@[toc]
松哥之前写过文章跟大家介绍过用 MyCat 实现 MySQL 的分库分表,不知道有没有小伙伴研究过,MySQL 其实也自带了分区功能,我们可以创建一个带有分区的表,而且不需要借助任何外部工具,今天我们就一起来看看。
1. 什么是表分区
小伙伴们知道,MySQL 数据库中的数据是以文件的形势存在磁盘上的,默认放在 /var/lib/mysql/ 目录下面,我们可以通过 show variables like '%datadir%'; 命令来查看:
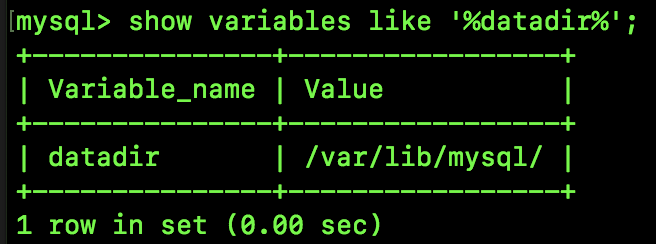
我们进入到这个目录下,就可以看到我们定义的所有数据库了,一个数据库就是一个文件夹,一个库中,有其对应的表的信息,如下:
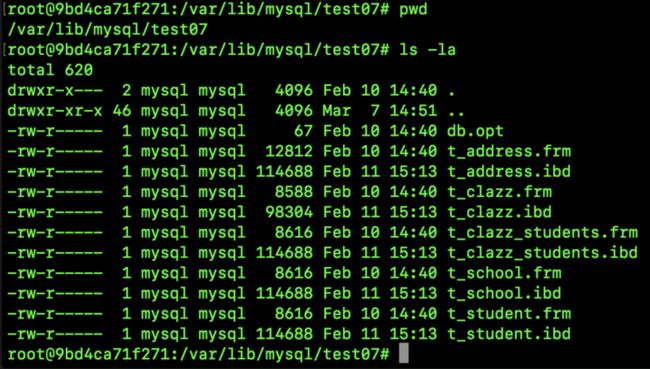
在 MySQL 中,如果存储引擎是 MyISAM,那么在 data 目录下会看到 3 类文件:.frm、.myi、.myd,作用如下:
*.frm:这个是表定义,是描述表结构的文件。*.myd:这个是数据信息文件,是表的数据文件。*.myi:这个是索引信息文件。
如果存储引擎是 InnoDB, 那么在 data 目录下会看到两类文件:.frm、.ibd,作用分别如下:
*.frm:表结构文件。*.ibd:表数据和索引的文件。
无论是哪种存储引擎,只要一张表的数据量过大,就会导致 *.myd、*.myi 以及 *.ibd 文件过大,数据的查找就会变的很慢。
为了解决这个问题,我们可以利用 MySQL 的分区功能,在物理上将这一张表对应的文件,分割成许多小块,如此,当我们查找一条数据时,就不用在某一个文件中进行整个遍历了,我们只需要知道这条数据位于哪一个数据块,然后在那一个数据块上查找就行了;另一方面,如果一张表的数据量太大,可能一个磁盘放不下,这个时候,通过表分区我们就可以把数据分配到不同的磁盘里面去。
MySQL 从 5.1 开始添加了对分区的支持,分区的过程是将一个表或索引分解为多个更小、更可管理的部分。对于开发者而言,分区后的表使用方式和不分区基本上还是一模一样,只不过在物理存储上,原本该表只有一个数据文件,现在变成了多个,每个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
需要注意的是,分区功能并不是在存储引擎层完成的,常见的存储引擎如 InnoDB、MyISAM、NDB 等都支持分区。但并不是所有的存储引擎都支持,如 CSV、FEDORATED、MERGE 等就不支持分区,因此在使用此分区功能前,应该对选择的存储引擎对分区的支持有所了解。
2. 分区的两种方式
不同于 MyCat 中既可以垂直切分又可以水平切分,MySQL 数据库支持的分区类型为水平分区,它不支持垂直分区。
2.1 水平切分
先来一张简单的示意图,大家感受一下什么是水平切分:

假设我的 DB 中有 table-1、table-2 以及 table-3 三张表,水平切分就是拿着我 40 米大刀,对准黑色的线条,砍一剑或者砍 N 剑!
砍完之后,将砍掉的部分放到另外一个数据库实例中,变成下面这样:
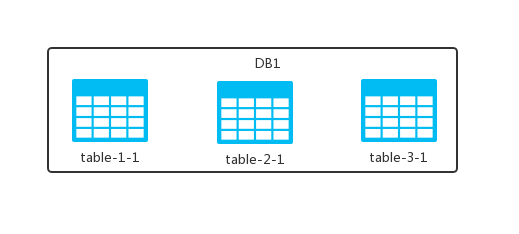
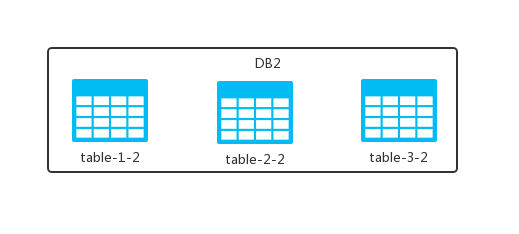
这样,原本放在一个 DB 中的 table 现在放在两个 DB 中了,观察之后我们发现:
- 两个 DB 中表的个数都是完整的,就是原来 DB 中有几张表,现在还是几张。
- 每张表中的数据是不完整的,数据被拆分到了不同的 DB 中去了。
这就是数据库的水平切分,也可以理解为按照数据行进行切分,即按照表中某个字段的某种规则来将表数据分散到多个库之中,每个表中包含一部分数据,即水平切分不改变表结构。
2.2 垂直切分
先来一张简单的示意图,大家感受一下垂直切分:

所谓的垂直切分就是拿着我 40 米大刀,对准了黑色的线条砍。砍完之后,将不同的表放到不同的数据库实例中去,变成下面这个样子:



这个时候我们发现如下几个特点:
- 每一个数据库实例中的表的数量都是不完整的。
- 每一个数据库实例中表的数据是完整的。
这就是垂直切分。一般来说,垂直切分我们可以按照业务来划分,不同业务的表放到不同的数据库实例中。
MySQL 数据库支持的分区类型为水平分区。
此外,MySQL 数据库的分区是局部分区索引,即一个分区中既存放了数据又存放了索引,目前,MySQL数据库还不支持全局分区(数据存放在各个分区中,但是所有数据的索引放在一个对象中)。
3. 为什么需要表分区
- 可以让单表存储更多的数据。
- 分区表的数据更容易维护,可以通过清除整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作。
- 部分查询能够从查询条件确定只落在少数分区上,查询速度会很快。
- 分区表的数据还可以分布在不同的物理设备上,从而高效利用多个硬件设备。
- 可以使用分区表来避免某些特殊瓶颈,例如 InnoDB 单个索引的互斥访问、ext3 文件系统的 inode 锁竞争。
- 可以备份和恢复单个分区。
分区的限制和缺点:
- 一个表最多只能有 1024 个分区。
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
- 分区表无法使用外键约束。
- NULL 值会使分区过滤无效。
- 所有分区必须使用相同的存储引擎。
4. 分区实践
说了这么多,来个例子看一下。
首先我们先来查看一下当前的 MySQL 是否支持分区。
在 MySQL5.6.1 之前可以通过命令 show variables like '%have_partitioning%' 来查看 MySQL 是否支持分区。如果 have_partitioning 的值为 YES,则表示支持分区。
从 MySQL5.6.1 开始,have_partitioning 参数已经被去掉了,而是用 SHOW PLUGINS 来代替。若有 partition 行且 STATUS 列的值为 ACTIVE,则表示支持分区,如下所示:

确认我们的 MySQL 支持分区后,我们就可以开始分区啦!
接下来我们来看几种不同的分区策略。
4.1 RANGE 分区
RANGE 分区比较简单,就是根据某一个字段的值进行分区。不过这个字段有一个要求,就是必须是主键或者是联合主键中的某个字段。
例如根据 user 表的 id 进行分区:
- 当 id 小于 100,数据插入 p0 分区;
- 当 id 大于等于 100 小于 200 的时候,插入 p1 分区;
- 如果 id 大于等于 200 则插入 p2 分区。
上面的规则涉及到了 id 的所有范围了,如果没有第三条规则,那么插入一个 id 为 300 的记录时,就会报错。
建表 SQL 如下:
create table user(
id int primary key,
username varchar(255)
)engine=innodb
partition by range(id)(
partition p0 values less than(100),
partition p1 values less than(200),
partition p2 values less than maxvalue
);表创建成功后,我们进入到 /var/lib/mysql/test08 文件夹中,来看刚刚创建的表文件:

可以看到,此时的数据文件分为好几个了。
在 information_schema.partitions 表中,我们可以查看分区的详细信息:
![]()
也可以自己写个 SQL 去查询:
select * from information_schema.partitions where table_schema='test08' and table_name='user'\G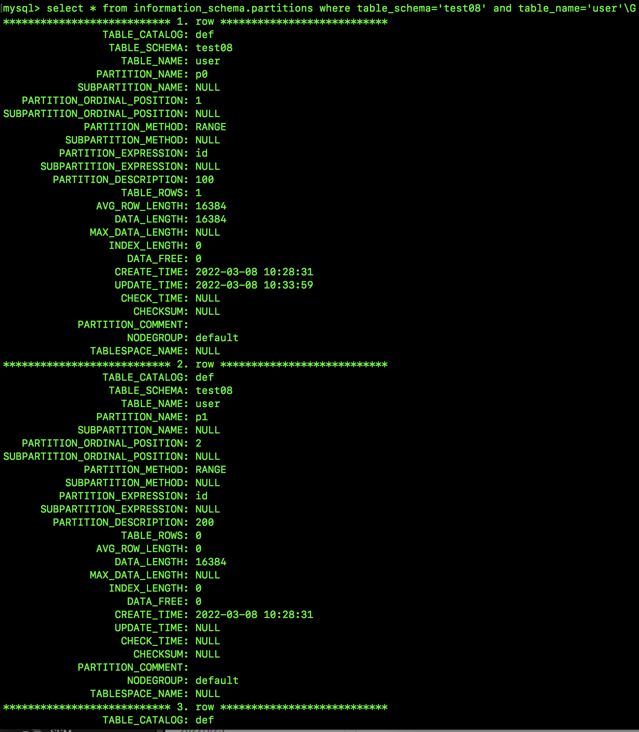
每一行展示一个分区的信息,包括分区的方式、该区的范围、分区的字段、该区目前有几条记录等等。
RANGE 分区有一个比较典型的使用场景,就是按照日期对表进行分区,例如同一年注册的用户放在一个分区中,如下:
create table user(
id int,
username varchar(255),
password varchar(255),
createDate date,
primary key (id,createDate)
)engine=innodb
partition by range(year(createDate))(
partition p2022 values less than(2023),
partition p2023 values less than(2024),
partition p2024 values less than(2025)
);注意,createDate 是联合主键的一员。如果 createDate 不是主键,只是一个普通字段,那么创建时就会抛出如下错误:
![]()
现在,如果我们要查询 2022 年注册的用户,系统就只会去搜索 p2022 这个分区,通过 explain 执行计划可以证实我们的想法:

如果想要删除 2022 年注册的用户,则只需要删除该分区即可:
alter table user drop partition p2022;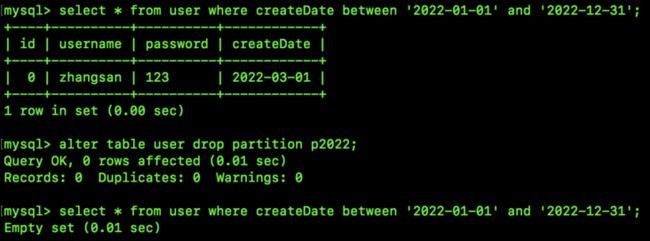
由上图可以看到,删除之后,数据就没了。
4.2 LIST 分区
LIST 分区和 RANGE 分区类似,区别在于 LIST 分区是基于列值匹配一个离散值集合中的某个值来进行选择,而非连续的。举个例子大家看下就明白了:
假设我有一个用户表,用户有性别,现在想按照性别将用户分开存储,男性存储在一个分区中,女性存储在一个分区中,SQL 如下:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
)engine=innodb
partition by list(gender)(
partition man values in (1),
partition woman values in (0));这个表将来就两个分区,分别存储男性和女性,gender 的取值为 1 或者 0,gender 如果取其他值,执行就会出错,最终执行结果如下:
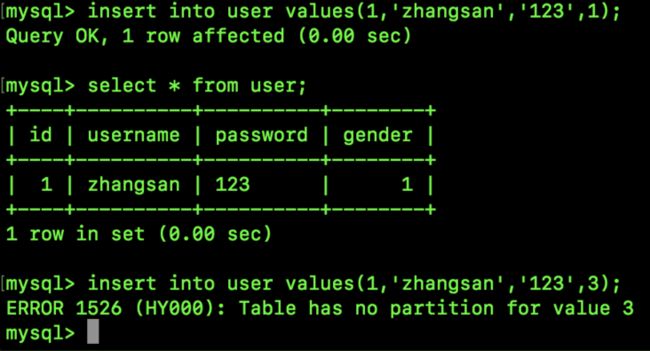
这样分区之后,将来查询男性或者查询女性效率都会比较高,删除某一性别的用户时删除效率也高。
4.3 HASH 分区
HASH 分区的目的是将数据均匀地分布到预先定义的各个分区中,保证各分区的数据量大致都是一样的。在 RANGE 和 LIST 分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中;而在 HASH 分区中,MySQL 自动完成这些工作,用户所要做的只是基于将要进行哈希分区的列指定一个表达式,并且分区的数量。
使用 HASH 分区来分割一个表,要在 CREATE TABLE 语句上添加 PARTITION BY HASH (expr),其中 expr 是一个字段或者是一个返回整数的表达式;另外通过 PARTITIONS 属性指定分区的数量,如果没有指定,那么分区的数量默认为 1,另外,HASH 分区不能删除分区,所以不能使用 DROP PARTITION 操作进行分区删除操作。
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
)engine=innodb partition by hash(id) partitions 4;4.4 KEY 分区
KEY 分区和 HASH 分区相似,但是 KEY 分区支持除 text 和 BLOB 之外的所有数据类型的分区,而 HASH 分区只支持数字分区。
KEY 分区不允许使用用户自定义的表达式进行分区,KEY 分区使用系统提供的 HASH 函数进行分区。
当表中存在主键或者唯一索引时,如果创建 KEY 分区时没有指定字段系统默认会首选主键列作为分区字段,如果不存在主键列会选择非空唯一索引列作为分区字段。
举个例子:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
)engine=innodb partition by key(id) partitions 4;4.5 COLUMNS 分区
COLUMN 分区是 5.5 开始引入的分区功能,只有 RANGE COLUMN 和 LIST COLUMN 这两种分区;支持整形、日期、字符串;这种分区方式和 RANGE、LIST 的分区方式非常的相似。
COLUMNS Vs RANGE Vs LIST 分区:
- 针对日期字段的分区不需要再使用函数进行转换了。
- COLUMN 分区支持多个字段作为分区键但是不支持表达式作为分区键。
COLUMNS 支持的类型
- 整形支持:tinyint、smallint、mediumint、int、bigint;不支持 decimal 和 float。
- 时间类型支持:date、datetime。
- 字符类型支持:char、varchar、binary、varbinary;不支持text、blob。
举个例子看下:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
createDate date,
primary key(id, createDate)
)engine=innodb PARTITION BY RANGE COLUMNS(createDate) (
PARTITION p0 VALUES LESS THAN ('1990-01-01'),
PARTITION p1 VALUES LESS THAN ('2000-01-01'),
PARTITION p2 VALUES LESS THAN ('2010-01-01'),
PARTITION p3 VALUES LESS THAN ('2020-01-01'),
PARTITION p4 VALUES LESS THAN MAXVALUE
);这是 RANGE COLUMNS,分区值是连续的。
再来看 LIST COLUMNS 分区,这个就类似于枚举了:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
createDate date,
primary key(id, createDate)
)engine=innodb PARTITION BY LIST COLUMNS(createDate) (
PARTITION p0 VALUES IN ('1990-01-01'),
PARTITION p1 VALUES IN ('2000-01-01'),
PARTITION p2 VALUES IN ('2010-01-01'),
PARTITION p3 VALUES IN ('2020-01-01')
);5. 常见分区命令
- 添加分区:
alter table user add partition (partition p3 values less than (4000)); -- range 分区alter table user add partition (partition p3 values in (40)); -- lists分区- 删除表分区(会删除数据):
alter table user drop partition p30;- 删除表的所有分区(不会丢失数据):
alter table user remove partitioning; - 重新定义 range 分区表(不会丢失数据):
alter table user partition by range(salary)(
partition p1 values less than (2000),
partition p2 values less than (4000)); - 重新定义 hash 分区表(不会丢失数据):
alter table user partition by hash(salary) partitions 7; - 合并分区:把 2 个分区合并为一个,不会丢失数据:
alter table user reorganize partition p1,p2 into (partition p1 values less than (1000));6. 小结
不知道小伙伴们是否还记得松哥 2019 年写的 MyCat 教程(公众号江南一点雨后台回复 2019 有文章索引),这些分区策略是不是和 MyCat 中的策略非常相似呀?感兴趣的小伙伴赶紧去试一把吧~
参考资料: