GNN Tricks《Bag of Tricks of Semi-Supervised Classification with Graph Neural Networks》
Wang Y. Bag of Tricks of Semi-Supervised Classification with Graph Neural Networks[J]. arXiv preprint arXiv:2103.13355, 2021.
我在浏览OGB排行榜代码的时候偶然发现了一篇关于GNN的Tricks的文章,作者是DGL Team的大佬,这篇貌似还没有被会议接受,不过已经在Arxiv上preprint出来了。本文改进后的几个模型在几个OGB数据集上的表现都不错。所以就赶快拿过来看看,学习一下,还是受到了一些启发。代码的话是用DGL框架和规范写的,现在还看不太懂,等我先把DGL框架学一下再好好拜读一下code。
本文配套的ogbn-arxiv代码:https://github.com/Espylapiza/dgl/tree/master/examples/pytorch/ogb/ogbn-arxiv
目前我按照作者的思路试了一下label use(PyG代码),并没有对我的模型(GCN内核)起到什么效果。ogbn-arxiv排行榜我的是13名,用了label use的模型是16名。。
PS:我记得当年CNN也有一篇《Bag of Tricks…》,很经典,可以参考《深度学习 cnn trick合集》。
文章目录
-
- Abstract
- 1. Introduction
- 2. Preliminary
-
- 2.1. Problem Formulation
- 2.2. Existing Tricks
- 3. Methodology
-
- 3.1. Label Usage
- 3.2. Loss Function
- 3.3. Architecture Design
- 4. Experiments
- 我的总结与思考
Abstract
作者表示,关于GNN的模型结构改进方法现在有不少,但是这些paper里常常会忽略模型实现的一些Tricks(可能觉得太low所以闭口不提),只有当你去看code的时候才会发现一些细节和Tricks。
但是,这些被忽略的技术/trick在GNN的实践中起到了十分重要的作用,并且往往伴随着模型精度的提升。
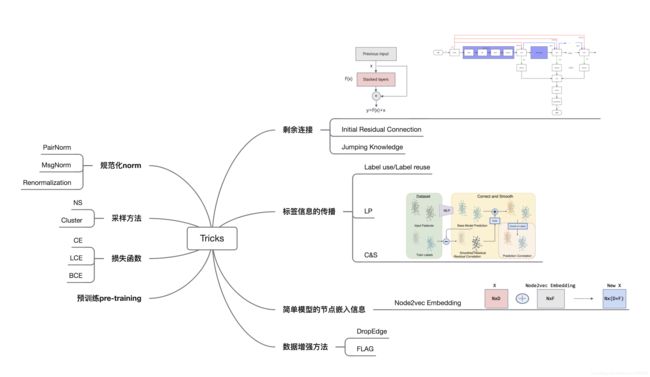
本文就提出了一些GNN中的新技巧,包括模型设计+标签使用等等。
1. Introduction
从OGB排行榜上可以十分直观的发现,模型精度的提升不仅仅依赖于模型(体系)结构的改变,也就是说并不一定要提出新的GNN模型,从技巧或Tricks上进行改进也能提升模型性能、发paper(比如本文,哈哈哈)。
作者发现,目前的GNN模型缺乏对节点标签信息的使用。虽然说最近出现了LPA相关的算法,比如LP、C&S,但是基于LP的算法的理论动机是要求相邻节点具有相似的label,但是在异构图中貌似并不是这样的,并且LPA算法也不能直接处理加权图。
本文提出的新技术主要涉及标签使用和架构设计,后面会详细说。
2. Preliminary
2.1. Problem Formulation
Label Propagation Algorithm.
LPA算法就是通过边/邻接关系,把节点的标签信息传播给邻居节点。(这里和文章中的不太一样,是加了残差传播的版本)
Y ′ = α ⋅ D − 1 / 2 A D − 1 / 2 Y + ( 1 − α ) Y \mathbf{Y}^{\prime} = \alpha \cdot \mathbf{D}^{-1/2} \mathbf{A} \mathbf{D}^{-1/2} \mathbf{Y} + (1 - \alpha) \mathbf{Y} Y′=α⋅D−1/2AD−1/2Y+(1−α)Y
Combination of Label and Feature Usages.
LP、C&S等方法可能会导致产生次优解,我在实践中也有体会,有时候用C&S,模型的性能反而会下降。
2.2. Existing Tricks
Data Augmentation.
数据增强方法。在之前的笔记中我也对这方面有所关注,主要是Dropout和FLAG。
Sampling.
采样方法。采样除了被应用于缩小每次训练的图规模(minibatch),还可以被当做是一种训练或正则化技巧。代表性方法有FastGCN(分层采用)、LADIES(层重要性采样)以及NLP(word2vec)当中的负采样技术。
Renormalization.
GCN中提出的重归一化,用于缓解数值不稳定和梯度爆炸。
3. Methodology
3.1. Label Usage
主要是将节点的标签也作为输入。由于节点的标签信息能够提供更多的信息,所以如果能利用好label的话理论上会对模型性能提升有很大帮助。
本文在label use方面提出的Trick主要是通过mask技术,将初始节点特征和label(经过mask后的)拼接后作为输入,以从标签信息中学习到更多的标签信息。
label use大体思路就是:(PyG代码,可自己体会,比较难描述)
def add_labels(feat, labels, idx):
onehot = torch.zeros([feat.shape[0], dataset.num_classes]).to(device)
onehot[idx, labels[idx, 0]] = 1
return torch.cat([feat, onehot], dim=-1)
# 定义训练函数
def train():
model.train()
mask_rate = 0.5
mask = torch.rand(train_idx.shape) < mask_rate
train_labels_idx = train_idx[mask]
train_pred_idx = train_idx[~mask]
feat = add_labels(x, y, train_labels_idx)
out = model(feat, data.adj_t)
loss = criterion(out[train_pred_idx], data.y.squeeze(1)[train_pred_idx])
# loss = cross_entropy(out[train_idx], data.y[train_idx])
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
Augmentation with Label Reuse.
label reuse等什么时候看了作者的code之后再说吧。主要思想是用上一次迭代的预测值来代替常数0。
3.2. Loss Function
主要是对CrossEntropy损失函数进行了小改动(CE–>LCE),并证明了LCE鲁棒性更好。
改进方面是在CE的基础上增加了超参数 ϵ \epsilon ϵ=1e-2。就不上公式了,pytorch代码更易懂一些。
epsilon = 1 - math.log(2)
def cross_entropy(x, labels):
y = F.cross_entropy(x, labels[:, 0], reduction="none")
y = torch.log(epsilon + y) - math.log(epsilon)
return torch.mean(y)
3.3. Architecture Design
Architecture Variant for GCN.
对于GCN内核的改进主要是仿照skip-connection,增加了一个linear层(公式里后面那一项),以保证每个节点的输出都不同,以缓解过平滑。
X ( k + 1 ) = σ ( ( D ~ − 1 2 A ~ D ~ − 1 2 ) X ( k ) W 0 ( k ) + X ( k ) W 1 ( k ) ) X^{(k+1)}=\sigma \left(\left(\tilde D^{-\frac12}\tilde A\tilde D^{-\frac12}\right)X^{(k)}W_0^{(k)}+X^{(k)}W_1^{(k)}\right) X(k+1)=σ((D~−21A~D~−21)X(k)W0(k)+X(k)W1(k))
def forward(self, graph, feat):
h = feat
h = self.input_drop(h)
for i in range(self.n_layers):
conv = self.convs[i](graph, h)
if self.use_linear:
linear = self.linear[i](h)
h = conv + linear
else:
h = conv
if i < self.n_layers - 1:
h = self.norms[i](h)
h = self.activation(h)
h = self.dropout(h)
return h
Architecture Variant for GAT.
GAT的改动就比较大了,并且从实验结果来看,改进策略相当成功!不仅成功优化了训练时的内存占用,还能够和其他策略一起,提升模型的精度,值得我好好学习GAT的代码以及策略。
(我用PyG复现的GAT跑,16GB显卡会出现GPU内存溢出的问题,并且效果贼差,看来是时候好好学习一下DGL了)
从公式上看,改进后的GAT和GCN形式貌似差不多。
X ( k + 1 ) = σ ( ( D ~ − 1 2 A ~ a t t D ~ − 1 2 ) X ( k ) W 0 ( k ) + X ( k ) W 1 ( k ) ) X^{(k+1)}=\sigma \left(\left(\tilde D^{-\frac12}\tilde A_{att}\tilde D^{-\frac12}\right)X^{(k)}W_0^{(k)}+X^{(k)}W_1^{(k)}\right) X(k+1)=σ((D~−21A~attD~−21)X(k)W0(k)+X(k)W1(k))
当 A ~ a t t = A \tilde A_{att}=A A~att=A时,GAT就退化成了GCN。 A ~ a t t \tilde A_{att} A~att是归一化后的注意力矩阵,具体的实现还需要去仔细研究一下代码。
4. Experiments
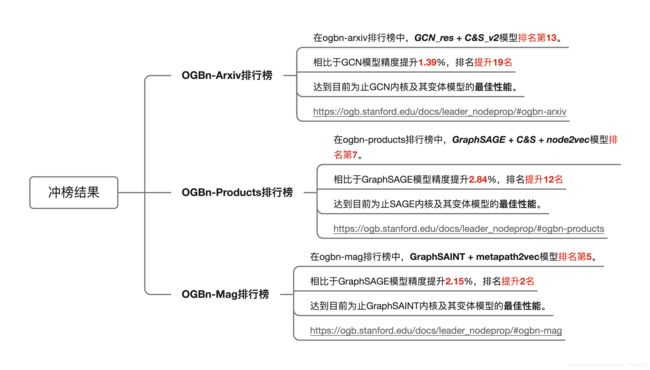
作者主要在ogbn-arxiv、ogbn-products和ogbn-proteins这三个数据集上进行了实验,结果就不赘述了。
我的总结与思考
近期会研究一下Tricks以及OGB冲榜。看来这次DGL是不得不学了。
我的博客:我向OGB排行榜提交代码的经历。