,它将训练集随机分割成10个不同的子集,每个子集称为一个折叠(fold),然后对模型进行10次训练和评估—每次挑选1个折叠进行评估,使用另外9个进行训练。产生结果是一个包含10次评估分数的数组:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, strat_train_set.drop("median_house_value",axis=1), strat_train_set["median_house_value"],scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
结果来看,模型好像更加糟糕了,请注意,交叉验证不仅可以得到一个模型性能的评估值,还可以衡量该评估的精确度。这里模型评估分为69575,上下浮动+-2243。
我们再测试一个模型,随机森林:RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=10, random_state=42)
这个看起来好多了哈,但是,请注意,训练集上的分数仍然远低于验证集,这意味着该模型仍然对训练集过度拟合。过度拟合的解决方案包括简化模型,约束模型,或是获取更多的训练数据。记住,不要花太多时间去调整超参数,我们的目的是筛选几个(2~5)有效模型。
六,微调模型
- 网格搜索,这是一种手动调整超参数,找到一组很好的超参数值组合的方法,你可以使用Scikit-Learn的GridSearchCV来替你进行探索。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(strat_train_set.drop("median_house_value",axis=1), strat_train_set["median_house_value"])
print("best_params_:",grid_search.best_params_)
print("best_estimator_:",grid_search.best_estimator_)
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)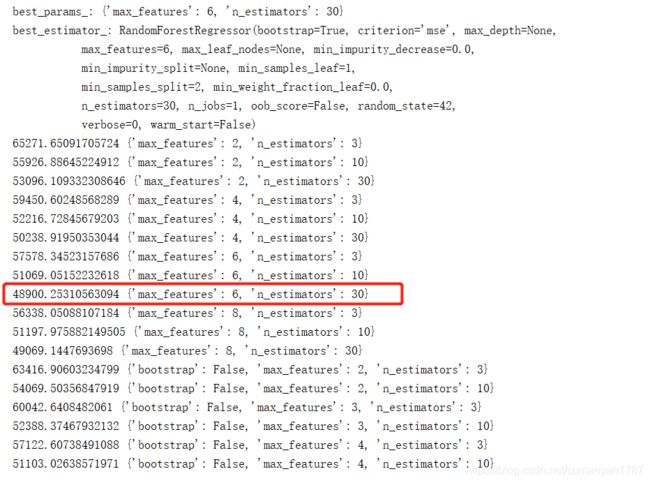
这个param_grid告诉Scikit-Learn,首先评估第一个dict中的n_estimators和max_features的所有3x4=12种超参数值组合。以此类推。网格搜索将探索12+6=18种组合,并对每个模型进行5次训练,共90次训练,完成后得到结果如上图。
- 随机搜索,如果探索的组合数量较少—例如上面实例,网格搜索是一个不错的选择,但是当超参数的搜索范围较大时,通常会优先选择RandomizedSearchCV。它不会尝试所有可能的组合,而是在每次迭代中为每个超参数选择一个随机值,然后对一定数量的随机组合进行评估。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)2.集成方法,将表现最佳的模型组合起来。
3.测试集评估模型
七,启动、监控和维护系统