Elasticsearch顶尖高手系列:高手进阶篇(一)
Elasticsearch顶尖高手系列:高手进阶篇(一)
- 第1-29节
-
- 01_搜索_IT技术论坛案例背景介绍
- 02_搜索_term filter
- 03_搜索_filter原理(bitset机制与caching机制)
- 04_搜索_bool组合多个filter条件
- 05_搜索_terms搜索
- 06_搜索_filter range范围过滤
- 07_搜索_operator、minimum_should_match控制精度
- 08_搜索_term+bool实现的multiword
- 09_搜索_boost权重
- 10_搜索_多shard下relevance score不准确
- 11_搜索_dis_max实现best fields多字段搜索
- 12_搜索_tie_breaker优化dis_max搜索
- 13_搜索_multi_match+best-fields策略
- 14_搜索_multi_match+most fiels策略
- 15_搜索_most_fields策略进行cross-fields搜索
- 16_搜索_copy_to定制组合field解决cross-fields搜索弊端
- 17_搜索_cross-fiels解决搜索弊端
- 18_搜索_match_phrase搜索
- 19_搜索_match_phrase的slop参数实现近似匹配
- 20_搜索_match_phrase和match召回率与精准度的平衡
- 21_搜索_match_phrase的rescore近似匹配优化
- 22_搜索_prefix前缀、wildcard通配符、regexp正则搜索等技术
- 23_搜索_match_phrase_prefix搜索推荐
- 24_搜索_ngram分词机制实现index-time搜索推荐
- 25_搜索_深入揭秘TF&IDF算法以及向量空间模型算法
- 26_搜索_深入揭秘lucene的相关度分数算法
- 27_搜索_四种常见的相关度分数优化方法
- 28_搜索_function_score自定义相关度分数
- 29_搜索_fuzzy误拼写模糊搜索、_delete_by_query
- 第30-58节
-
- 30_IK中文分词
- 31_IK中文分词_配置文件以及自定义词库
- 32_IK中文分词_修改IK分词器源码来基于mysql热更新词库
- 33_聚合分析_bucket与metric两个核心概念的讲解
- 34_聚合分析_aggs+terms
- 35_聚合分析_aggs+terms+avg统计每种颜色电视平均价格
- 36_聚合分析_bucket嵌套实现颜色+品牌的多层下钻分析
- 37_聚合分析_统计每种颜色电视最大最小价格
- 38_聚合分析_hitogram按价格区间统计电视销量和销售额
- 39_聚合分析_date hitogram之统计每月电视销量
- 40_聚合分析_date_histogram统计每季度每个品牌的销售额
- 41_聚合分析_query+filter:统计指定品牌下每个颜色的销量
- 42_聚合分析_global bucket:单个品牌与所有品牌销量对比
- 43_聚合分析_filter+aggs:统计价格大于1200的电视平均价格
- 44_聚合分析_bucket filter:统计牌品最近一个月的平均价格
- 45_聚合分析_排序:按每种颜色的平均销售额降序排序
- 46_聚合分析_颜色+品牌下钻分析时按最深层metric进行排序
- 47_聚合分析_易并行聚合算法,三角选择原则,近似聚合算法
- 48_聚合分析_cardinality去重每月销售品牌数量统计
- ==49_聚合分析_cardinality算法之优化内存开销以及HLL算法==
- 50_聚合分析_percentiles百分比算法以及网站访问时延统计
- 51_聚合分析_percentiles rank以及网站访问时延SLA统计
- 52_聚合分析_doc value正排索引的聚合
- 53_聚合分析_doc value机制内核级原理深入探秘
- 54_聚合分析_string field聚合实验以及fielddata
- 55_聚合分析_fielddata内存控制以及circuit breaker断路器
- 56_聚合分析_fielddata filter的细粒度内存加载控制
- 57_聚合分析_fielddata预加载机制以及序号标记预加载
- ==58_聚合分析_海量bucket优化机制:从深度优先到广度优先==
第1-29节
01_搜索_IT技术论坛案例背景介绍
课程大纲
IT技术论坛,案例背景
IT技术论坛中相关的数据,会在es中建立数据的索引
深度讲解搜索,数据分析,数据建模
特色:纯手工画图剖析各种原理,纯实战驱动讲解各种知识点,知识体系的细致和完整
怎么实战驱动?
核心知识篇,上半季,我们也是纯实战驱动,但是之前没有一个统一的案例背景
IT技术论坛,发各种IT技术的帖子:一种是自己研究了一个技术,就发出来一些研究心得;自己遇到了问题,发个帖子问一问。帖子会有人回复,还会有人浏览。当然了,还有一些论坛会提供简单社交的一个功能,互相加好友,互相关注,互相点赞,之类的。
在IT技术论坛的背景下,去开发一些跟案例背景相关的搜索或者数据分析,或者数据建模的需求,用每一讲学到的知识点,去接解决一些问题
既可以学到知识和技术,也可以在真实的案例背景中练习一下学到的东西
02_搜索_term filter
课程大纲
1、根据用户ID、是否隐藏、帖子ID、发帖日期来搜索帖子
(1)插入一些测试帖子数据
POST /forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }
初步来说,就先搞4个字段,因为整个es是支持json document格式的,所以说扩展性和灵活性非常之好。如果后续随着业务需求的增加,要在document中增加更多的field,那么我们可以很方便的随时添加field。但是如果是在关系型数据库中,比如mysql,我们建立了一个表,现在要给表中新增一些column,那就很坑爹了,必须用复杂的修改表结构的语法去执行。而且可能对系统代码还有一定的影响。
GET /forum/_mapping/article
{
"forum": {
"mappings": {
"article": {
"properties": {
"articleID": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"hidden": {
"type": "boolean"
},
"postDate": {
"type": "date"
},
"userID": {
"type": "long"
}
}
}
}
}
}
现在es 5.2版本,type=text,默认会设置两个field,一个是field本身,比如articleID,就是分词的;还有一个的话,就是field.keyword,articleID.keyword,默认不分词,会最多保留256个字符
(2)根据用户ID搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"userID" : 1
}
}
}
}
}
term filter/query:对搜索文本不分词,直接拿去倒排索引中匹配,你输入的是什么,就去匹配什么
比如说,如果对搜索文本进行分词的话,“helle world” --> “hello”和“world”,两个词分别去倒排索引中匹配
term,“hello world” --> “hello world”,直接去倒排索引中匹配“hello world”
(3)搜索没有隐藏的帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"hidden" : false
}
}
}
}
}
(4)根据发帖日期搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"postDate" : "2017-01-01"
}
}
}
}
}
(5)根据帖子ID搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID.keyword" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01"
}
}
]
}
}
articleID.keyword,是es最新版本内置建立的field,就是不分词的。所以一个articleID过来的时候,会建立两次索引,一次是自己本身,是要分词的,分词后放入倒排索引;另外一次是基于articleID.keyword,不分词,保留256个字符最多,直接一个字符串放入倒排索引中。
所以term filter,对text过滤,可以考虑使用内置的field.keyword来进行匹配。但是有个问题,默认就保留256个字符。所以尽可能还是自己去手动建立索引,指定not_analyzed吧。在最新版本的es中,不需要指定not_analyzed也可以,将type=keyword即可。
(6)查看分词
GET /forum/_analyze
{
"field": "articleID",
"text": "XHDK-A-1293-#fJ3"
}
默认是analyzed的text类型的field,建立倒排索引的时候,就会对所有的articleID分词,分词以后,原本的articleID就没有了,只有分词后的各个word存在于倒排索引中。
term,是不对搜索文本分词的,XHDK-A-1293-#fJ3 --> XHDK-A-1293-#fJ3;但是articleID建立索引的时候,XHDK-A-1293-#fJ3 --> xhdk,a,1293,fj3
(7)重建索引
DELETE /forum
PUT /forum
{
"mappings": {
"article": {
"properties": {
"articleID": {
"type": "keyword"
}
}
}
}
}
POST /forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }
(8)重新根据帖子ID和发帖日期进行搜索
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
2、梳理学到的知识点
(1)term filter:根据exact value进行搜索,数字、boolean、date天然支持
(2)text需要建索引时指定为not_analyzed,才能用term query
(3)相当于SQL中的单个where条件
select *
from forum.article
where articleID=‘XHDK-A-1293-#fJ3’
03_搜索_filter原理(bitset机制与caching机制)
课程大纲
(1)在倒排索引中查找搜索串,获取document list
date来举例
| word | doc1 | doc2 | doc3 |
| 2017-01-01 | * | * | |
| 2017-02-02 | * | * | |
| 2017-03-03 | * | * | * |
filter:2017-02-02
到倒排索引中一找,发现2017-02-02对应的document list是doc2,doc3
(2)为每个在倒排索引中搜索到的结果,构建一个bitset,[0, 0, 0, 1, 0, 1]
非常重要
使用找到的doc list,构建一个bitset,就是一个二进制的数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0
[0, 1, 1]
doc1:不匹配这个filter的
doc2和do3:是匹配这个filter的
尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能
(3)遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document
后面会讲解,一次性其实可以在一个search请求中,发出多个filter条件,每个filter条件都会对应一个bitset
遍历每个filter条件对应的bitset,先从最稀疏的开始遍历
[0, 0, 0, 1, 0, 0]:比较稀疏
[0, 1, 0, 1, 0, 1]
先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据
遍历所有的bitset,找到匹配所有filter条件的doc
请求:filter,postDate=2017-01-01,userID=1
postDate: [0, 0, 1, 1, 0, 0]
userID: [0, 1, 0, 1, 0, 1]
遍历完两个bitset之后,找到的匹配所有条件的doc,就是doc4
就可以将document作为结果返回给client了
(4)caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
比如postDate=2017-01-01,[0, 0, 1, 1, 0, 0],可以缓存在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,反复生成bitset,可以大幅度提升性能。
在最近的256个filter中,有某个filter超过了一定的次数,次数不固定,就会自动缓存这个filter对应的bitset
segment(上半季),filter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小 segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了 针对一个小segment的bitset,[0, 0, 1, 0] filter比query的好处就在于会caching,但是之前不知道caching的是什么东西,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存起来。下次不用扫描倒排索引了。 (5)filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据 query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序 (6)如果document有新增或修改,那么cached bitset会被自动更新 postDate=2017-01-01,[0, 0, 1, 0] (7)以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset 课程大纲 1、搜索发帖日期为2017-01-01,或者帖子ID为XHDK-A-1293-#fJ3的帖子,同时要求帖子的发帖日期绝对不为2017-01-02 select * must,should,must_not,filter:必须匹配,可以匹配其中任意一个即可,必须不匹配 2、搜索帖子ID为XHDK-A-1293-#fJ3,或者是帖子ID为JODL-X-1937-#pV7而且发帖日期为2017-01-01的帖子 select * 3、梳理学到的知识点 (1)bool:must,must_not,should,组合多个过滤条件 课程大纲 term: {“field”: “value”} sql中的in select * from tbl where col in (“value1”, “value2”) 1、为帖子数据增加tag字段 2、搜索articleID为KDKE-B-9947-#kL5或QQPX-R-3956-#aD8的帖子,搜索tag中包含java的帖子 3、优化搜索结果,仅仅搜索tag只包含java的帖子 [“java”, “hadoop”, “elasticsearch”] 4、学到的知识点梳理 (1)terms多值搜索 课程大纲 1、为帖子数据增加浏览量的字段 gte 3、搜索发帖日期在最近1个月的帖子 4、梳理一下学到的知识点 (1)range,sql中的between,或者是>=1,<=1 课程大纲 1、为帖子数据增加标题字段 2、搜索标题中包含java或elasticsearch的blog 这个,就跟之前的那个term query,不一样了。不是搜索exact value,是进行full text全文检索。 GET /forum/article/_search 3、搜索标题中包含java和elasticsearch的blog 搜索结果精准控制的第一步:灵活使用and关键字,如果你是希望所有的搜索关键字都要匹配的,那么就用and,可以实现单纯match query无法实现的效果 4、搜索包含java,elasticsearch,spark,hadoop,4个关键字中,至少3个的blog 控制搜索结果的精准度的第二步:指定一些关键字中,必须至少匹配其中的多少个关键字,才能作为结果返回 5、用bool组合多个搜索条件,来搜索title 6、bool组合多个搜索条件,如何计算relevance score must和should搜索对应的分数,加起来,除以must和should的总数 排名第一:java,同时包含should中所有的关键字,hadoop,elasticsearch should是可以影响相关度分数的 must是确保说,谁必须有这个关键字,同时会根据这个must的条件去计算出document对这个搜索条件的relevance score 7、搜索java,hadoop,spark,elasticsearch,至少包含其中3个关键字 默认情况下,should是可以不匹配任何一个的,比如上面的搜索中,this is java blog,就不匹配任何一个should条件 但是可以精准控制,should的4个条件中,至少匹配几个才能作为结果返回 梳理一下学到的知识点 1、全文检索的时候,进行多个值的检索,有两种做法,match query;should 课程大纲 1、普通match如何转换为term+should 使用诸如上面的match query进行多值搜索的时候,es会在底层自动将这个match query转换为bool的语法 2、and match如何转换为term+must 3、minimum_should_match如何转换 上一讲,为啥要讲解两种实现multi-value搜索的方式呢?实际上,就是给这一讲进行铺垫的。match query --> bool + term。 课程大纲 需求:搜索标题中包含java的帖子,同时呢,如果标题中包含hadoop或elasticsearch就优先搜索出来,同时呢,如果一个帖子包含java hadoop,一个帖子包含java elasticsearch,包含hadoop的帖子要比elasticsearch优先搜索出来 知识点,搜索条件的权重,boost,可以将某个搜索条件的权重加大,此时当匹配这个搜索条件和匹配另一个搜索条件的document,计算relevance score时,匹配权重更大的搜索条件的document,relevance score会更高,当然也就会优先被返回回来 默认情况下,搜索条件的权重都是一样的,都是1 课程大纲 1、多shard场景下relevance score不准确问题大揭秘 如果你的一个index有多个shard的话,可能搜索结果会不准确 图解 2、如何解决该问题? (1)生产环境下,数据量大,尽可能实现均匀分配 数据量很大的话,其实一般情况下,在概率学的背景下,es都是在多个shard中均匀路由数据的,路由的时候根据_id,负载均衡 (2)测试环境下,将索引的primary shard设置为1个,number_of_shards=1,index settings 如果说只有一个shard,那么当然,所有的document都在这个shard里面,就没有这个问题了 (3)测试环境下,搜索附带search_type=dfs_query_then_fetch参数,会将local IDF取出来计算global IDF 计算一个doc的相关度分数的时候,就会将所有shard对的local IDF计算一下,获取出来,在本地进行global IDF分数的计算,会将所有shard的doc作为上下文来进行计算,也能确保准确性。但是production生产环境下,不推荐这个参数,因为性能很差。 课程大纲 1、为帖子数据增加content字段 2、搜索title或content中包含java或solution的帖子 下面这个就是multi-field搜索,多字段搜索 3、结果分析 期望的是doc5,结果是doc2,doc4排在了前面 计算每个document的relevance score:每个query的分数,乘以matched query数量,除以总query数量 算一下doc4的分数 { “match”: { “title”: “java solution” }},针对doc4,是有一个分数的 所以是两个分数加起来,比如说,1.1 + 1.2 = 2.3 2.3 * 2 / 2 = 2.3 算一下doc5的分数 { “match”: { “title”: “java solution” }},针对doc5,是没有分数的 所以说,只有一个query是有分数的,比如2.3 2.3 * 1 / 2 = 1.15 doc5的分数 = 1.15 < doc4的分数 = 2.3 4、best fields策略,dis_max best fields策略,就是说,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面 dis_max语法,直接取多个query中,分数最高的那一个query的分数即可 { “match”: { “title”: “java solution” }},针对doc4,是有一个分数的,1.1 { “match”: { “title”: “java solution” }},针对doc5,是没有分数的 然后doc4的分数 = 1.2 < doc5的分数 = 2.3,所以doc5就可以排在更前面的地方,符合我们的需要 GET /forum/article/_search 课程大纲 1、搜索title或content中包含java beginner的帖子 有些场景不是太好复现的,因为是这样,你需要尝试去构造不同的文本,然后去构造一些搜索出来,去达到你要的一个效果 可能在实际场景中出现的一个情况是这样的: (1)某个帖子,doc1,title中包含java,content不包含java beginner任何一个关键词 dis_max,只是取分数最高的那个query的分数而已。 2、dis_max只取某一个query最大的分数,完全不考虑其他query的分数 3、使用tie_breaker将其他query的分数也考虑进去 tie_breaker参数的意义,在于说,将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算,除了取最高分以外,还会考虑其他的query的分数 课程大纲 minimum_should_match,主要是用来干嘛的? 课程大纲 从best-fields换成most-fields策略 sub_title用的是enligsh analyzer,所以还原了单词 为什么,因为如果我们用的是类似于english analyzer这种分词器的话,就会将单词还原为其最基本的形态,stemmer sub_titile: learning coureses --> learn course { “doc” : {“sub_title” : “learned a lot of course”} },就排在了{ “doc” : {“sub_title” : “learning more courses”} }的前面 很绕。。。。我自己都觉得很绕 很多东西,你看文字就觉得很绕,然后用语言去表述,也很绕,但是我觉得,用语言去说,相对来说会好一点点 你问我,具体的分数怎么算出来的,很难说,因为这个东西很复杂, 还不只是TF/IDF算法。因为不同的query,不同的语法,都有不同的计算score的细节。 与best_fields的区别 (1)best_fields,是对多个field进行搜索,挑选某个field匹配度最高的那个分数,同时在多个query最高分相同的情况下,在一定程度上考虑其他query的分数。简单来说,你对多个field进行搜索,就想搜索到某一个field尽可能包含更多关键字的数据 优点:通过best_fields策略,以及综合考虑其他field,还有minimum_should_match支持,可以尽可能精准地将匹配的结果推送到最前面 实际的例子:百度之类的搜索引擎,最匹配的到最前面,但是其他的就没什么区分度了 (2)most_fields,综合多个field一起进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,此时就会是个大杂烩,出现类似best_fields案例最开始的那个结果,结果不一定精准,某一个document的一个field包含更多的关键字,但是因为其他document有更多field匹配到了,所以排在了前面;所以需要建立类似sub_title.std这样的field,尽可能让某一个field精准匹配query string,贡献更高的分数,将更精准匹配的数据排到前面 优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的 实际的例子:wiki,明显的most_fields策略,搜索结果比较均匀,但是的确要翻好几页才能找到最匹配的结果 课程大纲 cross-fields搜索,一个唯一标识,跨了多个field。比如一个人,标识,是姓名;一个建筑,它的标识是地址。姓名可以散落在多个field中,比如first_name和last_name中,地址可以散落在country,province,city中。 跨多个field搜索一个标识,比如搜索一个人名,或者一个地址,就是cross-fields搜索 初步来说,如果要实现,可能用most_fields比较合适。因为best_fields是优先搜索单个field最匹配的结果,cross-fields本身就不是一个field的问题了。 Peter Smith,匹配author_first_name,匹配到了Smith,这时候它的分数很高,为什么啊??? 不要有过多的疑问,一定是这样吗? 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc 问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 课程大纲 上一讲,我们其实说了,用most_fields策略,去实现cross-fields搜索,有3大弊端,而且搜索结果也显示出了这3大弊端 第一个办法:用copy_to,将多个field组合成一个field 问题其实就出在有多个field,有多个field以后,就很尴尬,我们只要想办法将一个标识跨在多个field的情况,合并成一个field即可。比如说,一个人名,本来是first_name,last_name,现在合并成一个full_name,不就ok了吗。。。。。 用了这个copy_to语法之后,就可以将多个字段的值拷贝到一个字段中,并建立倒排索引 很无奈,很多时候,我们很难复现。比如官网也会给一些例子,说用什么什么文本,怎么怎么搜索,是怎么怎么样的效果。es版本在不断迭代,这个打分的算法也在不断的迭代。所以我们其实很难说,对类似这几讲讲解的best_fields,most_fields,cross_fields,完全复现出来应有的场景和效果。 更多的把原理和知识点给大家讲解清楚,带着大家演练一遍怎么操作的,做一下实验 期望的是说,比如大家自己在开发搜索应用的时候,碰到需要best_fields的场景,知道怎么做,知道best_fields的原理,可以达到什么效果;碰到most_fields的场景,知道怎么做,以及原理;碰到搜搜cross_fields标识的场景,知道怎么做,知道原理是什么,效果是什么。。。。 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc --> 解决,最匹配的document被最先返回 问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 --> 解决,可以使用minimum_should_match去掉长尾数据 问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 --> 解决,Smith和Peter在一个field了,所以在所有document中出现的次数是均匀的,不会有极端的偏差 课程大纲 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc --> 解决,要求每个term都必须在任何一个field中出现 Peter,Smith 要求Peter必须在author_first_name或author_last_name中出现 Peter Smith可能是横跨在多个field中的,所以必须要求每个term都在某个field中出现,组合起来才能组成我们想要的标识,完整的人名 原来most_fiels,可能像Smith Williams也可能会出现,因为most_fields要求只是任何一个field匹配了就可以,匹配的field越多,分数越高 问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 --> 解决,既然每个term都要求出现,长尾肯定被去除掉了 java hadoop spark --> 这3个term都必须在任何一个field出现了 比如有的document,只有一个field中包含一个java,那就被干掉了,作为长尾就没了 问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 --> 计算IDF的时候,将每个query在每个field中的IDF都取出来,取最小值,就不会出现极端情况下的极大值了 Peter Smith Peter Smith,在author_first_name这个field中,在所有doc的这个Field中,出现的频率很低,导致IDF分数很高;Smith在所有doc的author_last_name field中的频率算出一个IDF分数,因为一般来说last_name中的Smith频率都较高,所以IDF分数是正常的,不会太高;然后对于Smith来说,会取两个IDF分数中,较小的那个分数。就不会出现IDF分过高的情况。 近似匹配 1、什么是近似匹配 两个句子 java is my favourite programming language, and I also think spark is a very good big data system. match query,搜索java spark match query,只能搜索到包含java和spark的document,但是不知道java和spark是不是离的很近 包含java或包含spark,或包含java和spark的doc,都会被返回回来。我们其实并不知道哪个doc,java和spark距离的比较近。如果我们就是希望搜索java spark,中间不能插入任何其他的字符,那这个时候match去做全文检索,能搞定我们的需求吗?答案是,搞不定。 如果我们要尽量让java和spark离的很近的document优先返回,要给它一个更高的relevance score,这就涉及到了proximity match,近似匹配 如果说,要实现两个需求: 1、java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc 要实现上述两个需求,用match做全文检索,是搞不定的,必须得用proximity match,近似匹配 phrase match,proximity match:短语匹配,近似匹配 这一讲,要学习的是phrase match,就是仅仅搜索出java和spark靠在一起的那些doc,比如有个doc,是java use’d spark,不行。必须是比如java spark are very good friends,是可以搜索出来的。 phrase match,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回。不像是match,java spark,java的doc也会返回,spark的doc也会返回。 2、match_phrase 单单包含java的doc也返回了,不是我们想要的结果 将一个doc的content设置为恰巧包含java spark这个短语 match_phrase语法 成功了,只有包含java spark这个短语的doc才返回了,只包含java的doc不会返回 3、term position hello world, java spark doc1 hello doc1(0) 了解什么是分词后的position GET _analyze 索引中的position,match_phrase hello world, java spark doc1 hello doc1(0) java spark --> match phrase java spark --> java和spark java --> doc1(2) doc2(2) 要找到每个term都在的一个共有的那些doc,就是要求一个doc,必须包含每个term,才能拿出来继续计算 doc1 --> java和spark --> spark position恰巧比java大1 --> java的position是2,spark的position是3,恰好满足条件 doc1符合条件 doc2 --> java和spark --> java position是2,spark position是1,spark position比java position小1,而不是大1 --> 光是position就不满足,那么doc2不匹配 必须理解这块原理!!!! 因为后面的proximity match就是原理跟这个一模一样!!! slop的含义是什么? query string,搜索文本,中的几个term,要经过几次移动才能与一个document匹配,这个移动的次数,就是slop 实际举例,一个query string经过几次移动之后可以匹配到一个document,然后设置slop hello world, java is very good, spark is also very good. java spark,match phrase,搜不到 如果我们指定了slop,那么就允许java spark进行移动,来尝试与doc进行匹配 java is very good spark is java spark 这里的slop,就是3,因为java spark这个短语,spark移动了3次,就可以跟一个doc匹配上了 slop的含义,不仅仅是说一个query string terms移动几次,跟一个doc匹配上。一个query string terms,最多可以移动几次去尝试跟一个doc匹配上 slop,设置的是3,那么就ok 就可以把刚才那个doc匹配上,那个doc会作为结果返回 但是如果slop设置的是2,那么java spark,spark最多只能移动2次,此时跟doc是匹配不上的,那个doc是不会作为结果返回的 做实验,验证slop的含义 spark is best big data solution based on scala ,an programming language similar to java spark spark data spark is best big data data spark slop搜索下,关键词离的越近,relevance score就会越高,做实验说明。。。 其实,加了slop的phrase match,就是proximity match,近似匹配 1、java spark,短语,doc,phrase match 召回率 比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果,就是召回率,recall 精准度 比如你搜索一个java spark,能不能尽可能让包含java spark,或者是java和spark离的很近的doc,排在最前面,precision 直接用match_phrase短语搜索,会导致必须所有term都在doc field中出现,而且距离在slop限定范围内,才能匹配上 match phrase,proximity match,要求doc必须包含所有的term,才能作为结果返回;如果某一个doc可能就是有某个term没有包含,那么就无法作为结果返回 java spark --> hello world java --> 就不能返回了 近似匹配的时候,召回率比较低,精准度太高了 但是有时可能我们希望的是匹配到几个term中的部分,就可以作为结果出来,这样可以提高召回率。同时我们也希望用上match_phrase根据距离提升分数的功能,让几个term距离越近分数就越高,优先返回 就是优先满足召回率,意思,java spark,包含java的也返回,包含spark的也返回,包含java和spark的也返回;同时兼顾精准度,就是包含java和spark,同时java和spark离的越近的doc排在最前面 此时可以用bool组合match query和match_phrase query一起,来实现上述效果 match和phrase match(proximity match)区别 match --> 只要简单的匹配到了一个term,就可以理解将term对应的doc作为结果返回,扫描倒排索引,扫描到了就ok phrase match --> 首先扫描到所有term的doc list; 找到包含所有term的doc list; 然后对每个doc都计算每个term的position,是否符合指定的范围; slop,需要进行复杂的运算,来判断能否通过slop移动,匹配一个doc match query的性能比phrase match和proximity match(有slop)要高很多。因为后两者都要计算position的距离。 但是别太担心,因为es的性能一般都在毫秒级别,match query一般就在几毫秒,或者几十毫秒,而phrase match和proximity match的性能在几十毫秒到几百毫秒之间,所以也是可以接受的。 优化proximity match的性能,一般就是减少要进行proximity match搜索的document数量。主要思路就是,用match query先过滤出需要的数据,然后再用proximity match来根据term距离提高doc的分数,同时proximity match只针对每个shard的分数排名前n个doc起作用,来重新调整它们的分数,这个过程称之为rescoring,重计分。因为一般用户会分页查询,只会看到前几页的数据,所以不需要对所有结果进行proximity match操作。 用我们刚才的说法,match + proximity match同时实现召回率和精准度 默认情况下,match也许匹配了1000个doc,proximity match全都需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数 rescore:重打分 match:1000个doc,其实这时候每个doc都有一个分数了; proximity match,前50个doc,进行rescore,重打分,即可; 让前50个doc,term举例越近的,排在越前面 课程大纲 1、前缀搜索 C3D0-KD345 不用帖子的案例背景,因为比较简单,直接用自己手动建的新索引,给大家演示一下就可以了 2、前缀搜索的原理 prefix query不计算relevance score,与prefix filter唯一的区别就是,filter会cache bitset 扫描整个倒排索引,举例说明 前缀越短,要处理的doc越多,性能越差,尽可能用长前缀搜索 前缀搜索,它是怎么执行的?性能为什么差呢? match C3-D0-KD345 全文检索 每个字符串都需要被分词 c3 doc1,doc2 c3 --> 扫描倒排索引 --> 一旦扫描到c3,就可以停了,因为带c3的就2个doc,已经找到了 --> 没有必要继续去搜索其他的term了 match性能往往是很高的 不分词 C3-D0-KD345 c3 --> 先扫描到了C3-D0-KD345,很棒,找到了一个前缀带c3的字符串 --> 还是要继续搜索的,因为后面还有一个C3-K5-DFG65,也许还有其他很多的前缀带c3的字符串 --> 你扫描到了一个前缀匹配的term,不能停,必须继续搜索 --> 直到扫描完整个的倒排索引,才能结束 因为实际场景中,可能有些场景是全文检索解决不了的 C3D0-KD345 c3d0 c3 --> match --> 扫描整个倒排索引,能找到吗 c3 --> 只能用prefix prefix性能很差 跟前缀搜索类似,功能更加强大 C3D0-KD345 5字符-D任意个字符5 5?-*5:通配符去表达更加复杂的模糊搜索的语义 ?:任意字符 性能一样差,必须扫描整个倒排索引,才ok C[0-9].+ [0-9]:指定范围内的数字 wildcard和regexp,与prefix原理一致,都会扫描整个索引,性能很差 主要是给大家介绍一些高级的搜索语法。在实际应用中,能不用尽量别用。性能太差了。 搜索推荐,search as you type,搜索提示,解释一下什么意思 hello w --> 搜索 hello world hello w --> hello world 搜索推荐的功能 百度 --> elas --> elasticsearch --> elasticsearch权威指南 原理跟match_phrase类似,唯一的区别,就是把最后一个term作为前缀去搜索 hello就是去进行match,搜索对应的doc 也可以指定slop,但是只有最后一个term会作为前缀 max_expansions:指定prefix最多匹配多少个term,超过这个数量就不继续匹配了,限定性能 默认情况下,前缀要扫描所有的倒排索引中的term,去查找w打头的单词,但是这样性能太差。可以用max_expansions限定,w前缀最多匹配多少个term,就不再继续搜索倒排索引了。 尽量不要用,因为,最后一个前缀始终要去扫描大量的索引,性能可能会很差 1、ngram和index-time搜索推荐原理 什么是ngram quick,5种长度下的ngram ngram length=1,q u i c k 什么是edge ngram quick,anchor首字母后进行ngram q 使用edge ngram将每个单词都进行进一步的分词切分,用切分后的ngram来实现前缀搜索推荐功能 hello world h w doc1,doc2 helloworld min ngram = 1 h hello w hello --> hello,doc1 doc1,hello和w,而且position也匹配,所以,ok,doc1返回,hello world 搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了; 简单的拿前缀去倒排索引中匹配即可,如果匹配上了,那么就好了; match,全文检索 2、实验一下ngram hello world h w hello w h w hello w --> hello --> w 如果用match,只有hello的也会出来,全文检索,只是分数比较低 课程大纲 1、boolean model 类似and这种逻辑操作符,先过滤出包含指定term的doc query “hello world” --> 过滤 --> hello / world / hello & world 2、TF/IDF 单个term在doc中的分数 query: hello world --> doc.content hello对doc1的评分 TF: term frequency 找到hello在doc1中出现了几次,1次,会根据出现的次数给个分数 IDF:inversed document frequency 找到hello在所有的doc中出现的次数,3次 length norm hello搜索的那个field的长度,field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高 最后,会将hello这个term,对doc1的分数,综合TF,IDF,length norm,计算出来一个综合性的分数 hello world --> doc1 --> hello对doc1的分数,world对doc1的分数 --> 但是最后hello world query要对doc1有一个总的分数 --> vector space model 3、vector space model 多个term对一个doc的总分数 hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量 hello这个term,给的基于所有doc的一个评分就是2 [2, 5] query vector doc vector,3个doc,一个包含1个term,一个包含另一个term,一个包含2个term 3个doc doc1:包含hello --> [2, 0] 会给每一个doc,拿每个term计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector 画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数 每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数 如果是多个term,那么就是线性代数来计算,无法用图表示 课程大纲 我们boolean model、TF/IDF、vector space model 深入讲解TF/IDF算法,在lucene中,底层,到底进行TF/IDF算法计算的一个完整的公式是什么? 0、boolean model query: hello world “match”: { “bool”: { 普通multivalue搜索,转换为bool搜索,boolean model 1、lucene practical scoring function practical scoring function,来计算一个query对一个doc的分数的公式,该函数会使用一个公式来计算 score(q,d) = score(q,d) score(q,d) is the relevance score of document d for query q. 这个公式的最终结果,就是说是一个query(叫做q),对一个doc(叫做d)的最终的总评分 queryNorm(q) is the query normalization factor (new). queryNorm,是用来让一个doc的分数处于一个合理的区间内,不要太离谱,举个例子,一个doc分数是10000,一个doc分数是0.1,你们说好不好,肯定不好 coord(q,d) is the coordination factor (new). 简单来说,就是对更加匹配的doc,进行一些分数上的成倍的奖励 The sum of the weights for each term t in the query q for document d. ∑:求和的符号 ∑ (t in q):query中每个term,query = hello world,query中的term就包含了hello和world query中每个term对doc的分数,进行求和,多个term对一个doc的分数,组成一个vector space,然后计算吗,就在这一步 tf(t in d) is the term frequency for term t in document d. 计算每一个term对doc的分数的时候,就是TF/IDF算法 idf(t) is the inverse document frequency for term t. t.getBoost() is the boost that has been applied to the query (new). norm(t,d) is the field-length norm, combined with the index-time field-level boost, if any. (new). 2、query normalization factor queryNorm = 1 / √sumOfSquaredWeights sumOfSquaredWeights = 所有term的IDF分数之和,开一个平方根,然后做一个平方根分之1 3、query coodination 奖励那些匹配更多字符的doc更多的分数 Document 1 with hello → score: 1.5 Document 1 with hello → score: 1.5 * 1 / 3 = 0.5 把计算出来的总分数 * 匹配上的term数量 / 总的term数量,让匹配不同term/query数量的doc,分数之间拉开差距 4、field level boost 之前两节课,我觉得已经很了解整个es的相关度评分的算法了,算法思想,TF/IDF,vector model,boolean model; 实际的公式,query norm,query coordination,boost 对相关度评分进行调节和优化的常见的4种方法 重构查询结果,在es新版本中,影响越来越小了。一般情况下,没什么必要的话,大家不用也行。 搜索包含java,不包含spark的doc,但是这样子很死板 negative的doc,会乘以negative_boost,降低分数 4、constant_score 如果你压根儿不需要相关度评分,直接走constant_score加filter,所有的doc分数都是1,没有评分的概念了 前言 function_score简介 function_score参数 3.1 function_score 提供了几种加强_score计算的函数: 3.2 function_scroe其他辅助的参数 3.2.1 boost_mode 3.2.2 score_mode 3.2.3 max_boost 4 function_score查询模板 4.1 单个加强函数的查询模板 例如: 下面的例子,field_value_factor和gauss这两个加强函数会应用到所有文档上,而weight只会应用到满足filter的文档上,假设有个文档满足了filter的条件,那他就会得到3个加强score,这3个加强score会使用sum的方式合併成一个总加强score,然后才和old_score使用multiply的方式合并。 不要执著在调整function_score上,文档相关度的调整非常玄,“最相关的文档” 是一个难以触及的模糊概念,每个人对文档排序有著不同的想法,这很容易使人陷入持续反覆调整,但是确没有明显的进展。为了避免跳入这种死循环,在调整function_score时,一定要搭配监控用户操作,才有意义。 例如:如果返回的文档是用户想要的高相关的文档,那麽用户就会选择前10个中的一个文档,得到想要的结果,反之,用户可能会来回点击,或是尝试新的搜索条件。一旦有了这些监控手段,想要调适完美的function_score就不是问题。 因此,调整function_score的重点在于,要透过监控用户、和用户互动,慢慢去调整我们的搜索条件,而不要妄想一步登天,第一次就把文档的相关度调整到最好,这几乎是不可能的,因为,连用户自己也不知道他自己想要什麽。 function_score (field_value_factor具体实例) 给所有的帖子数据增加follower数量 将对帖子搜索得到的分数,跟follower_num进行运算,由follower_num在一定程度上增强帖子的分数 数据准备 本来 “ES最高难度” 的score是0.16540512,经过field_value_factor的改变,乘上了那个文档中的like值(10)之后,新的score变为 1.6540513 可以看到“ES入门”的加强score是2,在max_boost限制裡,所以不受影响。而“ES进阶”和“ES最高难度”的field_value_factor函数产生的加强score因为超过max_boost的限制,所以被设为3。 有时候线性的计算new_score = old_score * like值的效果并不是那麽好,field_value_factor中还支持 modifier、factor 参数,可以改变like值对old_score的影响。 modifier参数支持的值: none : new_score = old_score * like值 默认状态就是none,线性。 log1p : new_score = old_score * log(1 + like值) 最常用,可以让like值字段的评分曲线更平滑。 log2p : new_score = old_score * log(2 + like值) ln : new_score = old_score * ln(like值) ln1p : new_score = old_score * ln(1 + like值) ln2p : new_score = old_score * ln(2 + like值) square : 计算平方 sqrt : 计算平方根 reciprocal : 计算倒数 factor参数: 对刚刚的例子加上 modifier、factor参数的查询语句如下: 就算加上了modifier,但是 “全文评分 与 field_value_factor函数值乘积” 的效果可能还是太大,我们可以通过参数boost_mode来决定 old_score 和 加强score 合併的方法。 如果将boost_mode改成sum,可以大幅弱化最终效果,特别是使用一个较小的factor时; 对刚刚的例子加上max_boost参数的查询语句如下: function_score (衰减函数 linear、exp、gauss 具体实例) 很多变量都可以影响用户对于酒店的选择,像是用户可能希望酒店离市中心近一点,但是如果价格足够便宜,也愿意为了省钱,妥协选择一个更远的住处。如果我们只是使用一个 filter 排除所有市中心方圆 100 米以外的酒店,再用一个filter排除每晚价格超过100元的酒店,这种作法太过强硬,可能有一间房在 500米,但是超级便宜一晚只要10元,用户可能会因此愿意妥协住这间房。 为了解决这个问题,因此function_score查询提供了一组 衰减函数 (decay functions), 让我们有能力在两个滑动标准(如地点和价格)之间权衡。 function_score支持的衰减函数有三种,分别是 linear、exp 和 gauss。linear、exp、gauss三种衰减函数的差别只在于衰减曲线的形状,在DSL的语法上的用法完全一样。 linear : 线性函数是条直线,一旦直线与横轴0相交,所有其他值的评分都是0。 origin : 中心点,或是字段可能的最佳值,落在原点(origin)上的文档评分_score为满分1.0,支持数值、时间 以及 “经纬度地理座标点”(最常用) 的字段。 所有曲线(linear、exp、gauss)的origin都是40,offset是5,因此范围在40-5 <= value <= 40+5的文档的评分_score都是满分1.0。 先准备数据和索引,在ES插入三条数据,其中language是keywork类型,like是integer类型(代表点赞量): 以like=15为中心,使用gauss函数: 假设有一个用户希望租一个离市中心近一点的酒店,且每晚不超过100元的酒店,而且与距离相比,我们的用户对价格更敏感,那麽使用衰减函数guass查询如下: 其中把price语句的origin点设为50是有原因的,由于价格的特性一定是越低越好,所以0~100元的所有价格的酒店都应该认为是比较好的,而100元以上的酒店就慢慢衰减。 如果我们将price的origin点设置成100,那麽价格低于100元的酒店的评分反而会变低,这不是我们期望的结果,与其这样不如将origin和offset同时设成50,只让price大于100元时评分才会变低 虽然这样设置也会使得price小于0元的酒店评分降低没错,不过现实生活中价格不会有负数,因此就算price<0的评分会下降,也不会对我们的搜索结果造成影响(酒店的价格一定都是正的)。 换句话说,其实只要把origin + offset的值设为100,origin或offset是什麽样的值都无所谓,只要能确保酒店价格在100元以上的酒店会衰减就好了。 搜索的时候,可能输入的搜索文本会出现误拼写的情况 doc1: hello world 搜索:hallo world fuzzy搜索技术 --> 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据 surprize --> 拼写错误 --> surprise --> s -> z surprize --> surprise -> z -> s,纠正一个字母,就可以匹配上,所以在fuziness指定的2范围内 fuzzy搜索以后,会自动尝试将你的搜索文本进行纠错,然后去跟文本进行匹配 之前大家会发现,我们全部是用英文在玩儿。。。好玩儿不好玩儿。。。不好玩儿 中国人,其实我们用来进行搜索的,绝大多数,都是中文应用,很少做英文的 英语的也要学:所以说,我们利用核心知识篇的相关的知识,来把es这种英文原生的搜索引擎,先学一下; 因为有些知识点,可能用英文讲更靠谱,因为比如说analyzed,palyed,students --> stemmer,analyze,play,student。有些知识点,仅仅适用于英文,不太适用于中文 从这一讲开始,大家就会觉得很爽,因为全部都是我们熟悉的中文了,没有英文了,高阶知识点,搜索,聚合,全部是中文了 在搜索引擎领域,比较成熟和流行的,就是ik分词器 中国人很喜欢吃油条 standard:中 国 人 很 喜 欢 吃 油 条 1、在elasticsearch中安装ik中文分词器 2、ik分词器基础知识 两种analyzer,你根据自己的需要自己选吧,但是一般是选用ik_max_word ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合; ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。 共和国 --> 中华人民共和国和国歌,搜到吗???? 3、ik分词器的使用 1、ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用来配置自定义词库 ik原生最重要的两个配置文件 main.dic:包含了原生的中文词语,会按照这个里面的词语去分词 停用词,stopword a the and at but 一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中 2、自定义词库 (1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里 自己补充自己的最新的词语,到ik的词库里面去 IKAnalyzer.cfg.xml:ext_dict,custom/mydict.dic 补充自己的词语,然后需要重启es,才能生效 (2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索 custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es 每次都是在es的扩展词典中,手动添加新词语,很坑 (1)每次添加完,都要重启es才能生效,非常麻烦 (2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改 es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语 热更新的方案 (1)修改ik分词器源码,然后手动支持从mysql中每隔一定时间,自动加载新的词库 (2)基于ik分词器原生支持的热更新方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新 用第一种方案,第二种,ik git社区官方都不建议采用,觉得不太稳定 1、下载源码 https://github.com/medcl/elasticsearch-analysis-ik/tree/v5.2.0 ik分词器,是个标准的java maven工程,直接导入eclipse就可以看到源码 2、修改源码 Dictionary类,169行:Dictionary单例类的初始化方法,在这里需要创建一个我们自定义的线程,并且启动它 HotDictReloadThread类:就是死循环,不断调用Dictionary.getSingleton().reLoadMainDict(),去重新加载词典 Dictionary类,389行:this.loadMySQLExtDict(); Dictionary类,683行:this.loadMySQLStopwordDict(); 3、mvn package打包代码 4、解压缩ik压缩包 将mysql驱动jar,放入ik的目录下 5、修改jdbc相关配置 7 测试,mysql添加前 结果: 次数停用词 添加停用词 一看日志已经加载出来 9分词实验,验证热更新生效 停用词实验 课程大纲 1、文本编辑器介绍 (1)windows操作系统,原生的txt文本编辑器,一些json格式,不太方便去调整 2、两个核心概念:bucket和metric bucket:一个数据分组 city name 北京 小李 基于city划分buckets 划分出来两个bucket,一个是北京bucket,一个是上海bucket 北京bucket:包含了2个人,小李,小王 按照某个字段进行bucket划分,那个字段的值相同的那些数据,就会被划分到一个bucket中 有一些mysql的sql知识的话,聚合,首先第一步就是分组,对每个组内的数据进行聚合分析,分组,就是我们的bucket metric:对一个数据分组执行的统计 当我们有了一堆bucket之后,就可以对每个bucket中的数据进行聚合分词了,比如说计算一个bucket内所有数据的数量,或者计算一个bucket内所有数据的平均值,最大值,最小值 metric,就是对一个bucket执行的某种聚合分析的操作,比如说求平均值,求最大值,求最小值 select count(*) bucket:group by user_id --> 那些user_id相同的数据,就会被划分到一个bucket中 课程大纲 1、家电卖场案例背景 以一个家电卖场中的电视销售数据为背景,来对各种品牌,各种颜色的电视的销量和销售额,进行各种各样角度的分析 { “price” : 2500, “color” : “蓝色”, “brand” : “小米”, “sold_date” : “2017-02-12” } 2、统计各种颜色的电视销量 size:只获取聚合结果,而不要执行聚合的原始数据 hits.hits:我们指定了size是0,所以hits.hits就是空的,否则会把执行聚合的那些原始数据给你返回回来 每种颜色对应的bucket中的数据的 课程大纲 按照color去分bucket,可以拿到每个color bucket中的数量,这个仅仅只是一个bucket操作,doc_count其实只是es的bucket操作默认执行的一个内置metric 这一讲,就是除了bucket操作,分组,还要对每个bucket执行一个metric聚合统计操作 在一个aggs执行的bucket操作(terms),平级的json结构下,再加一个aggs,这个第二个aggs内部,同样取个名字,执行一个metric操作,avg,对之前的每个bucket中的数据的指定的field,price field,求一个平均值 “aggs”: { 就是一个metric,就是一个对一个bucket分组操作之后,对每个bucket都要执行的一个metric 第一个metric,avg,求指定字段的平均值 buckets,除了key和doc_count select avg(price) 课程大纲 从颜色到品牌进行下钻分析,每种颜色的平均价格,以及找到每种颜色每个品牌的平均价格 我们可以进行多层次的下钻 比如说,现在红色的电视有4台,同时这4台电视中,有3台是属于长虹的,1台是属于小米的 红色电视中的3台长虹的平均价格是多少? 下钻的意思是,已经分了一个组了,比如说颜色的分组,然后还要继续对这个分组内的数据,再分组,比如一个颜色内,还可以分成多个不同的品牌的组,最后对每个最小粒度的分组执行聚合分析操作,这就叫做下钻分析 es,下钻分析,就要对bucket进行多层嵌套,多次分组 按照多个维度(颜色+品牌)多层下钻分析,而且学会了每个下钻维度(颜色,颜色+品牌),都可以对每个维度分别执行一次metric聚合操作 课程大纲 要学更多的metric count,avg count:bucket,terms,自动就会有一个doc_count,就相当于是count 一般来说,90%的常见的数据分析的操作,metric,无非就是count,avg,max,min,sum 求总和,就可以拿到一个颜色下的所有电视的销售总额 课程大纲 histogram:类似于terms,也是进行bucket分组操作,接收一个field,按照这个field的值的各个范围区间,进行bucket分组操作 interval:2000,划分范围,02000,20004000,40006000,60008000,8000~10000,buckets 去根据price的值,比如2500,看落在哪个区间内,比如20004000,此时就会将这条数据放入20004000对应的那个bucket中 bucket划分的方法,terms,将field值相同的数据划分到一个bucket中 bucket有了之后,一样的,去对每个bucket执行avg,count,sum,max,min,等各种metric操作,聚合分析 课程大纲 bucket,分组操作,histogram,按照某个值指定的interval,划分一个一个的bucket date histogram,按照我们指定的某个date类型的日期field,以及日期interval,按照一定的日期间隔,去划分bucket date interval = 1m, 2017-01-01~2017-01-31,就是一个bucket 然后会去扫描每个数据的date field,判断date落在哪个bucket中,就将其放入那个bucket 2017-01-05,就将其放入2017-01-01~2017-01-31,就是一个bucket min_doc_count:即使某个日期interval,2017-01-01~2017-01-31中,一条数据都没有,那么这个区间也是要返回的,不然默认是会过滤掉这个区间的 课程大纲 课程大纲 实际上来说,我们之前学习的搜索相关的知识,完全可以和聚合组合起来使用 select count(*) es aggregation,scope,任何的聚合,都必须在搜索出来的结果数据中之行,搜索结果,就是聚合分析操作的scope 课程大纲 aggregation,scope,一个聚合操作,必须在query的搜索结果范围内执行 出来两个结果,一个结果,是基于query搜索结果来聚合的; 一个结果,是对所有数据执行聚合的 global:就是global bucket,就是将所有数据纳入聚合的scope,而不管之前的query single_brand_avg_price:就是针对query搜索结果,执行的,拿到的,就是长虹品牌的平均价格 课程大纲 搜索+聚合 课程大纲 aggs.filter,针对的是聚合去做的 如果放query里面的filter,是全局的,会对所有的数据都有影响 但是,如果,比如说,你要统计,长虹电视,最近1个月的平均值; 最近3个月的平均值; 最近6个月的平均值 bucket filter:对不同的bucket下的aggs,进行filter 课程大纲 之前的话,排序,是按照每个bucket的doc_count降序来排的 但是假如说,我们现在统计出来每个颜色的电视的销售额,需要按照销售额降序排序???? 课程大纲 课程大纲 1、画图讲解易并行聚合算法:max 有些聚合分析的算法,是很容易就可以并行的,比如说max 有些聚合分析的算法,是不好并行的,比如说,count(distinct),并不是说,在每个node上,直接就出一些distinct value,就可以的,因为数据可能会很多 es会采取近似聚合的方式,就是采用在每个node上进行近估计的方式,得到最终的结论,cuont(distcint),100万,1050万/95万 --> 5%左右的错误率 2、三角选择原则 精准+实时+大数据 --> 选择2个 (1)精准+实时: 没有大数据,数据量很小,那么一般就是单击跑,随便你则么玩儿就可以 3、近似聚合算法 如果采取近似估计的算法:延时在100ms左右,0.5%错误 课程大纲 es,去重,cartinality metric,对每个bucket中的指定的field进行去重,取去重后的count,类似于count(distcint) 课程大纲 cardinality,count(distinct),5%的错误率,性能在100ms左右 1、precision_threshold优化准确率和内存开销 brand去重,如果brand的unique value,在100个以内,小米,长虹,三星,TCL,HTL。。。 在多少个unique value以内,cardinality,几乎保证100%准确 precision_threshold,值设置的越大,占用内存越大,1000 * 8 = 8000 / 1000 = 8KB,可以确保更多unique value的场景下,100%的准确 field,去重,count,这时候,unique value,10000,precision_threshold=10000,10000 * 8 = 80000个byte,80KB 2、HyperLogLog++ (HLL)算法性能优化 cardinality底层算法:HLL算法,HLL算法的性能 会对所有的uqniue value取hash值,通过hash值近似去求distcint count,误差 默认情况下,发送一个cardinality请求的时候,会动态地对所有的field value,取hash值; 将取hash值的操作,前移到建立索引的时候 课程大纲 需求:比如有一个网站,记录下了每次请求的访问的耗时,需要统计tp50,tp90,tp99 tp50:50%的请求的耗时最长在多长时间 pencentiles 50%的请求,数值的最大的值是多少,不是完全准确的 课程大纲 SLA:就是你提供的服务的标准 我们的网站的提供的访问延时的SLA,确保所有的请求100%,都必须在200ms以内,大公司内,一般都是要求100%在200ms以内 如果超过1s,则需要升级到A级故障,代表网站的访问性能和用户体验急剧下降 需求:在200ms以内的,有百分之多少,在1000毫秒以内的有百分之多少,percentile ranks metric 这个percentile ranks,其实比pencentile还要常用 按照品牌分组,计算,电视机,售价在1000占比,2000占比,3000占比 percentile的优化 TDigest算法,用很多节点来执行百分比的计算,近似估计,有误差,节点越多,越精准 compression 限制节点数量最多 compression * 20 = 2000个node去计算 默认100 越大,占用内存越多,越精准,性能越差 一个节点占用32字节,100 * 20 * 32 = 64KB 如果你想要percentile算法越精准,compression可以设置的越大 聚合分析的内部原理是什么????aggs,term,metric avg max,执行一个聚合操作的时候,内部原理是怎样的呢?用了什么样的数据结构去执行聚合?是不是用的倒排索引? 搜索+聚合,写个示例 GET /test_index/test_type/_search 纯用倒排索引来实现的弊端 es肯定不是纯用倒排索引来实现聚合+搜索的 search_field doc1: hello world test1, test2 hello doc1,doc2 “query”: { test --> doc2,doc3 --> search result, doc2,doc3 agg_field doc2: agg1 100万个值 doc2, doc3, search result --> 实际上,要搜索到doc2的agg_field的值是多少,doc3的agg_field的值是多少 doc2和doc3的agg_field的值之后,就可以根据值进行分组,实现terms bucket操作 doc2的agg_field的值是多少,这个时候,如果你手上只有一个倒排索引,你该怎么办???你要扫描整个倒排索引,去一个一个的搜,拿到每个值,比如说agg1,看一下,它是不是doc2的值,拿到agg2,看一下,是不是doc2的值,直到找到doc2的agg_field的值,在倒排索引中 如果用纯倒排索引去实现聚合,现实不现实啊???性能是很低下的。。。搜索,search,搜倒排索引,搜那个term,就结束了。。。聚合,搜索出了1万个doc,每个doc都要在倒排索引中搜索出它的那个聚合field的值 倒排索引+正排索引(doc value)的原理和优势 doc value:正排索引 search_field doc1: hello world test1, test2 hello doc1,doc2 “query”: { test --> doc2,doc3 --> search result, doc2,doc3 doc value数据结构,正排索引 … 倒排索引的话,必须遍历完整个倒排索引才可以。。。。 因为可能你要聚合的那个field的值,是分词的,比如说hello world my name --> 一个doc的聚合field的值可能在倒排索引中对应多个value 所以说,当你在倒排索引中找到一个值,发现它是属于某个doc的时候,还不能停,必须遍历完整个倒排索引,才能说确保找到了每个doc对应的所有terms,然后进行分组聚合 … 我们有没有必要搜索完整个正排索引啊??1万个doc --> 搜 -> 可能跟搜索到15000次,就搜索完了,就找到了1万个doc的聚合field的所有值了,然后就可以执行分组聚合操作了 课程大纲 1、doc value原理 (1)index-time生成 PUT/POST的时候,就会生成doc value数据,也就是正排索引 (2)核心原理与倒排索引类似 正排索引,也会写入磁盘文件中,然后呢,os cache先进行缓存,以提升访问doc value正排索引的性能 (3)性能问题:给jvm更少内存,64g服务器,给jvm最多16g es官方是建议,es大量是基于os cache来进行缓存和提升性能的,不建议用jvm内存来进行缓存,那样会导致一定的gc开销和oom问题 2、column压缩 doc1: 550 合并相同值,550,doc1和doc2都保留一个550的标识即可 (1)所有值相同,直接保留单值 doc1: 36 6 --> doc1: 6, doc2: 4 --> 保留一个最大公约数6的标识,6也保存起来 (4)如果没有最大公约数,采取offset结合压缩的方式: 3、disable doc value 如果的确不需要doc value,比如聚合等操作,那么可以禁用,减少磁盘空间占用 1、对于分词的field执行aggregation,发现报错。。。 对分词的field,直接执行聚合操作,会报错,大概意思是说,你必须要打开fielddata,然后将正排索引数据加载到内存中,才可以对分词的field执行聚合操作,而且会消耗很大的内存 2、给分词的field,设置fielddata=true,发现可以执行,但是结果却。。。 如果要对分词的field执行聚合操作,必须将fielddata设置为true 3、使用内置field不分词,对string field进行聚合 如果对不分词的field执行聚合操作,直接就可以执行,不需要设置fieldata=true 4、分词field+fielddata的工作原理 doc value --> 不分词的所有field,可以执行聚合操作 --> 如果你的某个field不分词,那么在index-time,就会自动生成doc value --> 针对这些不分词的field执行聚合操作的时候,自动就会用doc value来执行 分词field,是没有doc value的。。。在index-time,如果某个field是分词的,那么是不会给它建立doc value正排索引的,因为分词后,占用的空间过于大,所以默认是不支持分词field进行聚合的 分词field默认没有doc value,所以直接对分词field执行聚合操作,是会报错的 对于分词field,必须打开和使用fielddata,完全存在于纯内存中。。。结构和doc value类似。。。如果是ngram或者是大量term,那么必将占用大量的内存。。。 如果一定要对分词的field执行聚合,那么必须将fielddata=true,然后es就会在执行聚合操作的时候,现场将field对应的数据,建立一份fielddata正排索引,fielddata正排索引的结构跟doc value是类似的,但是只会讲fielddata正排索引加载到内存中来,然后基于内存中的fielddata正排索引执行分词field的聚合操作 如果直接对分词field执行聚合,报错,才会让我们开启fielddata=true,告诉我们,会将fielddata uninverted index,正排索引,加载到内存,会耗费内存空间 为什么fielddata必须在内存?因为大家自己思考一下,分词的字符串,需要按照term进行聚合,需要执行更加复杂的算法和操作,如果基于磁盘和os cache,那么性能会很差 课程大纲 1、fielddata核心原理 fielddata加载到内存的过程是lazy加载的,对一个analzyed field执行聚合时,才会加载,而且是field-level加载的 2、fielddata内存限制 indices.fielddata.cache.size: 20%,超出限制,清除内存已有fielddata数据 3、监控fielddata内存使用 4、circuit breaker 如果一次query load的feilddata超过总内存,就会oom --> 内存溢出 circuit breaker会估算query要加载的fielddata大小,如果超出总内存,就短路,query直接失败 min:仅仅加载至少在1%的doc中出现过的term对应的fielddata 比如说某个值,hello,总共有1000个doc,hello必须在10个doc中出现,那么这个hello对应的fielddata才会加载到内存中来 min_segment_size:少于500 doc的segment不加载fielddata 加载fielddata的时候,也是按照segment去进行加载的,某个segment里面的doc数量少于500个,那么这个segment的fielddata就不加载 这个,就我的经验来看,有点底层了,一般不会去设置它,大家知道就好 如果真的要对分词的field执行聚合,那么每次都在query-time现场生产fielddata并加载到内存中来,速度可能会比较慢 我们是不是可以预先生成加载fielddata到内存中来??? 1、fielddata预加载 query-time的fielddata生成和加载到内存,变为index-time,建立倒排索引的时候,会同步生成fielddata并且加载到内存中来,这样的话,对分词field的聚合性能当然会大幅度增强 2、序号标记预加载 global ordinal原理解释 doc1: status1 有很多重复值的情况,会进行global ordinal标记 status1 --> 0 doc1: 0 建立的fielddata也会是这个样子的,这样的好处就是减少重复字符串的出现的次数,减少内存的消耗 当buckets数量特别多的时候,深度优先和广度优先的原理,图解 我们的数据,是每个演员的每个电影的评论 每个演员的评论的数量 --> 每个演员的每个电影的评论的数量 评论数量排名前10个的演员 --> 每个演员的电影取到评论数量排名前5的电影 深度优先的方式去执行聚合操作的 film1 film2 film3 film1 film2 film3 …film 比如说,我们有10万个actor,最后其实是主要10个actor就可以了 但是我们已经深度优先的方式,构建了一整颗完整的树出来了,10万个actor,每个actor平均有10部电影,10万 + 100万 --> 110万的数据量的一颗树 裁剪掉10万个actor中的99990 actor,99990 * 10 = film,剩下10个actor,每个actor的10个film裁剪掉5个,110万 --> 10 * 5 = 50个 构建了大量的数据,然后裁剪掉了99.99%的数据,浪费了 广度优先的方式去执行聚合 actor1 actor2 actor3 … n个actor 10万个actor,不去构建它下面的film数据,10万 --> 99990,10个actor,构建出film,裁剪出其中的5个film即可,10万 -> 50个 10倍
filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
document,id=5,postDate=2017-01-01,会自动更新到postDate=2017-01-01这个filter的bitset中,全自动,缓存会自动更新。postDate=2017-01-01的bitset,[0, 0, 1, 0, 1]
document,id=1,postDate=2016-12-30,修改为postDate-2017-01-01,此时也会自动更新bitset,[1, 0, 1, 0, 1]04_搜索_bool组合多个filter条件
from forum.article
where (post_date=‘2017-01-01’ or article_id=‘XHDK-A-1293-#fJ3’)
and post_date!=‘2017-01-02’GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{"term": { "postDate": "2017-01-01" }},
{"term": {"articleID": "XHDK-A-1293-#fJ3"}}
],
"must_not": {
"term": {
"postDate": "2017-01-02"
}
}
}
}
}
}
}
from forum.article
where article_id=‘XHDK-A-1293-#fJ3’
or (article_id=‘JODL-X-1937-#pV7’ and post_date=‘2017-01-01’)GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
},
{
"bool": {
"must": [
{
"term":{
"articleID": "JODL-X-1937-#pV7"
}
},
{
"term": {
"postDate": "2017-01-01"
}
}
]
}
}
]
}
}
}
}
}
(2)bool可以嵌套
(3)相当于SQL中的多个and条件:当你把搜索语法学好了以后,基本可以实现部分常用的sql语法对应的功能05_搜索_terms搜索
terms: {“field”: [“value1”, “value2”]}POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag" : ["java", "hadoop"]} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag" : ["java"]} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag" : ["hadoop"]} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag" : ["java", "elasticsearch"]} }
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"articleID": [
"KDKE-B-9947-#kL5",
"QQPX-R-3956-#aD8"
]
}
}
}
}
}
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"tag" : ["java"]
}
}
}
}
}
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 1,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
]
}
}
]
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag_cnt" : 2} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag_cnt" : 2} }
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"term": {
"tag_cnt": 1
}
},
{
"terms": {
"tag": ["java"]
}
}
]
}
}
}
}
}
(2)优化terms多值搜索的结果
(3)相当于SQL中的in语句06_搜索_filter range范围过滤
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"view_cnt" : 30} }
{ "update": { "_id": "2"} }
{ "doc" : {"view_cnt" : 50} }
{ "update": { "_id": "3"} }
{ "doc" : {"view_cnt" : 100} }
{ "update": { "_id": "4"} }
{ "doc" : {"view_cnt" : 80} }
2、搜索浏览量在30~60之间的帖子
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"view_cnt": {
"gt": 30,
"lt": 60
}
}
}
}
}
}
ltePOST /forum/article/_bulk
{ "index": { "_id": 5 }}
{ "articleID" : "DHJK-B-1395-#Ky5", "userID" : 3, "hidden": false, "postDate": "2017-03-01", "tag": ["elasticsearch"], "tag_cnt": 1, "view_cnt": 10 }
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "2017-03-10||-30d"
}
}
}
}
}
}
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "now-30d"
}
}
}
}
}
}
(2)range做范围过滤07_搜索_operator、minimum_should_match控制精度
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"title" : "this is java and elasticsearch blog"} }
{ "update": { "_id": "2"} }
{ "doc" : {"title" : "this is java blog"} }
{ "update": { "_id": "3"} }
{ "doc" : {"title" : "this is elasticsearch blog"} }
{ "update": { "_id": "4"} }
{ "doc" : {"title" : "this is java, elasticsearch, hadoop blog"} }
{ "update": { "_id": "5"} }
{ "doc" : {"title" : "this is spark blog"} }
match query,是负责进行全文检索的。当然,如果要检索的field,是not_analyzed类型的,那么match query也相当于term query。
{
“query”: {
“match”: {
“title”: “java elasticsearch”
}
}
}GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch spark hadoop",
"minimum_should_match": "75%"
}
}
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"must": { "match": { "title": "java" }},
"must_not": { "match": { "title": "spark" }},
"should": [
{ "match": { "title": "hadoop" }},
{ "match": { "title": "elasticsearch" }}
]
}
}
}
排名第二:java,同时包含should中的elasticsearch
排名第三:java,不包含should中的任何关键字
在满足must的基础之上,should中的条件,不匹配也可以,但是如果匹配的更多,那么document的relevance score就会更高{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.3375794,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 1.3375794,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.53484553,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.19856805,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog"
}
}
]
}
}
但是有个例外的情况,如果没有must的话,那么should中必须至少匹配一个才可以
比如下面的搜索,should中有4个条件,默认情况下,只要满足其中一个条件,就可以匹配作为结果返回GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java" }},
{ "match": { "title": "elasticsearch" }},
{ "match": { "title": "hadoop" }},
{ "match": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
}
2、控制搜索结果精准度:and operator,minimum_should_match08_搜索_term+bool实现的multiword
{
"match": { "title": "java elasticsearch"}
}
bool should,指定多个搜索词,同时使用term query{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
{
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
{
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }},
{ "term": { "title": "hadoop" }},
{ "term": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
09_搜索_boost权重
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "blog"
}
}
],
"should": [
{
"match": {
"title": {
"query": "java"
}
}
},
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "elasticsearch"
}
}
},
{
"match": {
"title": {
"query": "spark",
"boost": 5
}
}
}
]
}
}
}
10_搜索_多shard下relevance score不准确

比如说有10个document,title都包含java,一共有5个shard,那么在概率学的背景下,如果负载均衡的话,其实每个shard都应该有2个doc,title包含java
如果说数据分布均匀的话,其实就没有刚才说的那个问题了11_搜索_dis_max实现best fields多字段搜索
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "i like to write best elasticsearch article"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "i think java is the best programming language"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "i am only an elasticsearch beginner"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "spark is best big data solution based on scala ,an programming language similar to java"} }
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
{ “match”: { “content”: “java solution” }},针对doc4,也是有一个分数的
matched query数量 = 2
总query数量 = 2
{ “match”: { “content”: “java solution” }},针对doc5,是有一个分数的
matched query数量 = 1
总query数量 = 2
{ “match”: { “content”: “java solution” }},针对doc4,也是有一个分数的,1.2
取最大分数,1.2
{ “match”: { “content”: “java solution” }},针对doc5,是有一个分数的,2.3
取最大分数,2.3{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
12_搜索_tie_breaker优化dis_max搜索
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
]
}
}
}
(2)某个帖子,doc2,content中包含beginner,title中不包含任何一个关键词
(3)某个帖子,doc3,title中包含java,content中包含beginner
(4)最终搜索,可能出来的结果是,doc1和doc2排在doc3的前面,而不是我们期望的doc3排在最前面
tie_breaker的值,在0~1之间,是个小数,就okGET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
],
"tie_breaker": 0.3
}
}
}
13_搜索_multi_match+best-fields策略
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [ "title^2", "content" ],
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "java beginner",
"minimum_should_match": "50%",
"boost": 2
}
}
},
{
"match": {
"body": {
"query": "java beginner",
"minimum_should_match": "30%"
}
}
}
],
"tie_breaker": 0.3
}
}
}
去长尾,long tail
长尾,比如你搜索5个关键词,但是很多结果是只匹配1个关键词的,其实跟你想要的结果相差甚远,这些结果就是长尾
minimum_should_match,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回14_搜索_multi_match+most fiels策略
best-fields策略,主要是说将某一个field匹配尽可能多的关键词的doc优先返回回来
most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来POST /forum/_mapping/article
{
"properties": {
"sub_title": {
"type": "string",
"analyzer": "english",
"fields": {
"std": {
"type": "string",
"analyzer": "standard"
}
}
}
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"sub_title" : "learning more courses"} }
{ "update": { "_id": "2"} }
{ "doc" : {"sub_title" : "learned a lot of course"} }
{ "update": { "_id": "3"} }
{ "doc" : {"sub_title" : "we have a lot of fun"} }
{ "update": { "_id": "4"} }
{ "doc" : {"sub_title" : "both of them are good"} }
{ "update": { "_id": "5"} }
{ "doc" : {"sub_title" : "haha, hello world"} }
GET /forum/article/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.219939,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.219939,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.5063205,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses"
}
}
]
}
}
learning --> learn
learned --> learn
courses --> courseGET /forum/article/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.219939,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.219939,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1.012641,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses"
}
}
]
}
}
缺点:除了那些精准匹配的结果,其他差不多大的结果,排序结果不是太均匀,没有什么区分度了
缺点:可能那些精准匹配的结果,无法推送到最前面15_搜索_most_fields策略进行cross-fields搜索
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"author_first_name" : "Peter", "author_last_name" : "Smith"} }
{ "update": { "_id": "2"} }
{ "doc" : {"author_first_name" : "Smith", "author_last_name" : "Williams"} }
{ "update": { "_id": "3"} }
{ "doc" : {"author_first_name" : "Jack", "author_last_name" : "Ma"} }
{ "update": { "_id": "4"} }
{ "doc" : {"author_first_name" : "Robbin", "author_last_name" : "Li"} }
{ "update": { "_id": "5"} }
{ "doc" : {"author_first_name" : "Tonny", "author_last_name" : "Peter Smith"} }
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "most_fields",
"fields": [ "author_first_name", "author_last_name" ]
}
}
}
因为IDF分数高,IDF分数要高,那么这个匹配到的term(Smith),在所有doc中的出现频率要低,author_first_name field中,Smith就出现过1次
Peter Smith这个人,doc 1,Smith在author_last_name中,但是author_last_name出现了两次Smith,所以导致doc 1的IDF分数较低{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.6931472,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.6931472,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.5753642,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.51623213,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith"
}
}
]
}
}
16_搜索_copy_to定制组合field解决cross-fields搜索弊端
PUT /forum/_mapping/article
{
"properties": {
"new_author_first_name": {
"type": "string",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "string",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "string"
}
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"new_author_first_name" : "Peter", "new_author_last_name" : "Smith"} } --> Peter Smith
{ "update": { "_id": "2"} }
{ "doc" : {"new_author_first_name" : "Smith", "new_author_last_name" : "Williams"} } --> Smith Williams
{ "update": { "_id": "3"} }
{ "doc" : {"new_author_first_name" : "Jack", "new_author_last_name" : "Ma"} } --> Jack Ma
{ "update": { "_id": "4"} }
{ "doc" : {"new_author_first_name" : "Robbin", "new_author_last_name" : "Li"} } --> Robbin Li
{ "update": { "_id": "5"} }
{ "doc" : {"new_author_first_name" : "Tonny", "new_author_last_name" : "Peter Smith"} } --> Tonny Peter Smith
GET /forum/article/_search
{
"query": {
"match": {
"new_author_full_name": "Peter Smith"
}
}
}
17_搜索_cross-fiels解决搜索弊端
GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": ["author_first_name", "author_last_name"]
}
}
}
要求Smith必须在author_first_name或author_last_name中出现
Smith18_搜索_match_phrase搜索
java spark are very related, because scala is spark’s programming language and scala is also based on jvm like java.{
"match": {
"content": "java spark"
}
}
2、java spark,但是要求,java和spark两个单词靠的越近,doc的分数越高,排名越靠前GET /forum/article/_search
{
"query": {
"match": {
"content": "java spark"
}
}
}
POST /forum/article/5/_update
{
"doc": {
"content": "spark is best big data solution based on scala ,an programming language similar to java spark"
}
}
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": "java spark"
}
}
}
hi, spark java doc2
wolrd doc1(1)
java doc1(2) doc2(2)
spark doc1(3) doc2(1)
{
“text”: “hello world, java spark”,
“analyzer”: “standard”
}
4、match_phrase的基本原理
hi, spark java doc2
wolrd doc1(1)
java doc1(2) doc2(2)
spark doc1(3) doc2(1)
spark --> doc1(3) doc2(1)19_搜索_match_phrase的slop参数实现近似匹配
GET /forum/article/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java spark",
"slop": 1
}
}
}
}
java --> spark
java --> spark
java --> sparkGET /forum/article/_search
{
"query": {
"match_phrase": {
"title": {
"query": "java spark",
"slop": 3
}
}
}
}
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "spark data",
"slop": 3
}
}
}
}
–> data
–> data
spark --> dataGET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "data spark",
"slop": 5
}
}
}
}
–> data/spark
spark <–data
spark --> data
spark --> data
spark --> data{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.3728157,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1.3728157,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.5753642,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.28582606,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith",
"new_author_last_name": "Smith",
"new_author_first_name": "Peter"
}
}
]
}
}
GET /forum/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "java best",
"slop": 15
}
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.65380025,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.65380025,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.07111243,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny"
}
}
]
}
}
2、java spark,可以有一定的距离,但是靠的越近,越先搜索出来,proximity match20_搜索_match_phrase和match召回率与精准度的平衡
java spark --> hello world, java spark --> 才可以返回GET /forum/article/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": {
"query": "java spark" --> java或spark或java spark,java和spark靠前,但是没法区分java和spark的距离,也许java和spark靠的很近,但是没法排在最前面
}
}
},
"should": {
"match_phrase": { --> 在slop以内,如果java spark能匹配上一个doc,那么就会对doc贡献自己的relevance score,如果java和spark靠的越近,那么就分数越高
"title": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java spark"
}
}
]
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.68640786,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.68640786,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"followers": [
"Tom",
"Jack"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 0.68324494,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"followers": [
"Jack",
"Robbin Li"
]
}
}
]
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java spark"
}
}
],
"should": [
{
"match_phrase": {
"content": {
"query": "java spark",
"slop": 50
}
}
}
]
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.258609,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 1.258609,
"_source": {
"articleID": "DHJK-B-1395-#Ky5",
"userID": 3,
"hidden": false,
"postDate": "2017-03-01",
"tag": [
"elasticsearch"
],
"tag_cnt": 1,
"view_cnt": 10,
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java spark",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith",
"new_author_last_name": "Peter Smith",
"new_author_first_name": "Tonny",
"followers": [
"Jack",
"Robbin Li"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.68640786,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams",
"new_author_last_name": "Williams",
"new_author_first_name": "Smith",
"followers": [
"Tom",
"Jack"
]
}
}
]
}
}
21_搜索_match_phrase的rescore近似匹配优化
match query比phrase match的性能要高10倍,比proximity match的性能要高20倍。
但是很多情况下,match出来也许1000个doc,其实用户大部分情况下是分页查询的,所以可能最多只会看前几页,比如一页是10条,最多也许就看5页,就是50条
proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数GET /forum/article/_search
{
"query": {
"match": {
"content": "java spark"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "java spark",
"slop": 50
}
}
}
}
}
}
22_搜索_prefix前缀、wildcard通配符、regexp正则搜索等技术
C3K5-DFG65
C4I8-UI365
C3 --> 上面这两个都搜索出来 --> 根据字符串的前缀去搜索PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"title": {
"type": "keyword"
}
}
}
}
}
GET my_index/my_type/_search
{
"query": {
"prefix": {
"title": {
"value": "C3"
}
}
}
}
C3-K5-DFG65
C4-I8-UI365
d0
kd345
k5
dfg65
c4
i8
ui365
C3-K5-DFG65
C4-I8-UI365
C3K5-DFG65
C4I8-UI365
kd345
C3K5-DFG65
C4I8-UI365GET my_index/my_type/_search
{
"query": {
"wildcard": {
"title": {
"value": "C?K*5"
}
}
}
}
*:0个或任意多个字符
GET /my_index/my_type/_search
{
"query": {
"regexp": {
"title": "C[0-9].+"
}
}
}
[a-z]:指定范围内的字母
.:一个字符
+:前面的正则表达式可以出现一次或多次23_搜索_match_phrase_prefix搜索推荐
hello we
hello win
hello wind
hello dog
hello cat
hello we
hello win
hello windGET /my_index/my_type/_search
{
"query": {
"match_phrase_prefix": {
"title": "hello d"
}
}
}
w,会作为前缀,去扫描整个倒排索引,找到所有w开头的doc
然后找到所有doc中,即包含hello,又包含w开头的字符的doc
根据你的slop去计算,看在slop范围内,能不能让hello w,正好跟doc中的hello和w开头的单词的position相匹配24_搜索_ngram分词机制实现index-time搜索推荐
ngram length=2,qu ui ic ck
ngram length=3,qui uic ick
ngram length=4,quic uick
ngram length=5,quick
qu
qui
quic
quick
hello we
he
hel
hell
hello doc1,doc2
wo
wor
worl
world
e doc2
max ngram = 3
he
hel
w --> w,doc1PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
GET /my_index/_analyze
{
"analyzer": "autocomplete",
"text": "quick brown"
}
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "string",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
he
hel
hell
hello
wo
wor
worl
world
he
hel
hell
helloGET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "hello w"
}
}
}
推荐使用match_phrase,要求每个term都有,而且position刚好靠着1位,符合我们的期望的25_搜索_深入揭秘TF&IDF算法以及向量空间模型算法
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能
doc1: java is my favourite programming language, hello world !!!
doc2: hello java, you are very good, oh hello world!!!
一个term在一个doc中,出现的次数越多,那么最后给的相关度评分就会越高
一个term在所有的doc中,出现的次数越多,那么最后给的相关度评分就会越低
world这个term,给的基于所有doc的一个评分就是5
doc2:包含world --> [0, 5]
doc3:包含hello, world --> [2, 5]
弧度越大,分数月底; 弧度越小,分数越高

26_搜索_深入揭秘lucene的相关度分数算法
“title”: “hello world”
}
“should”: [
{
“match”: {
“title”: “hello”
}
},
{
“natch”: {
“title”: “world”
}
}
]
}
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)2
· t.getBoost()
· norm(t,d)
) (t in q)
主要是为了将分数进行规范化 --> 开平方根,首先数据就变小了 --> 然后还用1去除以这个平方根,分数就会很小 --> 1.几 / 零点几
分数就不会出现几万,几十万,那样的离谱的分数
Document 2 with hello world → score: 3.0
Document 3 with hello world java → score: 4.5
Document 2 with hello world → score: 3.0 * 2 / 3 = 2.0
Document 3 with hello world java → score: 4.5 * 3 / 3 = 4.527_搜索_四种常见的相关度分数优化方法
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "java spark",
"boost": 2
}
}
},
{
"match": {
"content": "java spark"
}
}
]
}
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": "java"
}
},
{
"match": {
"content": "spark"
}
},
{
"bool": {
"should": [
{
"match": {
"content": "solution"
}
},
{
"match": {
"content": "beginner"
}
}
]
}
}
]
}
}
}
搜索包含java,尽量不包含spark的doc,如果包含了spark,不会说排除掉这个doc,而是说将这个doc的分数降低
包含了negative term的doc,分数乘以negative boost,分数降低GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content": "java"
}
}
],
"must_not": [
{
"match": {
"content": "spark"
}
}
]
}
}
}
GET /forum/article/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"content": "java"
}
},
"negative": {
"match": {
"content": "spark"
}
},
"negative_boost": 0.2
}
}
}
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"title": "java"
}
}
}
},
{
"constant_score": {
"query": {
"match": {
"title": "spark"
}
}
}
}
]
}
}
}
28_搜索_function_score自定义相关度分数
在使用 Elasticsearch 进行全文搜索时,搜索结果默认会以文档的相关度进行排序,如果想要改变默认的排序规则,也可以通过sort指定一个或多个排序字段。但是使用sort排序过于绝对,它会直接忽略掉文档本身的相关度(根本不会去计算)。在很多时候这样做的效果并不好,这时候就需要对多个字段进行综合评估,得出一个最终的排序。Elasticsearch提供了function_score功能来满足我们的需求。
在使用ES进行全文搜索时,搜索结果默认会以文档的相关度进行排序,而这个 “文档的相关度”,是可以透过 function_score 自己定义的,也就是说我们可以透过使用function_score,来控制 “怎麽样的文档相关度更高” 这件事
function_score是专门用于处理文档_score的DSL,它允许爲每个主查询query匹配的文档应用加强函数, 以达到改变原始查询评分 score的目的。
function_score会在主查询query结束后对每一个匹配的文档进行一系列的重打分操作,能够对多个字段一起进行综合评估,且能够使用 filter 将结果划分爲多个子集 (每个特性一个filter),并为每个子集使用不同的加强函数。
我们可以做到自定义一个function_score函数,自己将某个field的值,跟es内置算出来的分数进行运算,然后由自己指定的field来进行分数的增强
weight : 设置一个简单而不被规范化的权重提升值。
weight加强函数和 boost参数类似,可以用于任何查询,不过有一点差别是weight不会被Lucene nomalize成难以理解的浮点数,而是直接被应用 (boost会被nomalize)
例如当 weight 爲 2 时,最终结果爲new_score = old_score * 2
field_value_factor : 将某个字段的值乘上old_score。
像是将 字段shareCount 或是 字段likiCount 作爲考虑因素,new_score = old_score * 那个文档的likeCount的值
random_score : 爲每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的。
衰减函数 (linear、exp、guass) : 以某个字段的值为基准,距离某个值越近得分越高。
script_score : 当需求超出以上范围时,可以用自定义脚本完全控制评分计算,不过因为还要额外维护脚本不好维护,因此尽量使用ES提供的评分函数,需求真的无法满足再使用script_score。
boost_mode决定 old_score 和 加强score 如何合并。
multiply(默认) : new_score = old_score * 加强score
sum : new_score = old_score + 加强score
min : old_score 和 加强score 取较小值,new_score = min(old_score, 加强score)
max : old_score 和 加强score 取较大值,new_score = max(old_score, 加强score)
replace : 加强score直接替换掉old_score,new_score = 加强score
score_mode决定functions裡面的加强score们怎麽合併,会先合併加强score们成一个总加强score,再使用总加强score去和old_score做合併,换言之就是会先执行score_mode,再执行boost_mode。
multiply (默认)
sum
avg
first : 使用首个函数(可以有filter,也可以没有)的结果作为最终结果。
max
min
max_boost : 限制加强函数的最大效果,就是限制加强score最大能多少,但要注意不会限制old_score。
如果加强score超过了max_boost限制的值,会把加强score的值设成max_boost的值。
假设加强score是5,而max_boost是2,因为加强score超出了max_boost的限制,所以max_boost就会把加强score改为2。简单的说,就是加强score = min(加强score, max_boost)
如果要使用function_score改变分数,要使用function_score查询。简单的说,就是在一个function_score内部的query的全文搜索得到的_score基础上,给他加上其他字段的评分标准,就能够得到把 “全文搜索 + 其他字段” 综合起来评分的效果。GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {.....}, //主查询,查询完后这裡自己会有一个评分,就是old_score
"field_value_factor": {...}, //在old_score的基础上,给他加强其他字段的评分,这裡会产生一个加强score
,如果只有一个加强function时,直接将加强函数名写在query下面就可以了
"boost_mode": "multiply", //指定用哪种方式结合old_score和加强score成为new_score
"max_boost": 1.5 //限制加强score的最高分,但是不会限制old_score
}
}
}
如果有多个加强函数,那就要使用functions来包含这些加强函数们,functions是一个数组,裡面放著的是将要被使用的加强函数列表。
可以为functions裡的加强函数指定一个filter,这样做的话,只有在文档满足此filter的要求,此filter的加强函数才会应用到文挡上,也可以不指定filter,这样的话此加强函数就会应用到全部的文挡上。
一个文档可以一次满足多条加强函数和多个filter,如果一次满足多个,那麽就会产生多个加强score,因此ES会使用score_mode定义的方式来合併这些加强score们,得到一个总加强score,得到总加强score之后,才会再使用boost_mode定义的方式去和old_score做合并。GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {.....},
"functions": [ //可以有多个加强函数(或是filter+加强函数),每一个加强函数会产生一个加强score,因
此functions会有多个加强score
{ "field_value_factor": ... },
{ "gauss": ... },
{ "filter": {...}, "weight": ... }
],
"score_mode": "sum", //决定加强score们怎麽合併,
"boost_mode": "multiply" //決定總加強score怎麼和old_score合併
}
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"follower_num" : 5} }
{ "update": { "_id": "2"} }
{ "doc" : {"follower_num" : 10} }
{ "update": { "_id": "3"} }
{ "doc" : {"follower_num" : 25} }
{ "update": { "_id": "4"} }
{ "doc" : {"follower_num" : 3} }
{ "update": { "_id": "5"} }
{ "doc" : {"follower_num" : 60} }
看帖子的人越多,那么帖子的分数就越高GET /forum/article/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["tile", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 2
}
}
}
再加个factor,可以进一步影响分数,new_score = old_score * log(1 + factor * number_of_votes)
boost_mode,可以决定分数与指定字段的值如何计算,multiply,sum,min,max,replace
max_boost,限制计算出来的分数不要超过max_boost指定的值
首先准备数据和索引,在ES插入三条数据,其中title是text类型,like是integer类型(代表点赞量)。{ "title": "ES 入门", "like": 2 }
{ "title": "ES 进阶", "like": 5 }
{ "title": "ES 最高难度", "like": 10 }
先使用一般的query,查看普通的查询的评分会是如何:GET 127.0.0.1/mytest/doc/_search
{
"query": {
"match": {
"title": "ES"
}
}
}
"hits": [
{
"_score": 0.2876821,
"_source": { "title": "ES 入门", "like": 2 }
},
{
"_score": 0.20309238,
"_source": { "title": "ES 进阶", "like": 5 }
},
{
"_score": 0.16540512,
"_source": { "title": "ES 最高难度", "like": 10 }
}
]
使用function_score的field_value_factor改变_score,将old_score乘上like的值。{
"query": {
"function_score": {
"query": {
"match": {
"title": "ES"
}
},
"field_value_factor": {
"field": "like"
}
}
}
}
"hits": [
{
"_score": 1.6540513, //原本是0.16540512
"_source": { "title": "ES 最高难度", "like": 10 }
},
{
"_score": 1.0154619, //原本是0.20309238
"_source": { "title": "ES 进阶", "like": 5 }
},
{
"_score": 0.5753642, //原本是0.2876821
"_source": { "title": "ES 入门", "like": 2 }
}
]
加上max_boost,限制field_value_factor的最大加强score。GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "ES"
}
},
"field_value_factor": {
"field": "like"
},
"max_boost": 3
}
}
}
"hits": [
{
"_score": 0.6092771, //原本是0.20309238
"_source": { "title": "ES 进阶", "like": 5 }
},
{
"_score": 0.5753642, //原本是0.2876821
"_source": { "title": "ES 入门", "like": 2 }
},
{
"_score": 0.49621537, //原本是0.16540512
"_source": { "title": "ES 最高难度", "like": 10 }
}
]


factor作为一个调节用的参数,没有modifier那麽强大会改变整个曲线,他仅改变一些常量值,设置factor>1会提昇效果,factor<1会降低效果。假设modifier是log1p,那麽加入了factor的公式就是new_score = old_score * log(1 + factor * like值)。
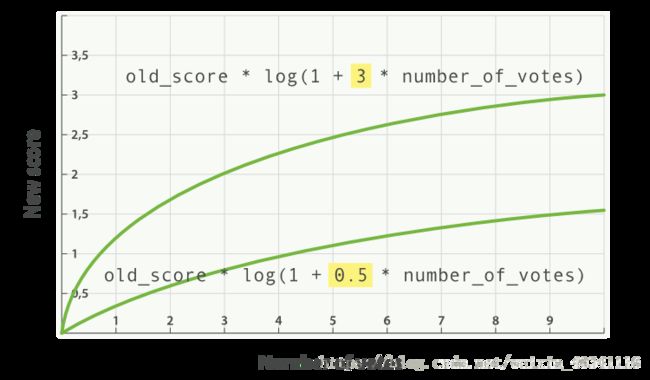
GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "ES"
}
},
"field_value_factor": {
"field": "like",
"modifier": "log1p",
"factor": 2
}
}
}
}
加入了boost_mode=sum、且factor=0.1的公式变为new_score = old_score + log(1 + 0.1 * like值);

GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "ES"
}
},
"field_value_factor": {
"field": "like",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}
exp : 指数函数是先剧烈衰减然后变缓。
guass(最常用) : 高斯函数则是钟形的,他的衰减速率是先缓慢,然后变快,最后又放缓。

offset : 从 origin 为中心,为他设置一个偏移量offset覆盖一个范围,在此范围内所有的评分_score也都是和origin一样满分1.0。
scale : 衰减率,即是一个文档从origin下落时,_score改变的速度。
decay : 从 origin 衰减到 scale 所得的评分_score,默认为0.5 (一般不需要改变,这个参数使用默认的就好了)。
以上面的图为例:
而在此范围之外,评分会开始衰减,衰减率由scale值(此处是5)和decay值(此处是默认值0.5)决定,在origin +/- (offset + scale)处的评分是decay值,也就是在30、50的评分处是0.5分。
也就是说,在origin + offset + scale或是origin - offset - scale的点上,得到的分数仅有decay分。
{ "language": "java", "like": 5 }
{ "language": "python", "like": 10 }
{ "language": "go", "like": 15 }
GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"functions": [
{
"gauss": {
"like": {
"origin": "15", //如果不设置offset,offset默认为0
"scale": "5",
"decay": "0.2"
}
}
}
]
}
}
}
"hits": [
{
"_score": 1,
"_source": { "language": "go", "like": 15 }
},
{
"_score": 0.2, //因为改变了decay=0.2,所以当位于 origin-offset-scale=10 的位置时,分数为decay,就是0.2
"_source": { "language": "python", "like": 10 }
},
{
"_score": 0.0016,
"_source": { "language": "java", "like": 5 }
}
]
GET 127.0.0.1/mytest/doc/_search
{
"query": {
"function_score": {
"functions": [
//第一个gauss加强函数,决定距离的衰减率
{
"gauss": {
"location": {
"origin": { //origin点设成酒店的经纬度座标
"lat": 51.5,
"lon": 0.12
},
"offset": "2km", //距离中心点2km以内都是满分1.0,2km外开始衰减
"scale": "3km" //衰减率
}
}
},
//第二个gauss加强函数,决定价格的衰减率,因为用户对价格更敏感,所以给了这个gauss加强函数2倍的权重
{
"gauss": {
"price": {
"origin": "50",
"offset": "50",
"scale": "20"
}
},
"weight": 2
}
]
}
}
}
29_搜索_fuzzy误拼写模糊搜索、_delete_by_query
doc2: hello javaPOST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "text": "Surprise me!"}
{ "index": { "_id": 2 }}
{ "text": "That was surprising."}
{ "index": { "_id": 3 }}
{ "text": "I wasn't surprised."}
GET /my_index/my_type/_search
{
"query": {
"fuzzy": {
"text": {
"value": "surprize",
"fuzziness": 2
}
}
}
}
surprize --> surprised -> z -> s,末尾加个d,纠正了2次,也可以匹配上,在fuziness指定的2范围内
surprize --> surprising -> z -> s,去掉e,ing,3次,总共要5次,才可以匹配上,始终纠正不了
fuzziness,你的搜索文本最多可以纠正几个字母去跟你的数据进行匹配,默认如果不设置,就是2GET /my_index/my_type/_search
{
"query": {
"match": {
"text": {
"query": "SURPIZE ME",
"fuzziness": "AUTO",
"operator": "and"
}
}
}
}
curl -X POST "localhost:9200/twitter/_delete_by_query" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"name": "测试删除"
}
}
}
第30-58节
30_IK中文分词
standard:没有办法对中文进行合理分词的,只是将每个中文字符一个一个的切割开来,比如说中国人 --> 中 国 人
ik:中国人 很 喜欢 吃 油条(1)git clone https://github.com/medcl/elasticsearch-analysis-ik
(2)git checkout tags/v5.2.0
(3)mvn package
(4)将target/releases/elasticsearch-analysis-ik-5.2.0.zip拷贝到es/plugins/ik目录下
(5)在es/plugins/ik下对elasticsearch-analysis-ik-5.2.0.zip进行解压缩
(6)重启es
PUT /my_index
{
"mappings": {
"my_type": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
POST /my_index/my_type/_bulk
{ "index": { "_id": "1"} }
{ "text": "男子偷上万元发红包求交女友 被抓获时仍然单身" }
{ "index": { "_id": "2"} }
{ "text": "16岁少女为结婚“变”22岁 7年后想离婚被法院拒绝" }
{ "index": { "_id": "3"} }
{ "text": "深圳女孩骑车逆行撞奔驰 遭索赔被吓哭(图)" }
{ "index": { "_id": "4"} }
{ "text": "女人对护肤品比对男票好?网友神怼" }
{ "index": { "_id": "5"} }
{ "text": "为什么国内的街道招牌用的都是红黄配?" }
GET /my_index/_analyze
{
"text": "男子偷上万元发红包求交女友 被抓获时仍然单身",
"analyzer": "ik_max_word"
}
GET /my_index/my_type/_search
{
"query": {
"match": {
"text": "16岁少女结婚好还是单身好?"
}
}
}
31_IK中文分词_配置文件以及自定义词库
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
quantifier.dic:放了一些单位相关的词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
stopword.dic:包含了英文的停用词32_IK中文分词_修改IK分词器源码来基于mysql热更新词库
/**
* 词典初始化 由于IK Analyzer的词典采用Dictionary类的静态方法进行词典初始化
* 只有当Dictionary类被实际调用时,才会开始载入词典, 这将延长首次分词操作的时间 该方法提供了一个在应用加载阶段就初始化字典的手段
*
* @return Dictionary
*/
public static synchronized Dictionary initial(Configuration cfg) {
if (singleton == null) {
synchronized (Dictionary.class) {
if (singleton == null) {
singleton = new Dictionary(cfg);
singleton.loadMainDict();
singleton.loadSurnameDict();
singleton.loadQuantifierDict();
singleton.loadSuffixDict();
singleton.loadPrepDict();
singleton.loadStopWordDict();
new Thread(new HotDictReloadThread()).start();
if(cfg.isEnableRemoteDict()){
// 建立监控线程
for (String location : singleton.getRemoteExtDictionarys()) {
// 10 秒是初始延迟可以修改的 60是间隔时间 单位秒
pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);
}
for (String location : singleton.getRemoteExtStopWordDictionarys()) {
pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);
}
}
return singleton;
}
}
}
return singleton;
}
package org.wltea.analyzer.dic;
import org.apache.logging.log4j.Logger;
import org.elasticsearch.common.logging.ESLoggerFactory;
public class HotDictReloadThread implements Runnable {
private static final Logger logger = ESLoggerFactory.getLogger(HotDictReloadThread.class.getName());
@Override
public void run() {
while(true) {
logger.info("[==========]reload hot dict from mysql......");
Dictionary.getSingleton().reLoadMainDict();
}
}
}
/**
* 加载主词典及扩展词典
*/
private void loadMainDict() {
// 建立一个主词典实例
_MainDict = new DictSegment((char) 0);
// 读取主词典文件
Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_MAIN);
InputStream is = null;
try {
is = new FileInputStream(file.toFile());
} catch (FileNotFoundException e) {
logger.error(e.getMessage(), e);
}
try {
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"), 512);
String theWord = null;
do {
theWord = br.readLine();
if (theWord != null && !"".equals(theWord.trim())) {
_MainDict.fillSegment(theWord.trim().toCharArray());
}
} while (theWord != null);
} catch (IOException e) {
logger.error("ik-analyzer", e);
} finally {
try {
if (is != null) {
is.close();
is = null;
}
} catch (IOException e) {
logger.error("ik-analyzer", e);
}
}
// 加载扩展词典
this.loadExtDict();
// 加载远程自定义词库
this.loadRemoteExtDict();
// 从mysql加载词典
this.loadMySQLExtDict();
}
/**
* 从mysql加载热更新词典
*/
private void loadMySQLExtDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
logger.info("[==========]jdbc-reload.properties");
for(Object key : prop.keySet()) {
logger.info("[==========]" + key + "=" + prop.getProperty(String.valueOf(key)));
}
logger.info("[==========]query hot dict from mysql, " + prop.getProperty("jdbc.reload.sql") + "......");
conn = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.sql"));
while(rs.next()) {
String theWord = rs.getString("word");
logger.info("[==========]hot word from mysql: " + theWord);
_MainDict.fillSegment(theWord.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval"))));
} catch (Exception e) {
logger.error("erorr", e);
} finally {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}
/**
* 加载用户扩展的停止词词典
*/
private void loadStopWordDict() {
// 建立主词典实例
_StopWords = new DictSegment((char) 0);
// 读取主词典文件
Path file = PathUtils.get(getDictRoot(), Dictionary.PATH_DIC_STOP);
InputStream is = null;
try {
is = new FileInputStream(file.toFile());
} catch (FileNotFoundException e) {
logger.error(e.getMessage(), e);
}
try {
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"), 512);
String theWord = null;
do {
theWord = br.readLine();
if (theWord != null && !"".equals(theWord.trim())) {
_StopWords.fillSegment(theWord.trim().toCharArray());
}
} while (theWord != null);
} catch (IOException e) {
logger.error("ik-analyzer", e);
} finally {
try {
if (is != null) {
is.close();
is = null;
}
} catch (IOException e) {
logger.error("ik-analyzer", e);
}
}
// 加载扩展停止词典
List<String> extStopWordDictFiles = getExtStopWordDictionarys();
if (extStopWordDictFiles != null) {
is = null;
for (String extStopWordDictName : extStopWordDictFiles) {
logger.info("[Dict Loading] " + extStopWordDictName);
// 读取扩展词典文件
file = PathUtils.get(getDictRoot(), extStopWordDictName);
try {
is = new FileInputStream(file.toFile());
} catch (FileNotFoundException e) {
logger.error("ik-analyzer", e);
}
// 如果找不到扩展的字典,则忽略
if (is == null) {
continue;
}
try {
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"), 512);
String theWord = null;
do {
theWord = br.readLine();
if (theWord != null && !"".equals(theWord.trim())) {
// 加载扩展停止词典数据到内存中
_StopWords.fillSegment(theWord.trim().toCharArray());
}
} while (theWord != null);
} catch (IOException e) {
logger.error("ik-analyzer", e);
} finally {
try {
if (is != null) {
is.close();
is = null;
}
} catch (IOException e) {
logger.error("ik-analyzer", e);
}
}
}
}
// 加载远程停用词典
List<String> remoteExtStopWordDictFiles = getRemoteExtStopWordDictionarys();
for (String location : remoteExtStopWordDictFiles) {
logger.info("[Dict Loading] " + location);
List<String> lists = getRemoteWords(location);
// 如果找不到扩展的字典,则忽略
if (lists == null) {
logger.error("[Dict Loading] " + location + "加载失败");
continue;
}
for (String theWord : lists) {
if (theWord != null && !"".equals(theWord.trim())) {
// 加载远程词典数据到主内存中
logger.info(theWord);
_StopWords.fillSegment(theWord.trim().toLowerCase().toCharArray());
}
}
}
this.loadMySQLStopwordDict();
}
/**
* 从mysql加载停用词
*/
private void loadMySQLStopwordDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
logger.info("[==========]jdbc-reload.properties");
for(Object key : prop.keySet()) {
logger.info("[==========]" + key + "=" + prop.getProperty(String.valueOf(key)));
}
logger.info("[==========]query hot stopword dict from mysql, " + prop.getProperty("jdbc.reload.stopword.sql") + "......");
conn = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.stopword.sql"));
while(rs.next()) {
String theWord = rs.getString("word");
logger.info("[==========]hot stopword from mysql: " + theWord);
_StopWords.fillSegment(theWord.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval"))));
} catch (Exception e) {
logger.error("erorr", e);
} finally {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}

target\releases\elasticsearch-analysis-ik-5.2.0.zip
在elasticsearch-5.2.0\plugins\ik 对压缩文件进行解压缩


6、重启es
观察日志,日志中就会显示我们打印的那些东西,比如加载了什么配置,加载了什么词语,什么停用词
测试分词GET _analyze
{
"text": "一人饮酒",
"analyzer": "ik_max_word"
}
{
"tokens": [
{
"token": "一人",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "一",
"start_offset": 0,
"end_offset": 1,
"type": "TYPE_CNUM",
"position": 1
},
{
"token": "人",
"start_offset": 1,
"end_offset": 2,
"type": "COUNT",
"position": 2
},
{
"token": "饮酒",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "饮",
"start_offset": 2,
"end_offset": 3,
"type": "CN_WORD",
"position": 4
},
{
"token": "酒",
"start_offset": 3,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
}
]
}
8在mysql中添加词库与停用词
添加分词



分词实验

33_聚合分析_bucket与metric两个核心概念的讲解
(2)notepad++,功能不是太丰富
(3)sublime,整个功能也比较丰富,比较好,自己可以上网去下载,官网,免费的
北京 小王
上海 小张
上海 小丽
上海 小陈
上海bucket:包含了3个人,小张,小丽,小陈
from access_log
group by user_id
metric:count(*),对每个user_id bucket中所有的数据,计算一个数量34_聚合分析_aggs+terms
PUT /tvs
{
"mappings": {
"sales": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date"
}
}
}
}
}
POST /tvs/sales/_bulk
{ "index": {}}
{ "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-10-28" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" }
{ "index": {}}
{ "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2016-05-18" }
{ "index": {}}
{ "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2016-07-02" }
{ "index": {}}
{ "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2016-08-19" }
{ "index": {}}
{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" }
{ "index": {}}
{ "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2017-01-01" }
{ "index": {}}
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
aggs:固定语法,要对一份数据执行分组聚合操作
popular_colors:就是对每个aggs,都要起一个名字,这个名字是随机的,你随便取什么都ok
terms:根据字段的值进行分组
field:根据指定的字段的值进行分组{
"took": 61,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"popular_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4
},
{
"key": "绿色",
"doc_count": 2
},
{
"key": "蓝色",
"doc_count": 2
}
]
}
}
}
aggregations:聚合结果
popular_color:我们指定的某个聚合的名称
buckets:根据我们指定的field划分出的buckets
key:每个bucket对应的那个值
doc_count:这个bucket分组内,有多少个数据
数量,其实就是这种颜色的销量
默认的排序规则:按照doc_count降序排序35_聚合分析_aggs+terms+avg统计每种颜色电视平均价格
GET /tvs/sales/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
“avg_price”: {
“avg”: {
“field”: “price”
}
}
}{
"took": 28,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4,
"avg_price": {
"value": 3250
}
},
{
"key": "绿色",
"doc_count": 2,
"avg_price": {
"value": 2100
}
},
{
"key": "蓝色",
"doc_count": 2,
"avg_price": {
"value": 2000
}
}
]
}
}
}
avg_price:我们自己取的metric aggs的名字
value:我们的metric计算的结果,每个bucket中的数据的price字段求平均值后的结果
from tvs.sales
group by color36_聚合分析_bucket嵌套实现颜色+品牌的多层下钻分析
红色电视中的1台小米的平均价格是多少?GET /tvs/sales/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"color_avg_price": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4,
"color_avg_price": {
"value": 3250
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "长虹",
"doc_count": 3,
"brand_avg_price": {
"value": 1666.6666666666667
}
},
{
"key": "三星",
"doc_count": 1,
"brand_avg_price": {
"value": 8000
}
}
]
}
},
{
"key": "绿色",
"doc_count": 2,
"color_avg_price": {
"value": 2100
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "TCL",
"doc_count": 1,
"brand_avg_price": {
"value": 1200
}
},
{
"key": "小米",
"doc_count": 1,
"brand_avg_price": {
"value": 3000
}
}
]
}
},
{
"key": "蓝色",
"doc_count": 2,
"color_avg_price": {
"value": 2000
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "TCL",
"doc_count": 1,
"brand_avg_price": {
"value": 1500
}
},
{
"key": "小米",
"doc_count": 1,
"brand_avg_price": {
"value": 2500
}
}
]
}
}
]
}
}
}
37_聚合分析_统计每种颜色电视最大最小价格
avg:avg aggs,求平均值
max:求一个bucket内,指定field值最大的那个数据
min:求一个bucket内,指定field值最小的那个数据
sum:求一个bucket内,指定field值的总和
mGET /tvs/sales/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} },
"sum_price" : { "sum": { "field": "price" } }
}
}
}
}
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4,
"max_price": {
"value": 8000
},
"min_price": {
"value": 1000
},
"avg_price": {
"value": 3250
},
"sum_price": {
"value": 13000
}
},
{
"key": "绿色",
"doc_count": 2,
"max_price": {
"value": 3000
},
"min_price": {
"value":
}, 1200
"avg_price": {
"value": 2100
},
"sum_price": {
"value": 4200
}
},
{
"key": "蓝色",
"doc_count": 2,
"max_price": {
"value": 2500
},
"min_price": {
"value": 1500
},
"avg_price": {
"value": 2000
},
"sum_price": {
"value": 4000
}
}
]
}
}
}
38_聚合分析_hitogram按价格区间统计电视销量和销售额
"histogram":{
"field": "price",
"interval": 2000
},
GET /tvs/sales/_search
{
"size" : 0,
"aggs":{
"price":{
"histogram":{
"field": "price",
"interval": 2000
},
"aggs":{
"revenue": {
"sum": {
"field" : "price"
}
}
}
}
}
}
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_price": {
"buckets": [
{
"key": 0,
"doc_count": 3,
"sum_price": {
"value": 3700
}
},
{
"key": 2000,
"doc_count": 4,
"sum_price": {
"value": 9500
}
},
{
"key": 4000,
"doc_count": 0,
"sum_price": {
"value": 0
}
},
{
"key": 6000,
"doc_count: {
"value":": 0,
"sum_price" 0
}
},
{
"key": 8000,
"doc_count": 1,
"sum_price": {
"value": 8000
}
}
]
}
}
}
39_聚合分析_date hitogram之统计每月电视销量
2017-02-01~2017-02-28,就是一个bucket
extended_bounds,min,max:划分bucket的时候,会限定在这个起始日期,和截止日期内GET /tvs/sales/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2016-01-01",
"max" : "2017-12-31"
}
}
}
}
}
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_sold_date": {
"buckets": [
{
"key_as_string": "2016-01-01",
"key": 1451606400000,
"doc_count": 0
},
{
"key_as_string": "2016-02-01",
"key": 1454284800000,
"doc_count": 0
},
{
"key_as_string": "2016-03-01",
"key": 1456790400000,
"doc_count": 0
},
{
"key_as_string": "2016-04-01",
"key": 1459468800000,
"doc_count": 0
},
{
"key_as_string": "2016-05-01",
"key": 1462060800000,
"doc_count": 1
},
{
"key_as_string": "2016-06-01",
"key": 1464739200000,
"doc_count": 0
},
{
"key_as_string": "2016-07-01",
"key": 1467331200000,
"doc_count": 1
},
{
"key_as_strin
"key_as_string": "2016-09-01",
"key": 1472688000000,
"doc_count": 0
},g": "2016-08-01",
"key": 1470009600000,
"doc_count": 1
},
{
{
"key_as_string": "2016-10-01",
"key": 1475280000000,
"doc_count": 1
},
{
"key_as_string": "2016-11-01",
"key": 1477958400000,
"doc_count": 2
},
{
"key_as_string": "2016-12-01",
"key": 1480550400000,
"doc_count": 0
},
{
"key_as_string": "2017-01-01",
"key": 1483228800000,
"doc_count": 1
},
{
"key_as_string": "2017-02-01",
"key": 1485907200000,
"doc_count": 1
}
]
}
}
}
40_聚合分析_date_histogram统计每季度每个品牌的销售额
GET /tvs/sales/_search
{
"size": 0,
"aggs": {
"group_by_sold_date": {
"date_histogram": {
"field": "sold_date",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2016-01-01",
"max": "2017-12-31"
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
},
"total_sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_sold_date": {
"buckets": [
{
"key_as_string": "2016-01-01",
"key": 1451606400000,
"doc_count": 0,
"total_sum_price": {
"value": 0
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": []
}
},
{
"key_as_string": "2016-04-01",
"key": 1459468800000,
"doc_count": 1,
"total_sum_price": {
"value": 3000
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "小米",
"doc_count": 1,
"sum_price": {
"value": 3000
}
}
]
}
},
{
"key_as_string": "2016-07-01",
"key": 1467331200000,
"doc_count": 2,
"total_sum_price": {
"value": 2700
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "TCL",
"doc_count": 2,
"sum_price": {
"value": 2700
}
}
]
}
},
{
"key_as_string": "2016-10-01",
"key": 1475280000000,
"doc_count": 3,
"total_sum_price": {
"value": 5000
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "长虹",
"doc_count": 3,
"sum_price": {
"value": 5000
}
}
]
}
},
{
"key_as_string": "2017-01-01",
"key": 1483228800000,
"doc_count": 2,
"total_sum_price": {
"value": 10500
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "三星",
"doc_count": 1,
"sum_price": {
"value": 8000
}
},
{
"key": "小米",
"doc_count": 1,
"sum_price": {
"value": 2500
}
}
]
}
},
{
"key_as_string": "2017-04-01",
"key": 1491004800000,
"doc_count": 0,
"total_sum_price": {
"value": 0
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": []
}
},
{
"key_as_string": "2017-07-01",
"key": 1498867200000,
"doc_count": 0,
"total_sum_price": {
"value": 0
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": []
}
},
{
"key_as_string": "2017-10-01",
"key": 1506816000000,
"doc_count": 0,
"total_sum_price": {
"value": 0
},
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": []
}
}
]
}
}
}
41_聚合分析_query+filter:统计指定品牌下每个颜色的销量
from tvs.sales
where brand like “%长%”
group by priceGET /tvs/sales/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
}
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "绿色",
"doc_count": 1
},
{
"key": "蓝色",
"doc_count": 1
}
]
}
}
}
42_聚合分析_global bucket:单个品牌与所有品牌销量对比
GET /tvs/sales/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "长虹"
}
}
},
"aggs": {
"single_brand_avg_price": {
"avg": {
"field": "price"
}
},
"all": {
"global": {},
"aggs": {
"all_brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0,
"hits": []
},
"aggregations": {
"all": {
"doc_count": 8,
"all_brand_avg_price": {
"value": 2650
}
},
"single_brand_avg_price": {
"value": 1666.6666666666667
}
}
}
all.all_brand_avg_price:拿到所有品牌的平均价格43_聚合分析_filter+aggs:统计价格大于1200的电视平均价格
过滤+聚合GET /tvs/sales/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 1200
}
}
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
{
"took": 41,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 7,
"max_score": 0,
"hits": []
},
"aggregations": {
"avg_price": {
"value": 2885.714285714286
}
}
}
44_聚合分析_bucket filter:统计牌品最近一个月的平均价格
GET /tvs/sales/_search
{
"size": 0,
"query": {
"term": {
"brand": {
"value": "长虹"
}
}
},
"aggs": {
"recent_150d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-150d"
}
}
},
"aggs": {
"recent_150d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_140d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-140d"
}
}
},
"aggs": {
"recent_140d_avg_price": {
"avg": {
"field": "price"
}
}
}
},
"recent_130d": {
"filter": {
"range": {
"sold_date": {
"gte": "now-130d"
}
}
},
"aggs": {
"recent_130d_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
45_聚合分析_排序:按每种颜色的平均销售额降序排序
GET /tvs/sales/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4,
"avg_price": {
"value": 3250
}
},
{
"key": "绿色",
"doc_count": 2,
"avg_price": {
"value": 2100
}
},
{
"key": "蓝色",
"doc_count": 2,
"avg_price": {
"value": 2000
}
}
]
}
}
}
GET /tvs/sales/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_price": "asc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
46_聚合分析_颜色+品牌下钻分析时按最深层metric进行排序
GET /tvs/sales/_search
{
"size": 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_price": "desc"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_color": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "红色",
"doc_count": 4,
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "三星",
"doc_count": 1,
"avg_price": {
"value": 8000
}
},
{
"key": "长虹",
"doc_count": 3,
"avg_price": {
"value": 1666.6666666666667
}
}
]
}
},
{
"key": "绿色",
"doc_count": 2,
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "小米",
"doc_count": 1,
"avg_price": {
"value": 3000
}
},
{
"key": "TCL",
"doc_count": 1,
"avg_price": {
"value": 1200
}
}
]
}
},
{
"key": "蓝色",
"doc_count": 2,
"group_by_brand": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "小米",
"doc_count": 1,
"avg_price": {
"value": 2500
}
},
{
"key": "TCL",
"doc_count": 1,
"avg_price": {
"value": 1500
}
}
]
}
}
]
}
}
}
47_聚合分析_易并行聚合算法,三角选择原则,近似聚合算法

近似估计后的结果,不完全准确,但是速度会很快,一般会达到完全精准的算法的性能的数十倍
(2)精准+大数据:hadoop,批处理,非实时,可以处理海量数据,保证精准,可能会跑几个小时
(3)大数据+实时:es,不精准,近似估计,可能会有百分之几的错误率
如果采取100%精准的算法:延时一般在5s~几十s,甚至几十分钟,几小时, 0%错误
未完待续。。。。。48_聚合分析_cardinality去重每月销售品牌数量统计
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"months" : {
"date_histogram": {
"field": "sold_date",
"interval": "month"
},
"aggs": {
"distinct_colors" : {
"cardinality" : {
"field" : "brand"
}
}
}
}
}
}
{
"took": 70,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_sold_date": {
"buckets": [
{
"key_as_string": "2016-05-01T00:00:00.000Z",
"key": 1462060800000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2016-06-01T00:00:00.000Z",
"key": 1464739200000,
"doc_count": 0,
"distinct_brand_cnt": {
"value": 0
}
},
{
"key_as_string": "2016-07-01T00:00:00.000Z",
"key": 1467331200000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2016-08-01T00:00:00.000Z",
"key": 1470009600000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2016-09-01T00:00:00.000Z",
"key": 1472688000000,
"doc_count": 0,
"distinct_brand_cnt": {
"value": 0
}
},
{
"key_as_string": "2016-10-01T00:00:00.000Z",
"key": 1475280000000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2016-11-01T00:00:00.000Z",
"key": 1477958400000,
"doc_count": 2,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2016-12-01T00:00:00.000Z",
"key": 1480550400000,
"doc_count": 0,
"distinct_brand_cnt": {
"value": 0
}
},
{
"key_as_string": "2017-01-01T00:00:00.000Z",
"key": 1483228800000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
},
{
"key_as_string": "2017-02-01T00:00:00.000Z",
"key": 1485907200000,
"doc_count": 1,
"distinct_brand_cnt": {
"value": 1
}
}
]
}
}
}
49_聚合分析_cardinality算法之优化内存开销以及HLL算法
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {
"field" : "brand",
"precision_threshold" : 100
}
}
}
}
cardinality算法,会占用precision_threshold * 8 byte 内存消耗,100 * 8 = 800个字节
占用内存很小。。。而且unique value如果的确在值以内,那么可以确保100%准确
100,数百万的unique value,错误率在5%以内PUT /tvs/
{
"mappings": {
"sales": {
"properties": {
"brand": {
"type": "text",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
}
}
}
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {
"field" : "brand.hash",
"precision_threshold" : 100
}
}
}
}
50_聚合分析_percentiles百分比算法以及网站访问时延统计
tp90:90%的请求的耗时最长在多长时间
tp99:99%的请求的耗时最长在多长时间PUT /website
{
"mappings": {
"logs": {
"properties": {
"latency": {
"type": "long"
},
"province": {
"type": "keyword"
},
"timestamp": {
"type": "date"
}
}
}
}
}
POST /website/logs/_bulk
{ "index": {}}
{ "latency" : 105, "province" : "江苏", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 83, "province" : "江苏", "timestamp" : "2016-10-29" }
{ "index": {}}
{ "latency" : 92, "province" : "江苏", "timestamp" : "2016-10-29" }
{ "index": {}}
{ "latency" : 112, "province" : "江苏", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 68, "province" : "江苏", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 76, "province" : "江苏", "timestamp" : "2016-10-29" }
{ "index": {}}
{ "latency" : 101, "province" : "新疆", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 275, "province" : "新疆", "timestamp" : "2016-10-29" }
{ "index": {}}
{ "latency" : 166, "province" : "新疆", "timestamp" : "2016-10-29" }
{ "index": {}}
{ "latency" : 654, "province" : "新疆", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 389, "province" : "新疆", "timestamp" : "2016-10-28" }
{ "index": {}}
{ "latency" : 302, "province" : "新疆", "timestamp" : "2016-10-29" }
GET /website/logs/_search
{
"size": 0,
"aggs": {
"latency_percentiles": {
"percentiles": {
"field": "latency",
"percents": [
50,
95,
99
]
}
},
"latency_avg": {
"avg": {
"field": "latency"
}
}
}
}
{
"took": 31,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 12,
"max_score": 0,
"hits": []
},
"aggregations": {
"latency_avg": {
"value": 201.91666666666666
},
"latency_percentiles": {
"values": {
"50.0": 108.5,
"95.0": 508.24999999999983,
"99.0": 624.8500000000001
}
}
}
}
GET /website/logs/_search
{
"size": 0,
"aggs": {
"group_by_province": {
"terms": {
"field": "province"
},
"aggs": {
"latency_percentiles": {
"percentiles": {
"field": "latency",
"percents": [
50,
95,
99
]
}
},
"latency_avg": {
"avg": {
"field": "latency"
}
}
}
}
}
}
{
"took": 33,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 12,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_province": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "新疆",
"doc_count": 6,
"latency_avg": {
"value": 314.5
},
"latency_percentiles": {
"values": {
"50.0": 288.5,
"95.0": 587.75,
"99.0": 640.75
}
}
},
{
"key": "江苏",
"doc_count": 6,
"latency_avg": {
"value": 89.33333333333333
},
"latency_percentiles": {
"values": {
"50.0": 87.5,
"95.0": 110.25,
"99.0": 111.65
}
}
}
]
}
}
}
51_聚合分析_percentiles rank以及网站访问时延SLA统计
GET /website/logs/_search
{
"size": 0,
"aggs": {
"group_by_province": {
"terms": {
"field": "province"
},
"aggs": {
"latency_percentile_ranks": {
"percentile_ranks": {
"field": "latency",
"values": [
200,
1000
]
}
}
}
}
}
}
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 12,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_province": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "新疆",
"doc_count": 6,
"latency_percentile_ranks": {
"values": {
"200.0": 29.40613026819923,
"1000.0": 100
}
}
},
{
"key": "江苏",
"doc_count": 6,
"latency_percentile_ranks": {
"values": {
"200.0": 100,
"1000.0": 100
}
}
}
]
}
}
}
52_聚合分析_doc value正排索引的聚合
{
“query”: {
“match”: {
“search_field”: “test”
}
},
“aggs”: {
“group_by_agg_field”: {
“terms”: {
“field”: “agg_field”
}
}
}
}
doc2: hello test
doc3: world test
world doc1,doc3
test1 doc1
test2 doc1
test doc2,doc3
“match”: {
“search_field”: “test”
}
}
doc3: agg2
…
…
…
…
agg1 doc2
agg2 doc3
doc2: hello test
doc3: world test
world doc1,doc3
test1 doc1
test2 doc1
test doc2,doc3
“match”: {
“search_field”: “test”
}
}
…
…
100万个
doc2: agg1
doc3: agg2
…
…
100万个
doc2: agg1 hello world
doc3: agg2 test hello53_聚合分析_doc value机制内核级原理深入探秘
如果os cache内存大小不足够放得下整个正排索引,doc value,就会将doc value的数据写入磁盘文件中
给jvm更少的内存,给os cache更大的内存
64g服务器,给jvm最多16g,几十个g的内存给os cache
os cache可以提升doc value和倒排索引的缓存和查询效率
doc2: 550
doc3: 500
(2)少于256个值,使用table encoding模式:一种压缩方式
(3)大于256个值,看有没有最大公约数,有就除以最大公约数,然后保留这个最大公约数
doc2: 24PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"my_field": {
"type": "keyword"
"doc_values": false
}
}
}
}
}
54_聚合分析_string field聚合实验以及fielddata
GET /test_index/test_type/_search
{
"aggs": {
"group_by_test_field": {
"terms": {
"field": "test_field"
}
}
}
}
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [test_field] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "test_index",
"node": "4onsTYVZTjGvIj9_spWz2w",
"reason": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [test_field] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [test_field] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory."
}
},
"status": 400
}
POST /test_index/_mapping/test_type
{
"properties": {
"test_field": {
"type": "text",
"fielddata": true
}
}
}
{
"test_index": {
"mappings": {
"test_type": {
"properties": {
"test_field": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"fielddata": true
}
}
}
}
}
}
GET /test_index/test_type/_search
{
"size": 0,
"aggs": {
"group_by_test_field": {
"terms": {
"field": "test_field"
}
}
}
}
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_test_field": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "test",
"doc_count": 2
}
]
}
}
}
GET /test_index/test_type/_search
{
"size": 0,
"aggs": {
"group_by_test_field": {
"terms": {
"field": "test_field.keyword"
}
}
}
}
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_test_field": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "test",
"doc_count": 2
}
]
}
}
}
55_聚合分析_fielddata内存控制以及circuit breaker断路器
一个index的一个field,所有doc都会被加载,而不是少数doc
不是index-time创建,是query-time创建
fielddata占用的内存超出了这个比例的限制,那么就清除掉内存中已有的fielddata数据
默认无限制,限制内存使用,但是会导致频繁evict和reload,大量IO性能损耗,以及内存碎片和gcGET /_stats/fielddata?fields=*
GET /_nodes/stats/indices/fielddata?fields=*
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
indices.breaker.fielddata.limit:fielddata的内存限制,默认60%
indices.breaker.request.limit:执行聚合的内存限制,默认40%
indices.breaker.total.limit:综合上面两个,限制在70%以内
56_聚合分析_fielddata filter的细粒度内存加载控制
POST /test_index/_mapping/my_type
{
"properties": {
"my_field": {
"type": "text",
"fielddata": {
"filter": {
"frequency": {
"min": 0.01,
"min_segment_size": 500
}
}
}
}
}
}
57_聚合分析_fielddata预加载机制以及序号标记预加载
POST /test_index/_mapping/test_type
{
"properties": {
"test_field": {
"type": "string",
"fielddata": {
"loading" : "eager"
}
}
}
}
doc2: status2
doc3: status2
doc4: status1
status2 --> 1
doc2: 1
doc3: 1
doc4: 0POST /test_index/_mapping/test_type
{
"properties": {
"test_field": {
"type": "string",
"fielddata": {
"loading" : "eager_global_ordinals"
}
}
}
}
58_聚合分析_海量bucket优化机制:从深度优先到广度优先
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "films",
"size" : 5
}
}
}
}
}
}
actor1 actor2 .... actor