国外大神一张图学会python-12306看了会沉默,国外大神利用机器学习15分钟破解网站验证码!...
原标题:12306看了会沉默,国外大神利用机器学习15分钟破解网站验证码!
相信很多同学,都曾被12306的神级验证码虐到过怀疑人生,但是看了下面这一位国外一位大神的分享,小蓝我算是知道为什么12306网站要把验证码设置的这么变态了!

登录网站时必须输入的图片验证码可以用来识别访问者到底是人还是机器——这同时也是某种程度上的「图灵测试」,人工智能研究者们寻求破解的方向,让计算机学会破解验证码,我们就距离通用智能更近了一步(前不久 Vicarious 发表在 Science 上的论文就介绍了一种用于破解图片验证码的机器学习新模型)。今天,破解全世界最为流行的图片验证码需要多久?本文作者 Adam Geitgey 告诉你:仅需 15 分钟。
每个人都讨厌 CAPTCHA——这些恼人的图片中包含你必须输入的文字,正确地填写它你才能访问网站。CAPTCHA 全称「全自动区分计算机和人类的公开图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart)」,旨在确认访问者是真正的人类,防止恶意程序的入侵。然而,随着深度学习和计算机视觉技术的发展,现在这些认证方法可以被我们轻松破解了。
最近,我正在读 Adrian RoseBrock 撰写的《Deep Learning for Computer Vision with Python》。在这本书中,Adrian 利用机器学习破解了 E-ZPass New York 网站上的 CAPTCHA 验证码:
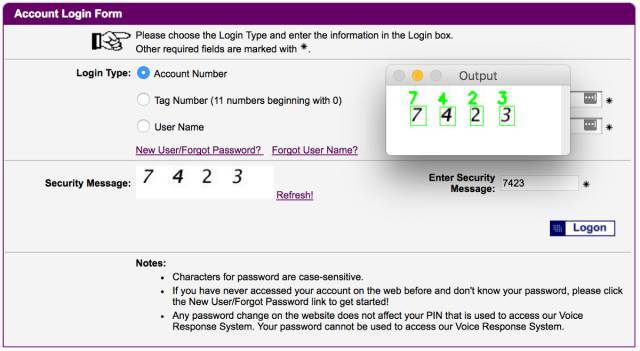
在这里,Adrian 没有接入生成 CAPTCHA 图片应用源代码的权限。为了破解这样的系统,我们必须找到数百张示例图片,然后训练机器学习模型来破解它。
但是如果我们想要破解开源的 CAPTCHA 系统——在这里我们拥有所有源代码的访问权,事情又会如何呢?
我访问了 WordPress.org (http://wordpress.org/) 插件登记网站,在其中搜索「CAPTCHA」。结果中显示的第一个内容是「Really Simple CAPTCHA」,已经拥有超过 100 万次活跃安装了:https://wordpress.org/plugins/really-simple-captcha/。
重点在于,这里有它的源代码!有了生成 CAPTCHA 图片的源代码,我们就可以轻松破解验证码了。在这里,为了让任务更具挑战性,我们先给自己添加一点限制:我们能不能在 15 分钟内破解它?Let's try it!
Note:这并不意味着我们在批评「Really Simple CAPTCHA」插件及其作者。目前,插件的作者已表示该款验证码已经不再安全,并推荐用户寻找其他更加具有安全性的认证方式。但如果你真的是这 100 万用户中的一员,或许你应该有所防备了:)
挑战
首先,我们需要做好计划,让我们看看 Really Simple CAPTCHA 生成的图片是什么样子。在 Demo 站中,我们看到了这样的情景:

一个 CAPTCHA 图片范例
看起来它会生成由四个字符组成的图片。让我们在这个插件的 PHP 源代码里面确认一下:
public function __construct() {
/*Charactersavailableinimages */
$this->chars ='ABCDEFGHJKLMNPQRSTUVWXYZ23456789';
/*Lengthof a wordinan image */
$this->char_length =4;
/*Arrayof fonts.Randomlypicked up per character */
$this->fonts = array(
dirname( __FILE__ ) .'/gentium/GenBkBasR.ttf',
dirname( __FILE__ ) .'/gentium/GenBkBasI.ttf',
dirname( __FILE__ ) .'/gentium/GenBkBasBI.ttf',
dirname( __FILE__ ) .'/gentium/GenBkBasB.ttf',
);
没错,它会生成四个字母/数字组成的 CAPTCHA 验证码,每个字符的字体各不相同,在代码中我们也可以看出验证码中不会包含「O」或者「I」,因为这两个字母很可能会让人与数字产生混淆。所以,我们共有 32 个数字或字母需要识别。没问题!
至此用时:2 分钟
我们需要的工具
在开始破解之前,我们先要介绍一下行动所需的工具:
Python 3
Python 是目前人工智能领域中最为流行的编程语言,包含多种机器学习和计算机视觉库。
OpenCV
OpenCV 是计算机视觉和图像处理任务上的流行框架。在这里,我们需要使用 OpenCV 来处理 CAPTCHA 生成的图像,OpenCV 拥有 Python API,所以我们可以直接使用 Python 调用它。
Keras
Keras 是一个使用 Python 编写的深度学习框架。他可以让我们更加轻松地定义、训练和使用深度神经网络——仅需编写很少的代码。
TensorFlow
TensorFlow 是谷歌推出与维护的机器学习库,也是目前人工智能领域里最为流行的框架。我们会在 Keras 之上写代码,但 Keras 实际上并没有实现神经网络运算的方法——它需要使用 TensorFlow 作为后端来完成具体的工作。
好了,让我们回到挑战之中。
创立数据集
想要训练任何机器学习系统,我们都需要相应的数据集。为了破解 CAPTCHA 验证码系统,我们需要这样的训练数据:

看起来少不了大量的标注工作。不过在这里我们有了 WordPress 插件的源代码,我们可以稍稍修改插件,让它自动输出 10,000 个 CAPTCHA 图片,以及相应的正确答案。
在对源代码的几分钟破解之后(只要简单地加个『for』循环),我们就拥有了一个内含 10,000 张 PNG 图片的训练集,而图片的正确答案就是每张图片的文件名:

Note:在这部分我不会给你示例代码。因为本文面向教学,希望各位不会真的去破解各家 WordPress 网站。不过这里我会给你 10,000 张生成的图片让大家用于复现。
至此用时:5 分钟
简化问题
现在我们已经有了训练数据,我们可以直接用它来训练一个简单的神经网络:
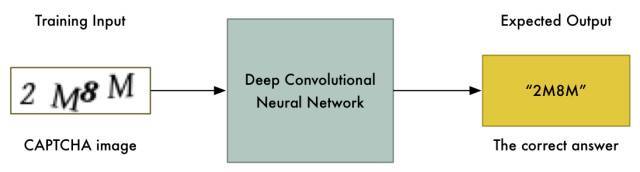
因为有了足够的数据,这种方法将能很好地工作,但我们可以使问题变得更简单。因为问题越简单、训练数据越少,我们解决问题所需要的计算力就越少,毕竟我们总共只有 15 分钟的时间。
幸运的是,一个 CAPTCHA 图像由四个符合组成,因此我们可以以某种方式将图像分割开以令每张图像只有一个符号。这样的话我们只需训练神经网络识别单个字符就行了。
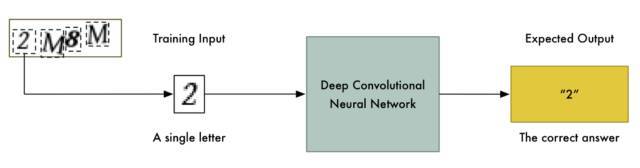
我们并不能手动地用 Photoshop 等图像软件将它们分割开,因为训练图像总共有 1 万张。此外,我们也不能将图像切分为四个等大小的图像块,因为 CAPTCHA 会随机地将这些不同的字符放置在不同的水平线上,如下所示:
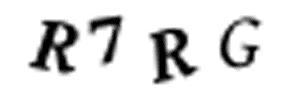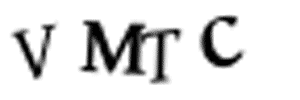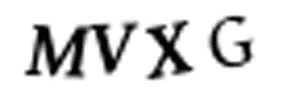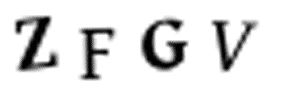
幸运的是,我们能使用已有的方法自动完成这一部分。在图像处理中,我们经常需要检测有相同色彩的像素块,这些连续像素块的边界可以称之为轮廓。而 OpenCV 有一个内置的 findContours() 函数可以检测这些轮廓的区域。
所以我们原始的 CAPTCHA 图像为如下所示:
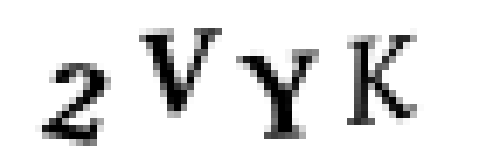
然后我们将该图像转换为纯净的黑白像素点(即采用色彩阈值的方法),因此我们将很容易寻找到连续的轮廓边界:

下面我们使用 OpenCV 的 findContours() 函数以检测包含连续相同像素块的分离部分:

随后将每个区域保存为一个单独的图像文件就非常简单了,而且我们也知道每张图像从左到右有四个字符,因此我们可以在保存的时候使用这种知识标注各个字符。我们只需要按顺序保存它们,并将每一张图像保存为对应的字符名。
但是还有一个问题,有些 CAPTCHA 图像包含重叠的字符:

这就意味着我们很可能会将两个字符抽取为一个分割区域:

如果我们不解决这个问题,那么我们最后就会创建一个非常糟糕的训练集。我们需要解决这个问题,以免模型会将两个重叠的字符识别为一个。
这里有一个简单的解决方案,如果字符轮廓的宽要比高长一些,那么很有可能这一个切分内就包含了两个字符。因此我们可以将这种连体的字符拆分为两半,并将它们视为单独的字符。

我们将宽度大于高度一定数值的图像拆分为两个数值,虽然这种方法非常简单,但在 CAPTCHA 上却十分有效。
现在我们有方法抽取独立的字符,因此我们需要将所有的 CAPTCHA 图像都执行这种处理。我们的目标是收集每个字符的不同变体,并将单个字符的所有变体保留在一个文件夹中。

上图展示了字符「W」的抽取情况,我们最后从 1 万张 CAPTCHA 图像中获取了 1147 张不同的「W」。处理完这些图像后,我们总共大约花了 10 分钟。
构建并训练神经网络
因为我们一次只需要识别单个字符,所以并不需要一个复杂的神经网络架构,且识别这种字母与数字的任务要比其它识别复杂图像的任务简单地多。因此我们使用了一个简单的卷积神经网络,它一共包含两个卷积层与两个全连接层。

如果我们使用的是 Keras,那么只需要几行代码就能构建一个神经网络架构:
# Build the neural network!
model =Sequential()
# First convolutional layer with max pooling
model.add(Conv2D(20, (5,5), padding="same", input_shape=(20,20,1), activation="relu"))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# Second convolutional layer with max pooling
model.add(Conv2D(50, (5,5), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# Hidden layer with 500 nodes
model.add(Flatten())
model.add(Dense(500, activation="relu"))
# Output layer with 32 nodes (one for each possible letter/number we predict)
model.add(Dense(32, activation="softmax"))
# Ask Keras to build the TensorFlow model behind the scenes
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
现在开始训练
# Train the neural network
model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, verbose=1)
在经过 10 个 Epoch 的训练后,我们的训练准确度可以到达 100%,因此我们就能终止程序以完成整个模型的训练。所以最后我们一共花了 15 分钟。
使用训练后的模型解决 CAPTCHA 识别问题
现在我们利用已训练的神经网络可以轻松识别 CAPTCHA 验证码:
在网站上使用 WordPress 插件获取真正的 CAPTCHA 验证码;
将 CAPTCHA 图像分割为四个独立的字符块,这里使用的方法和创建训练集的方法一样;
调用神经网络对这四个独立的字符块进行预测;
将四个预测结果排列以作为该 CAPTCHA 验证码的返回结果。

或者我们可以直接使用命令行运行:
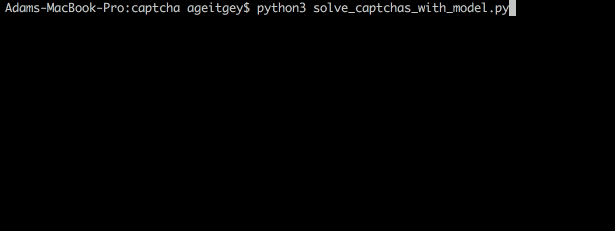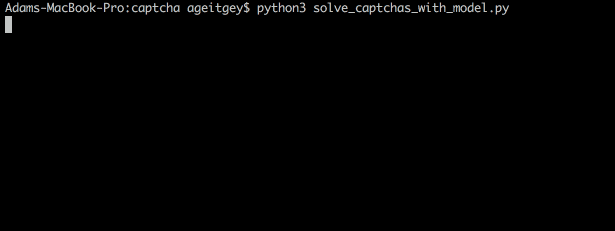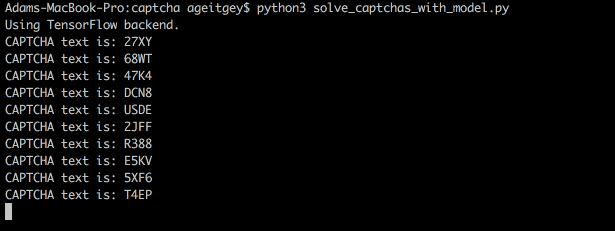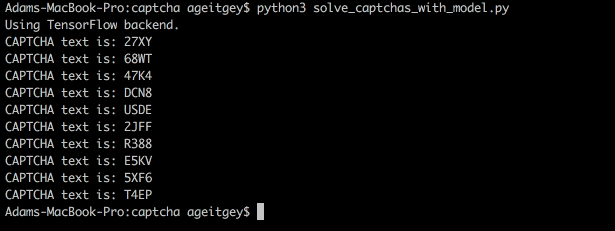
试试看!
如果你想自己试验一下,这里有代码:https://s3-us-west-2.amazonaws.com/mlif-example-code/solving_captchas_code_examples.zip
这个压缩文件包中包含 10,000 张实例图片以及本文中涉及的每一步的代码。其中还有 README 文件告诉你如何运行它。
如果你想要深入了解代码背后的知识,那么最好读一读那本《Deep Learning for Computer Vision with Python》。它涵盖了很多细节,并介绍了大量示例,如果你对解决现实生活中困难问题的示例感兴趣,那么它或许很适合你。
作者:Adam Geitgey 机器之心编译
原文链接:https://medium.com/@ageitgey/how-to-break-a-captcha-system-in-15-minutes-with-machine-learning-dbebb035a710返回搜狐,查看更多
责任编辑: