【2021.12.12】基于用户名/序列号的软件保护机制分析
文章目录
- 一、实验环境和开发工具
- 二、任务描述
- 三. 分析过程
- 四、序列号求解
-
- 4.1 不构造注册机
- 4.2 构造注册机
- 五 安全性分析
-
- 5.1 保护机制分析
- 5.2 改进建议
- 六 注册机源代码
- 总结
一、实验环境和开发工具
硬件环境:
处理器 i5-8300H
内存(RAM) 8G
硬盘 476G
软件环境:
Windows 10
开发工具:
Visual studio 2019
IDA PRO7.5
二、任务描述
针对所给的程序CM.exe,要求:
1.软件保护机制破解:序列号求解
(1)用户名为自己的班学号,如 19219101
(2)序列号形如:Q1T33-6IOYL-U6NQW-QCQM8-SNCJT
2.软件保护机制的安全性分析
(1)该保护机制是否存在问题,试分析之
(2)若保护机制存在问题,请提出改进的建议
3.写出注册机。(选做)
4.撰写详细的实验报告。
三. 分析过程
首先尝试了直接反汇编Crack.exe,无法识别,发现其大多内容是Unexplored,可读性不高,且开头有Rar的字段显示,推测其为压缩文件,对Crack.exe进行解压。
提示需要解压密码,根据同目录下的”你相信自己所看到的吗?”txt,推测解压密码就是”你相信自己所看到的吗?”解压成功得到CM.exe.使用IDA PRO反汇编CM.exe。
反汇编后的代码没有主函数,不知道代码在哪里开始,逆向思维反过来推,通过View-open subviews-Strings找到提示failure的字符串aFailure
![]()
再通过Search-Text找到调用该字符串地址的函数loc_401885
![]()
再通过Search-Text找到调用loc_401885的段loc_401831
发现跳转至loc_401885(输出验证失败)的条件是edi!=eax,输入验证成功的条件是edi==eax,而edi又与esi有关重点关注esi和****eax的由来
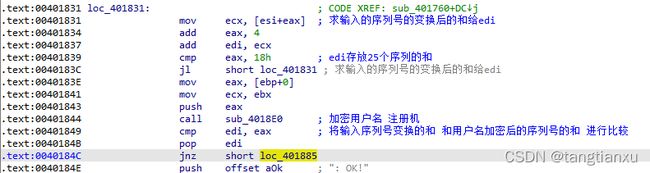
再通过Search-Text找到调用loc_401831的段,发现除了他自己以外没人调用他,那么就去分析前面的代码段。
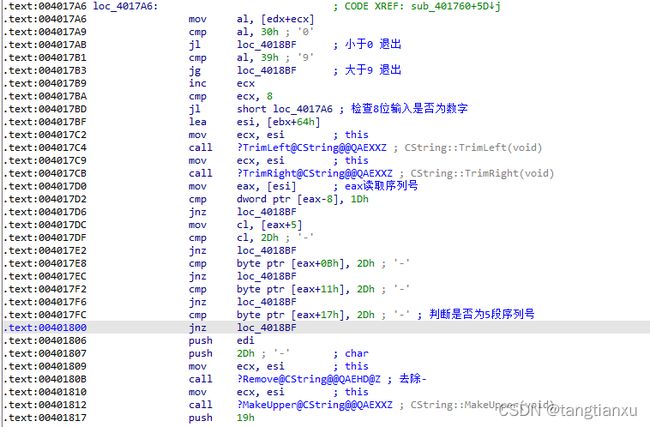

易看出这段在检查输入的用户名是否为8位数字,判断输入的序列号是否为5段,并将去除‘-’的序列号作为sub_401700的参数,通过esi返回。
查看sub_401700,进行反编译
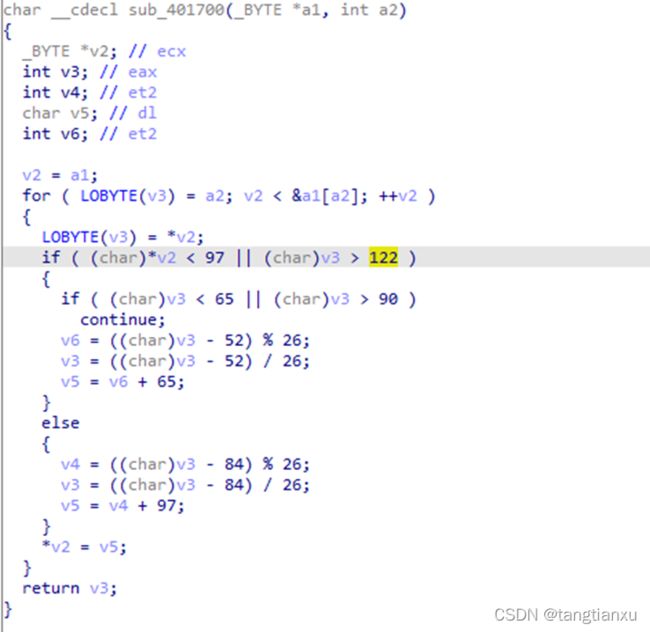 sub_401700将满足条件的字节(A~Z),进行减‘A’模26后+‘4’的操作。
sub_401700将满足条件的字节(A~Z),进行减‘A’模26后+‘4’的操作。
即将输入的序列号中所有的字母进行了该处理,字母外的字符保持不变。
这就是esi的由来。
再返回loc_401831,查看得到eax的过程。发现eax首先存储着输入的用户名然后作为参数被sub_4018E0调用.
![]()
查看sub_4018E0

发现其调用了sub_401590,有五个参数,(输入的用户名,用户名位数8,明文数组,序列号25,和一个数组).查看该明文数组,其内部为{ 0xC8 ,0xED,0xBC,0xFE,0xB0 ,
0xB2,0xC8,0xAB,0xCA,0xB5,
0xD1,0xE9,0xBF,0xCE,0xB3,
0xCC,0x31,0x39,0x32,0x31,
0x39,0x31,0x2D,0x32,0x00 };
查看sub_401590,发现为RC4算法,以输入的用户名为密钥

值得一提的是,与一般的RC4算法不同,一般的RC4算法密钥数组和状态数组是分开存储的,在这段代码中将长为512字节的数组前256位当成状态数组,后256位当成密钥数组.该密钥数组即重复填充用户名填充至256位形成的,加密也是一步到位。
我们知道RC4加密后的输出为明文与随机密钥流异或的结果,结果大概率不是我们想要的序列号。在RC4算法结束后,进行了如下图所示的操作

翻译成C++即
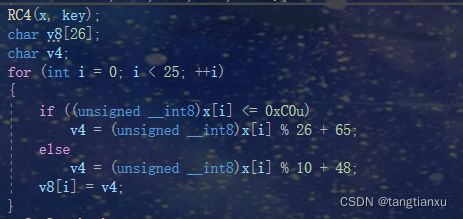
其中x[i]为RC4加密后的结果。最后将v8中的序列号每4个4个相加,将和存储在eax中返回。
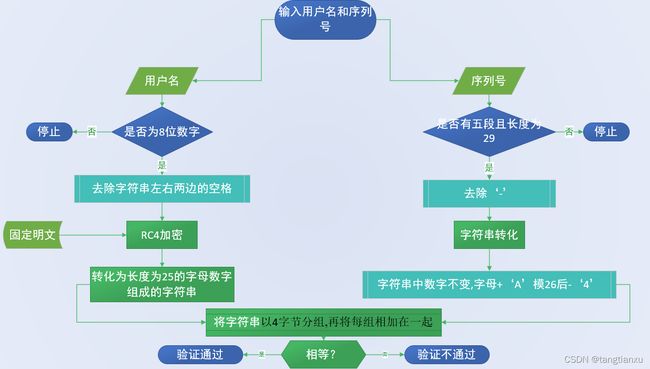
分析至此,整个程序的逻辑框架就清晰了。程序将输入的用户名作为初始密钥与一固定明文进行RC4加密,再将得到的密文转换为字符串A,将A以4字节分组,再将每组相加在一起得到值x。将输入的序列号B进行转换成字符串C, 将C以4字节分组,再将每组相加在一起得到值y。若x=y,则验证通过;若x!=y,验证失败。
整个程序流程图如下:
四、序列号求解
4.1 不构造注册机
如果不构造注册机,我们只要首先截取到RC4加密转化得到的字符串,并将该字符串进行逆转化(即将字符串中的-‘A’+’4’再加26直至该字节大于’A’),便能得到所需的序列号。
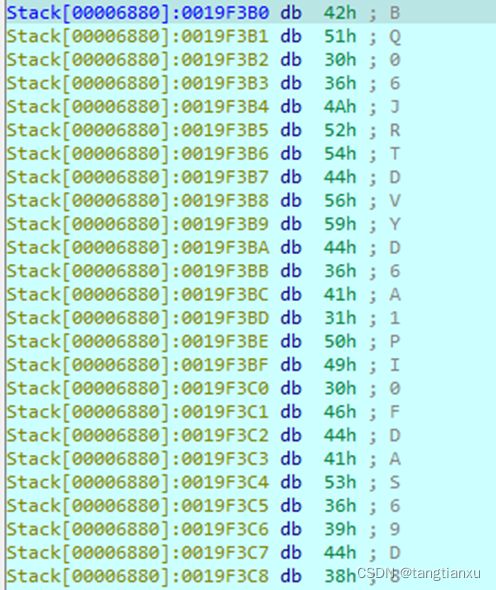
调试运行到这一行时能看到RC4加密转化得到的字符串
![]()
我输入的是19219119,在这里截取到的字符串为BQ06JRTDVYD6A1PIOFDAS69D8
进行逆转化得到OD06W-EGQIL-Q6N1C-V0SQN-F69Q8
进行输入
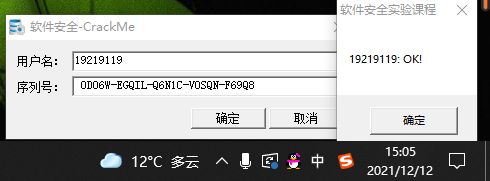
求解成功
4.2 构造注册机
构造注册机,就要关注输入用户名后的加密过程。首先实现RC4算法
void RC4(int *C, char* key)
{
int S[256];//状态数组
int T[256];
int count = 256;
for (int i = 0; i < 256; i++)
{
S[i] = i;
int tmp = i % count;
T[i] = key[tmp];
}
int j = 0;
for (int i = 0; i < 256; i++) {
j = (j + S[i] + T[i]) % 256;
int tmp;
tmp = S[j];
S[j] = S[i];
S[i] = tmp;
}
int length = 25;
int i;
i = 0, j = 0;
for (int p = 0; p < length; p++){
i = (i + 1) % 256;
j = (j + S[i]) % 256;
int tmp;
tmp = S[j];
S[j] = S[i];
S[i] = tmp;
int k= (S[(S[i] + S[j]) % 256]);
C[p] = C[p] ^ k;
}
}
然后构造明文数组
int plaintext[25] = { 0xC8 ,0xED,0xBC,0xFE,0xB0 ,
0xB2,0xC8,0xAB,0xCA,0xB5,
0xD1,0xE9,0xBF,0xCE,0xB3,
0xCC,0x31,0x39,0x32,0x31,
0x39,0x31,0x2D,0x32,0x00 };
初始密钥为从键盘输入.然后将RC4加密后的结果进行
char v8[26];
char v4;
for (int i = 0; i < 25; ++i)
{
if ((unsigned __int8)x[i] <= 0xC0u)
v4 = (unsigned __int8)x[i] % 26 + 65;
else
v4 = (unsigned __int8)x[i] % 10 + 48;
v8[i] = v4;
}
v8[25] = '\0';
}
然后进行逆转化
char* fun(char a1[], int a2)
{
char v3 = 0;
char v6;
char* v2 = a1;
for (int i = 0; i < a2; i++)
{
v3 = v2[i];
if ((v3 < 'A' || v3 > 'Z')) {
arr[i] = v3;
continue;
}
else {
v6 = '\0';
v6 = v3 - 'A' + '4';
while (v6 < 'A') {
v6 = v6 + 26;
}
arr[i] = v6;
continue;
}
}
return arr;
}
运行注册机

得到的结果与上述不构造注册机得到的结果是相同的,自然验证也是通过的。

五 安全性分析
5.1 保护机制分析
一个系统的密码保护机制是否安全取决于两个方面,即密码传输的安全性和密码存储的安全性。很显然该软件密码传输的安全性是非常差的,无论破解者是否懂得加密算法,随意构造格式正确的输入便能截取到与序列号关系非常近的结果,稍加转化便能破解。
从密码学的角度来说,该系统也不满足唯一解密性。每一个用户名对应的序列号远不止一个。因为验证的方法并不是比对输入的序列号和正确的序列号,而是将输入的序列号和正确的序列号以4字节分组,再比较两者各相加在一起得到的值是否相等。将25位序列号分为6组4字节的字符串,和一1字节的字符串,若将他们看成千位百位十位个位,则有6位千位,6位百位,6位十位,6位十位。如果不变换字符串中的字节,只进行移动,那么对应的能够通过验证的输入就有666*6=1296种,如图所示,将正确答案的第四位的Q与第8位的6互换

且最后一位不参与运算,可以为任意字节。
如果将某位+1,对应的位数-1,亦能通过验证
比如将正确答案的第一位O加1换成P,将第五位W减1换成V也通过了验证

这样能构造的正确的输入就远不止1296种了,远超这个数量级。
因此,该保护机制是有很严重的问题的。
5.2 改进建议
一、放弃RC4算法,现阶段对RC4的攻击方法已有很多。
二、改进验证算法。不应该采取比较字节和这种对应多种输入的算法,应该考虑使用Hash算法,比如SHA-256,实现单向性和抗碰撞,避免被破解者获取到关键的相关信息。
六 注册机源代码
#include总结
逆向分析是信息安全专业学习必须掌握的基本技能。通过本次实验
1) 阅读汇编代码的能力得到提高。汇编语言看似枯燥无味,可读性不高,但寄存器的各种操作都接近代码的本质,只要稍加分析,问题的脉络,漏洞的原理就清晰了。一开始是有些生疏,各种跳转指令都得去搜索,各种mov lea指令也是不能理解。但经过一段时间的精心阅读和断点调试,我逐渐摸到逆向分析的门道。正着走不通的路就反过来走,动态分析前尽可能静态分析找到问题所在。对逆向分析的运用,随着实验的深入,是越来越深刻,而且各种思路也是层出不穷。
2) 思考的能力得到提高。单一用户名对应的序列号究竟有多少种?我本以为只是6个分组的置换,但通过动手实践我可以交换他们对应位置上的数,可以A处增加B处所减少的值…我发现问题并没有要求的那么简单,只要深入去思考,花时间去学习,能够看清很多表面下的东西。