ARM 汇编详解 -- 体系结构与编程
1.ARM体系结构与编程:
ARM是什么?
Advanced RISC Machines
RSIC, 精简指令集 ---> ARM, MIPS, LA, IBM
CSIC, 复杂指令集 ---> intel,AMD
指令集 架构 Soc
ARMV4T ARM7 s3c44b0
ARMV5TE ARM9 s3c2410/s3c2440
ARMV6 ARM11 s3c6410
ARMV7 coretex-a sp5v210
ARMV8 coretex-a53 s5p6818 用在高大上领域,音视频处理较多
coretex-r 实时性较强的领域
coretex-m 以单片机的价格实现32bit的性能
stm32

ARM 官方网站: www.arm.com
1.流水线:
三级流水线: 取指令 解码指令 执行指令

最佳流水线:
for (i = 0; i < 10; i++) //执行效率更高
{
for (j=0; j<10000; j++)
{
....
}
}
for (j = 0; j < 10000; j++)
{
for (i=0; i<10;i++)
{
....
}
}

常见的打断流水线:
LDR 流水线举例:

冯诺依曼体系结构:
取指令 取数据用的是同一套总线
ARM7
哈佛体系结构:
ARM9 及以后的版本
ARM9中的流水线为5级
2.ARM 编程模型
2.1 ARM 工作模式

SVC (管理模式) : 系统上电, 执行了软中断指令
内核态
FIQ (快速中断) : 发生了高优先级的中断
IRQ (中断) : 发生了低优先级的中断
ABORT(终止模式) : 当产生了非法的存储访问时
UNDEF (未定义) : 遇到了不认识的指令
SYSTEM (系统模式): 与用户模式共用的寄存器模式
USER(用户模式): 用户态
前5种为异常模式, 后两种为正常模式
前6中为特权模式,后两种为非特权模式
2.2. ARM 工作状态
ARM状态, 执行ARM (32bit) 指令时
TUMB状态, 执行TUMB (16bit) 指令时
以上两种工作状态可以进行切换
异常处理过程中必须处于ARM工作状态
2.3 寄存器组织结构
寄存器和特殊功能寄存器的区别:
1) 存在的位置不同:
寄存器 位于 ARM Core内部
特殊功能寄存器位于ARM Core外部
2) 访问方式不同:
特殊功能寄存器都有特定的物理地址
寄存器只有名字没有地址
使用C很难访到
ARM中有37个32bit的寄存器
其中31个通用寄存器 命名为 r0 r1 ....r15
r11 (fp, frame pointer忽略)
r13 (sp, 栈指针寄存器)
r14 (lr, 保存函数的指针)
func ()
{
...
return
}
main ()
{
func (); // i++指令的地址----> lr
i++;
}
r15 (pc, 保存取指令的位置)
6 个状态寄存器 :
1个程序状态寄存器 cpsr
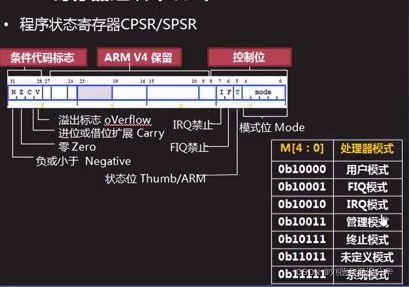
[4:0] 模式位, 标识当前arm核处于什么模式下,在特权模式下,可以写该寄存器
[5] T位, 1 当前处于thumb状态 0 处于arm状态
[6] F位, 1 禁止FIQ
0 使能FIQ
[7] I位, 1 禁止RIQ
0 使能RIQ
[28] V位 有符号数据在做运算的时候有进位
[29] C位 运算结果最高位有进位
0xfffffffc + 10 C=1
[30] Z位,运算结果为0时=1
[31] N 运算结果为负数时 = 1
5个状态寄存器 spsr,是CPSR的备份寄存器
每种工作模式下,只能访问其中的一个子集

2.4 异常与异常向量表
裸板程序:
main () {
xxx_init ();
...
while (1) {
周期性的事务
}
}
+ 异常处理
ARM core支持7种异常:
reset (复位异常) 按下复位键 svc
undef (未定义异常) 执行到不认识的指令 undef
swi (软中断异常) 执行汇编指令"swi" svc
pretch abort (预取终止异常) 取指令时进行了非法的存储器访问 abort
data abort (数据终止异常) 取数据时进行了非法的存储器访问 abort
irq (中断异常) 按键中断 irq
fiq (快速中断异常) 高优先级的中断产生 frq
即7种异常会导致arm 进入5种异常模式
当产生异常时, arm硬件自动做4件事
1) 备份CPSR
SPSR_= CPSR
2) 修改CPSR
a) 切换为arm工作状态 CPSR[T] = 0
b) 切换为异常工作模式 CPSR[4:0]
c) 禁止中断 CPSR[I] = 1 CPSR[F] = 1
3) 保存返回地址到LR_
4) 给PC赋值
reset异常 ⇒ PC= 0X00
undef异常 => PC = 0X04
swi 异常 => PC = 0X08
pretch 异常=> PC = 0X0C
data 异常 => PC = 0X10
irq 异常 => PC = 0X18
fiq 异常 => PC = 0X1C
PC = vec_tab_base + offset
从异常返回,软件上需要处理:
1) 恢复CPSR
CPSR = SPSR_
2) 返回被打断的位置
pc = LR_

2.5 ARM支持的数据类型
byte
halfword
word
double word
2.6 对齐方式
4字节对齐, 存储的首地址可以被4整除
struct stu
{
int a;
char c;
short d;
int b;
};
sizeof (struct stu) = ?
2.7 大小端的判断
int a = 0x12345678;
字节序:
大端模式 小端模式
地址 值
0x100 12 78
0x101 34 56
0x102 56 34
0x103 78 12
编程实现arm处理器大小端的判断?
这里我也提供两种方法:
int main ()
{
int a = 0x12345678;
char *p = (char *) &a;
if (*p == 0x12)
{
printf ("BIG-endian\n");
}
else
{
printf ("LITTLE-endian\n");
}
return 0;
}
-----------------------------------
union
{
int a;
char c[4];
} endian;
int main ()
{
int i = 0;
endian.a = 1;
if (endian.c[0]==1){
printf ("LITTLE-endian\n");
}
return 0;
}
------------------------------------
//linux 内核中判断大小端是用的union进行判断的
static union { char c[4]; unsigned long l; } endian_test __initdata = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
3 ARM 汇编
3.1 基本概念
汇编的语言 叫做助记符语言
ARM 和 Thumb指令集的设计目标
由编译器产生最佳代码
尤其是Thumb指令集
大多数系统设计的主要工作都集中在编译代码 (C), 一般不需要了解指令集信息
但是以下情况需要
嵌入式系统需要初始化和中断服务程序
所有的系统都需要调试,可能汇编指令级的调试
可以通过汇编语言来提升系统性能
有些指令编译器无法产生,只能通过汇编完成
3.2 ARM汇编指令
ARM 汇编指令的特点:
1) 大多数汇编指令都是单周期
2) 大多数arm汇编指令都可以条件执行


3.2.1 分支跳转指令
b {cond} <目标地址> //类似于goto
b main
b 指令应用示例:
start:
cmp r0,r1
beq not_copy
move r0,r1
not_copy:
b .
bl {cond} <目标地址> // 用于函数调用
bl main //在向main函数跳转前,记录当前下条指令的地址到LR
注意: 目标地址的范围 +-32M
为指令执行的条件码 EQ,NE,CS,CC
为指令跳转的目标地址.这个目标地址的计算方法是:
将指令中的24位带符号的补码立即数扩展为32位(扩展其符号位),
将此32位数左移两位;将得到的值加到PC寄存器中,即得到跳转目标的地址.
原理: 根据4字节对齐
0 0000
4 0100
8 1000
c 1100
可以知道4字节对齐的,最后两位都是0,所以不再计算,24位的立即数相当于有26位的寻址能力.2^25--> 32M

bl 指令应用示例:
START:
MOV R0, #1
MOV R1, #2
BL DoAdd
B .
DoAdd:
ADD R0,R0,R1
MOV PC,LR
bx
blx
b {l} {cond}
b {l} {cond}
x, 带状态切换 目标地址处的如果目标地址的指令是ARM 指令,
则 寄存器的bit[0] 为0.
bit[0] 为 1时,则 寄存器的bit[0]为1.
Rn,一定是通用寄存器(r0~r15)
存储要跳转的目标地址
注意: 跳转范围不受限制 (0~4G)
.CODE 32
ARM_code:
ADR R0, THUMB_code + 1
BX R0 @R0 里面存的是目标地址
......
.CODE 16
THUMB_code:
ADR R0,ARM_Code
BX R0
3.2.2 数据处理指令
3.2.2.0 移位指令
LSL: Logical shift left 逻辑左移 进行移位操作后,空出的位添0
, LSL #
, LSL @ 移位的位数由Rs寄存器的bit[7:0] 决定
LSR: Logical shift right 逻辑右移 进行移位操作后,空出的位添0
, LSR #
, LSR @ 移位的位数由Rs寄存器的bit[7:0] 决定
ASR: Arithmetic shif right 算数右移 最高位补符号位
ROR: 循环右移 最低位循环变成最高位
RRX: 带扩展位的循环右移 新的最高位由CPSR的C位,而且最低位更新C位.

3.2.2.1 数据传输指令
mov {cond} {s} ,
cond, 可以条件执行
moveq r0,#10
s, 操作结果影响 cpsr的 NZCV
mov R0, #10 @R0 = 10
movs R0, #10 @R0 = 10 N=0 Z=0
Rd,一定是通用寄存器
operand : 三种表现形式
mov r0, #10
注意立即数的合法性问题
存在一个8bit的立即数,循环右移偶数位得到,那么这个立即数就是合法的.
mov r0, r2 @ r0 = r2
mov r0, r2, lsl #2 @ r0 = r2 << 2
moveqs r0, r1 @if (CPSR.Z ==1)
movs r0, r1 @ r0 = r1 if (r0==0) Z=1 else Z=0
@ N= r0[31]
mvn {cond} {s} ,
将operand 表示的数据的反码传送到目标寄存器r0中,并根据操作的结果影响CPSR的NZ位.
3.2.2.2 算数运算指令
add {cond} {s} , ,
cond ,可以条件执行
s, 操作结果影响NZCV
N=r[31]
if (Rd==0) Z=1 else Z=0
最高位有进位 C=1 反之 C=0
Rd
Rn
一定是通用寄存器
operand 三种表达形式:
add r0, r1, #10 @立即数形式
add r0, r1, r2 @寄存器
add r0, r1, r2, lsl #3 @r0 = r1+r2*8
adc {cond} {s} , ,
adc r0, r1, r2 @r0=r1+r2+C
64bit的加法运算:
高 低
被加数 r0 r1
加数 r2 r3
和 r0 r1
adds r1, r1,r3
adc r0, r0,r2
sub {cond} {s} , ,
s,注意对C位的影响
Rn > Operand C=1
反之 C=0
sbc {cond} {s} , ,
sbc r0, r1, r2 @r0= r1-r2-NOT(C) @又反了一下,出现负负得正的效果
64bit 的减法:
高 低
被减数 r4 r5
减数 r6 r7
差 r8 r9
subs r9, r5, r7 @if (r5 > r7) C=1
sbc r8, r4, r6 @r8 = r4 -r6 -Not (C)
rsb {cond} {s} , , @逆向减法指令
rsb r0, r1, r2 @r0 = r2 - r1
rsb r0, r1, #8 @r0 = 8 - r1
rsb r0, #8, r1 @语法错误
rsb r0, r0, #0 @取相反数
练习: 求1到10的累加和,结果保存到r0中
1.arm 指令实现:
.text
.CODE 32
.global _start
_start:
mov r1, #10
mov r0, #0
sum:
add r0, r0, r1
sub r1, r1, #1
cmp r1, #0
beq sum
b .
.end
2.LoongArch 指令实现:
.text
.global _start
_start:
li.d $r1, 10
li.d $r2, 0
li.d $r3, 1
sum:
add.d $r1, $r1, $r2
sub.d $r2, $r2, $r3
beqz $r2, sum
b .
.end
qemu, 仿真软件
运行在PC机上, 模拟ARM核执行指令的执行过程
qemu 的安装:
联网安装: sudo apt-get install qemu
在线安装: cd /home/liuyang/DownLoads/qemu
dpkg -i *.deb
重新编译程序 -g 选项
arm-coretex_a9-linux-gnueabi-as sum.s -o sum.o -g
arm-coretex_a9-linux-gnueabi-ld sum.o -o sum
启动服务器端
qemu-arm -g 1234 sum
启动客户端调试程序
另外开启一个新的窗口
arm-coretex_a9_linux-gnueabi-gdb sum
出现的问题:
arm-coretex_a9-linux-gnueabi-gdb:
/lib/x86_64-linux-gnu/libc.so.6: version 'GLIBC_2.16' not found
解决方案:
cd Downloads
dpkg -i libc6_2.16-0ubuntu4_amd64.deb
重新执行 arm-coretex_a9_linux-gnueabi-gdb sum
(gdb) target remote localhost:1234
(gdb) l
(gdb) b 8
(gdb) c
(gdb) info reg
(gdb) n
(gdb) info reg r0
(gdb) b 16
(gdb) c
(gdb) info reg r0
3.2.2.3 位运算指令
and {} {s} ,, @按位与
and r0, r1, r2 @r0=r1&r2
and r0, r1, #8 @r0=r1&8
and r0,r1,r2,lsl #3 @r0= r1 & r2*8
orr {} {s} ,, @按位或
orrgts r0, r1, r2
eor {} {s} ,, @按位异或 (两个位数值相同为0)
eor r0, r0, #8 @ r0 = r0 ^ 8
如何取反32位整型变量的BIT15?
mov r1, #1
eor r0, r0, r1, lsl #15
bic {} {s} ,, @第2个操作数对应的bit位里为1,结果为0
@第2个操作数对应的bit位里为0,结果不变

bic r0, r0, #0x08 @将r0中的bit 3位清0
如何清除一个整型变量(32位)的第7位? 其他位保持不变?
mov r1, #1
bic r0, r0, r1, lsl #7
3.2.2.4 比较测试指令
cmp {} ,
特点:
1) 不需要+s 默认就影响NZCV
2) 操作结果不保存
cmp r0, #0x08 @alu_out = r0 -0x08
@ r0 > 0x08 C = 1
@ r0 == 0x08 Z = 1
@ r0 < 0x08 C = 0
例子:
cmp r1, #10
moveq r0, r1
bleq test
......
test:
......
tst {} ,
tst r0, #0x08 @测试r0 bit 3是否为0
@alu_out = r0 &0x08
@如果为 0 Z=1
@如果非 0 Z=0
teq {} ,
teq r0, #0x08 @测试r0 和 0x08是否相等
@alu_out = r0 ^ 0x08
@相等 Z = 1
@不等 Z = 0
练习二: 求两个数据的最大公约数
128 24
算法: 104 24
80 24
56 24
32 24
8 24
16 8
8 8
.text
.global _start
_start:
move r0, 128
move r1, 24
gcd:
cmp r0, r1
beq gcd_ok
subcs r0, r0, r1
subcc r1, r1, r0
b gcd
gcd_ok:
b .
3.2.3 加载存储指令
ARM中所有的运算都是在通用寄存器中完成的

操作的对象: 通用寄存器
内存 (特殊功能寄存器)
mov r1, 0x48000000
ldr r0, [r1] @将内存0x48000000开始的4字节数据加载到r0中
@r0 = *((int *) 0x48000000)
ldrb r0,[r1] @将内存0x48000000开始的1字节数据加载到r0中
@ (*(unsigned char *) 0x48000000) 取出来的8个bit位存放到了r0的低8个bit, r0的高24个bit 补0
ldrsb r0,[r1] @将内存0x48000000开始的1字节数据加载到r0中, r0的高24个bit补符号位 (*(char *) 0x48000000)
ldrh r0,[r1] @将内存0x48000000开始的2字节数据加载到r0中, r0的高16个bit补0 (*(unsigned short *) 0x48000000)
ldrsh r0, [r1] @将内存0x48000000开始的2字节数据加载到r0中, r0的高16个bit补0 (*(short *) 0x48000000)
ldr r0, [r1] @[r1] ---> r0
--------------------------------------
ldr r0,[r1,#0x08] @[r1+0x08] ----> r1
ldr r0,[r1+r2] @[r1+r2] ----> r0
ldr r0, [r1,r2,lsl #2] @[r1+r2*4]---->r0
--------------------------------------
ldr r0,[r1,#0x08]! @[r1+0x08] ----> r1 r1 = r1 +0x08 加!会进行更新基址
ldr r0,[r1+r2]! @[r1+r2] ----> r0 r1 = r1 +0x08
ldr r0, [r1,r2,lsl #2]! @[r1+r2*4]---->r0 r1 = r1 + r2 *4
--------------------------------------
ldr r0, [r1], #0x08 @ [r1]---> r0 r1=r1+0x08
ldr r0, [r1], r2 @ [r1]---> r0 r1=r1+ r2
ldr r0, [r1], r2, lsl #2 @[r1] --->r0 r1= r1 + r2 *4
mov r1, #0x48000000
str r0, [r1] @将r0中的4字节数据写入到0x48000000 指向的内存中
strb r0,[r1] @将r0中的低8bit位写入到0x48000000 指向的内存中
strh r0,[r1] @将r0低16bit写入到0x48000000 指向的内存中
str r0,[r1] @r0----->[r1]
str r0,[r1+0x08] @r0-----> [r1+0x08]
str r0,[r1], r2 @r0---->[r1+r2]
str r0,[r1], r2, lsl #2 @r0 -----> [r1+r2*4]
-----------------------------------
str r0,[r1+0x08]! @r0-----> [r1+0x08] r1 = r1+0x08
str r0, [r1]!, r2 @r0---->[r1+r2] r1 = r1 + r2
str r0,[r1]!, r2, lsl #2 @r0 -----> [r1+r2*4] r1 = r1 + r2 *4
-----------------------------------
str r0, [r1], #0x08 @r0----> [r1] r1 = r1 +0x08
str r0, [r1], r2 @ r0 -----> [r1+r2] r1 = r1+r2
str r0, [r1], r1, lsl #2 @r0----->[r1+r2*4] r1 = r1+r2*4
练习: memcpy,将内存0x8e00开始的64字节数据拷贝到0x8f00开始的内存空间
.text
.code 32
.global _start
_start:
@将0x8e00开始的16个字初始化为1-16
mov r0, #0x00008e00
mov r1, #1
mov r2, #16
loop:
str r1, [r0], #4
subs r2, r2, #1
bne loop
@开始复制数据
mem_cpy:
mov r0, #0x00008e00
mov r1, #0x00008f00
mov r2, #16
mem_cpy_loop:
ldr r3, [r0], #4
str r3, [r1], #4
subs r2, r2, #1
bne mem_cpy_loop
memcpy_ok:
b .
仿真调试运行,必须注意:
1. memcpy.s
.data
.space 1024
2. 链接时指定数据段的地址
arm-cortex_a9-liinux-gnueabi-as memcpy.s -o memcpy.o -g
arm-cortex_a9-liinux-gnueabi-ld -Tdata=0x8e00 memcpy.o -o memcpy
qemu-arm -g 1234 memcpy
另开一个窗口:arm-coretex_a9_linux-gnueabi-gdb memcpy
(gdb) target remote localhost:1234
查看内存的详细格式:
x /nfu addr
x, examine
n, 要连续查看内存单元的个数
f, 显示内存中数据时使用的格式
x, 按16进制显示
d,按10进制显示
u, unit 每个内存单元的字节数
b, 字节
h, 半字
w,字节
(gdb) x /16xw 0x8e00
(gdb) b 20
(gdb) c
(gdb) x /16xw 0x8e00
(gdb) b 30
(gdb) c
(gdb) x /16xw 0x8f00
gdb中
查看寄存器 info reg r0
查看内存 x /nfu w
查看变量 p var
p & var
3.2.4 栈操作指令
ldmxx sp!, {r0-r5, r8}
@将sp指向的栈空间的数据加载到 r0, r1, r2, r3, r4, r5, r8中
stmxx sp!, {r0-r5,r8}
@将r0, r1, r2, r3, r4, r5,r8中的数据加载到sp指向的栈空间中
xx,
fd full 满减栈
fa ascend
ed descend
ea empty
注意空栈和满栈并不是说栈空间真的满了还是空的,而是当前栈指针里有没有数据,
或者说接下来往里存数据的时候,是先放数据还是先改变SP的值。

stmfd sp!, {r0-r5, r8} 等价于 push {r0-r5,r8}
ldmfd sp!, {r0~r5,r8} 等价于 pop {r0~r5,r8}
按满减栈压入栈 也按满减栈弹数据 就能恢复寄存器内容
ldmfd sp!, {r1-r3,r6}
stmfd sp!, {r1-r3,r6}

程序运行是在栈里面的内存布局:

局部变量如何在栈里面分配空间:
#include 00008508 <add>:
8508: e52db004 push {fp} ; (str fp, [sp, #-4]!)
850c: e28db000 add fp, sp, #0
8510: e24dd014 sub sp, sp, #20
8514: e50b0008 str r0, [fp, #-8]
8518: e50b100c str r1, [fp, #-12]
851c: e50b2010 str r2, [fp, #-16]
8520: e51b2008 ldr r2, [fp, #-8]
8524: e51b300c ldr r3, [fp, #-12]
8528: e0822003 add r2, r2, r3
852c: e51b3010 ldr r3, [fp, #-16]
8530: e0823003 add r3, r2, r3
8534: e1a00003 mov r0, r3
8538: e28bd000 add sp, fp, #0
853c: e8bd0800 ldmfd sp!, {fp}
8540: e12fff1e bx lr
00008544 <main>:
8544: e92d4800 push {fp, lr}
8548: e28db004 add fp, sp, #4
854c: e24dd010 sub sp, sp, #16
8550: e3a0300a mov r3, #10
8554: e50b3008 str r3, [fp, #-8]
8558: e3a03014 mov r3, #20
855c: e50b300c str r3, [fp, #-12]
8560: e3a0301e mov r3, #30
8564: e50b3010 str r3, [fp, #-16]
8568: e3a03000 mov r3, #0
856c: e50b3014 str r3, [fp, #-20]
8570: e51b0008 ldr r0, [fp, #-8]
8574: e51b100c ldr r1, [fp, #-12]
8578: e51b2010 ldr r2, [fp, #-16]
857c: ebffffe1 bl 8508 <add>
8580: e50b0014 str r0, [fp, #-20]
8584: e3a03000 mov r3, #0
8588: e1a00003 mov r0, r3
858c: e24bd004 sub sp, fp, #4
8590: e8bd8800 pop {fp, pc}

C语言的运行是离不开栈的:
1)局部变量在栈中分配空间
2) 函数嵌套调用时lr内容需要压入栈
fun1 ()
{
b++;
}
fun ()
{
push {fp, lr}
func1 (); // bl func1 ---> lr = a++;
a=++;
pop {lr} // bx lr
mov pc, lr
pop {pc}
}
main ()
{
func (); // bl func ---> lr = i++
i++;
}
3.3 伪指令
3.3.1 ldr伪指令
本身不被Cpu所识别,但是它能被汇编器翻译成一条或者多条指令cpu所识别的指令
实现了一个小功能
ldr r0, [r1] //汇编指令 判断依据 [ ] 有中括号的是加载指令没有中括号的是伪指令
.code 32
.global _start
.text
_start:
@mov r0, #0x1ff
@ldr r0, =0x1ff
@ldr r0, [pc]
ldr r0, [pc, #4]
add r3, r4, r5
b .
.word 0x1ff
.end
pedo.o: 文件格式 elf32-littlearm
Disassembly of section .text:
00000000 <_start>:
0: e59f0004 ldr r0, [pc, #4] ; c <_start+0xc>
4: e0843005 add r3, r4, r5
8: eafffffe b 8 <_start+0x8>
c: 000001ff .word 0x000001ff
根据三级流水线,pc 指向正在取值的指令,pc + 8 指向正在执行的指令,
相对位置不会发生改变,所以伪指令可以实现将0x1ff存入通用寄存器中。
.code 32
.global _start
.text
_start:
ldr r0, =0x1ff
ldr r1, =text
ldr r2, text
text:
.word 0x12345678
.end
pedo.o: 文件格式 elf32-littlearm
Disassembly of section .text:
00000000 <_start>:
0: e59f0008 ldr r0, [pc, #8] ; 10 <text+0x4>
4: e59f1008 ldr r1, [pc, #8] ; 14 <text+0x8>
8: e51f2004 ldr r2, [pc, #-4] ; c <text>
0000000c <text>:
c: 12345678 .word 0x12345678
10: 000001ff .word 0x000001ff
14: 0000000c .word 0x0000000c
ldr r0, =0x1ff
ldr r1, =test @ 将立即数本身放入r1
ldr r2, test @将立即数指向的内存中的数据加载到 r2
3.3.2 nop伪指令
通常被翻译为 mov r0, r0 一般用于延时
.code 32
.global _start
.text
_start:
ldr r0, =0x1ff
ldr r1, =text
ldr r2, text
nop
nop
text:
.word 0x12345678
.end
pedo.o: 文件格式 elf32-littlearm
Disassembly of section .text:
00000000 <_start>:
0: e59f0010 ldr r0, [pc, #16] ; 18 <text+0x4>
4: e59f1010 ldr r1, [pc, #16] ; 1c <text+0x8>
8: e59f2004 ldr r2, [pc, #4] ; 14 <text>
c: e1a00000 nop ; (mov r0, r0)
10: e1a00000 nop ; (mov r0, r0)
00000014 <text>:
14: 12345678 .word 0x12345678
18: 000001ff .word 0x000001ff
1c: 00000014 .word 0x00000014
3.3.3 adr 伪指令
小范围地址加载指令
忽略
3.4 伪操作
汇编文件中以“.” 开头的就是伪操作
微操作是给汇编器使用的 到编译完成就消失了
.text @下面的代码往代码段放
.data
.bss
.equ
.equ NUM, #20 @类似于C语言中的宏
MOV R1, NUM
.global @将一个标号声明为全局的
.extern
.byte
.word 0x12345678
.space 1024 @分配1024字节空间
.string
.string "abcdef" @分配7字节空间 初始化为“abcdef”
.ascii
.arm 等价于 .code 32
.thumb 等价于 .code 16
.section ....
练习:字符串的比较strcmp

.code 32
.global _start
.text
_start:
ldr r0, =str1
ldr r1, =str2
bl a_strcmp
cmp r0,#0
beq str1_eq_str2
bgt str1_gt_str2
blt str1_lt_str2
str1_lt_str2:
nop
b str1_lt_str2
str1_gt_str2:
nop
b str1_gt_str2
str1_eq_str2:
nop
b str1_eq_str2
@字符串比较函数
@r0 第一个字符串的地址
@r1 第二个字符串的地址
a_strcmp:
ldrb r2, [r0], #1
ldrb r3, [r1], #1
cmp r2,#0
beq str1_end
cmp r2, r3
beq a_strcmp
str1_end:
sub r0, r2, r3
mov pc, lr
@字符串定义
str1:
.ascii "ABCD\0"
str2:
@.ascii "ABCE"
@.string "ABCD"
@.asciz "ABC"
.asciz "ABB"
.end
LED的控制
1.1 电路原理图:
结论: 控制LED1的亮灭 实则就是控制W15管脚
1.2 CPU DATASHEET
GPIOCALTFN0 0xc001c020
[25:24] 01 配置为GPIO功能
GPIOCOUTENB 0xc001c004
[12] 1设置为输出模式
GPIOCOUT 0xc001c000
[12] 0/1 输出低、高电平
1.3 汇编程序
a = *((unsigned int *) 0xc001c20)
ldr r0, =&a
ldr r1, =0xc001c020
ldr r2, [r1]
str r2, [r0]
b = *((unsigned int *) 0xc001c020)
ldr r0, =&b
/*在这个过程中r2 中的内容软件没改
0xc001c020寄存器中的内容软件没改
编译器分析缓存中的数据和特殊功能寄存器中的内容一致
所以将以下两行代码优化*/
//ldr r1, =0xc001c020
//ldr r2,[r1]
str r2, [r0]
但是硬件上有可能改变了特殊功能寄存器中的值
很有可能缓存中的数据和真是数据不一致
不应该优化
加上volatile 编译器就不做以上优化了
volatile 的作用:防止编译器的过度优化
每次都去真实地址中取数据,而不是去缓存中取数据
使用场合:1)访问特殊功能寄存器
2)多线程访问的共享的全局变量
3) 进程与中断服务程序共享的全局变量
arm-cortex_a9-linux-gnueabi-as led.s -o led.o
arm-cortex_a9-linux-gnueabi-ld -nostdlib -nostartfiles -Ttext=0x48000000 led.o -o led
arm-cortex_a9-linux-gnueabi-objcopy -O binary led led.bin
cp led.bin /tftpboot
tftp 48000000 led.bin
go 48000000
.text
.global _start
.arm
.equ GPIOCALTFN0, 0xc001c020
.equ GPIOCOUT, 0xc001c000
.equ GPIOCOUTENB, 0xc001c004
_start:
/*配置管脚为GPIO功能*/
ldr r0, =GPIOCALTFN0
ldr r1, [r0]
mov r2, #0x03
bic r1, r1, r2, lsl #24
mov r3, #1
orr r1, r1, r3, lsl #24
/*将r1中的值写回特殊功能寄存器*/
str r1, [r0]
/*设置为输出模式*/
ldr r0, =GPIOCOUTENB
ldr r1, [r0]
orr r1, r1, r3, lsl #12
str r1, [r0]
loop:
/*亮*/
ldr r0, =GPIOCOUT
ldr r1, [r0]
bic r1, r1, r3, lsl #12
str r1, [r0]
bl delay
/*灭*/
ldr r1, [r0]
orr r1, r1, r3, lsl #12
str r1, [r0]
bl delay
b loop
delay:
push {r0}
mov r0, #0xf0000000
delay_loop:
sub r0, r0, #1
cmp r0, #0
bne delay_loop
pop {r0}
mov pc, lr
@delay:
@mov r5, =0xf0000000
@delay_loop:
@sub r5, r5, #1
@cmp r5, #0
@bne delay_loop
@
@mov pc, lr
@
.end