【Python 百炼成钢】错位键盘、单词的长度、字母重排
文章目录
- 前言
- 一、错位键盘
-
- 问题描述
- 问题分析
- 代码实现
- 二、单词的平均长度
-
- 问题描述
- 问题分析
- 代码实现
- 三、字母重排
-
- 问题描述
- 问题分析
- 代码实现
- 四、Tex括号问题
-
- 问题描述
- 问题分析
- 代码实现
- ฅʕ•̫͡•ʔฅ
- ᴴᴬᵛᴱ ᴬ ᴳᴼᴼᴰ ᵀᴵᴹᴱ
前言
前面一篇分享了关于数值的一些处理方式,本篇呢进行一下字符串处理的分享
题目也是超级简单,记录一下对字符串处理的方式
错位键盘(也就是错位字符串,使用错位的字符去匹配原字符)
单词的长度(字符串的分割)
字母重排(子串与主串的匹配,感觉这个匹配方式不错)
Tex括号问题(超级简单,下面见)
下面就步入正题开始我们今天的内容啦

一、错位键盘
问题描述
在我们打字的时候,往往会因为手误将A敲成S,将S敲成D
现在有一位程序员由于手误输入了一行字符串 请凭借你聪明的大脑将其还原
(键盘上的字符顺序:"`1234567890-=QWERTYUIOP[]\ASDFGHJKL;'ZXCVBNM,./")
样例输入:O S, GOMR YPFSU/
样例输出:I AM FINE TODAY
问题分析
这类的问题有事后想到的就是进行字符的替换,但是一个键盘上字符那么多逐个替换的话非常的费时费力于是我们可以进行一个下标数组的编排,用于记录字符在字符串中的位置,而为了不必要的转换我们不妨将下标数组开辟到255个这样每一种字符的ASCII值就可以直接作为下标数组的下标拿到他在原来字符串的索引。
然后根据输入可以知道,输入的有空格,给定的键盘内没有空格,所以需要进行分词处理。在Python中分词有极为简便的方法,在C语言中可以开辟一个字符型指针数组,用于存储每一段单词,处理方式与单词的平均长度无异。可以先往下看看。分完词之后可以迭字符型指针数组。然后按序列输出。输出的时候先拿字符做下标取原字符串中的索引,然后再拿索引-1去原字符中取字符。注意输出时候的格式。
代码实现
老规矩先上运行结果:
代码如下:

import sys
s=sys.stdin.readline().strip().split()
indexarr=[0]*255
# 将所有数据存放进一个数组,将键盘上相邻的两个字母在数组中以索引的形式相连
mystr="`1234567890-=QWERTYUIOP[]\\ASDFGHJKL;'ZXCVBNM,./"
# 将每一位字母的索引存储起来。供以后遍历输入的数据使用
for i in range(len(mystr)):
indexarr[ord(mystr[i])]=i
flag=True
#遍历输入的n段字符串
for line in s:
if flag:
flag=False
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")
else:
print(" ",end="")
for i in line:
print(mystr[indexarr[ord(i)]-1],end="")
二、单词的平均长度
这一题使用Python做超级简单
使用c语言做的话先进行空格统计,如果空格后面不为空格就进行单词数加1
如果空格后面依旧是空格向下遍历,如果一个位置不为空格就进行字母数加1
最终要将单词数额外加1,因为首尾单词循环的时候只统计进去了一个。
问题描述
输入若干个单词,单词只包含字母,每个单词由一个或多个空格组成
输出单词的平均长度
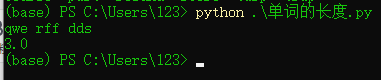
样例输入:qwe qwe qwe
样例输出:3.0
问题分析
对字符串进行分词,然后求每一个字串的长度,再将长度和除以单词的个数
代码实现
老规矩先上运行结果:
代码如下:
import sys
num=0
n=0
# 这里使用strip()去除输入的末尾换行符
# 使用split()进行字符串分段最后得到的是一个列表形式
mystr=sys.stdin.readline().strip().split()
for i in mystr:
num+=len(i)
n+=1
print(num/n)
三、字母重排
问题描述
输入一个字典(*****结尾),然后再输入若干单词。每输入一个单词w,你都需要
在字典中找出所有可以用w的字母重排后得到的单词,并按照字典序从小到大的顺序在一
行中输出(如果不存在,输出:0。输入单词之间用空格或空行隔开,且所有输入单词都由
不超过6个小写字母组成。注意,字典中的单词不一定按字典序排列。
样例输入:
第一行 tarp given score refund only trap work earn course pepper part
第二行 resco nfudre aptr sett oresuc
样例输出:
course part refund score tarp trap
问题分析
给出一个字典,所以我们在进行查找的时候可以先将字典进行处理,然后依照字典的标准进行查词
这里我们可以先对字典进行排序得到首字母有序的字典,然后对字典中每一个元素进行排序。
对要查询的子串进行排序,然后遍历有序字典进行查找,找到直接输出(也就是说将标准的字典按
一定的方式处理,然后将所要查的词经过相同的转换后与字典进行比对)
代码实现
老规矩先上运行结果:
代码如下:

import sys
# 元字典序字符串
mydic=list(sys.stdin.readline().strip().split())
mydic=sorted(mydic)
words=sys.stdin.readline().strip().split()
# 排序后的字符串
newdic=[]
newwords=[]
for i in mydic:
# 字符串不可以直接排序,先转换成字典,然后进行排序
newdic.append("".join(sorted(i)))
for i in words:
newwords.append("".join(sorted(i)))
flag=False
i=0
while i<len(newdic):
if newdic[i] in newwords:
if not flag:
print(mydic[i],end="")
flag=True
else:
print(" ",mydic[i],end="")
i+=1
if not flag:
print(0)
四、Tex括号问题
问题描述
有一篇文章,在撰稿的时候,没有按照指定格式编排,现在需要将包含’’ 的标点符号转换成为
只有中文双引号的文章“”
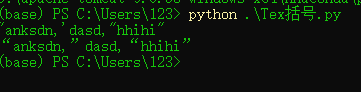
样例输入:"anksdn,'dasd,“hhihi”
样例输出:“anksdn,”dasd,“hhihi”
问题分析
这里与前面提到的灯光模拟非常的类似,只需要记性标记位的整顿就好
可以设计一个标记flag,当flag为True时遇见"进行左引号“的输出然后
立即将标记变为与其相反的值当flag为false时遇见"立即进行右引号输出。
然后将flag标记为True
代码实现
老规矩先上运行结果:
代码如下:
import sys
s=sys.stdin.readline().strip()
flag=True
for i in s:
if i=="'" or i=="\"":
if flag:
print("“",end="")
else:
print("”",end="")
flag=not flag
continue
print(i,end="")